
Merge branch 'dygraph' of https://github.com/PaddlePaddle/PaddleOCR into table_pr
Showing
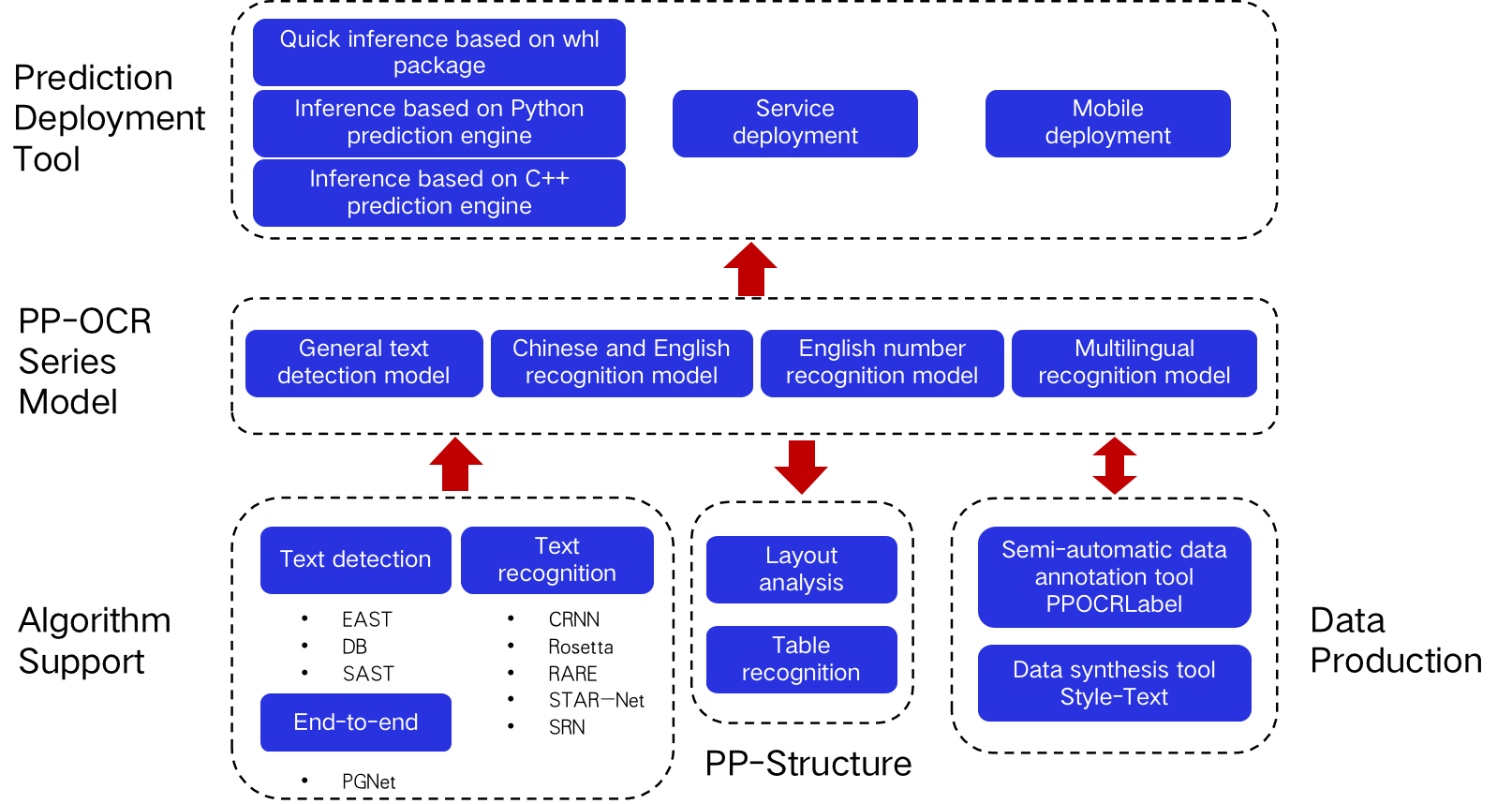
doc/overview_en.png
已删除
100644 → 0
{kind=link}
144.4 KB
doc/ppocr_v3/svtr_tiny.jpg
已删除
100644 → 0
{kind=link}

323.6 KB
ppstructure/layout/README.md
0 → 100644
此差异已折叠。
{kind=link}
2.6 KB
{kind=link}
2.8 KB
{kind=link}
2.4 KB
{kind=link}
2.5 KB
ppstructure/pdf2word/pdf2word.md
0 → 100644
ppstructure/pdf2word/pdf2word.py
0 → 100644