diff --git a/README_cn.md b/README_cn.md
index 574cd69138fa141f959c99deda791b1f05095948..2e454e83c0771c15b5b9543c2ca16bc1c6147ff2 100644
--- a/README_cn.md
+++ b/README_cn.md
@@ -191,9 +191,8 @@ PaddleDetection模块化地实现了多种主流目标检测算法,提供了
### 入门教程
- [安装说明](docs/tutorials/INSTALL_cn.md)
-- [快速开始](docs/tutorials/QUICK_STARTED_cn.md)
-- [如何准备数据](docs/tutorials/PrepareDataSet.md)
-- [训练/评估/预测流程](docs/tutorials/GETTING_STARTED_cn.md)
+- [数据准备](docs/tutorials/PrepareDataSet.md)
+- [30分钟上手PaddleDetcion](docs/tutorials/GETTING_STARTED_cn.md)
### 进阶教程
@@ -202,18 +201,19 @@ PaddleDetection模块化地实现了多种主流目标检测算法,提供了
- [PP-YOLO参数说明](docs/tutorials/config_annotation/ppyolo_r50vd_dcn_1x_coco_annotation.md)
- 模型压缩(基于[PaddleSlim](https://github.com/PaddlePaddle/PaddleSlim))
- [剪裁/量化/蒸馏教程](configs/slim)
+
- [推理部署](deploy/README.md)
- [模型导出教程](deploy/EXPORT_MODEL.md)
- - [Python端推理部署](deploy/python)
- - [C++端推理部署](deploy/cpp)
- - [服务端部署](deploy/serving)
- - [移动端部署](deploy/lite)
+ - [PaddleInference部署](deploy/README.md)
+ - [Python端推理部署](deploy/python)
+ - [C++端推理部署](deploy/cpp)
+ - [PaddleLite部署](deploy/serving)
+ - [PaddleServing部署](deploy/lite)
- [推理benchmark](deploy/BENCHMARK_INFER.md)
- 进阶开发
- [数据处理模块](docs/advanced_tutorials/READER.md)
- [新增检测模型](docs/advanced_tutorials/MODEL_TECHNICAL.md)
-
## 模型库
- 通用目标检测:
diff --git a/deploy/EXPORT_MODEL.md b/deploy/EXPORT_MODEL.md
index 15685e80c67b8544e9358c88ef6b8d983dfa5b82..91f34b5860d6384baf773e71a39ffa4ec773dee6 100644
--- a/deploy/EXPORT_MODEL.md
+++ b/deploy/EXPORT_MODEL.md
@@ -3,17 +3,18 @@
## 一、模型导出
本章节介绍如何使用`tools/export_model.py`脚本导出模型。
### 1、导出模输入输出说明
-- `PaddleDetection`中输入变量以及输入形状如下:
-| 输入名称 | 输入形状 | 表示含义 |
-| :---------: | ----------- | ---------- |
-| image | [None, 3, H, W] | 输入网络的图像,None表示batch维度,如果输入图像大小为变长,则H,W为None |
-| im_shape | [None, 2] | 图像经过resize后的大小,表示为H,W, None表示batch维度 |
-| scale_factor | [None, 2] | 输入图像大小比真实图像大小,表示为scale_y, scale_x |
+- 输入变量以及输入形状如下:
+
+ | 输入名称 | 输入形状 | 表示含义 |
+ | :---------: | ----------- | ---------- |
+ | image | [None, 3, H, W] | 输入网络的图像,None表示batch维度,如果输入图像大小为变长,则H,W为None |
+ | im_shape | [None, 2] | 图像经过resize后的大小,表示为H,W, None表示batch维度 |
+ | scale_factor | [None, 2] | 输入图像大小比真实图像大小,表示为scale_y, scale_x |
**注意**具体预处理方式可参考配置文件中TestReader部分。
-- PaddleDetection`中动转静导出模型输出统一为:
+- PaddleDetection中动转静导出模型输出统一为:
- bbox, NMS的输出,形状为[N, 6], 其中N为预测框的个数,6为[class_id, score, x1, y1, x2, y2]。
- bbox\_num, 每张图片对应预测框的个数,例如batch_size为2,输出为[N1, N2], 表示第一张图包含N1个预测框,第二张图包含N2个预测框,并且预测框的总个数和NMS输出的第一维N相同
diff --git a/deploy/README.md b/deploy/README.md
index 3987ace763260471922684d31b3c5588c2512f26..97db43e906a087951f3568e47dcfde9d8a4de9ac 100644
--- a/deploy/README.md
+++ b/deploy/README.md
@@ -1,62 +1,53 @@
# PaddleDetection 预测部署
-目前支持的部署方式有:
-- `Paddle Inference预测库`部署:
- - `Python`语言部署,支持`CPU`、`GPU`和`XPU`环境,参考文档[python部署](python/README.md)。
- - `C++`语言部署 ,支持`CPU`、`GPU`和`XPU`环境,支持在`Linux`、`Windows`系统下部署,支持`NV Jetson`嵌入式设备上部署。请参考文档[C++部署](cpp/README.md)。
- - `TensorRT`加速:请参考文档[TensorRT预测部署教程](TENSOR_RT.md)
-- 服务器端部署:使用[PaddleServing](./serving/README.md)部署。
-- 手机移动端部署:使用[Paddle-Lite](./lite/README.md) 在手机移动端部署。
+PaddleDetection提供了PaddleInference、PaddleServing、PaddleLite多种部署形式,支持服务端、移动端、嵌入式等多种平台,提供了完善的Python和C++部署方案。
+## PaddleDetection支持的部署形式说明
+|形式|语言|教程|设备/平台|
+|-|-|-|-|
+|PaddleInference|Python|已完善|Linux(ARM\X86)、Windows
+|PaddleInference|C++|已完善|Linux(ARM\X86)、Windows|
+|PaddleServing|Python|已完善|Linux(ARM\X86)、Windows|
+|PaddleLite|C++|已完善|Android、IOS、FPGA、RK...
-## 1.模型导出
+
+## 1.Paddle Inference部署
+
+### 1.1 导出模型
使用`tools/export_model.py`脚本导出模型已经部署时使用的配置文件,配置文件名字为`infer_cfg.yml`。模型导出脚本如下:
```bash
# 导出YOLOv3模型
-python tools/export_model.py -c configs/yolov3/yolov3_darknet53_270e_coco.yml -o weights=weights/yolov3_darknet53_270e_coco.pdparams
+python tools/export_model.py -c configs/yolov3/yolov3_mobilenet_v1_roadsign.yml -o weights=output/yolov3_mobilenet_v1_roadsign/best_model.pdparams
```
-预测模型会导出到`output_inference/yolov3_darknet53_270e_coco`目录下,分别为`infer_cfg.yml`, `model.pdiparams`, `model.pdiparams.info`, `model.pdmodel`。
+预测模型会导出到`output_inference/yolov3_mobilenet_v1_roadsign`目录下,分别为`infer_cfg.yml`, `model.pdiparams`, `model.pdiparams.info`, `model.pdmodel`。
+模型导出具体请参考文档[PaddleDetection模型导出教程](EXPORT_MODEL.md)。
+
+### 1.2 使用PaddleInference进行预测
+* Python部署 支持`CPU`、`GPU`和`XPU`环境,支持,windows、linux系统,支持NV Jetson嵌入式设备上部署。参考文档[python部署](python/README.md)
+* C++部署 支持`CPU`、`GPU`和`XPU`环境,支持,windows、linux系统,支持NV Jetson嵌入式设备上部署。参考文档[C++部署](cpp/README.md)
+* PaddleDetection支持TensorRT加速,相关文档请参考[TensorRT预测部署教程](TENSOR_RT.md)
+
+## 2.PaddleServing部署
+### 2.1 导出模型
如果需要导出`PaddleServing`格式的模型,需要设置`export_serving_model=True`:
```buildoutcfg
-python tools/export_model.py -c configs/yolov3/yolov3_darknet53_270e_coco.yml -o weights=weights/yolov3_darknet53_270e_coco.pdparams --export_serving_model=True
+python tools/export_model.py -c configs/yolov3/yolov3_mobilenet_v1_roadsign.yml -o weights=output/yolov3_mobilenet_v1_roadsign/best_model.pdparams --export_serving_model=True
```
预测模型会导出到`output_inference/yolov3_darknet53_270e_coco`目录下,分别为`infer_cfg.yml`, `model.pdiparams`, `model.pdiparams.info`, `model.pdmodel`, `serving_client/`文件夹, `serving_server/`文件夹。
模型导出具体请参考文档[PaddleDetection模型导出教程](EXPORT_MODEL.md)。
-## 2.部署环境准备
-
-- Python预测:在python环境下安装PaddlePaddle环境即可,如需TensorRT预测,在[Paddle Release版本](https://www.paddlepaddle.org.cn/documentation/docs/zh/install/Tables.html#whl-release)中下载合适的wheel包即可。
-
-- C++预测库:请从[这里](https://www.paddlepaddle.org.cn/documentation/docs/zh/guides/05_inference_deployment/inference/build_and_install_lib_cn.html),如果需要使用TensorRT,请下载带有TensorRT编译的预测库。您也可以自行编译,编译过程请参考[Paddle源码编译](https://www.paddlepaddle.org.cn/documentation/docs/zh/install/compile/linux-compile.html)。
-**注意:** Paddle预测库版本需要>=2.0
-
-- PaddleServing部署
- 请选择PaddleServing>0.5.0以上版本,具体可参考[PaddleServing安装文档](https://github.com/PaddlePaddle/Serving/blob/develop/README.md#installation)。
+### 2.2 使用PaddleServing进行预测
+* [安装PaddleServing](https://github.com/PaddlePaddle/Serving/blob/develop/README.md#installation)
+* [使用PaddleServing](./serving/README.md)
-- Paddle-Lite部署
- Paddle-Lite支持OP列表请参考:[Paddle-Lite支持的OP列表](https://paddle-lite.readthedocs.io/zh/latest/source_compile/library.html) ,请跟进所部署模型中使用到的op选择Paddle-Lite版本。
-
-- NV Jetson部署
- Paddle官网提供在NV Jetson平台上已经编译好的预测库,[Paddle NV Jetson预测库](https://www.paddlepaddle.org.cn/documentation/docs/zh/guides/05_inference_deployment/inference/build_and_install_lib_cn.html)。若列表中没有您需要的预测库,您可以在您的平台上自行编译,编译过程请参考[Paddle源码编译](https://www.paddlepaddle.org.cn/documentation/docs/zh/install/compile/linux-compile.html)。
-
-## 3.部署预测
-- Python部署:使用`deploy/python/infer.py`进行预测,可具体参考[python部署文档](python/README.md)。
-```shell
-python deploy/python/infer.py --model_dir=/path/to/models --image_file=/path/to/image --use_gpu=(False/True)
-```
-
-- C++部署,先使用跨平台编译工具`CMake`根据`CMakeLists.txt`生成`Makefile`,支持[Windows](cpp/docs/windows_vs2019_build.md)、[Linux](cpp/docs/linux_build.md)、[NV Jetson](cpp/docs/Jetson_build.md)平台部署,然后进行编译产出可执行文件。可以直接使用`cpp/scripts/build.sh`脚本编译:
-```buildoutcfg
-cd cpp
-sh scripts/build.sh
-```
-- PaddleServing部署请参考,[PaddleServing部署](./serving/README.md)部署。
+## 3.PaddleLite部署
+- [使用PaddleLite部署PaddleDetection模型](./lite/README.md)
+- 详细案例请参考[Paddle-Lite-Demo](https://github.com/PaddlePaddle/Paddle-Lite-Demo)部署。更多内容,请参考[Paddle-Lite](https://github.com/PaddlePaddle/Paddle-Lite)
-- 手机移动端部署,请参考[Paddle-Lite-Demo](https://github.com/PaddlePaddle/Paddle-Lite-Demo)部署。
## 4.Benchmark测试
- 使用导出的模型,运行Benchmark批量测试脚本:
diff --git a/deploy/cpp/README.md b/deploy/cpp/README.md
index c9962bd4a79a325b0575662304498d8dc2f8dc5e..ffa5e251e7913b4af30fa6abe9912c9434af996f 100644
--- a/deploy/cpp/README.md
+++ b/deploy/cpp/README.md
@@ -1,16 +1,20 @@
# C++端预测部署
-## 本教程结构
-[1.说明](#1说明)
-[2.主要目录和文件](#2主要目录和文件)
+## 各环境编译部署教程
+- [Linux 编译部署](docs/linux_build.md)
+- [Windows编译部署(使用Visual Studio 2019)](docs/windows_vs2019_build.md)
+- [NV Jetson编译部署](docs/Jetson_build.md)
-[3.编译部署](#3编译)
+## C++部署总览
+[1.说明](#1说明)
+[2.主要目录和文件](#2主要目录和文件)
-## 1.说明
+
+### 1.说明
本目录为用户提供一个跨平台的`C++`部署方案,让用户通过`PaddleDetection`训练的模型导出后,即可基于本项目快速运行,也可以快速集成代码结合到自己的项目实际应用中去。
@@ -20,7 +24,7 @@
- 高性能,除了`PaddlePaddle`自身带来的性能优势,我们还针对图像检测的特点对关键步骤进行了性能优化
- 支持各种不同检测模型结构,包括`Yolov3`/`Faster_RCNN`/`SSD`等
-## 2.主要目录和文件
+### 2.主要目录和文件
```bash
deploy/cpp
@@ -48,25 +52,3 @@ deploy/cpp
└── cmake # 依赖的外部项目cmake(目前仅有yaml-cpp)
```
-
-## 3.编译部署
-
-### 3.1 导出模型
-请确认您已经基于`PaddleDetection`的[export_model.py](https://github.com/PaddlePaddle/PaddleDetection/blob/dygraph/tools/export_model.py)导出您的模型,并妥善保存到合适的位置。导出模型细节请参考 [导出模型教程](https://github.com/PaddlePaddle/PaddleDetection/tree/dygraph/deploy/EXPORT_MODEL.md)。
-
-模型导出后, 目录结构如下(以`yolov3_darknet`为例):
-```
-yolov3_darknet # 模型目录
-├── infer_cfg.yml # 模型配置信息
-├── model.pdmodel # 模型文件
-├── model.pdiparams.info #模型公用信息
-└── model.pdiparams # 参数文件
-```
-
-预测时,该目录所在的路径会作为程序的输入参数。
-
-### 3.2 编译
-
-仅支持在`Windows`和`Linux`平台编译和使用
-- [Linux 编译指南](docs/linux_build.md)
-- [Windows编译指南(使用Visual Studio 2019)](docs/windows_vs2019_build.md)
diff --git a/deploy/cpp/docs/linux_build.md b/deploy/cpp/docs/linux_build.md
old mode 100644
new mode 100755
index 41a85a7657a6d59529fd7ca0b5b95cab9c6d51b0..8cbea7301ad83da8b3b16eaa148aca2f7576a372
--- a/deploy/cpp/docs/linux_build.md
+++ b/deploy/cpp/docs/linux_build.md
@@ -1,7 +1,7 @@
# Linux平台编译指南
## 说明
-本文档在 `Linux`平台使用`GCC 8.2`测试过,如果需要使用其他G++版本编译使用,则需要重新编译Paddle预测库,请参考: [从源码编译Paddle预测库](https://www.paddlepaddle.org.cn/documentation/docs/zh/develop/advanced_guide/inference_deployment/inference/build_and_install_lib_cn.html)。本文档使用的预置的opencv库是在ubuntu 16.04上用gcc4.8编译的,如果需要在ubuntu 16.04以外的系统环境编译,那么需自行编译opencv库。
+本文档在 `Linux`平台使用`GCC 8.2`测试过,如果需要使用其他G++版本编译使用,则需要重新编译Paddle预测库,请参考: [从源码编译Paddle预测库](https://paddleinference.paddlepaddle.org.cn/user_guides/source_compile.html)。本文档使用的预置的opencv库是在ubuntu 16.04上用gcc4.8编译的,如果需要在ubuntu 16.04以外的系统环境编译,那么需自行编译opencv库。
## 前置条件
* G++ 8.2
@@ -19,7 +19,7 @@
### Step2: 下载PaddlePaddle C++ 预测库 fluid_inference
-PaddlePaddle C++ 预测库针对不同的`CPU`和`CUDA`版本提供了不同的预编译版本,请根据实际情况下载: [C++预测库下载列表](https://www.paddlepaddle.org.cn/documentation/docs/zh/guides/05_inference_deployment/inference/build_and_install_lib_cn.html)
+PaddlePaddle C++ 预测库针对不同的`CPU`和`CUDA`版本提供了不同的预编译版本,请根据实际情况下载: [C++预测库下载列表](https://paddleinference.paddlepaddle.org.cn/user_guides/download_lib.html)
下载并解压后`/root/projects/fluid_inference`目录包含内容为:
diff --git a/deploy/cpp/docs/windows_vs2019_build.md b/deploy/cpp/docs/windows_vs2019_build.md
old mode 100644
new mode 100755
index b8a4902c0938ee2b166356b7c9287290e0883aa7..fd746ba51602b5e6a1af8ab529798e1d4d164397
--- a/deploy/cpp/docs/windows_vs2019_build.md
+++ b/deploy/cpp/docs/windows_vs2019_build.md
@@ -24,7 +24,7 @@ git clone https://github.com/PaddlePaddle/PaddleDetection.git
### Step2: 下载PaddlePaddle C++ 预测库 fluid_inference
-PaddlePaddle C++ 预测库针对不同的`CPU`和`CUDA`版本提供了不同的预编译版本,请根据实际情况下载: [C++预测库下载列表](https://www.paddlepaddle.org.cn/documentation/docs/zh/guides/05_inference_deployment/inference/windows_cpp_inference.html)
+PaddlePaddle C++ 预测库针对不同的`CPU`和`CUDA`版本提供了不同的预编译版本,请根据实际情况下载: [C++预测库下载列表](https://paddleinference.paddlepaddle.org.cn/user_guides/download_lib.html#windows)
解压后`D:\projects\fluid_inference`目录包含内容为:
```
@@ -128,4 +128,4 @@ cd D:\projects\PaddleDetection\deploy\cpp\out\build\x64-Release
## 性能测试
-benchmark请查看[BENCHMARK_INFER](../../BENCHMARK_INFER.md)
+Benchmark请查看[BENCHMARK_INFER](../../BENCHMARK_INFER.md)
diff --git a/deploy/python/README.md b/deploy/python/README.md
index 786756ec4e19dc3af92759280efda0cdf0f23cc1..386c05ce5a7cea97cced987a1de52dd5fdc2053a 100644
--- a/deploy/python/README.md
+++ b/deploy/python/README.md
@@ -14,17 +14,14 @@ PaddleDetection在训练过程包括网络的前向和优化器相关参数,
导出后目录下,包括`infer_cfg.yml`, `model.pdiparams`, `model.pdiparams.info`, `model.pdmodel`四个文件。
-## 2. 基于python的预测
+## 2. 基于Python的预测
+
-### 2.1 安装依赖
-- `PaddlePaddle`的安装: 请点击[官方安装文档](https://paddlepaddle.org.cn/install/quick) 选择适合的版本进行安装,要求PaddlePaddle>=2.0.1以上。
-- 切换到`PaddleDetection`代码库根目录,执行`pip install -r requirements.txt`安装其它依赖。
-### 2.2 执行预测程序
在终端输入以下命令进行预测:
```bash
-python deploy/python/infer.py --model_dir=/path/to/models --image_file=/path/to/image --use_gpu=(False/True)
+python deploy/python/infer.py --model_dir=./inference/yolov3_mobilenet_v1_roadsign --image_file=./demo/road554.png --use_gpu=True
```
参数说明如下:
@@ -48,4 +45,4 @@ python deploy/python/infer.py --model_dir=/path/to/models --image_file=/path/to/
- 参数优先级顺序:`camera_id` > `video_file` > `image_dir` > `image_file`。
- run_mode:fluid代表使用AnalysisPredictor,精度float32来推理,其他参数指用AnalysisPredictor,TensorRT不同精度来推理。
-- 如果安装的PaddlePaddle不支持基于TensorRT进行预测,需要自行编译,详细可参考[预测库编译教程](https://www.paddlepaddle.org.cn/documentation/docs/zh/advanced_usage/deploy/inference/paddle_tensorrt_infer.html)。
+- 如果安装的PaddlePaddle不支持基于TensorRT进行预测,需要自行编译,详细可参考[预测库编译教程](https://paddleinference.paddlepaddle.org.cn/user_guides/source_compile.html)。
diff --git a/docs/images/roadsign_yml.png b/docs/images/roadsign_yml.png
new file mode 100644
index 0000000000000000000000000000000000000000..242bab90bd75f7ab08c7477475222b0b37678c43
Binary files /dev/null and b/docs/images/roadsign_yml.png differ
diff --git a/docs/images/yaml_show.png b/docs/images/yaml_show.png
new file mode 100644
index 0000000000000000000000000000000000000000..b6319752d4f13471f2edc4a357cb9ec51ec90c75
Binary files /dev/null and b/docs/images/yaml_show.png differ
diff --git a/docs/tutorials/GETTING_STARTED_cn.md b/docs/tutorials/GETTING_STARTED_cn.md
index 152d6d7a35da79cc4ab32c28543dced3df653988..c2379e08c0ef84d2e446fa2ed8ddb7524b8db031 100644
--- a/docs/tutorials/GETTING_STARTED_cn.md
+++ b/docs/tutorials/GETTING_STARTED_cn.md
@@ -1,144 +1,251 @@
[English](GETTING_STARTED.md) | 简体中文
-# 入门使用
+# 30分钟快速上手PaddleDetection
-## 安装
+PaddleDetection作为成熟的目标检测开发套件,提供了从数据准备、模型训练、模型评估、模型导出到模型部署的全流程。在这个章节里面,我们以路标检测数据集为例,提供快速上手PaddleDetection的流程。
-关于安装配置运行环境,请参考[安装指南](INSTALL_cn.md)
+## 1 安装
+关于安装配置运行环境,请参考[安装指南](INSTALL_cn.md)
+在本演示案例中,假定用户将PaddleDetection的代码克隆并放置在`/home/paddle`目录中。用户执行的命令操作均在`/home/paddle/PaddleDetection`目录下完成
-## 准备数据
+## 2 准备数据
+目前PaddleDetection支持:COCO VOC WiderFace, MOT四种数据格式。
- 首先按照[准备数据文档](PrepareDataSet.md) 准备数据。
- 然后设置`configs/datasets`中相应的coco或voc等数据配置文件中的数据路径。
+- 在本项目中,我们使用路标识别数据集
+ ```bash
+python dataset/roadsign_voc/download_roadsign_voc.py
+```
+- 下载后的数据格式为
+```
+ ├── download_roadsign_voc.py
+ ├── annotations
+ │ ├── road0.xml
+ │ ├── road1.xml
+ │ | ...
+ ├── images
+ │ ├── road0.png
+ │ ├── road1.png
+ │ | ...
+ ├── label_list.txt
+ ├── train.txt
+ ├── valid.txt
+```
+
+## 3 配置文件改动和说明
+我们使用`configs/yolov3/yolov3_mobilenet_v1_roadsign`配置进行训练。
+在静态图版本下,一个模型往往可以通过两个配置文件(一个主配置文件、一个reader的读取配置)实现,在PaddleDetection 2.0后续版本,采用了模块解耦设计,用户可以组合配置模块实现检测器,并可自由修改覆盖各模块配置,如下图所示
+
+
+ +
+
+
+
配置文件摘要
-## 训练/评估/预测
-PaddleDetection提供了`训练`/`评估`/`预测`等功能,支持通过传入不同可选参数实现特定功能
+从上图看到`yolov3_mobilenet_v1_roadsign.yml`配置需要依赖其他的配置文件。在该例子中需要依赖:
```bash
-# GPU单卡训练
-export CUDA_VISIBLE_DEVICES=0
-python tools/train.py -c configs/faster_rcnn/faster_rcnn_r50_fpn_1x_coco.yml
-# GPU多卡训练
-export CUDA_VISIBLE_DEVICES=0,1,2,3,4,5,6,7
-python -m paddle.distributed.launch --gpus 0,1,2,3,4,5,6,7 tools/train.py -c configs/faster_rcnn/faster_rcnn_r50_fpn_1x_coco.yml
-# GPU评估
-export CUDA_VISIBLE_DEVICES=0
-python tools/eval.py -c configs/faster_rcnn/faster_rcnn_r50_fpn_1x_coco.yml -o weights=https://paddledet.bj.bcebos.com/models/faster_rcnn_r50_fpn_1x_coco.pdparams
-# 预测
-python tools/infer.py -c configs/faster_rcnn/faster_rcnn_r50_fpn_1x_coco.yml --infer_img=demo/000000570688.jpg -o weights=https://paddledet.bj.bcebos.com/models/faster_rcnn_r50_fpn_1x_coco.pdparams
-```
+ roadsign_voc.yml
+ runtime.yml
-### 参数列表
+ optimizer_40e.yml
-以下列表可以通过`--help`查看
+ yolov3_mobilenet_v1.yml
-| FLAG | 支持脚本 | 用途 | 默认值 | 备注 |
-| :----------------------: | :------------: | :---------------: | :--------------: | :-----------------: |
-| -c | ALL | 指定配置文件 | None | **必选**,例如-c configs/faster_rcnn/faster_rcnn_r50_fpn_1x_coco.yml |
-| -o | ALL | 设置或更改配置文件里的参数内容 | None | 相较于`-c`设置的配置文件有更高优先级,例如:`-o use_gpu=False` |
-| --eval | train | 是否边训练边测试 | False | 如需指定,直接`--eval`即可 |
-| -r/--resume_checkpoint | train | 恢复训练加载的权重路径 | None | 例如:`-r output/faster_rcnn_r50_1x_coco/10000` |
-| --slim_config | ALL | 模型压缩策略配置文件 | None | 例如`--slim_config configs/slim/prune/yolov3_prune_l1_norm.yml` |
-| --use_vdl | train/infer | 是否使用[VisualDL](https://github.com/paddlepaddle/visualdl)记录数据,进而在VisualDL面板中显示 | False | VisualDL需Python>=3.5 |
-| --vdl\_log_dir | train/infer | 指定 VisualDL 记录数据的存储路径 | train:`vdl_log_dir/scalar` infer: `vdl_log_dir/image` | VisualDL需Python>=3.5 |
-| --output_eval | eval | 评估阶段保存json路径 | None | 例如 `--output_eval=eval_output`, 默认为当前路径 |
-| --json_eval | eval | 是否通过已存在的bbox.json或者mask.json进行评估 | False | 如需指定,直接`--json_eval`即可, json文件路径在`--output_eval`中设置 |
-| --classwise | eval | 是否评估单类AP和绘制单类PR曲线 | False | 如需指定,直接`--classwise`即可 |
-| --output_dir | infer/export_model | 预测后结果或导出模型保存路径 | `./output` | 例如`--output_dir=output` |
-| --draw_threshold | infer | 可视化时分数阈值 | 0.5 | 例如`--draw_threshold=0.7` |
-| --infer_dir | infer | 用于预测的图片文件夹路径 | None | `--infer_img`和`--infer_dir`必须至少设置一个 |
-| --infer_img | infer | 用于预测的图片路径 | None | `--infer_img`和`--infer_dir`必须至少设置一个,`infer_img`具有更高优先级 |
-| --save_txt | infer | 是否在文件夹下将图片的预测结果保存到文本文件中 | False | 可选 |
+ yolov3_reader.yml
+--------------------------------------
-## 使用示例
-### 模型训练
+yolov3_mobilenet_v1_roadsign 文件入口
-- 边训练边评估
+roadsign_voc 主要说明了训练数据和验证数据的路径
- ```bash
- export CUDA_VISIBLE_DEVICES=0,1,2,3,4,5,6,7
- python -m paddle.distributed.launch --gpus 0,1,2,3,4,5,6,7 tools/train.py -c configs/faster_rcnn/faster_rcnn_r50_fpn_1x_coco.yml --eval
- ```
+runtime.yml 主要说明了公共的运行参数,比如说是否使用GPU、每多少个epoch存储checkpoint等
- 在训练中交替执行评估, 评估在每个epoch训练结束后开始。每次评估后还会评出最佳mAP模型保存到`best_model`文件夹下。
+optimizer_40e.yml 主要说明了学习率和优化器的配置。
- 如果验证集很大,测试将会比较耗时,建议调整`configs/runtime.yml` 文件中的 `snapshot_epoch`配置以减少评估次数,或训练完成后再进行评估。
+ppyolov2_r50vd_dcn.yml 主要说明模型、和主干网络的情况。
+ppyolov2_reader.yml 主要说明数据读取器配置,如batch size,并发加载子进程数等,同时包含读取后预处理操作,如resize、数据增强等等
-- Fine-tune其他任务
- 使用预训练模型fine-tune其他任务时,可以直接加载预训练模型,形状不匹配的参数将自动忽略,例如:
+```
- ```bash
- export CUDA_VISIBLE_DEVICES=0,1,2,3,4,5,6,7
- # 如果模型中参数形状与加载权重形状不同,将不会加载这类参数
- python -m paddle.distributed.launch --gpus 0,1,2,3,4,5,6,7 tools/train.py -c configs/faster_rcnn/faster_rcnn_r50_fpn_1x_coco.yml \
- -o pretrain_weights=output/faster_rcnn_r50_1x_coco/model_final \
- ```
+ -**提示:**
+
-**提示:**
+
配置文件结构说明
-- `CUDA_VISIBLE_DEVICES` 参数可以指定不同的GPU。例如: `export CUDA_VISIBLE_DEVICES=0,1,2,3`
-- 若本地未找到数据集,将自动下载数据集并保存在`~/.cache/paddle/dataset`中。
-- 预训练模型自动下载并保存在`〜/.cache/paddle/weights`中。
-- 模型checkpoints默认保存在`output`中,可通过修改配置文件`configs/runtime.yml`中`save_dir`进行配置。
+## 4 训练
+PaddleDetection提供了单卡/多卡训练模式,满足用户多种训练需求
+* GPU单卡训练
+```bash
+export CUDA_VISIBLE_DEVICES=0 #windows和Mac下不需要执行该命令
+python tools/train.py -c configs/yolov3/yolov3_mobilenet_v1_roadsign.yml
+```
-### 模型评估
+* GPU多卡训练
+```bash
+export CUDA_VISIBLE_DEVICES=0,1,2,3,4,5,6,7 #windows和Mac下不需要执行该命令
+python -m paddle.distributed.launch --gpus 0,1,2,3,4,5,6,7 tools/train.py -c configs/yolov3/yolov3_mobilenet_v1_roadsign.yml
+```
+* Fine-tune其他任务
-- 指定权重和数据集路径
+ 使用预训练模型fine-tune其他任务时,可以直接加载预训练模型,形状不匹配的参数将自动忽略,例如:
- ```bash
- export CUDA_VISIBLE_DEVICES=0
- python -u tools/eval.py -c configs/faster_rcnn/faster_rcnn_r50_fpn_1x_coco.yml \
- -o weights=https://paddledet.bj.bcebos.com/models/faster_rcnn_r50_fpn_1x_coco.pdparams
- ```
+```bash
+export CUDA_VISIBLE_DEVICES=0,1,2,3,4,5,6,7
+ # 如果模型中参数形状与加载权重形状不同,将不会加载这类参数
+python -m paddle.distributed.launch --gpus 0,1,2,3,4,5,6,7 tools/train.py -c configs/yolov3/yolov3_mobilenet_v1_roadsign.yml -o pretrain_weights=output/model_final
+```
+
+* 模型恢复训练
- 评估模型可以为本地路径,例如`output/faster_rcnn_r50_1x_coco/model_final`, 也可以是[MODEL_ZOO](../MODEL_ZOO_cn.md)中给出的模型链接。
+ 在日常训练过程中,有的用户由于一些原因导致训练中断,用户可以使用-r的命令恢复训练
+```bash
+export CUDA_VISIBLE_DEVICES=0 #windows和Mac下不需要执行该命令
+python tools/train.py -c configs/yolov3/yolov3_mobilenet_v1_roadsign.yml -r output/faster_rcnn_r50_1x_coco/10000
+ ```
+
+## 5 评估
+* 默认将训练生成的模型保存在当前`output`文件夹下
+ ```bash
+export CUDA_VISIBLE_DEVICES=0 #windows和Mac下不需要执行该命令
+python tools/eval.py -c configs/yolov3/yolov3_mobilenet_v1_roadsign.yml -o weights=https://paddledet.bj.bcebos.com/models/yolov3_mobilenet_v1_roadsign.pdparams
+```
+* 边训练,边评估
+
+```bash
+export CUDA_VISIBLE_DEVICES=0,1,2,3,4,5,6,7 #windows和Mac下不需要执行该命令
+python -m paddle.distributed.launch --gpus 0,1,2,3,4,5,6,7 tools/train.py -c configs/yolov3/yolov3_mobilenet_v1_roadsign.yml --eval
+```
+
+ 在训练中交替执行评估, 评估在每个epoch训练结束后开始。每次评估后还会评出最佳mAP模型保存到`best_model`文件夹下。
+
+ 如果验证集很大,测试将会比较耗时,建议调整`configs/runtime.yml` 文件中的 `snapshot_epoch`配置以减少评估次数,或训练完成后再进行评估。
- 通过json文件评估
- ```bash
- export CUDA_VISIBLE_DEVICES=0
- python tools/eval.py -c configs/faster_rcnn/faster_rcnn_r50_fpn_1x_coco.yml \
+```bash
+export CUDA_VISIBLE_DEVICES=0 #windows和Mac下不需要执行该命令
+python tools/eval.py -c configs/yolov3/yolov3_mobilenet_v1_roadsign.yml \
--json_eval \
-output_eval evaluation/
- ```
-
- json文件必须命名为bbox.json或者mask.json,放在`evaluation/`目录下。
-
+```
+* 上述命令中没有加载模型的选项,则使用配置文件中weights的默认配置,`weights`表示训练过程中保存的最后一轮模型文件
+* json文件必须命名为bbox.json或者mask.json,放在`evaluation`目录下。
-### 模型预测
+## 6 预测
-- 设置输出路径 && 设置预测阈值
+ ```bash
+ python tools/infer.py -c configs/yolov3/yolov3_mobilenet_v1_roadsign.yml --infer_img=demo/000000570688.jpg -o weights=https://paddledet.bj.bcebos.com/models/yolov3_mobilenet_v1_roadsign.pdparams
+ ```
+ * 设置参数预测
```bash
- export CUDA_VISIBLE_DEVICES=0
- python tools/infer.py -c configs/faster_rcnn/faster_rcnn_r50_fpn_1x_coco.yml \
- --infer_img=demo/000000570688.jpg \
+ export CUDA_VISIBLE_DEVICES=0 #windows和Mac下不需要执行该命令
+ python tools/infer.py -c configs/yolov3/yolov3_mobilenet_v1_roadsign.yml \
+ --infer_img=demo/road554.png \
--output_dir=infer_output/ \
--draw_threshold=0.5 \
- -o weights=output/faster_rcnn_r50_fpn_1x_coco/model_final \
+ -o weights=output/yolov3_mobilenet_v1_roadsign/model_final \
--use_vdl=Ture
```
- `--draw_threshold` 是个可选参数. 根据 [NMS](https://ieeexplore.ieee.org/document/1699659) 的计算,
- 不同阈值会产生不同的结果。
+ `--draw_threshold` 是个可选参数. 根据 [NMS](https://ieeexplore.ieee.org/document/1699659) 的计算,不同阈值会产生不同的结果
+ `keep_top_k`表示设置输出目标的最大数量,默认值为100,用户可以根据自己的实际情况进行设定。
+
+结果如下图:
+
+
+
+## 7 训练可视化
+
+当打开`use_vdl`开关后,为了方便用户实时查看训练过程中状态,PaddleDetection集成了VisualDL可视化工具,当打开`use_vdl`开关后,记录的数据包括:
+1. loss变化趋势
+2. mAP变化趋势
+
+```bash
+export CUDA_VISIBLE_DEVICES=0 #windows和Mac下不需要执行该命令
+python tools/train.py -c configs/yolov3/yolov3_mobilenet_v1_roadsign.yml
+ --use_vdl=true \
+ --vdl_log_dir=vdl_dir/scalar \
+```
+
+使用如下命令启动VisualDL查看日志
+```shell
+# 下述命令会在127.0.0.1上启动一个服务,支持通过前端web页面查看,可以通过--host这个参数指定实际ip地址
+visualdl --logdir vdl_dir/scalar/
+```
+
+在浏览器输入提示的网址,效果如下:
+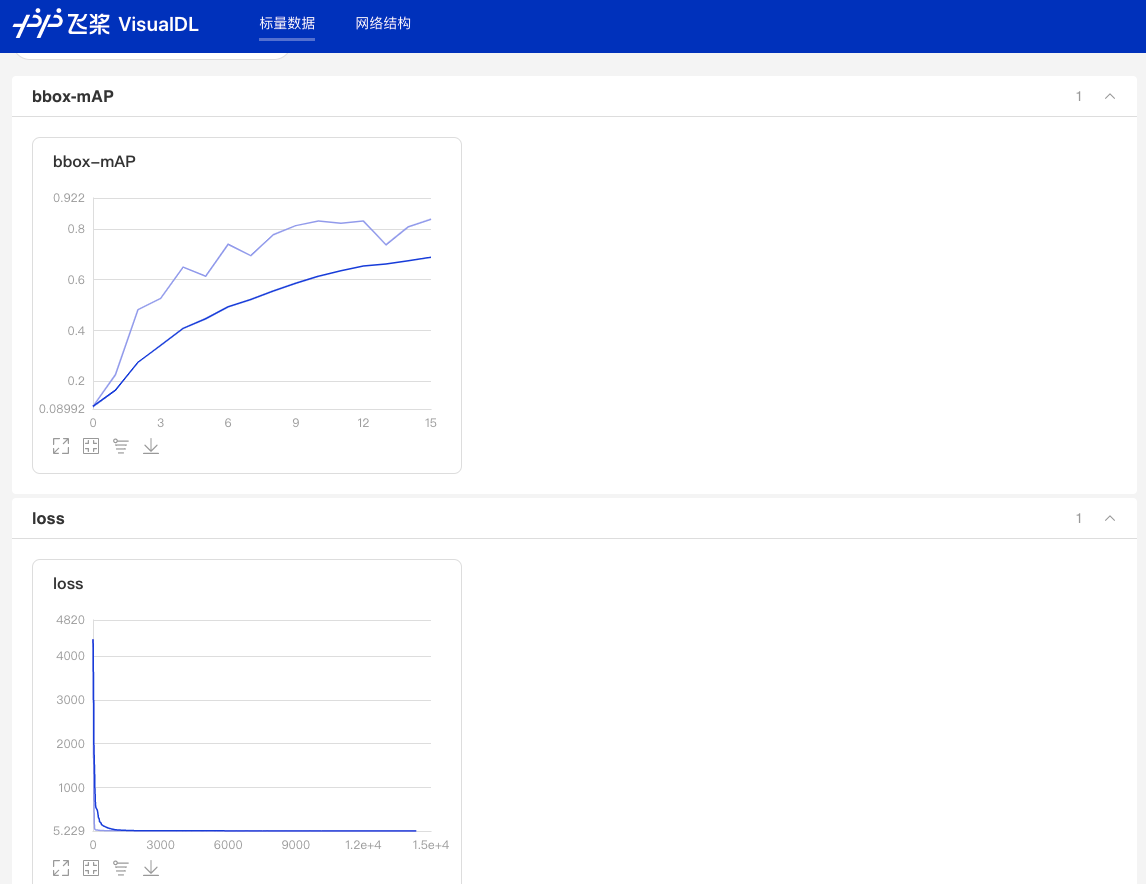 +
+
+
+
图:VDL效果演示
+**参数列表**
+以下列表可以通过`--help`查看
+
+| FLAG | 支持脚本 | 用途 | 默认值 | 备注 |
+| :----------------------: | :------------: | :---------------: | :--------------: | :-----------------: |
+| -c | ALL | 指定配置文件 | None | **必选**,例如-c configs/faster_rcnn/faster_rcnn_r50_fpn_1x_coco.yml |
+| -o | ALL | 设置或更改配置文件里的参数内容 | None | 相较于`-c`设置的配置文件有更高优先级,例如:`-o use_gpu=False` |
+| --eval | train | 是否边训练边测试 | False | 如需指定,直接`--eval`即可 |
+| -r/--resume_checkpoint | train | 恢复训练加载的权重路径 | None | 例如:`-r output/faster_rcnn_r50_1x_coco/10000` |
+| --slim_config | ALL | 模型压缩策略配置文件 | None | 例如`--slim_config configs/slim/prune/yolov3_prune_l1_norm.yml` |
+| --use_vdl | train/infer | 是否使用[VisualDL](https://github.com/paddlepaddle/visualdl)记录数据,进而在VisualDL面板中显示 | False | VisualDL需Python>=3.5 |
+| --vdl\_log_dir | train/infer | 指定 VisualDL 记录数据的存储路径 | train:`vdl_log_dir/scalar` infer: `vdl_log_dir/image` | VisualDL需Python>=3.5 |
+| --output_eval | eval | 评估阶段保存json路径 | None | 例如 `--output_eval=eval_output`, 默认为当前路径 |
+| --json_eval | eval | 是否通过已存在的bbox.json或者mask.json进行评估 | False | 如需指定,直接`--json_eval`即可, json文件路径在`--output_eval`中设置 |
+| --classwise | eval | 是否评估单类AP和绘制单类PR曲线 | False | 如需指定,直接`--classwise`即可 |
+| --output_dir | infer/export_model | 预测后结果或导出模型保存路径 | `./output` | 例如`--output_dir=output` |
+| --draw_threshold | infer | 可视化时分数阈值 | 0.5 | 例如`--draw_threshold=0.7` |
+| --infer_dir | infer | 用于预测的图片文件夹路径 | None | `--infer_img`和`--infer_dir`必须至少设置一个 |
+| --infer_img | infer | 用于预测的图片路径 | None | `--infer_img`和`--infer_dir`必须至少设置一个,`infer_img`具有更高优先级 |
+| --save_txt | infer | 是否在文件夹下将图片的预测结果保存到文本文件中 | False | 可选 |
-## 预测部署
-请参考[预测部署文档](../../deploy/README.md)。
+## 8 模型导出
+在模型训练过程中保存的模型文件是包含前向预测和反向传播的过程,在实际的工业部署则不需要反向传播,因此需要将模型进行导成部署需要的模型格式。
+在PaddleDetection中提供了 `tools/export_model.py`脚本来导出模型
-## 模型压缩
+```bash
+python tools/export_model.py -c configs/yolov3/yolov3_mobilenet_v1_roadsign.yml --output_dir=./inference_model \
+ -o weights=output/yolov3_mobilenet_v1_roadsign/best_model
+```
+预测模型会导出到`inference_model/yolov3_mobilenet_v1_roadsign`目录下,分别为`infer_cfg.yml`, `model.pdiparams`, `model.pdiparams.info`,`model.pdmodel` 如果不指定文件夹,模型则会导出在`output_inference`
+
+* 更多关于模型导出的文档,请参考[模型导出文档](../../deploy/EXPORT_MODEL.md)
-请参考[模型压缩文档](../../configs/slim/README.md)。
+## 9 模型压缩
+
+为了进一步对模型进行优化,PaddleDetection提供了基于PaddleSlim进行模型压缩的完整教程和benchmark。目前支持的方案:
+* 裁剪
+* 量化
+* 蒸馏
+* 联合策略
+* 更多关于模型压缩的文档,请参考[模型压缩文档](../../configs/slim/README.md)。
+## 10 预测部署
+PaddleDetection提供了PaddleInference、PaddleServing、PaddleLite多种部署形式,支持服务端、移动端、嵌入式等多种平台,提供了完善的Python和C++部署方案。
+* 在这里,我们以Python为例,说明如何使用PaddleInference进行模型部署
+```bash
+python deploy/python/infer.py --model_dir=./inference/yolov3_mobilenet_v1_roadsign --image_file=demo/road554.png --use_gpu=True
+```
+* 同时`infer.py`提供了丰富的接口,用户进行接入视频文件、摄像头进行预测,更多内容请参考[Python端预测部署](../../deploy/python.md)
+### PaddleDetection支持的部署形式说明
+|形式|语言|教程|设备/平台|
+|-|-|-|-|
+|PaddleInference|Python|已完善|Linux(arm X86)、Windows
+|PaddleInference|C++|已完善|Linux(arm X86)、Windows|
+|PaddleServing|Python|已完善|Linux(arm X86)、Windows|
+|PaddleLite|C++|已完善|Android、IOS、FPGA、RK...
+
+* 更多关于预测部署的文档,请参考[预测部署文档](../../deploy/README.md)。