Merge pull request #93 from zhaopu7/develop
update language model's README
Showing
{kind=link}
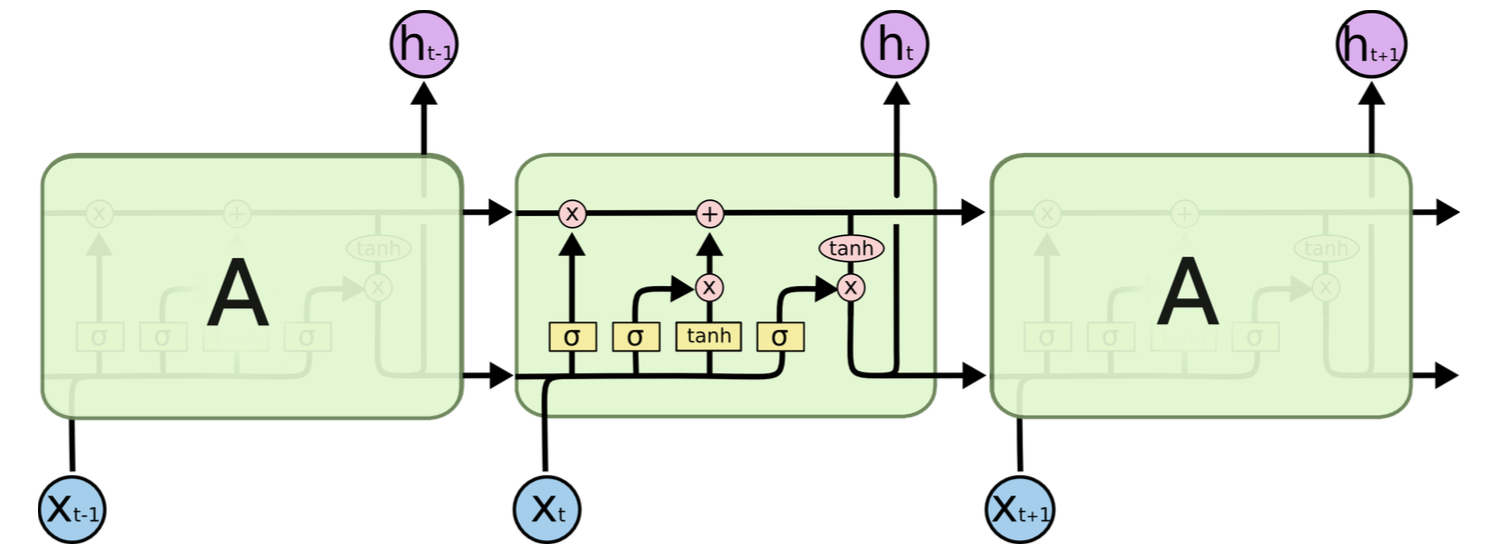
212.8 KB
language_model/images/ps.png
已删除
100644 → 0
{kind=link}
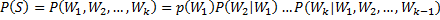
1.8 KB
language_model/images/ps2.png
已删除
100644 → 0
{kind=link}
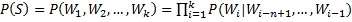
1.6 KB
{kind=link}
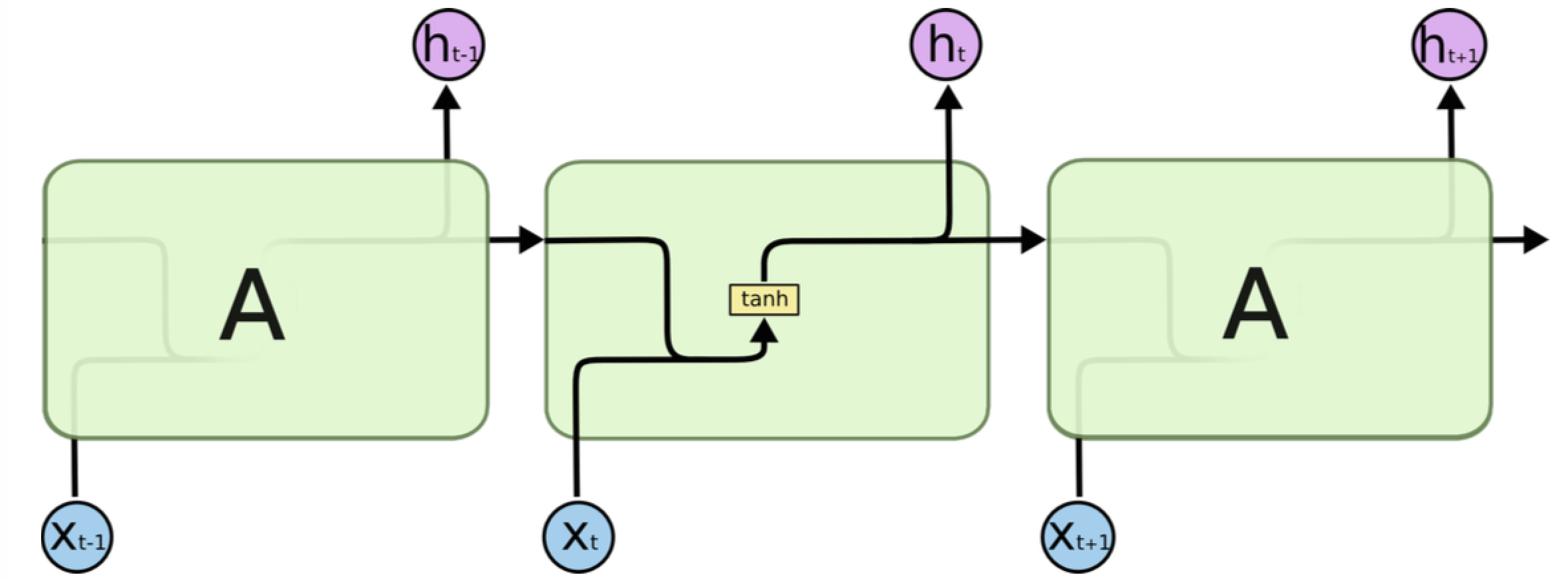
167.4 KB
language_model/images/s.png
已删除
100644 → 0
{kind=link}
720 字节