Skip to content
体验新版
项目
组织
正在加载...
登录
切换导航
打开侧边栏
s920243400
PaddleDetection
提交
8792ad03
P
PaddleDetection
项目概览
s920243400
/
PaddleDetection
与 Fork 源项目一致
Fork自
PaddlePaddle / PaddleDetection
通知
2
Star
0
Fork
0
代码
文件
提交
分支
Tags
贡献者
分支图
Diff
Issue
0
列表
看板
标记
里程碑
合并请求
0
Wiki
0
Wiki
分析
仓库
DevOps
项目成员
Pages
P
PaddleDetection
项目概览
项目概览
详情
发布
仓库
仓库
文件
提交
分支
标签
贡献者
分支图
比较
Issue
0
Issue
0
列表
看板
标记
里程碑
合并请求
0
合并请求
0
Pages
分析
分析
仓库分析
DevOps
Wiki
0
Wiki
成员
成员
收起侧边栏
关闭侧边栏
动态
分支图
创建新Issue
提交
Issue看板
提交
8792ad03
编写于
9月 14, 2017
作者:
H
Helin Wang
浏览文件
操作
浏览文件
下载
电子邮件补丁
差异文件
Design Doc: Distributed Training Architecture
上级
253d3c49
变更
15
隐藏空白更改
内联
并排
Showing
15 changed file
with
221 addition
and
122 deletion
+221
-122
doc/design/fully_static_graph.md
doc/design/fully_static_graph.md
+0
-122
doc/design/refactor/distributed_architecture.md
doc/design/refactor/distributed_architecture.md
+221
-0
doc/design/refactor/parameter_server.md
doc/design/refactor/parameter_server.md
+0
-0
doc/design/refactor/src/compiler.graffle
doc/design/refactor/src/compiler.graffle
+0
-0
doc/design/refactor/src/compiler.png
doc/design/refactor/src/compiler.png
+0
-0
doc/design/refactor/src/dist-graph.graffle
doc/design/refactor/src/dist-graph.graffle
+0
-0
doc/design/refactor/src/dist-graph.png
doc/design/refactor/src/dist-graph.png
+0
-0
doc/design/refactor/src/distributed_architecture.graffle
doc/design/refactor/src/distributed_architecture.graffle
+0
-0
doc/design/refactor/src/distributed_architecture.png
doc/design/refactor/src/distributed_architecture.png
+0
-0
doc/design/refactor/src/local-graph.graffle
doc/design/refactor/src/local-graph.graffle
+0
-0
doc/design/refactor/src/local-graph.png
doc/design/refactor/src/local-graph.png
+0
-0
doc/design/refactor/src/local_architecture.graffle
doc/design/refactor/src/local_architecture.graffle
+0
-0
doc/design/refactor/src/local_architecture.png
doc/design/refactor/src/local_architecture.png
+0
-0
doc/design/refactor/src/paddle-compile.graffle
doc/design/refactor/src/paddle-compile.graffle
+0
-0
doc/design/refactor/src/paddle-compile.png
doc/design/refactor/src/paddle-compile.png
+0
-0
未找到文件。
doc/design/fully_static_graph.md
已删除
100644 → 0
浏览文件 @
253d3c49
# Design Doc: Fully Static Graph
## Abstract
We propose the
*fully static graph*
rule: training and inference must
be fully specified by the static graph. This means training and
inference should be able to run solely on the cpp core (no Python
involved), everything should be implemented as an OP.
The user can still use Python to achieve the same result for
convenience when experimenting locally, but the distributed training
will not support Python.
## Background
There are two paradigms for expressing the computation graph: dynamic
and static. The dynamic paradigm constructs the graph on the fly:
every time
`eval`
is called, a new graph is created. The static
paradigm constructs the graph first, and then calls
`eval`
. There is
no new graph created each time
`eval`
is called.
The dynamic graph has the advantage of being flexible but is highly
dependent on the host language (most commonly Python). The static
graph is not as flexible, but more optimization can be done since the
graph is known before computing happens. PaddlePaddle is using the
static graph approach since we are focused on production deployment
and cluster training, efficiency is the key.
This design doc is trying to address an important question for the
static graph approach: should the training logic be fully specified by
the static graph?
For example, it's common to control the graph evaluation from Python:
```
Python
for i in range(10000):
paddle.eval(train_op)
```
In the above example: the training logic is not fully specified by the
graph: Python still take the control of the training logic.
## Fully Static Graph
The training logic should be fully specified by the graph (but we
still support controlling the graph evaluation from Python). Because
Python adds complication for distributed training:
-
The distributed training engine needs to place the computation graph
onto different nodes, and add communication OPs for data across node
boundaries. They are very hard to do if the training logic is not
fully specified by the graph.
-
For fault recovery, every runtime state needs to be saved. But the
state in Python code (such as training loop index and data reader
position) could not be saved.
-
Allowing executing arbitrary Python code on Paddle Cloud make
training data safety very hard if not impossible to control.
### Benefits
-
A clear separation between graph declaration (current using Python)
and graph execution. It's easier for us to add a new language
binding (or invent our own deep learning graph specification
language).
-
Local or distributed graph execution is easier to optimize.
-
Much easier to ensure training data safety on Paddle Cloud.
### Example
To give a concrete example, for loop is essential for the training:
with every loop, a new mini-batch is fed into the training
system. Under the fully static graph rule, we
**must**
implement the for
loop as an OP:
```
Python
# pseudo code, we need to discuss the for loop interface
i = pd.Variable(0)
optimizer = paddle.op.Adam()
# specify the input file as the argument, or
# leave blank and specify using config when running on Paddle Cloud
input = paddle.op.recordIO("/home/data/input.recordio")
q_x, q_y = input[0], input[1]
loss = pd.op.square(pd.op.sub(pd.op.add(pd.op.mul(x, w), b), y))
def cond(i):
return i < 10000
with pd.for_loop(cond, [i]) as loop
# Dequeue a new example each iteration.
x = q_x.dequeue()
y = q_y.dequeue()
optimizer.minimize(loss)
pd.add(i, 1)
# or paddle.save_target(loop, "job.bin") and
# submit the saved file to Paddle Cloud.
paddle.eval(loop)
```
The above code can run on both locally and on Paddle Cloud.
For user's convenience, he can use the Python for loop:
```
Python
optimizer = paddle.op.Adam()
input = paddle.op.recordIO("/home/data/input.recordio")
q_x, q_y = input[0], input[1]
x = q_x.dequeue()
y = q_y.dequeue()
loss = pd.op.square(pd.op.sub(pd.op.add(pd.op.mul(x, w), b), y))
train_op = optimizer.minimize(loss)
for i in range(10000):
paddle.eval(train_op)
```
The above code can only run locally.
doc/design/refactor/distributed_architecture.md
0 → 100644
浏览文件 @
8792ad03
# Design Doc: Distributed Training Architecture
## Abstract
PaddlePaddle v0.10.0 uses the "trainer-parameter server"
architecture. We run multiple replicated instances of trainers (runs
the same code written by the user) and parameter servers for
distributed training. This architecture served us well, but has some
limitations:
1.
Need to write special code to handle tasks which should only be run
by a single trainer. E.g., initializing model and saving model.
2.
Model parallelism is hard: need to write if-else branches conditioned
on the trainer ID to partition model onto each trainer, and manually
write the inter-model-shard communication code.
3.
The user can not directly specify the parameter update rule: need
to modify the parameter server C++ code and compile a new
binary. This adds complication for researchers: A lot of extra
effort is required. Besides, the training job submission program
may not allow running arbitrary binaries.
This design doc discusses PaddlePaddle's new distributed training
architecture that addresses the above limitations.
## Analysis
We will assume the user writes the trainer program by Python, the same
analysis holds if the trainer program is written in C++.
### Limitation 1
If we look at the Python code that the user writes, there are two
kinds of functionalities:
-
The training logic such as load / save model and print log.
-
The neural network definition such as the definition of the data
layer, the fully connected layer, the cost function and the
optimizer.
When we training with PaddlePaddle v0.10.0 distributedly, multiple
replicated Python instances are running on different nodes: both the
training logic and the neural network computation is replicated.
The tasks that should only run once all belong to the training logic,
if we only replicate the neural network computation, but do
**not**
replicate the training logic, the limitation could be solved.
### Limitation 2
Model parallelism means running a single model on multiple nodes by
partitioning the model onto different nodes and managing the
inter-model-shard communications.
PaddlePaddle should be able to modify the nerual network computation
definition to support model parallelism automatically. However, the
computation is only specified in Python code, and PaddlePaddle can not
modify Python code.
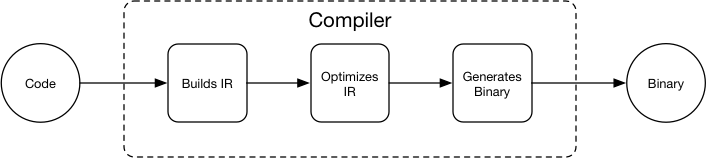
Just like compiler uses a intermediate representation (IR) so that
programmer does not need to manually optimize their code in most of
the cases - the compiler will optimize the IR:
<img
src=
"src/compiler.png"
/>
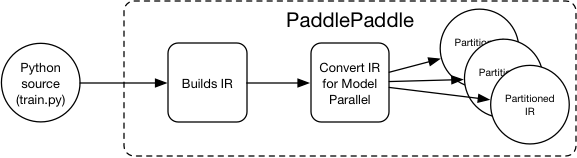
We can have our own IR too: PaddlePaddle can support model parallel by
converting the IR so the user no longer need to manually do it in
Python:
<img
src=
"src/paddle-compile.png"
/>
The IR for PaddlePaddle after refactor is called
`Block`
, it specifies
the computation dependency graph and the variables used in the
computation.
### Limitation 3
The user can not directly specify the parameter update rule for the
parameter server because the parameter server does not use the same
computation definition as the trainer. Instead, the update rule is
baked in the parameter server. The user can not specify the update
rule in the same way of specifying the trainer computation.
This could be fixed by making the parameter server run the same
computation definition as the trainer. For a detailed explanation,
please
see
[
Design Doc: Operation Graph Based Parameter Server
](
./dist_train.md
)
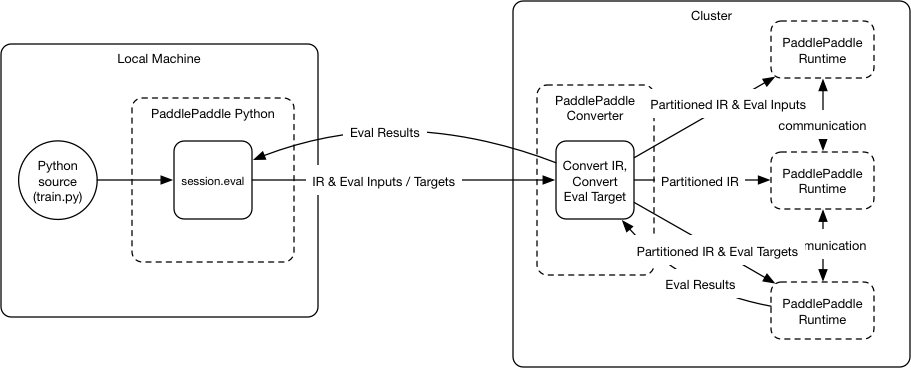
## Distributed Training Architecture
The new distributed training architecture can address the above
limitations. Below is the illustration:
<img
src=
"src/distributed_architecture.png"
/>
The architecture includes major components:
*PaddlePaddle Python*
,
*PaddlePaddle converter*
and
*PaddlePaddle runtime*
:
### PaddlePaddle Python
PaddlePaddle Python is the Python library that user's Python trainer
invoke to build the neural network topology, start training, etc.
```
Python
paddle.init()
input = paddle.op.recordIO("/home/data/mnist.recordio") # file stored on the cluster
img, label = input[0], input[1]
hidden = paddle.layer.fc(input=img, size=200, act=paddle.activation.Tanh())
prediction = paddle.layer.fc(input=img, size=10, act=paddle.activation.Softmax())
cost = paddle.layer.classification_cost(input=prediction, label=label)
optimizer = paddle.optimizer.SGD(cost, learning_rate=0.01)
session = paddle.session.NewRemote(num_trainer=3, num_ps=2, GPU_per_trainer=1)
for i in range(1000):
_, cost_val = session.eval(target=[cost, optimizer])
print cost_val
```
The code above is a typical Python trainer code, the neural network
topology is built using helper functions such as
`paddle.layer.fc`
. The training is done by calling
`session.eval`
iteratively.
#### session.eval
As shown in the graph,
`session.eval`
sends the IR and the evaluation
inputs/targets to the PaddlePaddle cluster for evaluation. The
targets can be any variable in the computation graph. When the target
is the
`optimizer`
variable, the neural network will be optimized
once. When the target is the
`cost`
variable,
`session.eval`
returns
the cost value.
For more information about
`Session`
, please
see
[
Design Doc: Session
](
./session.md
)
.
### PaddlePaddle Converter
PaddlePaddle converter automatically converts the IR in the request
(IR and evaluation inputs/targets) from PaddlePaddle Python to new
partitioned IRs and dispatch the new IRs and evaluation inputs/targets
to different PaddlePaddle runtimes. Below are the steps:
1.
Add
`feed`
OP that feeds the eval inputs, and
`fetch`
OP that
fetches the eval targets to the IR.
1.
Extract a new computation (sub)graph with
`feed`
and
`fetch`
OP as
the boundary. The runtime does not need to run the OP that is not
dependent by the
`fetch`
OP.
1.
Optimizes the computation graph.
1.
Place the OPs in the graph onto different devices on different
PaddlePaddle runtime according to a placement algorithm and device
constraint specified by the user.
1.
Partition the graph according to runtime boundaries and add
`send`
/
`recv`
OP pair on the runtime boundaries.
1.
Dispatch the partitioned graph to different PaddlePaddle runtimes.
1.
PaddlePaddle runtimes with the
`fetch`
OP reports evaluation
results back to the converter, the convert reports the evaluation
results back to the PaddlePaddle Python.
The output IRs will be cached to optimize the conversion latency.
#### Placement Algorithm
Our first implementation will only support "trainer-parameter server"
placement: the parameters, initializers, and optimizers are placed on
the PaddlePaddle runtimes with the parameter server role. And
everything else will be placed on the PaddlePaddle runtimes with the
trainer role. This has the same functionality of our
"trainer-parameter server" architecture of PaddlePaddle v0.10.0, but
is more general and flexible.
In the future, we will implement the general placement algorithm,
which makes placements according to the input IR, and a model of
device computation time and device communication time. Model
parallelism requires the general placement algorithm.
### PaddlePaddle Runtime
The PaddlePaddle runtime owns multiple devices (e.g., CPUs, GPUs) and
runs the IR. The runtime does not need to do OP placement since it's
already done by the converter.
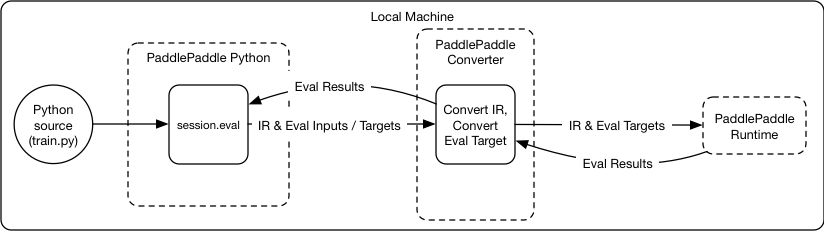
### Local Training Architecture
The local training architecture will be the same as the distributed
training architecture, the differences are everything runs locally,
and there is just one PaddlePaddle runtime:
<img
src=
"src/local_architecture.png"
/>
### Training Data
In PaddlePaddle v0.10.0, training data is typically read
with
[
data reader
](
../reader/README.md
)
from Python. This approach is
no longer efficient when training distributedly since the Python
process no longer runs on the same node with the trainer processes,
the Python reader will need to read from the distributed filesystem
(assuming it has the access) and send to the trainers, doubling the
network traffic.
When doing distributed training, the user can still use Python data
reader: the training data are sent with
`session.eval`
. However should
be used for debugging purpose only. The users are encouraged to use
the read data OPs.
## References:
[
1] [TensorFlow: Large-Scale Machine Learning on Heterogeneous Distributed Systems
](
https://static.googleusercontent.com/media/research.google.com/en//pubs/archive/45166.pdf
)
[
2] [TensorFlow: A System for Large-Scale Machine Learning
](
https://www.usenix.org/system/files/conference/osdi16/osdi16-abadi.pdf
)
doc/design/
ops/dist_train
.md
→
doc/design/
refactor/parameter_server
.md
浏览文件 @
8792ad03
文件已移动
doc/design/refactor/src/compiler.graffle
0 → 100644
浏览文件 @
8792ad03
文件已添加
doc/design/refactor/src/compiler.png
0 → 100644
浏览文件 @
8792ad03
15.5 KB
doc/design/
ops
/src/dist-graph.graffle
→
doc/design/
refactor
/src/dist-graph.graffle
浏览文件 @
8792ad03
文件已移动
doc/design/
ops
/src/dist-graph.png
→
doc/design/
refactor
/src/dist-graph.png
浏览文件 @
8792ad03
文件已移动
doc/design/refactor/src/distributed_architecture.graffle
0 → 100644
浏览文件 @
8792ad03
文件已添加
doc/design/refactor/src/distributed_architecture.png
0 → 100644
浏览文件 @
8792ad03
46.5 KB
doc/design/
ops
/src/local-graph.graffle
→
doc/design/
refactor
/src/local-graph.graffle
浏览文件 @
8792ad03
文件已移动
doc/design/
ops
/src/local-graph.png
→
doc/design/
refactor
/src/local-graph.png
浏览文件 @
8792ad03
文件已移动
doc/design/refactor/src/local_architecture.graffle
0 → 100644
浏览文件 @
8792ad03
文件已添加
doc/design/refactor/src/local_architecture.png
0 → 100644
浏览文件 @
8792ad03
28.3 KB
doc/design/refactor/src/paddle-compile.graffle
0 → 100644
浏览文件 @
8792ad03
文件已添加
doc/design/refactor/src/paddle-compile.png
0 → 100644
浏览文件 @
8792ad03
19.7 KB
编辑
预览
Markdown
is supported
0%
请重试
或
添加新附件
.
添加附件
取消
You are about to add
0
people
to the discussion. Proceed with caution.
先完成此消息的编辑!
取消
想要评论请
注册
或
登录
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}