Neural network models are defined as a `ProgramDesc` in Fluid. The `ProgramDesc` can be executed by an interpreter(i.e. the `executor` concept in Fluid). The instructions or operators in a `Program` will be executed, and the results will be fetched in Python side.
The executor is a very naive interpreter. It runs operators one by one. We can use `Parallel.Do` to support data parallelism, however, lacking device information in `ProgramDesc`; it is not possible to optimize the performance of `Parallel.Do`.
We want a `ProgramDesc` can be run on different nodes. It is better not to contain device information in `ProgramDesc`. However, we can write a high-performance interpreter, which can hold an alternative intermediate representation of `ProgramDesc`, to take full usage of Multi-GPUs.
ParallelExecutor is an interpreter of `ProgramDesc` which will [out-of-order execute](Out-of-order execution) `Program` in data parallelism mode and maximise the utility of Multi-GPUs.
## Overview of MultiGPUs logic
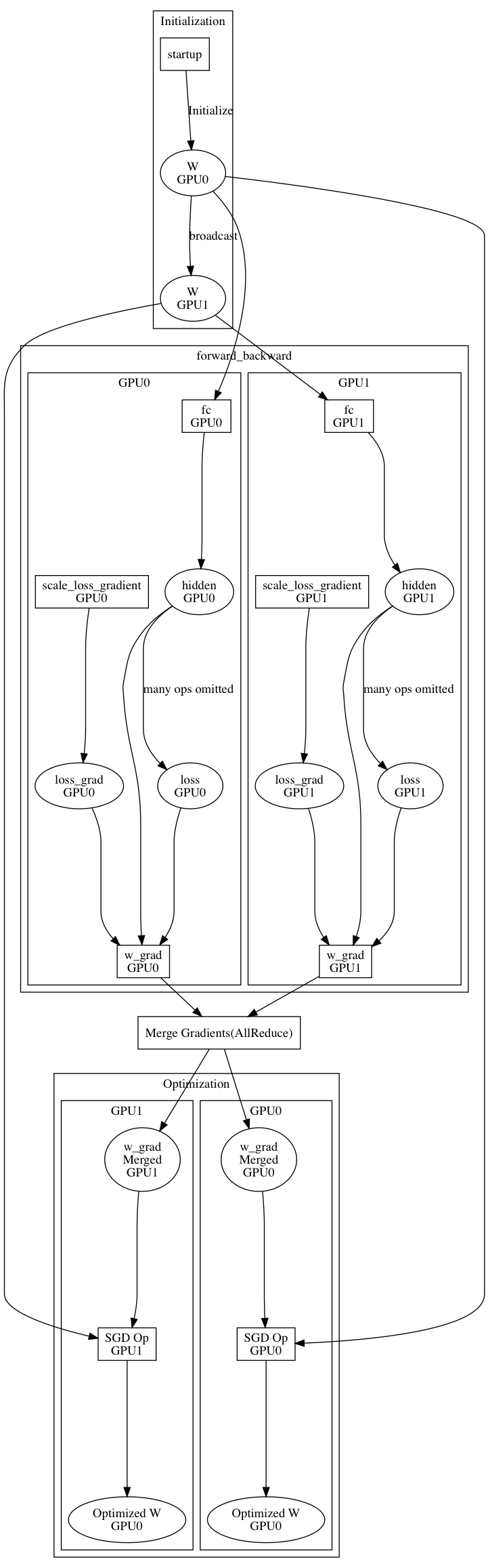
The ParallelExecutor takes the startup program and main program as inputs. The parameters will be initialised on `GPU0` by startup program and will broadcast to multi-GPUs. The main program will be duplicated into multi-GPUs. The gradient will be merged during each iteration, and each device will optimize parameters independently. Since the gradients on each device will be merged before parameter optimization, the parameters will be the same on each device and it does not need to be broadcast the parameters.

There are several optimizations for this logic.
1. We use an alternate representation in ParallelExecutor. It because the device information is critical for performance optimization.
2. The execution is out-of-order, i.e., an operator will be executed whenever the inputs of the operator are ready.
* GPU is a high-performance device; only one CPU thread cannot fulfil one GPU. So there is a thread pool to execute operators.
* Out-of-order also helps transpilers to generate `ProgramDesc`. It is no need to concern about the best order of performance when implementing a transpiler.
3. The streams of computation, merge gradients and fetch data are different.
The performance of `ResNeXt152` on `TitanX` which `batch_size=12` is shown below.
[Static single assignment form](https://en.wikipedia.org/wiki/Static_single_assignment_form)(`SSA` for short) is a common form for compiler optimization. To implement concurrent execution, we uses an `SSA` graph as an intermedia representation of `ProgramDesc`.
The `Program` is a directed acyclic graph, since a variable can be assigned multiple times. We enforce a variable will be assigned once, by adding version number to varaibles. We parsing the `Program` into a `SSA` graph. Also, ProgramExecutor duplicate `Program` into multi-devices. We also add a device number to varaibles and insert `NCCLAllReduce` into Graph.
The data structure of `SSA` graph is:
```c++
structVarHandleBase{
OpHandleBase*generated_op_;
vector<OpHandleBase*>pending_ops_;
stringname;
Placeplace;
size_tversion;
};
structOpHandleBase{
vector<OpHandleBase*>inputs_;
vector<OpHnadleBase*>outputs_;
};
structSSAGraph{
// vars on each devices.
// * the vars in each map in vector is on different device.
// * the map is mapping a variable name to variable handles
The variable handles are the wrapper of `Variables`. The operator handles are the wrapper of `OperatorBase`. Some `OpHandle` is not an `OperatorBase`, such as `NCCLAllReduceOpHandle`, because `AllReduceOpHandle` will use new device contexts.
When the `ProgramDesc` converted into an `SSA` Graph, the [data hazard](https://en.wikipedia.org/wiki/Hazard_(computer_architecture)) problem is also need to be taken care. The dummy variables, which represent the dependency between operators, will be manually inserted into SSA graph to resolve the [data hazard](https://en.wikipedia.org/wiki/Hazard_(computer_architecture)) problem.
## Execute SSA Graph
The SSA graph can be out-of-order executed by an approximate [topological sorting](https://en.wikipedia.org/wiki/Topological_sorting) algorithm. The algorithm is
1. Maintaining a map of an operator and its needed input number.
2. If a variable is not generated by an operator, i.e., `var.generated_op == nullptr`, decrease the needed input number of its pending operators.
3. If there is an operator which needed input number is decreased to zero, just run this operator.
4. After run this operator, just mark the variables are generated and repeat step 2 until all variables are generated.
Running an operator can be asynchronized. There is a thread pool to execute an `SSA` graph.
## Synchronize GPU Kernels
The GPU is a non-blocking device. The different streams need be synchronized when switing streams. In current implementation, the synchronization based on the following algorithm:
1.`OpHandle` will record `DeviceContext` that it is used.
2. In `OpHandle::Run`, if the `DeviceContext` of current operator is different from `DeviceContext` of any input variable, just wait the generate operator of this input variable.
The `wait` are implemented by two strategies:
1. Invoke `DeviceContext->Wait()`, It will wait all operators on this device contexts complete.
2. Uses `cudaStreamWaitEvent` to sending a event to the stream. It is a non-blocking call. The wait operators will be executed in GPU.
Generally, the `cudaStreamWaitEvent` will have a better perforamnce. However, `DeviceContext->Wait()` strategy is easier to debug. The strategy can be changed in runtime.
## What's next?
* Merging gradient of dense parameters has been done. However, the merging of sparse parameters has not been done.
* The CPU version of Parallel Executor has not been implemented. The out-of-order logic will make CPU compuatation faster, too.
* A better strategy to merge gradients can be introduced. We can shrink the gradients from `float32` to `int8` or `int4` while merging. It will significantly speed up multi-GPUs training without much loss of precision.
* Combine multi-Nodes implementation. By the benifit of out-of-order, sending and recving operator can be an blocking operator, and the transpiler does not need to concern about the best position of operator.
{kind=link}