Merge pull request #2 from denglelaibh/denglelaibh
Realization of DRN 2016 (also similar to resNet 16)
Showing
drn/.idea/drn.iml
0 → 100644
drn/.idea/misc.xml
0 → 100644
drn/.idea/modules.xml
0 → 100644
drn/.idea/workspace.xml
0 → 100644
此差异已折叠。
drn/README.md
0 → 100644
drn/drn.py
0 → 100644
drn/img/pic1.png
0 → 100644
{kind=link}
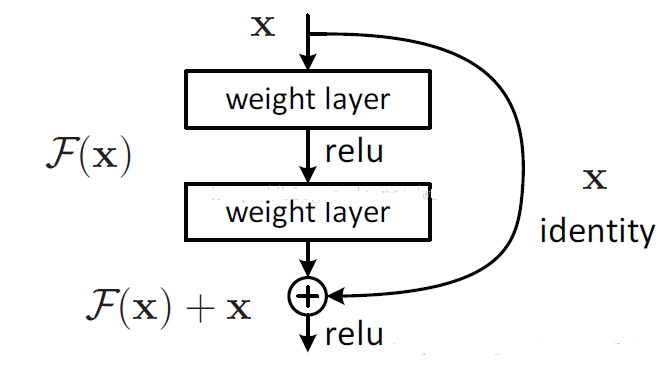
31.6 KB
drn/img/pic2.png
0 → 100644
{kind=link}
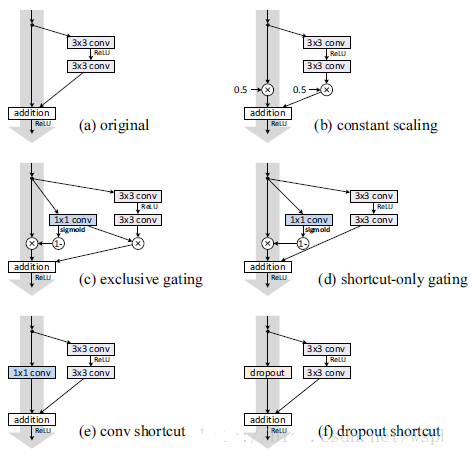
38.3 KB
drn/img/pic3.png
0 → 100644
{kind=link}
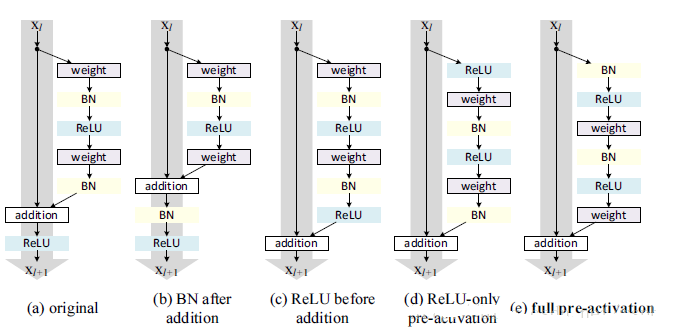
37.0 KB
drn/infer.py
0 → 100644
drn/train.py
0 → 100644
fluid/DeepQNetwork/DQN.py
0 → 100644
fluid/DeepQNetwork/README.md
0 → 100644
fluid/DeepQNetwork/agent.py
0 → 100644
fluid/DeepQNetwork/curve.png
0 → 100644
{kind=link}
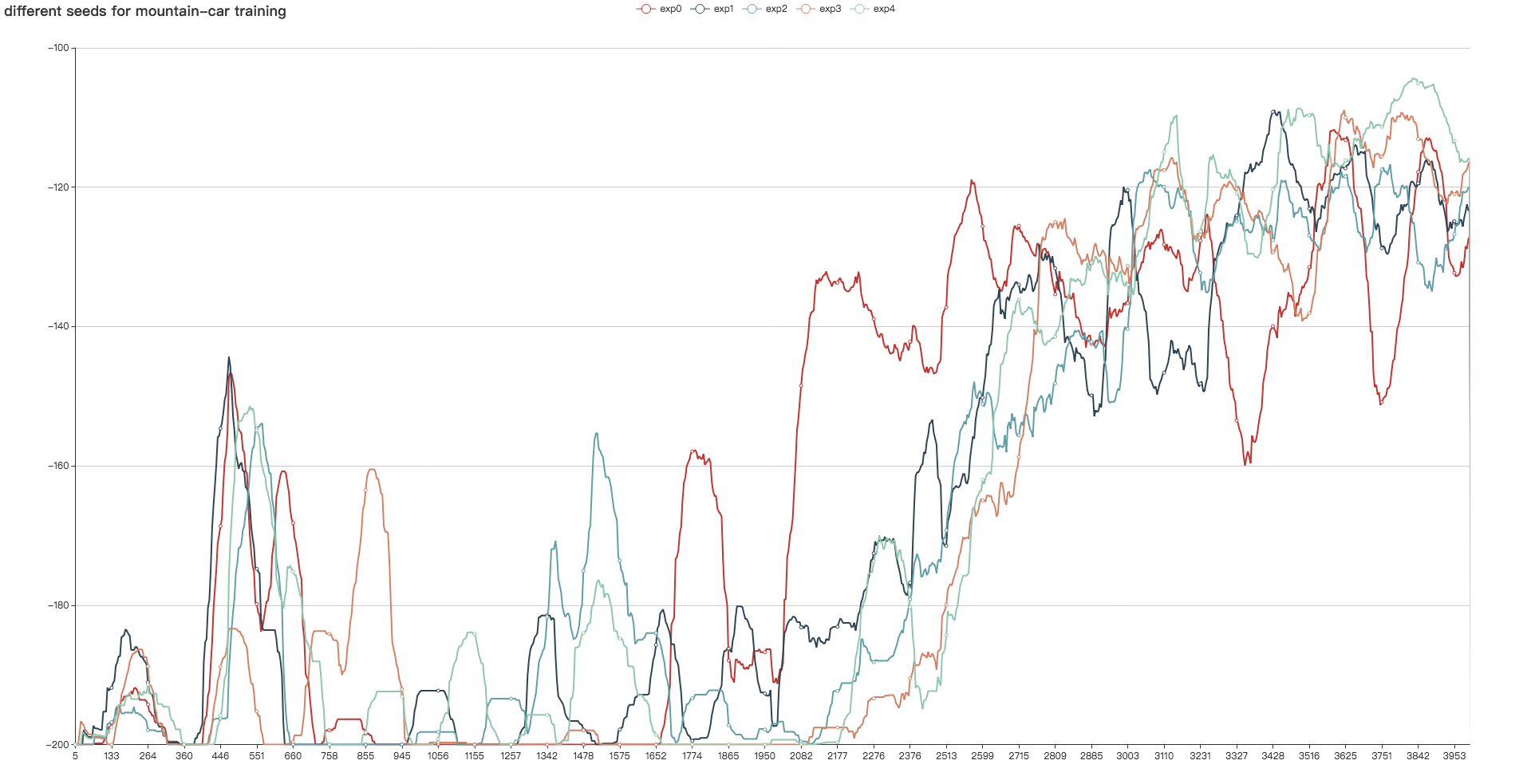
442.3 KB
fluid/DeepQNetwork/expreplay.py
0 → 100644
{kind=link}

98.6 KB