Skip to content
体验新版
项目
组织
正在加载...
登录
切换导航
打开侧边栏
不正经的廖老师
Python-100-Days
提交
6632c372
P
Python-100-Days
项目概览
不正经的廖老师
/
Python-100-Days
与 Fork 源项目一致
从无法访问的项目Fork
通知
1
Star
0
Fork
0
代码
文件
提交
分支
Tags
贡献者
分支图
Diff
Issue
0
列表
看板
标记
里程碑
合并请求
0
Wiki
0
Wiki
分析
仓库
DevOps
项目成员
Pages
P
Python-100-Days
项目概览
项目概览
详情
发布
仓库
仓库
文件
提交
分支
标签
贡献者
分支图
比较
Issue
0
Issue
0
列表
看板
标记
里程碑
合并请求
0
合并请求
0
Pages
分析
分析
仓库分析
DevOps
Wiki
0
Wiki
成员
成员
收起侧边栏
关闭侧边栏
动态
分支图
创建新Issue
提交
Issue看板
前往新版Gitcode,体验更适合开发者的 AI 搜索 >>
提交
6632c372
编写于
4月 06, 2021
作者:
J
jackfrued
浏览文件
操作
浏览文件
下载
电子邮件补丁
差异文件
更新了部分文档
上级
7efa67be
变更
5
隐藏空白更改
内联
并排
Showing
5 changed file
with
240 addition
and
53 deletion
+240
-53
Day66-70/66.数据分析概述.md
Day66-70/66.数据分析概述.md
+2
-2
Day66-70/67.NumPy的应用.md
Day66-70/67.NumPy的应用.md
+8
-5
Day66-70/68.Pandas的应用.md
Day66-70/68.Pandas的应用.md
+230
-46
Day66-70/res/series-bar-graph.png
Day66-70/res/series-bar-graph.png
+0
-0
Day66-70/res/series-pie-graph.png
Day66-70/res/series-pie-graph.png
+0
-0
未找到文件。
Day66-70/66.数据分析概述.md
浏览文件 @
6632c372
...
...
@@ -325,4 +325,4 @@ Notebook是基于网页的用于交互计算的应用程序,可以用于代码
按照上面的描述,贝叶斯定理可以表述为:`后验概率 = (似然性 * 先验概率) / 标准化常量`,简单的说就是后验概率与先验概率和相似度的乘积成正比。
描述性统计通常用于研究表象,将现象用数据的方式描述出来;推理性统计通常用于推测本质,也就是你看到的表象的东西有多大概率符合你对隐藏在表象后的本质的猜测。
\ No newline at end of file
描述性统计通常用于研究表象,将现象用数据的方式描述出来(用整体的数据来描述整体的特征);推理性统计通常用于推测本质(通过样本数据特征去推理总体数据特征),也就是你看到的表象的东西有多大概率符合你对隐藏在表象后的本质的猜测。
\ No newline at end of file
Day66-70/67.NumPy的应用.md
浏览文件 @
6632c372
...
...
@@ -1098,7 +1098,7 @@ print(np.log2(array35))
| `sinh` / `tan` / `tanh` | 三角函数 |
| `arccos` / `arccosh` / `arcsin` | 反三角函数 |
| `arcsinh` / `arctan` / `arctanh` | 反三角函数 |
| `rint` / `
around`
| 四舍五入函数 |
| `rint` / `
round`
| 四舍五入函数 |
#### 通用二元函数
...
...
@@ -1178,7 +1178,7 @@ array([[1, 1, 1],
[7, 7, 7]])
```
通过上面的例子,我们发现形状不同的数组仍然有机会进行二元运算,但也绝对不是任意的数组都可以进行二元运算。简单的说,只有两个数组后缘维度相同或者其中一个数组后缘维度为1时,
两个数组才能进行二元运算。所谓后缘维度,指的是数组`shape`属性对应的元组中最后一个元素的值(从后往前数最后一个维度的值),例如,我们之前打开的图像对应的数组后缘维度为3,3行4列的二维数组后缘维度为4,而有5个元素的一维数组后缘维度为5。后缘维度相同或者其中一个数组为1就可以应用广播机制对元素进行扩散,从而满足
两个数组对应元素做运算的需求,如下图所示。
通过上面的例子,我们发现形状不同的数组仍然有机会进行二元运算,但也绝对不是任意的数组都可以进行二元运算。简单的说,只有两个数组后缘维度相同或者其中一个数组后缘维度为1时,
广播机制会被触发,而通过广播机制如果能够使两个数组的形状一致,才能进行二元运算。所谓后缘维度,指的是数组`shape`属性对应的元组中最后一个元素的值(从后往前数最后一个维度的值),例如,我们之前打开的图像对应的数组后缘维度为3,3行4列的二维数组后缘维度为4,而有5个元素的一维数组后缘维度为5。简单的说就是,后缘维度相同或者其中一个数组的后缘维度为1,就可以应用广播机制;而广播机制如果能够使得数组的形状一致,就满足了
两个数组对应元素做运算的需求,如下图所示。

...
...
@@ -1294,7 +1294,9 @@ NumPy中提供了专门用于线性代数(linear algebra)的模块和表示
6. **矩阵**是由一系列元素排成的矩形阵列,矩阵里的元素可以是数字、符号或数学公式。
7. 矩阵可以进行**加法**、**减法**、**数乘**、**乘法**、**转置**等运算。
8. **逆矩阵**用$\boldsymbol{A^{-1}}$表示,$\boldsymbol{A}\boldsymbol{A^{-1}}=\boldsymbol{A^{-1}}\boldsymbol{A}=\boldsymbol{I}$;没有逆矩阵的方阵是**奇异矩阵**。
9. 如果一个方阵是**满秩矩阵**,该方阵对应的线性方程有唯一解。
9. 如果一个方阵是**满秩矩阵**(矩阵的秩等于矩阵的阶数),该方阵对应的线性方程有唯一解。
> **说明**:**矩阵的秩**是指矩阵中线性无关的行/列向量的最大个数,同时也是矩阵对应的线性变换的像空间的维度。
#### NumPy中矩阵相关函数
...
...
@@ -1334,7 +1336,6 @@ NumPy中提供了专门用于线性代数(linear algebra)的模块和表示
代码:
```
Python
# 矩阵乘法运算,等同于m1.dot(m2)
m1
*
m2
```
...
...
@@ -1345,6 +1346,8 @@ NumPy中提供了专门用于线性代数(linear algebra)的模块和表示
[32, 32]])
```
> **说明**:注意`matrix`对象和`ndarray`对象乘法运算的差别,如果两个二维数组要做矩阵乘法运算,应该使用`@`运算符或`matmul`函数,而不是`*`运算符。
2. 矩阵对象的属性。
| 属性 | 说明 |
...
...
@@ -1369,7 +1372,7 @@ NumPy的`linalg`模块中有一组标准的矩阵分解运算以及诸如求逆
| --------------- | ------------------------------------------------------------ |
| `diag` | 以一维数组的形式返回方阵的对角线元素或将一维数组转换为方阵(非对角元素元素为0) |
| `vdot` | 向量的点积 |
| `dot` | 数组的点积
(矩阵乘法)
|
| `dot` | 数组的点积 |
| `inner` | 数组的内积 |
| `outer` | 数组的叉积 |
| `trace` | 计算对角线元素的和 |
...
...
Day66-70/68.Pandas的应用.md
浏览文件 @
6632c372
...
...
@@ -6,20 +6,18 @@ Pandas核心的数据类型是`Series`(数据系列)、`DataFrame`(数据
### Series的应用
Pandas库中的
`Series`
对象可以用来表示一维数据结构,跟数组非常类似,但是多了一些额外的功能。
`Series`
的内部结构包含了两个数组,其中一个用来保存数据,另一个用来保存数据的索引,如下图所示。

Pandas库中的
`Series`
对象可以用来表示一维数据结构,跟数组非常类似,但是多了一些额外的功能。
`Series`
的内部结构包含了两个数组,其中一个用来保存数据,另一个用来保存数据的索引。
#### 创建Series对象
> **提示**:在执行下面的代码之前,请先导入
pandas
以及相关的库文件,具体的做法可以参考上一章。
> **提示**:在执行下面的代码之前,请先导入
`pandas`
以及相关的库文件,具体的做法可以参考上一章。
-
方法1:通过列表或数组创建Series对象。
代码:
```Python
# data参数表示数据,index参数表示
索引标签
# data参数表示数据,index参数表示
数据的索引(标签)
# 如果没有指定index属性,默认使用数字索引
ser1 = pd.Series(data=[320, 180, 300, 405], index=['一季度', '二季度', '三季度', '四季度'])
ser1
...
...
@@ -40,7 +38,7 @@ Pandas库中的`Series`对象可以用来表示一维数据结构,跟数组非
代码:
```Python
# 字典中的键就是
索引标签
,字典中的值就是数据
# 字典中的键就是
数据的索引(标签)
,字典中的值就是数据
ser2 = pd.Series({'一季度': 320, '二季度': 180, '三季度': 300, '四季度': 405})
ser2
```
...
...
@@ -59,20 +57,20 @@ Pandas库中的`Series`对象可以用来表示一维数据结构,跟数组非
跟数组一样,Series对象也可以进行索引和切片操作,不同的是Series对象因为内部维护了一个保存索引的数组,所以除了可以使用整数索引通过位置检索数据外,还可以通过自己设置的索引标签获取对应的数据。
-
使用
正负向
整数索引
-
使用整数索引
代码:
```Python
print(ser2[0], ser
2[2], ser2[-1
])
ser2[0], ser2[
-1] = 350, 360
print(ser2[0], ser
[1], ser[2], ser[3
])
ser2[0], ser2[
3] = 350, 360
print(ser2)
```
输出:
```
320 300 405
320
180
300 405
一季度 350
二季度 180
三季度 300
...
...
@@ -80,6 +78,8 @@ Pandas库中的`Series`对象可以用来表示一维数据结构,跟数组非
dtype: int64
```
> **提示**:如果要使用负向索引,必须在创建`Series`对象时通过`index`属性指定非数值类型的标签。
-
使用自己设置的标签索引
代码:
...
...
@@ -257,7 +257,7 @@ Series对象的常用属性如下表所示。
dtype: float64
```
> **提示**:因为`describe()`返回的也是一个`Series`对象,所以
也
可以用`ser2.describe()['mean']`来获取平均值。
> **提示**:因为`describe()`返回的也是一个`Series`对象,所以可以用`ser2.describe()['mean']`来获取平均值。
如果`Series`对象的数据中有重复元素,我们可以使用`unique()`方法获得去重之后的`Series`对象,如果想要统计重复元素重复的次数,可以使用`value_counts()`方法,这个方法会返回一个`Series`对象,它的索引就是原来的`Series`对象中的元素,而每个元素出现的次数就是返回的`Series`对象中的数据,在默认情况下会按照元素出现次数做降序排列。
...
...
@@ -282,117 +282,301 @@ Series对象的常用属性如下表所示。
`Series`对象的`dropna`和`fillna`方法分别用来删除空值和填充空值,具体的用法如下所示。
代码:
```Python
ser4 = pd.Series(data=[10, 20, np.NaN, 30, np.NaN])
ser4.dropna()
ser4.dropna()
```
输出:
```
0 10.0
1 20.0
3 30.0
dtype: float64
dtype: float64
```
代码:
```
Python
# 将空值填充为40
ser4.fillna(value=40)
ser4.fillna(value=40)
```
输出:
```
0 10.0
1 20.0
2 40.0
3 30.0
4 40.0
dtype: float64
dtype: float64
```
代码:
```
Python
# backfill或bfill表示用后一个元素的值填充空值
# ffill或pad表示用前一个元素的值填充空值
ser4.fillna(method='ffill')
ser4.fillna(method='ffill')
```
输出:
```
0 10.0
1 20.0
2 20.0
3 30.0
4 30.0
dtype: float64
dtype: float64
```
需要提醒大家注意的是,`dropna`和`fillna`方法都有一个名为`inplace`的参数,它的默认值是`False`,表示删除空值或填充空值不会修改原来的`Series`对象,而是返回一个新的`Series`对象来表示删除或填充空值后的数据系列,如果将`inplace`参数的值修改为`True`,那么删除或填充空值会就地操作,直接修改原来的`Series`对象,那么方法的返回值是`None`。后面我们会接触到的很多方法,包括`DataFrame`对象的很多方法都会有这个参数,它们的意义跟这里是一样的。
`Series`对象的`mask`和`where`方法可以将满足或不满足条件的值进行替换,如下所示。
代码:
```
Python
ser5 = pd.Series(range(5))
ser5.where(ser5 > 0)
```
输出:
```
0 NaN
1 1.0
2 2.0
3 3.0
4 4.0
dtype: float64
```
代码:
```
Python
ser5.where(ser5 > 1, 10)
```
输出:
```
0 10
1 10
2 2
3 3
4 4
dtype: int64
```
代码:
```
Python
ser5.mask(ser5 > 1, 10)
```
输出:
```
0 0
1 1
2 10
3 10
4 10
dtype: int64
```
`Series`对象的`apply`和`map`方法可以用于对数据进行处理,代码如下所示。
`Series`对象的`mask`和`where`方法可以将满足或不满足条件的值进行替换。
代码:
`Series`对象的`sort_index`和`sort_values`方法可以用于对索引和数据的排序,具体的用法请参考下面的例子。
```
Python
ser6 = pd.Series(['cat', 'dog', np.nan, 'rabbit'])
ser6
```
`Series`对象的`value_counts`方法可以统计每个值出现的次数并且以从大到小的顺序进行排列,`Series`对象的`unique`方法可以获取到不重复的值。
输出:
```
0 cat
1 dog
2 NaN
3 rabbit
dtype: object
```
代码:
```
Python
ser6.map({'cat': 'kitten', 'dog': 'puppy'})
```
输出:
```
0 kitten
1 puppy
2 NaN
3 NaN
dtype: object
```
代码:
```
Python
ser6.map('I am a {}'.format, na_action='ignore')
```
输出:
```
0 I am a cat
1 I am a dog
2 NaN
3 I am a rabbit
dtype: object
```
代码:
```
Python
ser7 = pd.Series([20, 21, 12], index=['London', 'New York', 'Helsinki'])
ser7
```
输出:
```
London 20
New York 21
Helsinki 12
dtype: int64
```
代码:
```
Python
ser7.apply(np.square)
```
输出:
```
London 400
New York 441
Helsinki 144
dtype: int64
```
代码:
```
Python
ser7.apply(lambda x, value: x - value, args=(5, ))
```
输出:
```
London 15
New York 16
Helsinki 7
dtype: int64
```
`Series`对象的`sort_index`和`sort_values`方法可以用于对索引和数据的排序,排序方法有一个名为`ascending`的布尔类型参数,该参数用于控制排序的结果是升序还是降序;而名为`kind`的参数则用来控制排序使用的算法,默认使用了`quicksort`,也可以选择`mergesort`或`heapsort`;如果存在空值,那么可以用`na_position`参数空值放在最前还是最后,默认是`last`。
#### 绘制图表
Series对象有一个名为
`plot`
的方法可以用来生成图表,如果选择生成折线图、散点图、柱状图等,默认会使用Series对象的索引作为横坐标,使用Series对象的数据作为纵坐标。
Series对象有一个名为`plot`的方法可以用来生成图表,如果选择生成折线图、饼图、柱状图等,默认会使用Series对象的索引作为横坐标,使用Series对象的数据作为纵坐标。
利用Series对象的数据也可以生成表示占比的饼图和显示数据分布的直方图,如下面的代码所示
。
首先导入`matplotlib`中`pyplot`模块并进行必要的配置
。
```
Python
import matplotlib.pyplot as plt
# 配置支持中文的非衬线字体(默认的字体无法显示中文)
plt.rcParams['font.sans-serif'] = ['SimHei', ]
# 使用指定的中文字体时需要下面的配置来避免负号无法显示
plt.rcParams['axes.unicode_minus'] = False
```
### DataFrame的应用
#### 创建DataFrame对象
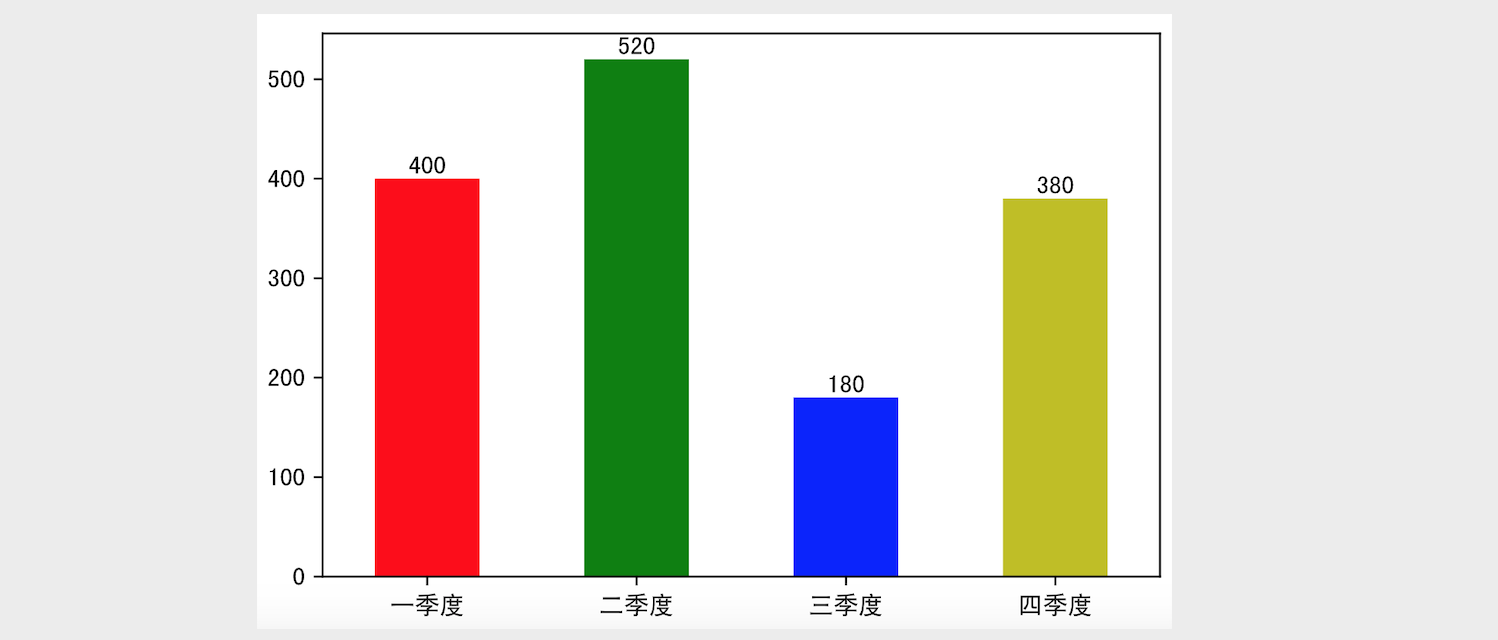
创建`Series`对象并绘制对应的柱状图。
```
Python
ser8 = pd.Series({'一季度': 400, '二季度': 520, '三季度': 180, '四季度': 380})
# 通过Series对象的plot方法绘图(kind='bar'表示绘制柱状图)
ser8.plot(kind='bar', color=['r', 'g', 'b', 'y'])
# x轴的坐标旋转到0度(中文水平显示)
plt.xticks(rotation=0)
# 在柱状图的柱子上绘制数字
for i in range(4):
plt.text(i, ser8[i] + 5, ser8[i], ha='center')
# 显示图像
plt.show()
```

#### 基本属性和方法
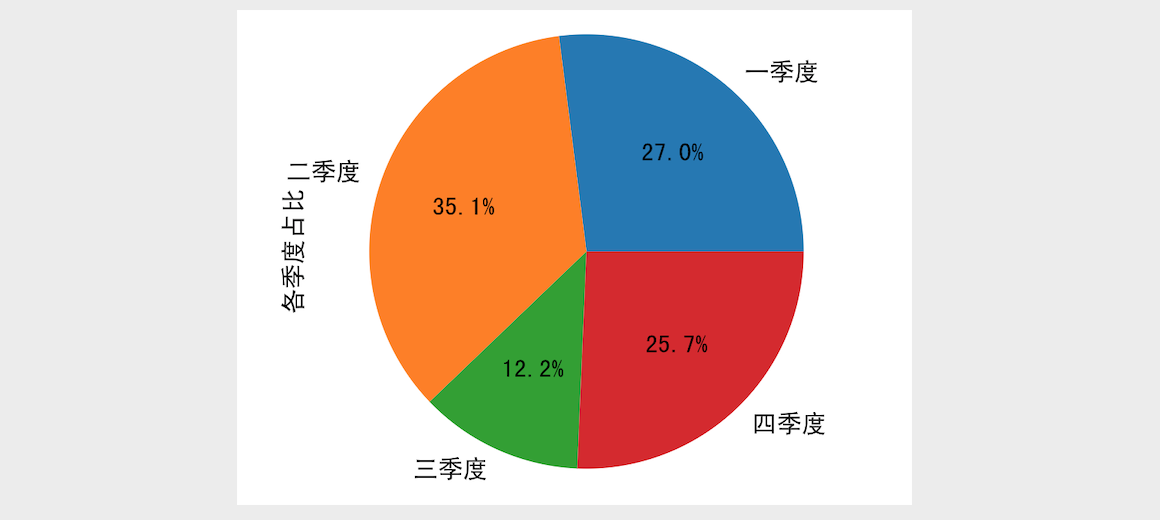
绘制反映每个季度占比的饼图。
```
Python
# autopct参数可以配置在饼图上显示每块饼的占比
ser8.plot(kind='pie', autopct='%.1f%%')
# 设置y轴的标签(显示在饼图左侧的文字)
plt.ylabel('各季度占比')
plt.show()
```

#### 索引和切片
### DataFrame的应用
####
相关运算
####
创建DataFrame对象
#### 缺失值处理
#### 基本属性和方法
####
数据离散化
####
获取数据
1. 索引和切片
2. 数据筛选
#### 数据处理
#### 数据的合并
1. 数据清洗
- 缺失值处理
- 重复值处理
- 异常值处理
2. 数据转换
- `apply`和`applymap`方法
- 字符串向量
- 时间日期向量
3. 数据合并
- `concat`函数
- `merge`函数
#### 数据分析
1. 描述性统计信息
2. 分组聚合操作
- `groupby`方法
- 透视表和交叉表
- 数据分箱
####
交叉表和透视表
####
数据可视化
1.
交叉表:根据一个数据系列计算另一个数据系列的统计结果得到的
`DataFrame`
对象。
2.
透视表:将
`DataFrame`
的列分别作为行索引和列索引,然后对指定的列应用聚合函数得到的结果。
1.
用`plot`方法出图
2.
其他方法
#### 分组和聚合
#### 绘制图表
Day66-70/res/series-bar-graph.png
0 → 100644
浏览文件 @
6632c372
54.0 KB
Day66-70/res/series-pie-graph.png
0 → 100644
浏览文件 @
6632c372
79.2 KB
编辑
预览
Markdown
is supported
0%
请重试
或
添加新附件
.
添加附件
取消
You are about to add
0
people
to the discussion. Proceed with caution.
先完成此消息的编辑!
取消
想要评论请
注册
或
登录
{kind=link}
{kind=link}