Merge pull request #60 from zhaopu7/develop
add neural language model.
Showing
language_model/config.py
0 → 100644
language_model/data/input.txt
0 → 100644
language_model/images/lstm.png
0 → 100644
{kind=link}
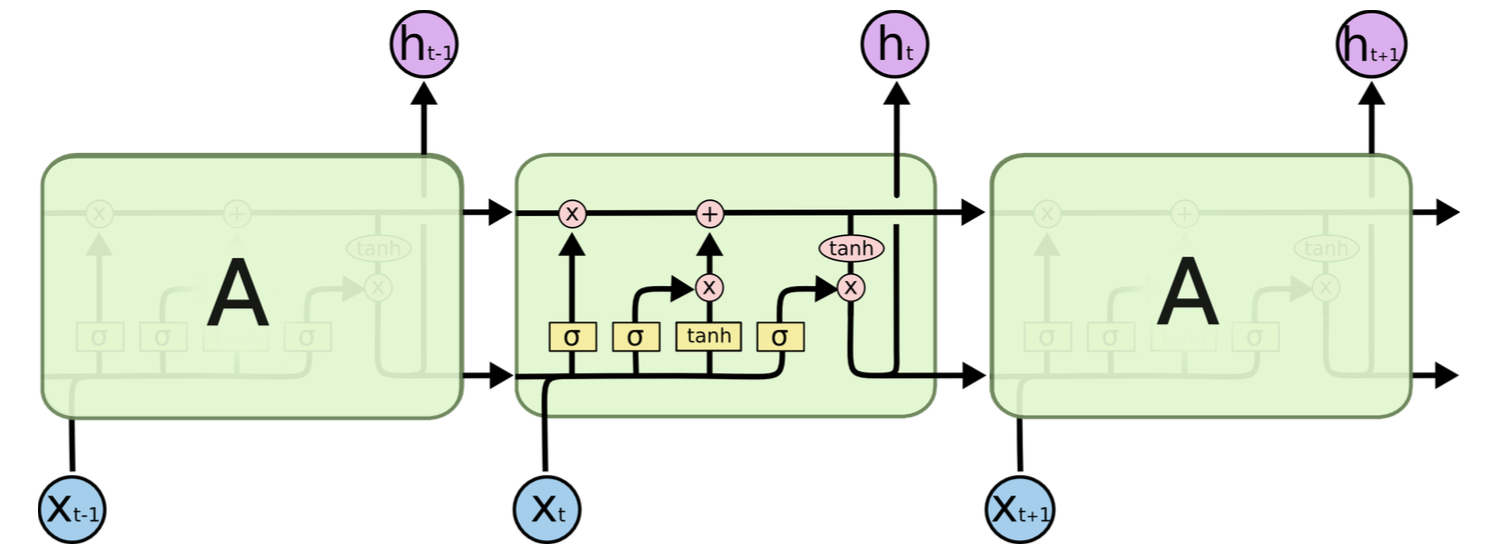
212.8 KB
language_model/images/ngram.png
0 → 100644
{kind=link}
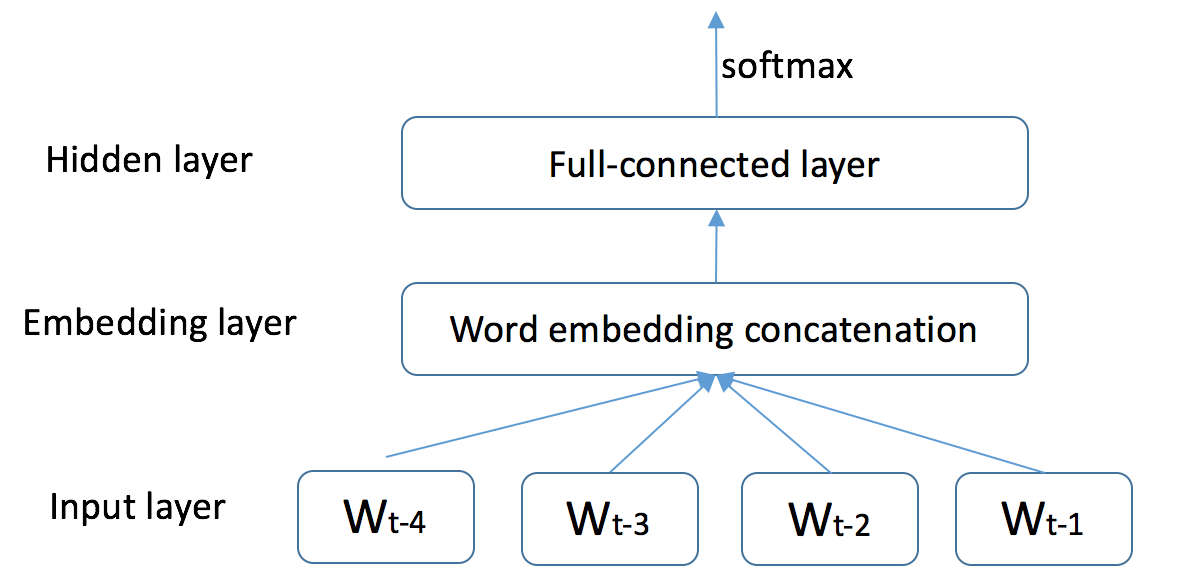
67.1 KB
language_model/images/ps.png
0 → 100644
{kind=link}
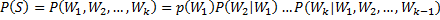
1.8 KB
language_model/images/ps2.png
0 → 100644
{kind=link}
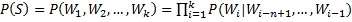
1.6 KB
language_model/images/rnn.png
0 → 100644
{kind=link}
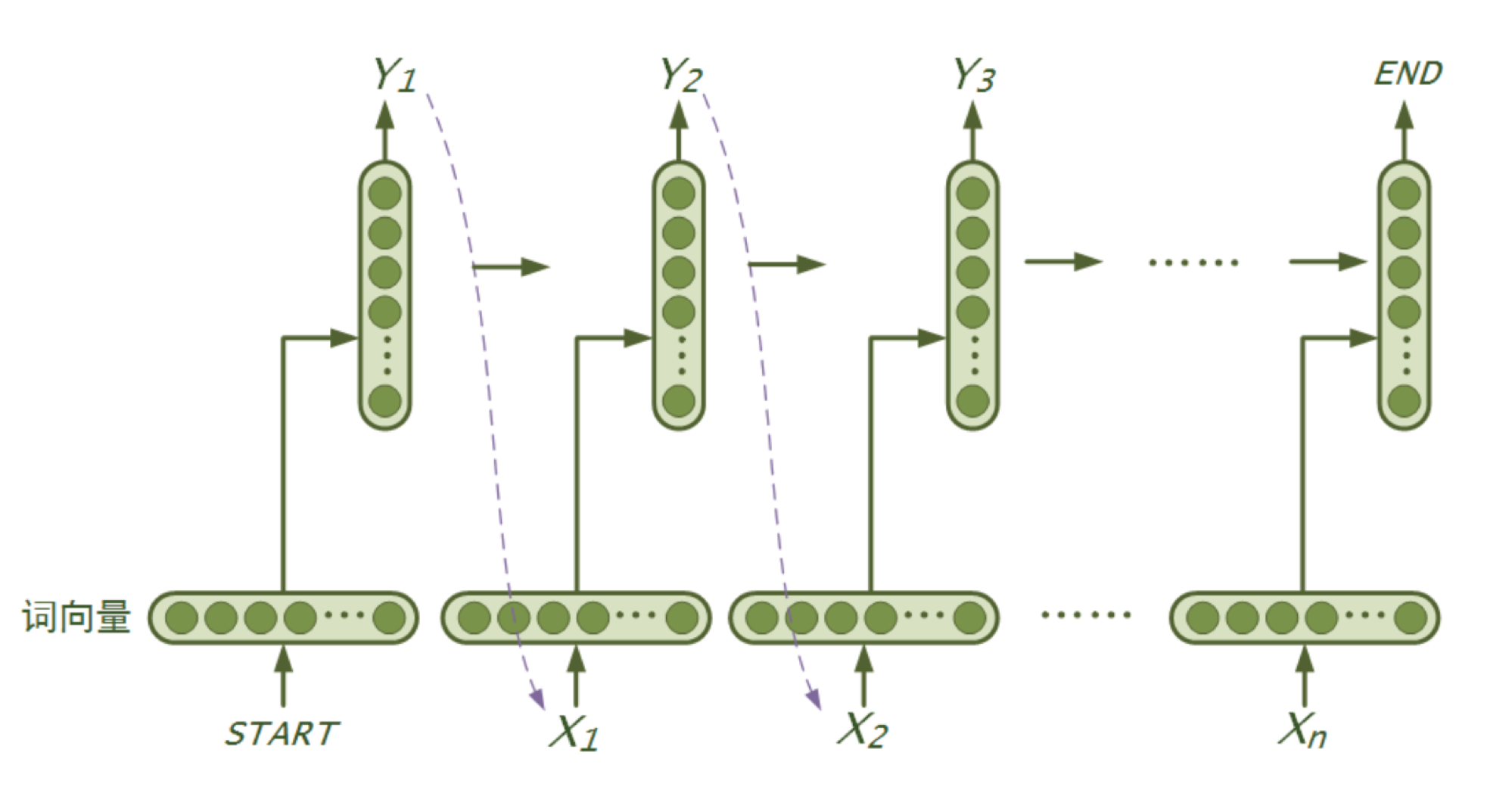
335.3 KB
language_model/images/rnn_str.png
0 → 100644
{kind=link}
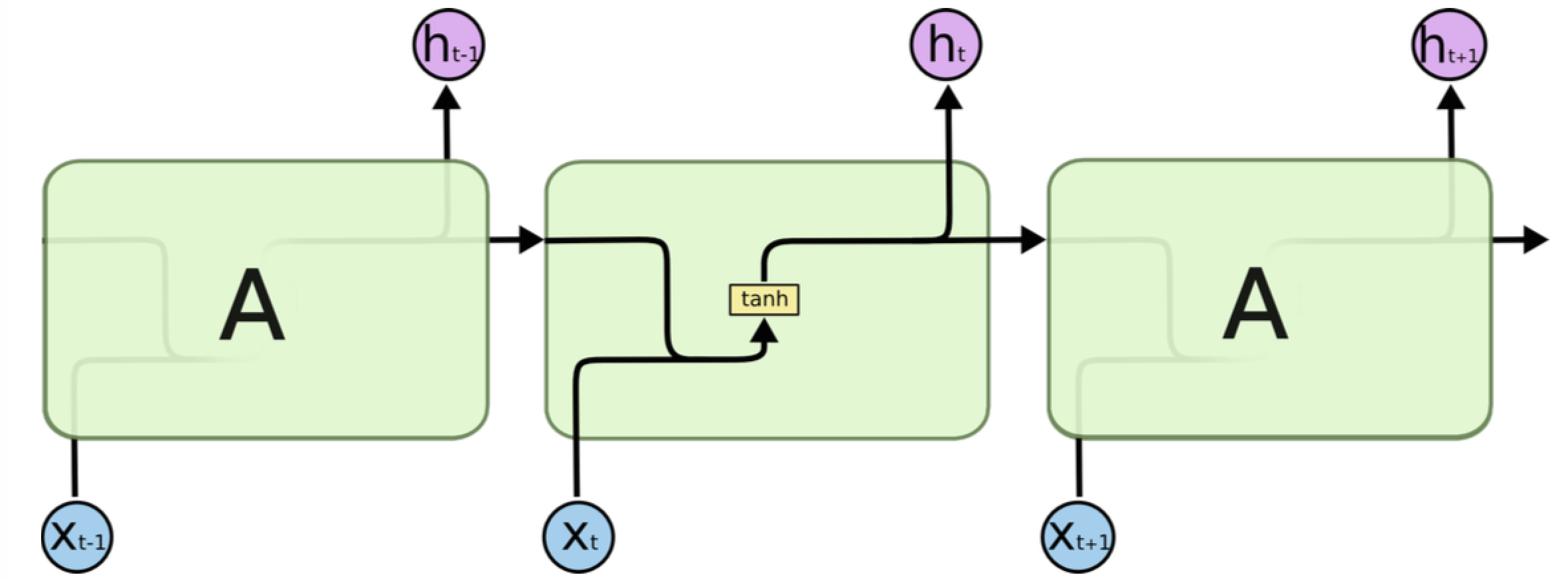
167.4 KB
language_model/images/s.png
0 → 100644
{kind=link}
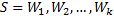
720 字节
language_model/infer.py
0 → 100644
language_model/network_conf.py
0 → 100644
language_model/reader.py
0 → 100644
language_model/train.py
0 → 100644
language_model/utils.py
0 → 100644