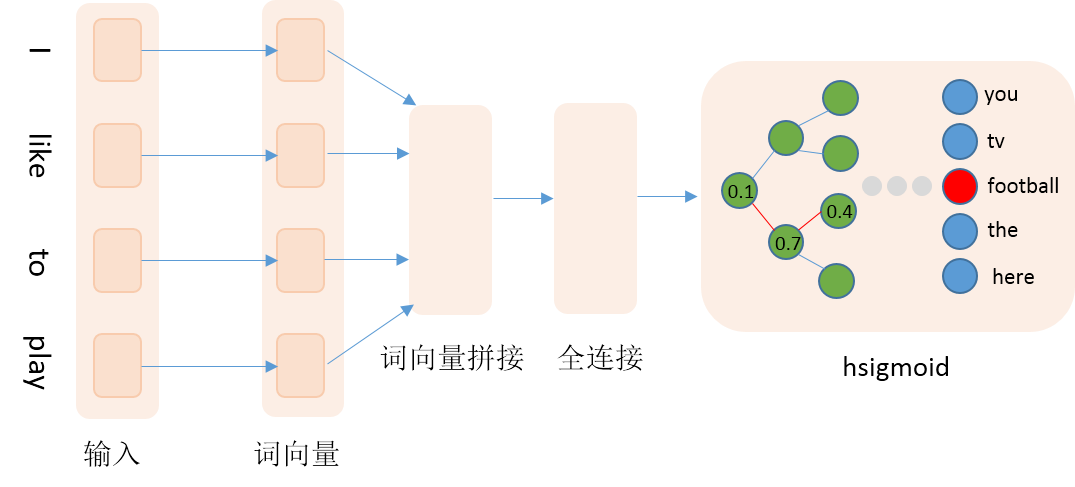
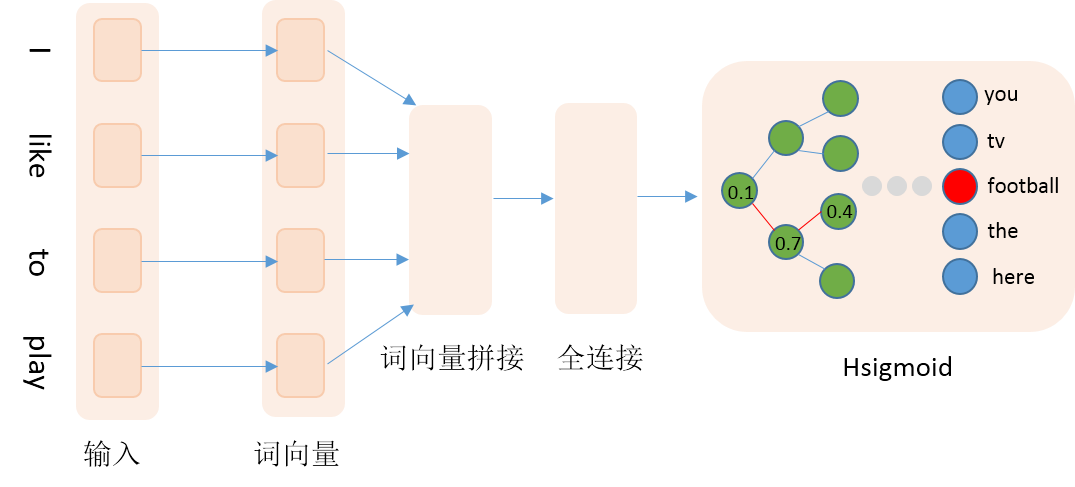
本文采用Penn Treebank (PTB)数据集([Tomas Mikolov预处理版本](http://www.fit.vutbr.cz/~imikolov/rnnlm/simple-examples.tgz)),共包含train、valid和test三个文件。其中使用train作为训练数据,valid作为测试数据。本文训练的是5-gram模型,即用每条数据的前4个词来预测第5个词。PaddlePaddle提供了对应PTB数据集的python包[paddle.dataset.imikolov](https://github.com/PaddlePaddle/Paddle/blob/develop/python/paddle/v2/dataset/imikolov.py) ,自动做数据的下载与预处理。预处理会把数据集中的每一句话前后加上开始符号\<s>以及结束符号\<e>,然后依据窗口大小(本文为5),从头到尾每次向右滑动窗口并生成一条数据。如"I have a dream that one day"可以生成\<s> I have a dream、I have a dream that、have a dream that one、a dream that one day、dream that one day \<e>,PaddlePaddle会把词转换成id数据作为预处理的输出。
It returns a reader creator, each sample in the reader is a word ID tuple.
:param filename: path of data file
:type filename: str
:param word_dict: word dictionary
:type word_dict: dict
:param n: sliding window size
:type n: int
"""
returnreader_creator(filename,word_dict,n)
```
# 数据准备
本文采用Penn Treebank (PTB)数据集(Tomas Mikolov预处理版本),共包含train、valid和test三个文件。其中使用train作为训练数据,valid作为测试数据。本文训练的是5-gram模型,每条数据的前4个词用来预测第5个词。PaddlePaddle提供了对应PTB数据集的python包paddle.dataset.imikolov,自动做数据的下载与预处理。预处理会把数据集中的每一句话前后加上开始符号\<s>以及结束符号\<e>。然后依据窗口大小(本文为5),从头到尾每次向右滑动窗口并生成一条数据。如"I have a dream that one day"可以生成\<s> I have a dream、I have a dream that、have a dream that one、a dream that one day、dream that one day \<e>,PaddlePaddle会把词转换成id数据作为最终输入。
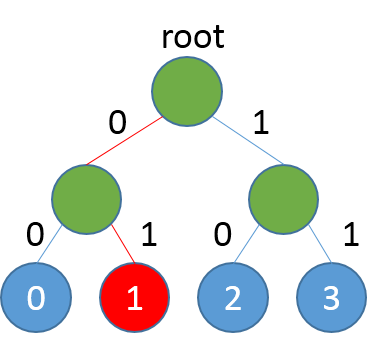
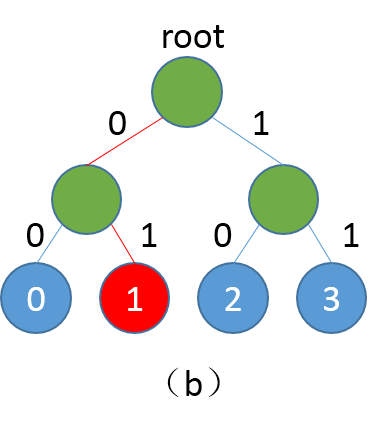
预测程序的输入数据格式与训练阶段相同,如have a dream that one,程序会根据have a dream that生成一组概率,通过对概率解码生成预测词,one作为真实词,方便评估。解码函数的输入是一个batch样本的预测概率以及词表的大小,里面的循环是对每条样本的输出概率进行解码,解码方式就是按照左0右1的准则,不断遍历路径,直至到达叶子节点。需要注意的是,本文选用的数据集需要较长的时间训练才能得到较好的结果,预测程序选用第一轮的模型,仅为展示方便,学习效果不能保证。
## 参考文献
1. Morin, F., & Bengio, Y. (2005, January). [Hierarchical Probabilistic Neural Network Language Model](http://www.iro.umontreal.ca/~lisa/pointeurs/hierarchical-nnlm-aistats05.pdf). In Aistats (Vol. 5, pp. 246-252).
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}