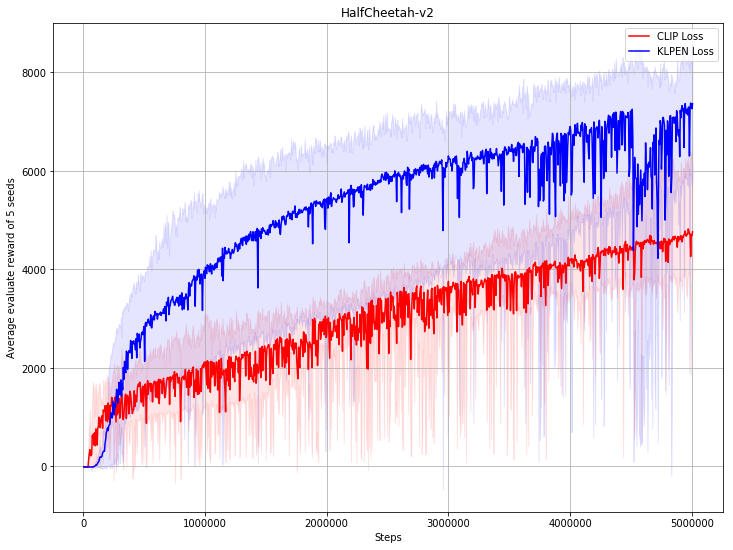
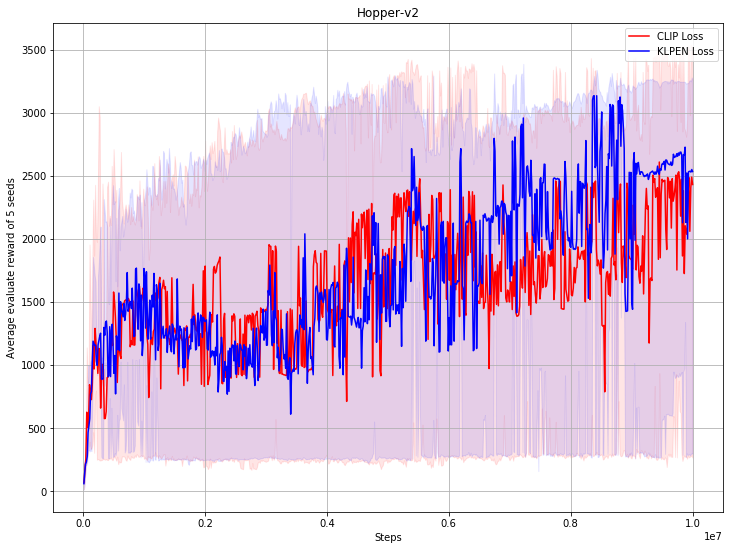
fix PPO bug; add more benchmark result (#47)
* fix PPO bug; add more benchmark result * refine code * update benchmark of PPO, after fix bug * refine code
Showing
{kind=link}
38.7 KB
{kind=link}
77.3 KB
{kind=link}
61.1 KB
{kind=link}
{kind=link}
| W: | H:
| W: | H:
{kind=link}
152.0 KB
* fix PPO bug; add more benchmark result * refine code * update benchmark of PPO, after fix bug * refine code
38.7 KB
77.3 KB
61.1 KB
| W: | H:
| W: | H:
152.0 KB