GAIL¶
Overview¶
GAIL (Generative Adversarial Imitation Learning) was first proposed in Generative Adversarial Imitation Learning, which deduced the optimization objective of GAIL from the perspective of occupancy measure. Compared to other learning methods, GAIL neither suffers from the compounding error problem in imitation learning, nor needs to expensively learn the inter-mediate reward function as in inverse reinforcement learning. But similar to other methods, GAIL is also exposed to “the curse of dimensionality”, which makes the scalability much valuable in high-dimension-space problems.
Quick Facts¶
GAIL consists of a generator and a discriminator, trained in an adversarial manner.
The generator is optimized for a surrogate reward, usually by policy-gradient reinforcement learning methods, like TRPO, for its sampling nature.
The discriminator can be simply optimized by typical gradient descent methods, like Adam, to distinguish expert and generated data.
Key Equations or Key Graphs¶
The objective function in GAIL’s adversarial training is as below:
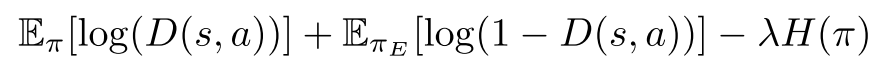
where pi is the generator policy, D is the discriminator policy, while \(H(\pi)\) is the causal entropy of policy pi. This is a min-max optimization process, and the objective is optimized in an iterative adversarial manner.
Pseudo-Code¶

Extensions¶
MAGAIL (Multi-Agent Generative Adversarial Imitation Learning)
Multi-agent systems tend to be much more complicated, due to the heterogeneity, stochasticity, and interaction among multi-agents.
MAGAIL:Multi-Agent Generative Adversarial Imitation Learning extended GAIL to multi-agent scenarios. The generator is redefined as a policy controlling all agents in a distributed manner, while the discriminator is distinguishing expert and generates behavior for each agent.
The Pseudo-Code is as following:

Other perspectives to understand GAIL
GAIL is closely related to other learning methods, and thus can be understood in different views.
A Connection Between Generative Adversarial Networks, Inverse Reinforcement Learning, and Energy-Based Models indicated GAIL’s implicit connection to GAN, IRL, and energy-based probability estimation.
Reference¶
Ho, Jonathan, and Stefano Ermon. “Generative adversarial imitation learning.” Advances in neural information processing systems 29 (2016): 4565-4573.
Song, Jiaming, et al. “Multi-agent generative adversarial imitation learning.” arXiv preprint arXiv:1807.09936 (2018).
Finn, Chelsea, et al. “A connection between generative adversarial networks, inverse reinforcement learning, and energy-based models.” arXiv preprint arXiv:1611.03852 (2016).