Fork自 PaddlePaddle / PaddleRec
体验新版 GitCode,发现更多精彩内容 >>
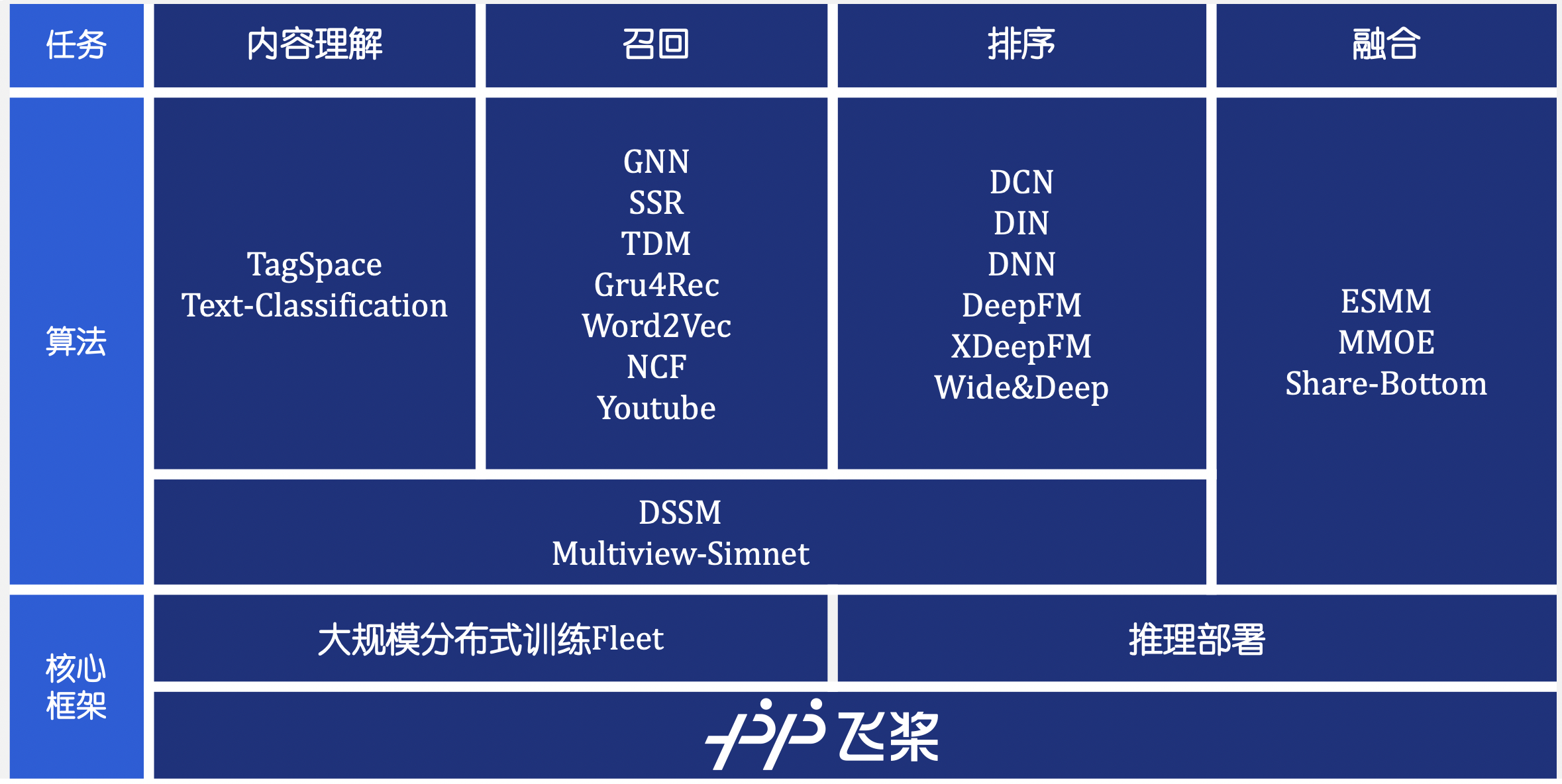
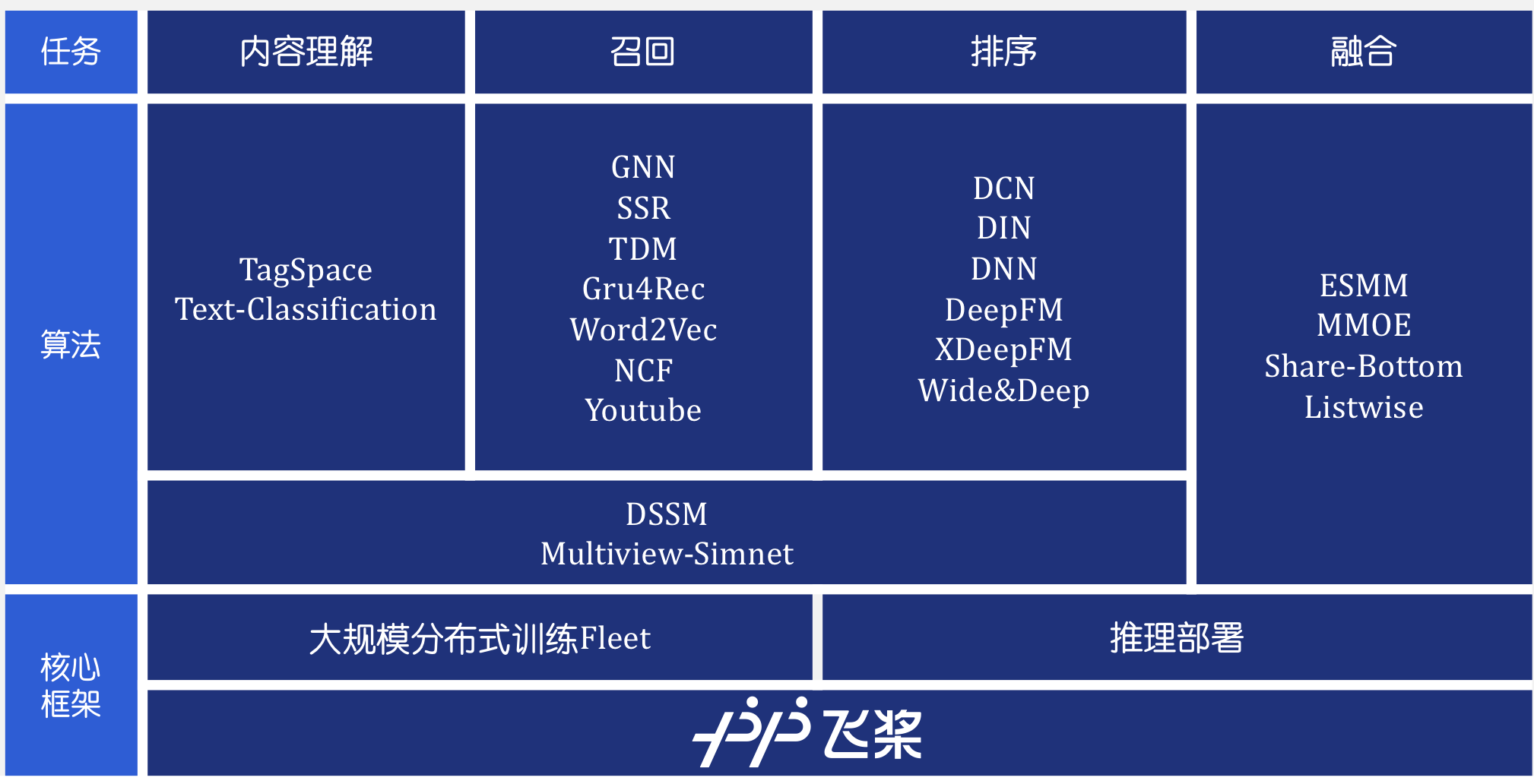
fix model for new version
698.6 KB | W: | H:
217.7 KB | W: | H:
{kind=link}
{kind=link}