Skip to content
体验新版
项目
组织
正在加载...
登录
切换导航
打开侧边栏
PaddlePaddle
models
提交
7fd3c7fd
M
models
项目概览
PaddlePaddle
/
models
大约 2 年 前同步成功
通知
232
Star
6828
Fork
2962
代码
文件
提交
分支
Tags
贡献者
分支图
Diff
Issue
602
列表
看板
标记
里程碑
合并请求
255
Wiki
0
Wiki
分析
仓库
DevOps
项目成员
Pages
M
models
项目概览
项目概览
详情
发布
仓库
仓库
文件
提交
分支
标签
贡献者
分支图
比较
Issue
602
Issue
602
列表
看板
标记
里程碑
合并请求
255
合并请求
255
Pages
分析
分析
仓库分析
DevOps
Wiki
0
Wiki
成员
成员
收起侧边栏
关闭侧边栏
动态
分支图
创建新Issue
提交
Issue看板
提交
7fd3c7fd
编写于
6月 14, 2017
作者:
Z
zhaopu
浏览文件
操作
浏览文件
下载
电子邮件补丁
差异文件
update readme
上级
f568a1fb
变更
3
隐藏空白更改
内联
并排
Showing
3 changed file
with
8 addition
and
12 deletion
+8
-12
language_model/README.md
language_model/README.md
+8
-12
language_model/images/lstm.png
language_model/images/lstm.png
+0
-0
language_model/images/rnn_str.png
language_model/images/rnn_str.png
+0
-0
未找到文件。
language_model/README.md
浏览文件 @
7fd3c7fd
# 语言模型
# 语言模型
## 简介
## 简介
语言模型即 Language Model,简称LM
,它是一个概率分布模型,简单来说,就是用来计算一个句子的概率的模型。利用它可以确定哪个词序列的可能性更大,或者给定若干个词,可以预测下一个最可能出现的词语。它是自然语言处理领域的
一个重要的基础模型。
语言模型即 Language Model,简称LM
。它是一个概率分布模型,简单来说,就是用来计算一个句子的概率的模型。利用它可以确定哪个词序列的可能性更大,或者给定若干个词,可以预测下一个最可能出现的词。语言模型是自然语言处理领域里
一个重要的基础模型。
## 应用场景
## 应用场景
**语言模型被应用在很多领域**
,如:
**语言模型被应用在很多领域**
,如:
...
@@ -9,7 +9,7 @@
...
@@ -9,7 +9,7 @@
*
**自动写作**
:语言模型可以根据上文生成下一个词,递归下去可以生成整个句子、段落、篇章。
*
**自动写作**
:语言模型可以根据上文生成下一个词,递归下去可以生成整个句子、段落、篇章。
*
**QA**
:语言模型可以根据Question生成Answer。
*
**QA**
:语言模型可以根据Question生成Answer。
*
**机器翻译**
:当前主流的机器翻译模型大多基于Encoder-Decoder模式,其中Decoder就是一个语言模型,用来生成目标语言。
*
**机器翻译**
:当前主流的机器翻译模型大多基于Encoder-Decoder模式,其中Decoder就是一个语言模型,用来生成目标语言。
*
**拼写检查**
:语言模型可以计算出词
语
序列的概率,一般在拼写错误处序列的概率会骤减,可以用来识别拼写错误并提供改正候选集。
*
**拼写检查**
:语言模型可以计算出词序列的概率,一般在拼写错误处序列的概率会骤减,可以用来识别拼写错误并提供改正候选集。
*
**词性标注、句法分析、语音识别......**
*
**词性标注、句法分析、语音识别......**
## 关于本例
## 关于本例
...
@@ -36,15 +36,9 @@ Language Model 常见的实现方式有 N-Gram、RNN、seq2seq。本例中实现
...
@@ -36,15 +36,9 @@ Language Model 常见的实现方式有 N-Gram、RNN、seq2seq。本例中实现
## RNN 语言模型
## RNN 语言模型
### 简介
### 简介
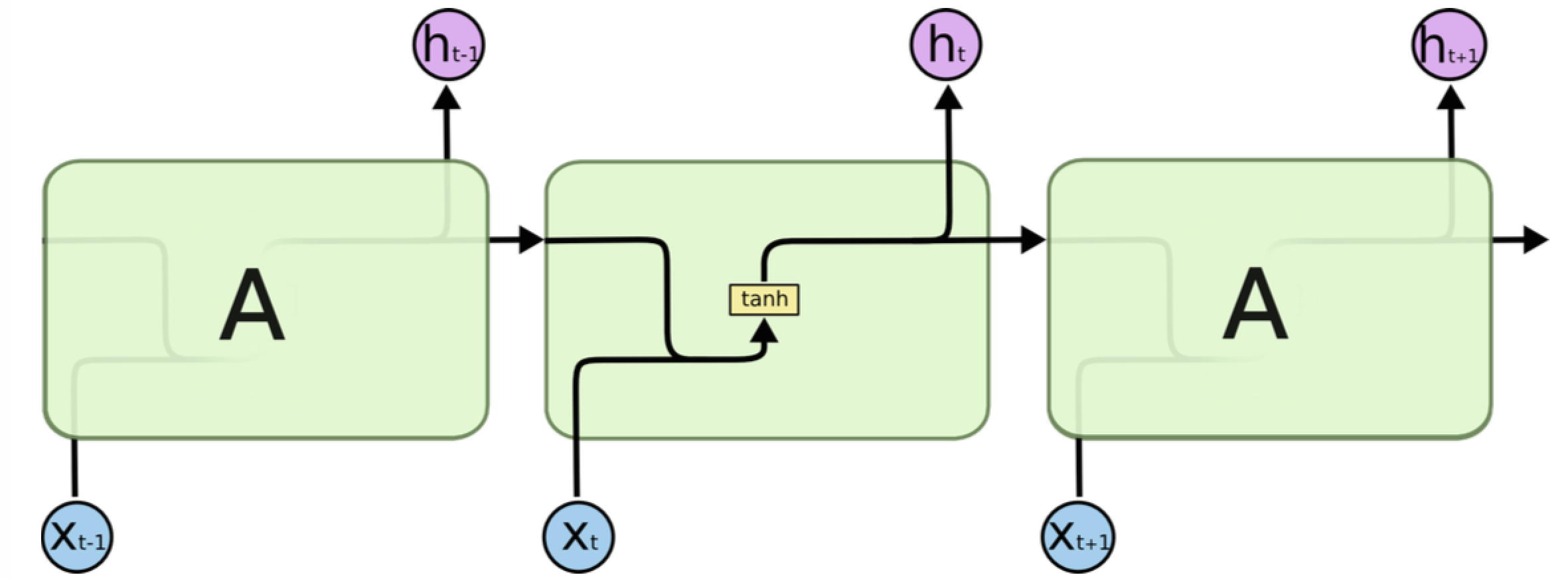
RNN是一个序列模型,基本思路是:在时刻t,将前一时刻t-1的隐藏层输出和t时刻的词向量一起输入到隐藏层从而得到时刻t的特征表示,然后用这个特征表示得到t时刻的预测输出,如此在时间维上递归下去
,如下图所示
:
RNN是一个序列模型,基本思路是:在时刻t,将前一时刻t-1的隐藏层输出和t时刻的词向量一起输入到隐藏层从而得到时刻t的特征表示,然后用这个特征表示得到t时刻的预测输出,如此在时间维上递归下去
。可以看出RNN善于使用上文信息、历史知识,具有“记忆”功能。理论上RNN能实现“长依赖”(即利用很久之前的知识),但在实际应用中发现效果并不理想,于是出现了很多RNN的变种,如常用的LSTM和GRU,它们对传统RNN的cell进行了改进,弥补了传统RNN的不足,本例中即使用了LSTM、GRU。下图是RNN(广义上包含了LSTM、GRU等)语言模型“循环”思想的示意图
:
<p
align=
center
><img
src=
'images/rnn_str.png'
width=
'500px'
/></p>
<p
align=
center
><img
src=
'images/rnn.png'
width=
'500px'
/></p>
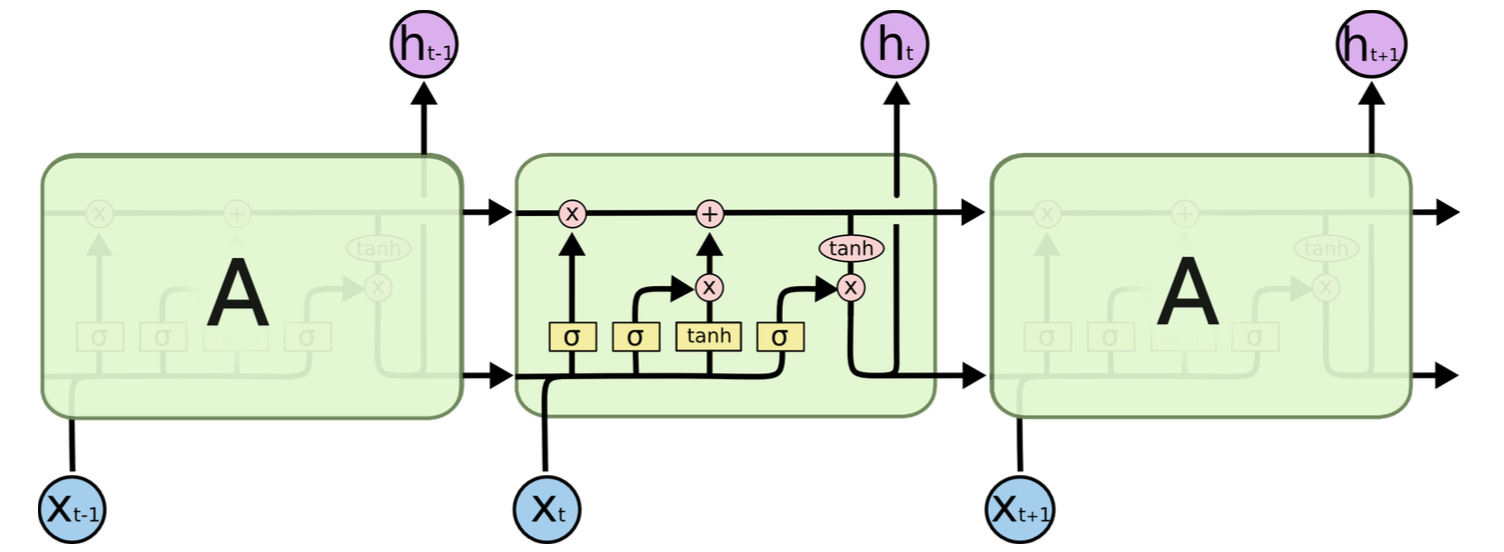
可以看出RNN善于使用上文信息、历史知识,具有“记忆”功能。理论上RNN能实现“长依赖”(即利用很久之前的知识),但在实际应用中发现效果并不理想,于是出现了很多RNN的变种,如常用的LSTM和GRU,它们对传统RNN的cell进行了改进,弥补了RNN的不足,下图是LSTM的示意图:
<p
align=
center
><img
src=
'images/lstm.png'
width=
'500px'
/></p>
本例中即使用了LSTM、GRU。
### 模型实现
### 模型实现
...
@@ -60,7 +54,7 @@ RNN是一个序列模型,基本思路是:在时刻t,将前一时刻t-1的
...
@@ -60,7 +54,7 @@ RNN是一个序列模型,基本思路是:在时刻t,将前一时刻t-1的
*
准备输入数据:建立并保存词典、构建train和test数据的reader。
*
准备输入数据:建立并保存词典、构建train和test数据的reader。
*
初始化模型:包括模型的结构、参数。
*
初始化模型:包括模型的结构、参数。
*
构建训练器:demo中使用的是Adam优化算法。
*
构建训练器:demo中使用的是Adam优化算法。
*
定义回调函数:构建
`event_handler`
来跟踪训练过程中loss的变化,并在每轮
时结束
保存模型的参数。
*
定义回调函数:构建
`event_handler`
来跟踪训练过程中loss的变化,并在每轮
训练结束时
保存模型的参数。
*
训练:使用trainer训练模型。
*
训练:使用trainer训练模型。
*
**生成文本**
:
`infer.py`
中的
`main`
方法实现了文本的生成,实现流程如下:
*
**生成文本**
:
`infer.py`
中的
`main`
方法实现了文本的生成,实现流程如下:
...
@@ -73,7 +67,9 @@ RNN是一个序列模型,基本思路是:在时刻t,将前一时刻t-1的
...
@@ -73,7 +67,9 @@ RNN是一个序列模型,基本思路是:在时刻t,将前一时刻t-1的
## N-Gram 语言模型
## N-Gram 语言模型
### 简介
### 简介
N-Gram模型也称为N-1阶马尔科夫模型,它有一个有限历史假设:当前词的出现概率仅仅与前面N-1个词相关。一般采用最大似然估计(Maximum Likelihood Estimation,MLE)的方法对模型的参数进行估计。当N取1、2、3时,N-Gram模型分别称为unigram、bigram和trigram语言模型。一般情况下,N越大、训练语料的规模越大,参数估计的结果越可靠,但由于模型较简单、表达能力不强以及数据稀疏等问题。一般情况下用N-Gram实现的语言模型不如RNN、seq2seq效果好。
N-Gram模型也称为N-1阶马尔科夫模型,它有一个有限历史假设:当前词的出现概率仅仅与前面N-1个词相关。一般采用最大似然估计(Maximum Likelihood Estimation,MLE)方法对模型的参数进行估计。当N取1、2、3时,N-Gram模型分别称为unigram、bigram和trigram语言模型。一般情况下,N越大、训练语料的规模越大,参数估计的结果越可靠,但由于模型较简单、表达能力不强以及数据稀疏等问题。一般情况下用N-Gram实现的语言模型不如RNN、seq2seq效果好。下图是基于神经网络的N-Gram语言模型结构示意图:
<p
align=
center
><img
src=
'images/ngram.png'
width=
'500px'
/></p>
### 模型实现
### 模型实现
...
...
language_model/images/lstm.png
已删除
100644 → 0
浏览文件 @
f568a1fb
212.8 KB
language_model/images/rnn_str.png
已删除
100644 → 0
浏览文件 @
f568a1fb
167.4 KB
编辑
预览
Markdown
is supported
0%
请重试
或
添加新附件
.
添加附件
取消
You are about to add
0
people
to the discussion. Proceed with caution.
先完成此消息的编辑!
取消
想要评论请
注册
或
登录
{kind=link}
{kind=link}