Skip to content
体验新版
项目
组织
正在加载...
登录
切换导航
打开侧边栏
wushizhenking
CS-Notes
提交
288fb85d
C
CS-Notes
项目概览
wushizhenking
/
CS-Notes
与 Fork 源项目一致
从无法访问的项目Fork
通知
2
Star
0
Fork
0
代码
文件
提交
分支
Tags
贡献者
分支图
Diff
Issue
0
列表
看板
标记
里程碑
合并请求
0
Wiki
0
Wiki
分析
仓库
DevOps
项目成员
Pages
C
CS-Notes
项目概览
项目概览
详情
发布
仓库
仓库
文件
提交
分支
标签
贡献者
分支图
比较
Issue
0
Issue
0
列表
看板
标记
里程碑
合并请求
0
合并请求
0
Pages
分析
分析
仓库分析
DevOps
Wiki
0
Wiki
成员
成员
收起侧边栏
关闭侧边栏
动态
分支图
创建新Issue
提交
Issue看板
体验新版 GitCode,发现更多精彩内容 >>
提交
288fb85d
编写于
8月 05, 2018
作者:
C
CyC2018
浏览文件
操作
浏览文件
下载
电子邮件补丁
差异文件
auto commit
上级
0da21d78
变更
7
隐藏空白更改
内联
并排
Showing
7 changed file
with
134 addition
and
41 deletion
+134
-41
notes/Java 基础.md
notes/Java 基础.md
+17
-17
notes/Java 容器.md
notes/Java 容器.md
+116
-23
notes/算法.md
notes/算法.md
+1
-1
pics/49495c95-52e5-4c9a-b27b-92cf235ff5ec.png
pics/49495c95-52e5-4c9a-b27b-92cf235ff5ec.png
+0
-0
pics/NP4z3i8m38Ntd28NQ4_0KCJ2q044Oez.png
pics/NP4z3i8m38Ntd28NQ4_0KCJ2q044Oez.png
+0
-0
pics/SoWkIImgAStDuUBAp2j9BKfBJ4vLy0G.png
pics/SoWkIImgAStDuUBAp2j9BKfBJ4vLy0G.png
+0
-0
pics/SoWkIImgAStDuUBAp2j9BKfBJ4vLy4q.png
pics/SoWkIImgAStDuUBAp2j9BKfBJ4vLy4q.png
+0
-0
未找到文件。
notes/Java 基础.md
浏览文件 @
288fb85d
...
...
@@ -4,7 +4,7 @@
*
[
缓存池
](
#缓存池
)
*
[
二、String
](
#二string
)
*
[
概览
](
#概览
)
*
[
String 不可变的好处
](
#string-
不可变的好处
)
*
[
不可变的好处
](
#
不可变的好处
)
*
[
String, StringBuffer and StringBuilder
](
#string,-stringbuffer-and-stringbuilder
)
*
[
String.intern()
](
#stringintern
)
*
[
三、运算
](
#三运算
)
...
...
@@ -153,7 +153,7 @@ public final class String
private
final
char
value
[];
```
##
String
不可变的好处
## 不可变的好处
**1. 可以缓存 hash 值**
...
...
@@ -212,7 +212,7 @@ String s5 = "bbb";
System
.
out
.
println
(
s4
==
s5
);
// true
```
在 Java 7 之前,字符串常量池被放在运行时常量池中,它属于永久代。而在 Java 7,字符串常量池被
放在堆
中。这是因为永久代的空间有限,在大量使用字符串的场景下会导致 OutOfMemoryError 错误。
在 Java 7 之前,字符串常量池被放在运行时常量池中,它属于永久代。而在 Java 7,字符串常量池被
移到 Native Method
中。这是因为永久代的空间有限,在大量使用字符串的场景下会导致 OutOfMemoryError 错误。
-
[
StackOverflow : What is String interning?
](
https://stackoverflow.com/questions/10578984/what-is-string-interning
)
-
[
深入解析 String#intern
](
https://tech.meituan.com/in_depth_understanding_string_intern.html
)
...
...
@@ -583,19 +583,7 @@ protected void finalize() throws Throwable {}
## equals()
**1. equals() 与 == 的区别**
-
对于基本类型,== 判断两个值是否相等,基本类型没有 equals() 方法。
-
对于引用类型,== 判断两个实例是否引用同一个对象,而 equals() 判断引用的对象是否等价,根据引用的对象的 equals() 方法的具体实现来进行比较。
```
java
Integer
x
=
new
Integer
(
1
);
Integer
y
=
new
Integer
(
1
);
System
.
out
.
println
(
x
.
equals
(
y
));
// true
System
.
out
.
println
(
x
==
y
);
// false
```
**2. 等价关系**
**1. 等价关系**
(一)自反性
...
...
@@ -632,6 +620,18 @@ x.equals(y) == x.equals(y); // true
x
.
equals
(
null
);
// false;
```
**2. equals() 与 ==**
-
对于基本类型,== 判断两个值是否相等,基本类型没有 equals() 方法。
-
对于引用类型,== 判断两个实例是否引用同一个对象,而 equals() 判断引用的对象是否等价,根据引用对象 equals() 方法的具体实现来进行比较。
```
java
Integer
x
=
new
Integer
(
1
);
Integer
y
=
new
Integer
(
1
);
System
.
out
.
println
(
x
.
equals
(
y
));
// true
System
.
out
.
println
(
x
==
y
);
// false
```
**3. 实现**
-
检查是否为同一个对象的引用,如果是直接返回 true;
...
...
@@ -1005,7 +1005,7 @@ public class A {
**4. 静态内部类**
非静态内部类依赖于
需要
外部类的实例,而静态内部类不需要。
非静态内部类依赖于外部类的实例,而静态内部类不需要。
```
java
public
class
OuterClass
{
...
...
notes/Java 容器.md
浏览文件 @
288fb85d
...
...
@@ -14,6 +14,7 @@
*
[
ConcurrentHashMap
](
#concurrenthashmap
)
*
[
LinkedHashMap
](
#linkedhashmap
)
*
[
WeekHashMap
](
#weekhashmap
)
*
[
附录
](
#附录
)
*
[
参考资料
](
#参考资料
)
<!-- GFM-TOC -->
...
...
@@ -24,15 +25,15 @@
## Collection
<div
align=
"center"
>
<img
src=
"../pics//
java-collections
.png"
/>
</div><br>
<div
align=
"center"
>
<img
src=
"../pics//
NP4z3i8m38Ntd28NQ4_0KCJ2q044Oez
.png"
/>
</div><br>
### 1. Set
-
HashSet:基于哈希
实现,支持快速查找,
但不支持有序性操作,例如根据一个范围查找元素的操作。并且失去了元素的插入顺序信息,也就是说使用 Iterator 遍历 HashSet 得到的结果是不确定的。
-
HashSet:基于哈希
表实现,支持快速查找。
但不支持有序性操作,例如根据一个范围查找元素的操作。并且失去了元素的插入顺序信息,也就是说使用 Iterator 遍历 HashSet 得到的结果是不确定的。
-
TreeSet:基于红黑树实现,支持有序性操作,但是查找效率不如 HashSet,HashSet 查找时间复杂度为 O(1),TreeSet 则为 O(logN)。
-
LinkedHashSet:具有 HashSet 的查找效率,且内部使用链表维护元素的插入顺序。
-
LinkedHashSet:具有 HashSet 的查找效率,且内部使用
双向
链表维护元素的插入顺序。
### 2. List
...
...
@@ -50,13 +51,13 @@
## Map
<div
align=
"center"
>
<img
src=
"../pics//
java-collections1
.png"
/>
</div><br>
<div
align=
"center"
>
<img
src=
"../pics//
SoWkIImgAStDuUBAp2j9BKfBJ4vLy4q
.png"
/>
</div><br>
-
HashMap:基于哈希实现;
-
HashMap:基于哈希
表
实现;
-
HashTable:和 HashMap 类似,但它是线程安全的,这意味着同一时刻多个线程可以同时写入 HashTable 并且不会导致数据不一致。它是遗留类,不应该去使用它。现在可以使用 ConcurrentHashMap 来支持线程安全,并且 ConcurrentHashMap 的效率会更高,因为 ConcurrentHashMap 引入了分段锁。
-
LinkedHashMap:使用链表来维护元素的顺序,顺序为插入顺序或者最近最少使用(LRU)顺序。
-
LinkedHashMap:使用
双向
链表来维护元素的顺序,顺序为插入顺序或者最近最少使用(LRU)顺序。
-
TreeMap:基于红黑树实现。
...
...
@@ -64,7 +65,7 @@
## 迭代器模式
<div
align=
"center"
>
<img
src=
"../pics//
Iterator-1.jp
g"
/>
</div><br>
<div
align=
"center"
>
<img
src=
"../pics//
SoWkIImgAStDuUBAp2j9BKfBJ4vLy0G.pn
g"
/>
</div><br>
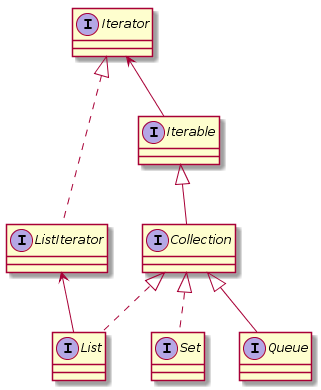
Collection 实现了 Iterable 接口,其中的 iterator() 方法能够产生一个 Iterator 对象,通过这个对象就可以迭代遍历 Collection 中的元素。
...
...
@@ -95,7 +96,7 @@ Integer[] arr = {1, 2, 3};
List
list
=
Arrays
.
asList
(
arr
);
```
也可以使用以下方式
使
用 asList():
也可以使用以下方式
调
用 asList():
```
java
List
list
=
Arrays
.
asList
(
1
,
2
,
3
);
...
...
@@ -111,7 +112,7 @@ List list = Arrays.asList(1,2,3);
### 1. 概览
实现了 RandomAccess 接口,因此支持随机访问
,
这是理所当然的,因为 ArrayList 是基于数组实现的。
实现了 RandomAccess 接口,因此支持随机访问
。
这是理所当然的,因为 ArrayList 是基于数组实现的。
```
java
public
class
ArrayList
<
E
>
extends
AbstractList
<
E
>
...
...
@@ -126,7 +127,9 @@ private static final int DEFAULT_CAPACITY = 10;
### 2. 序列化
基于数组实现,保存元素的数组使用 transient 修饰,该关键字声明数组默认不会被序列化。ArrayList 具有动态扩容特性,因此保存元素的数组不一定都会被使用,那么就没必要全部进行序列化。ArrayList 重写了 writeObject() 和 readObject() 来控制只序列化数组中有元素填充那部分内容。
ArrayList 基于数组实现,并且具有动态扩容特性,因此保存元素的数组不一定都会被使用,那么就没必要全部进行序列化。
保存元素的数组 elementData 使用 transient 修饰,该关键字声明数组默认不会被序列化。ArrayList 重写了 writeObject() 和 readObject() 来控制只序列化数组中有元素填充那部分内容。
```
java
transient
Object
[]
elementData
;
// non-private to simplify nested class access
...
...
@@ -174,7 +177,7 @@ private void grow(int minCapacity) {
### 4. 删除元素
需要调用 System.arraycopy() 将 index+1 后面的元素都复制到 index 位置上。
需要调用 System.arraycopy() 将 index+1 后面的元素都复制到 index 位置上
,该操作的时间复杂度为 O(N),可以看出 ArrayList 删除元素的代价是非常高的
。
```
java
public
E
remove
(
int
index
)
{
...
...
@@ -311,7 +314,7 @@ CopyOnWriteArrayList 在写操作的同时允许读操作,大大提高了读
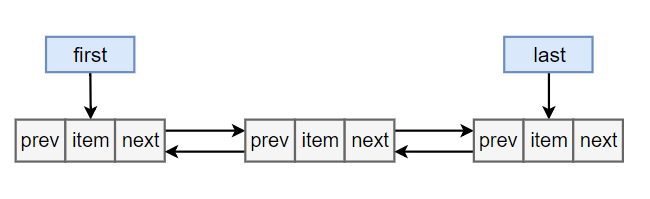
### 1. 概览
基于双向链表实现,
内部使用 Node 来
存储链表节点信息。
基于双向链表实现,
使用 Node
存储链表节点信息。
```
java
private
static
class
Node
<
E
>
{
...
...
@@ -328,7 +331,7 @@ transient Node<E> first;
transient
Node
<
E
>
last
;
```
<div
align=
"center"
>
<img
src=
"../pics//
5158bc2f-83a6-4351-817e-c9b07f955d76
.png"
/>
</div><br>
<div
align=
"center"
>
<img
src=
"../pics//
49495c95-52e5-4c9a-b27b-92cf235ff5ec
.png"
/>
</div><br>
### 2. ArrayList 与 LinkedList
...
...
@@ -474,7 +477,7 @@ public V put(K key, V value) {
}
```
HashMap 允许插入键为 null 的键值对。
因为无法调用 null 的 hashCode()
,也就无法确定该键值对的桶下标,只能通过强制指定一个桶下标来存放。HashMap 使用第 0 个桶存放键为 null 的键值对。
HashMap 允许插入键为 null 的键值对。
但是因为无法调用 null 的 hashCode() 方法
,也就无法确定该键值对的桶下标,只能通过强制指定一个桶下标来存放。HashMap 使用第 0 个桶存放键为 null 的键值对。
```
java
private
V
putForNullKey
(
V
value
)
{
...
...
@@ -601,10 +604,10 @@ static int indexFor(int h, int length) {
| 参数 | 含义 |
| :--: | :-- |
| capacity | table 的容量大小,默认为 16
,
需要注意的是 capacity 必须保证为 2 的 n 次方。|
| capacity | table 的容量大小,默认为 16
。
需要注意的是 capacity 必须保证为 2 的 n 次方。|
| size | table 的实际使用量。 |
| threshold | size 的临界值,size 必须小于 threshold,如果大于等于,就必须进行扩容操作。 |
| load
_factor | 装载因子,table 能够使用的比例,threshold = capacity
*
load_f
actor。|
| load
Factor | 装载因子,table 能够使用的比例,threshold = capacity
*
loadF
actor。|
```
java
static
final
int
DEFAULT_INITIAL_CAPACITY
=
16
;
...
...
@@ -851,7 +854,7 @@ public int size() {
### 3. JDK 1.8 的改动
JDK 1.7 使用分段锁机制来实现并发更新操作,核心类为 Segment,它继承自重入锁 ReentrantLock,并发
程
度与 Segment 数量相等。
JDK 1.7 使用分段锁机制来实现并发更新操作,核心类为 Segment,它继承自重入锁 ReentrantLock,并发度与 Segment 数量相等。
JDK 1.8 使用了 CAS 操作来支持更高的并发度,在 CAS 操作失败时使用内置锁 synchronized。
...
...
@@ -867,7 +870,7 @@ JDK 1.8 使用了 CAS 操作来支持更高的并发度,在 CAS 操作失败
public
class
LinkedHashMap
<
K
,
V
>
extends
HashMap
<
K
,
V
>
implements
Map
<
K
,
V
>
```
内存维护了一个双向
循环
链表,用来维护插入顺序或者 LRU 顺序。
内存维护了一个双向链表,用来维护插入顺序或者 LRU 顺序。
```
java
/**
...
...
@@ -881,13 +884,13 @@ transient LinkedHashMap.Entry<K,V> head;
transient
LinkedHashMap
.
Entry
<
K
,
V
>
tail
;
```
顺序使用 accessOrder 来决定
,默认为 false,此时使用的是插入顺序。
accessOrder 决定了顺序
,默认为 false,此时使用的是插入顺序。
```
java
final
boolean
accessOrder
;
```
LinkedHashMap 最重要的是以下用于
记录
顺序的函数,它们会在 put、get 等方法中调用。
LinkedHashMap 最重要的是以下用于
维护
顺序的函数,它们会在 put、get 等方法中调用。
```
java
void
afterNodeAccess
(
Node
<
K
,
V
>
p
)
{
}
...
...
@@ -896,7 +899,7 @@ void afterNodeInsertion(boolean evict) { }
### afterNodeAccess()
当一个
Node 被访问时,如果 accessOrder 为 true,会将它
移到链表尾部。也就是说指定为 LRU 顺序之后,在每次访问一个节点时,会将这个节点移到链表尾部,保证链表尾部是最近访问的节点,那么链表首部就是最近最久未使用的节点。
当一个
节点被访问时,如果 accessOrder 为 true,则会将 该节点
移到链表尾部。也就是说指定为 LRU 顺序之后,在每次访问一个节点时,会将这个节点移到链表尾部,保证链表尾部是最近访问的节点,那么链表首部就是最近最久未使用的节点。
```
java
void
afterNodeAccess
(
Node
<
K
,
V
>
e
)
{
// move node to last
...
...
@@ -951,7 +954,11 @@ protected boolean removeEldestEntry(Map.Entry<K,V> eldest) {
### LRU 缓存
以下是使用 LinkedHashMap 实现的一个 LRU 缓存,设定最大缓存空间 MAX_ENTRIES 为 3。使用 LinkedHashMap 的构造函数将 accessOrder 设置为 true,开启 LUR 顺序。覆盖 removeEldestEntry() 方法实现,在节点多于 MAX_ENTRIES 就会将最近最久未使用的数据移除。
以下是使用 LinkedHashMap 实现的一个 LRU 缓存:
-
设定最大缓存空间 MAX_ENTRIES 为 3;
-
使用 LinkedHashMap 的构造函数将 accessOrder 设置为 true,开启 LUR 顺序;
-
覆盖 removeEldestEntry() 方法实现,在节点多于 MAX_ENTRIES 就会将最近最久未使用的数据移除。
```
java
class
LRUCache
<
K
,
V
>
extends
LinkedHashMap
<
K
,
V
>
{
...
...
@@ -1002,7 +1009,9 @@ Tomcat 中的 ConcurrentCache 就使用了 WeakHashMap 来实现缓存功能。
ConcurrentCache 采取的是分代缓存:
-
经常使用的对象放入 eden 中,eden 使用 ConcurrentHashMap 实现,不用担心会被回收(伊甸园);
-
不常用的对象放入 longterm,longterm 使用 WeakHashMap 实现,用来存放比较老的对象,这些老对象会被垃圾收集器回收。
-
不常用的对象放入 longterm,longterm 使用 WeakHashMap 实现,这些老对象会被垃圾收集器回收。
-
当调用 get() 方法时,会先从 eden 区获取,如果没有找到的话再到 longterm 获取,当从 longterm 获取到就把对象放入 eden 中,保证频繁被访问的节点不容易被回收。
-
当调用 put() 方法时,如果缓存当前容量大小超过了 size,那么就将 eden 中的所有对象都放入 longterm 中,利用虚拟机回收掉一部分不经常使用的对象。
```
java
public
final
class
ConcurrentCache
<
K
,
V
>
{
...
...
@@ -1039,6 +1048,90 @@ public final class ConcurrentCache<K, V> {
}
```
# 附录
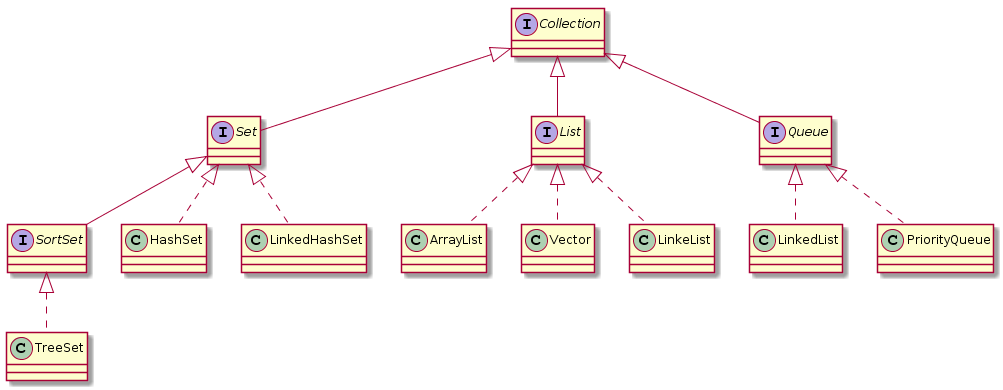
Collection 绘图源码:
```
@startuml
interface Collection
interface Set
interface List
interface Queue
interface SortSet
class HashSet
class LinkedHashSet
class TreeSet
class ArrayList
class Vector
class LinkedList
class PriorityQueue
Collection <|-- Set
Collection <|-- List
Collection <|-- Queue
Set <|-- SortSet
Set <|.. HashSet
Set <|.. LinkedHashSet
SortSet <|.. TreeSet
List <|.. ArrayList
List <|.. Vector
List <|.. LinkeList
Queue <|.. LinkedList
Queue <|.. PriorityQueue
@enduml
```
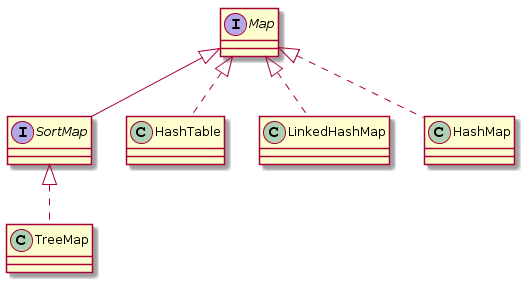
Map 绘图源码
```
@startuml
interface Map
interface SortMap
class HashTable
class LinkedHashMap
class HashMap
class TreeMap
Map <|.. HashTable
Map <|.. LinkedHashMap
Map <|.. HashMap
Map <|-- SortMap
SortMap <|.. TreeMap
@enduml
```
迭代器类图
```
@startuml
interface Iterable
interface Collection
interface List
interface Set
interface Queue
interface Iterator
interface ListIterator
Iterable <|-- Collection
Collection <|.. List
Collection <|.. Set
Collection <|-- Queue
Iterator <-- Iterable
Iterator <|.. ListIterator
ListIterator <-- List
@enduml
```
# 参考资料
...
...
notes/算法.md
浏览文件 @
288fb85d
...
...
@@ -2050,7 +2050,7 @@ public class SparseVector {
如果只有一个圆盘,那么只需要进行一次移动操作。
从上面的讨论可以知道,a
<sub>
n
</sub>
= 2
*
a
<sub>
n-1
</sub>
+ 1,显然
a
<sub>
n
</sub>
= 2
<sup>
n
</sup>
- 1,n
圆盘需要移动 2
<sup>
n
</sup>
- 1 次。
从上面的讨论可以知道,a
<sub>
n
</sub>
= 2
*
a
<sub>
n-1
</sub>
+ 1,显然
a
<sub>
n
</sub>
= 2
<sup>
n
</sup>
- 1,n 个
圆盘需要移动 2
<sup>
n
</sup>
- 1 次。
<div
align=
"center"
>
<img
src=
"../pics//54f1e052-0596-4b5e-833c-e80d75bf3f9b.png"
width=
"300"
/>
</div><br>
...
...
pics/49495c95-52e5-4c9a-b27b-92cf235ff5ec.png
0 → 100644
浏览文件 @
288fb85d
10.0 KB
pics/NP4z3i8m38Ntd28NQ4_0KCJ2q044Oez.png
0 → 100644
浏览文件 @
288fb85d
22.0 KB
pics/SoWkIImgAStDuUBAp2j9BKfBJ4vLy0G.png
0 → 100644
浏览文件 @
288fb85d
14.0 KB
pics/SoWkIImgAStDuUBAp2j9BKfBJ4vLy4q.png
0 → 100644
浏览文件 @
288fb85d
12.0 KB
编辑
预览
Markdown
is supported
0%
请重试
或
添加新附件
.
添加附件
取消
You are about to add
0
people
to the discussion. Proceed with caution.
先完成此消息的编辑!
取消
想要评论请
注册
或
登录
{kind=link}
{kind=link}
{kind=link}
{kind=link}