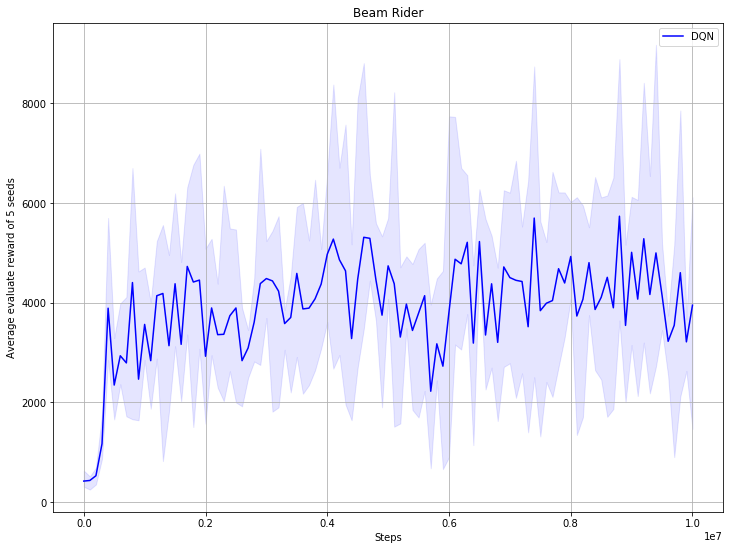
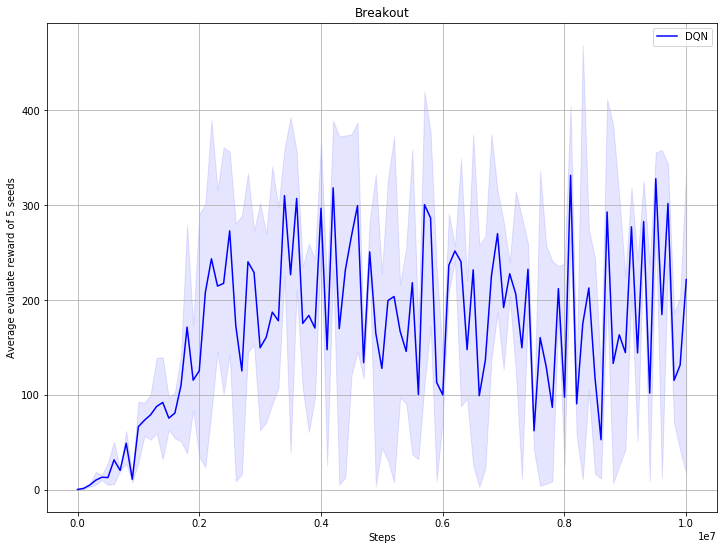
Add more dqn benchmark result and unify train scripts (#46)
* add more dqn benchmark result; unify train scripts * resize benchmark picture * resize benchmark picture, refine comments of args * change dependence, mujoco only support python3 now
Showing
{kind=link}
66.1 KB
{kind=link}
73.7 KB