update doc, test=document_fix (#3049)
* update doc, test=document_fix
Co-authored-by: NGuanghua Yu <742925032@qq.com>
Showing
deploy/cpp/docs/linux_build.md
100644 → 100755
deploy/cpp/docs/windows_vs2019_build.md
100644 → 100755
docs/images/roadsign_yml.png
0 → 100644
{kind=link}

101.9 KB
docs/images/yaml_show.png
0 → 100644
{kind=link}
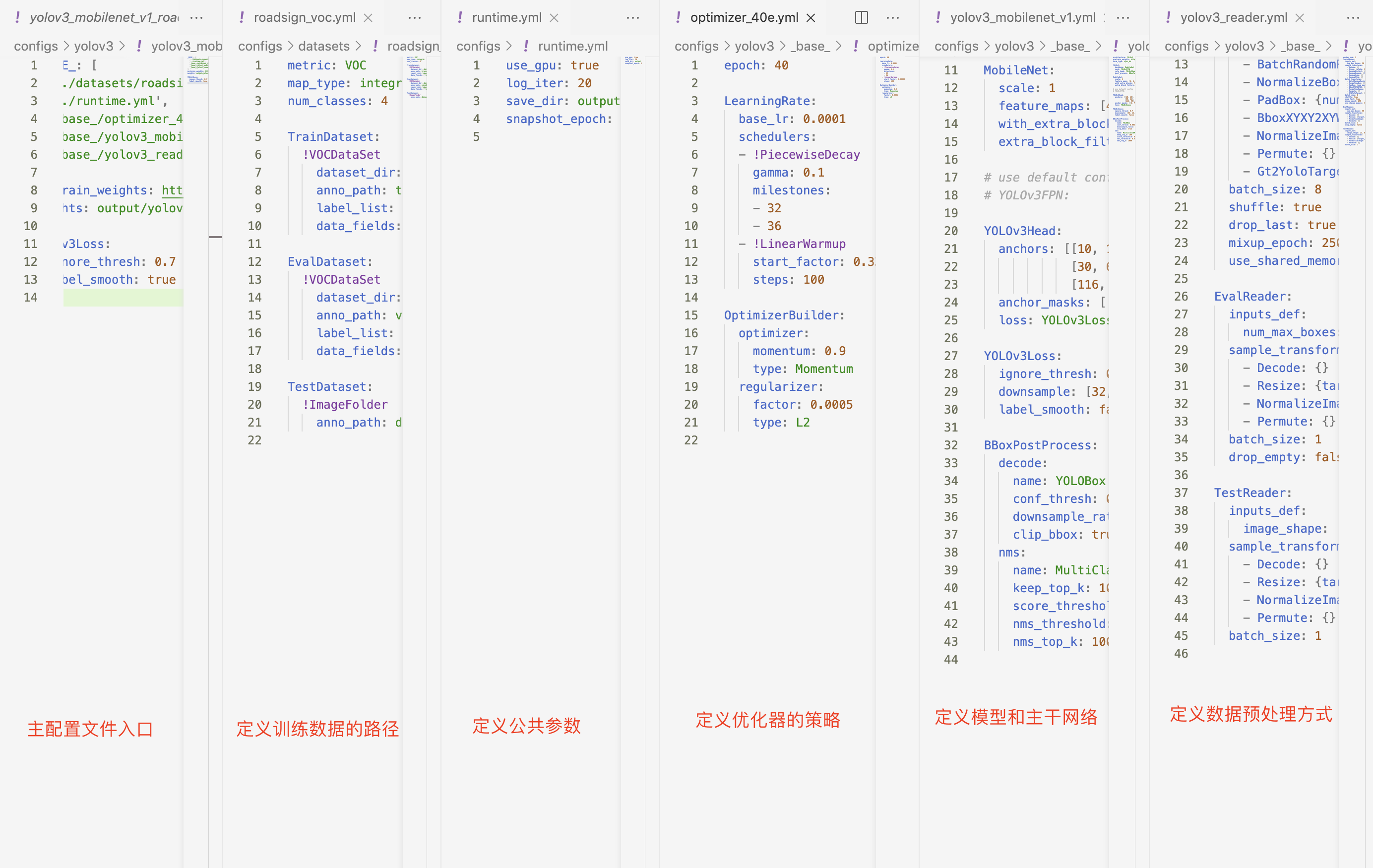
668.2 KB