更新了部分文档
Showing
Day86-90/87.Hive查询.md
已删除
100644 → 0
Day86-90/87.Hive简介.md
0 → 100644
{kind=link}
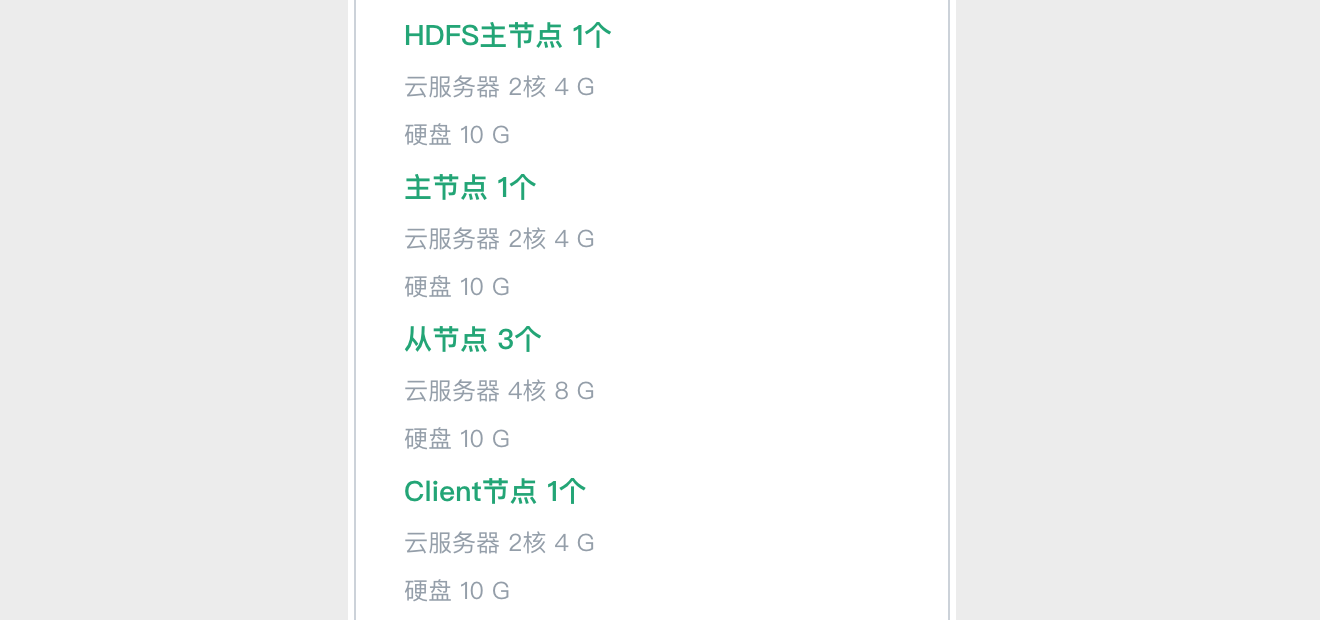
66.7 KB
Day86-90/res/bigdata-env.png
0 → 100644
{kind=link}

76.2 KB
Day86-90/res/bigdata-vpc.png
0 → 100644
{kind=link}
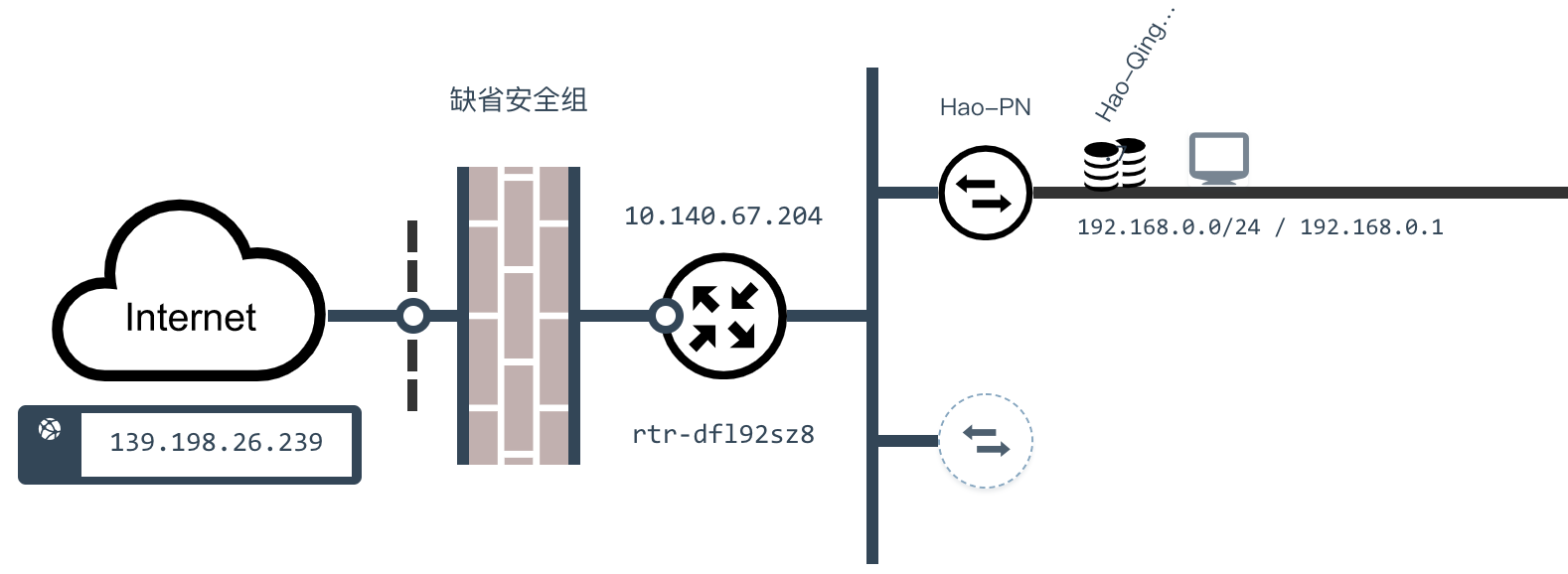
84.7 KB
Day86-90/res/hadoop-ecosystem.png
0 → 100644
{kind=link}

58.3 KB