Merge branch 'develop' of https://github.com/PaddlePaddle/models into...
Merge branch 'develop' of https://github.com/PaddlePaddle/models into add-transformer-BeamsearchDecoder-dev
Showing
fluid/DeepQNetwork/DQN.py
0 → 100644
fluid/DeepQNetwork/README.md
0 → 100644
fluid/DeepQNetwork/agent.py
0 → 100644
fluid/DeepQNetwork/curve.png
0 → 100644
{kind=link}
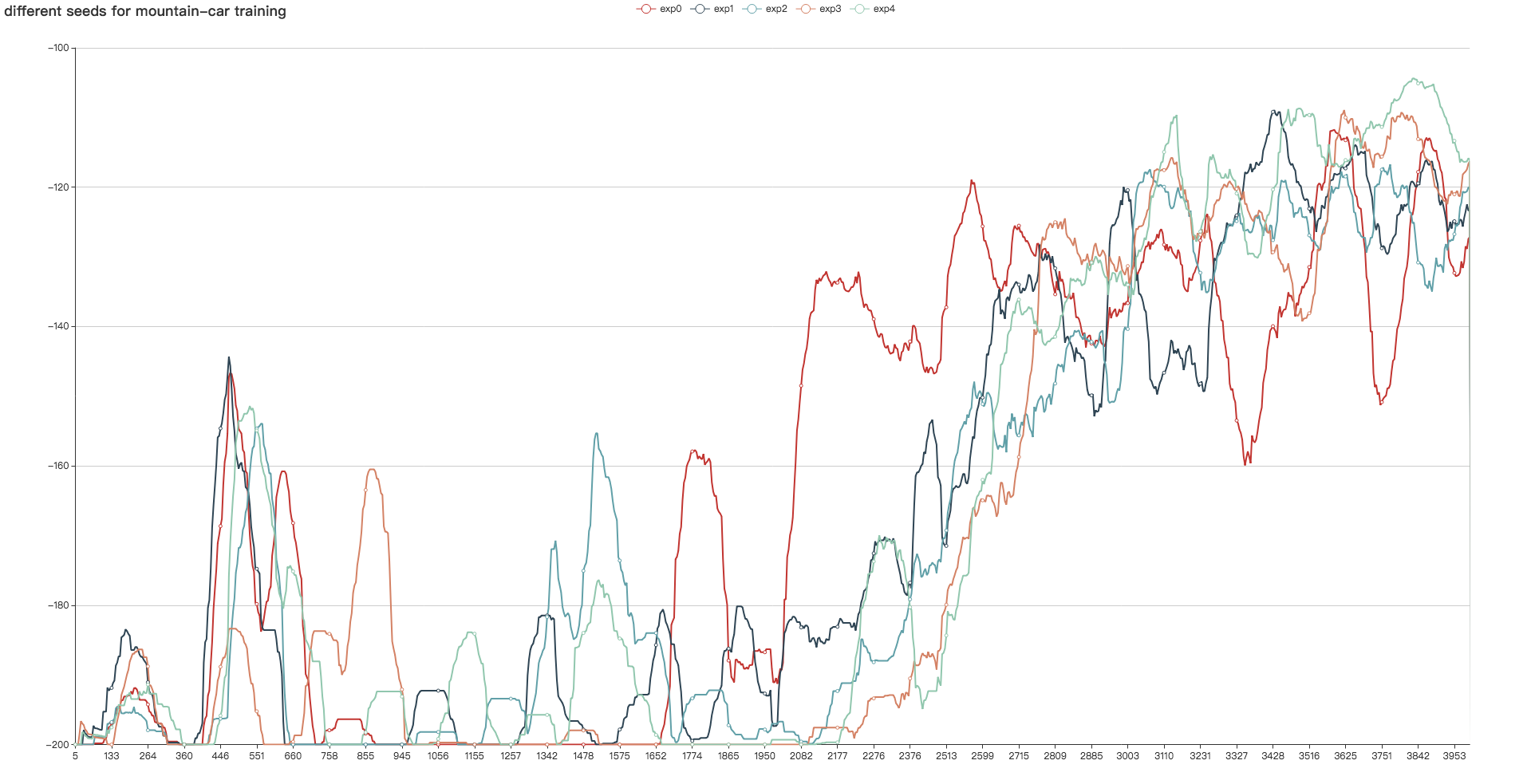
442.3 KB
fluid/DeepQNetwork/expreplay.py
0 → 100644
{kind=link}

98.6 KB
fluid/chinese_ner/README.md
0 → 100644
fluid/chinese_ner/data/label_dict
0 → 100644
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
fluid/chinese_ner/infer.py
0 → 100644
fluid/chinese_ner/reader.py
0 → 100644
fluid/chinese_ner/train.py
0 → 100644
此差异已折叠。
fluid/language_model/README.md
0 → 100644
fluid/language_model/infer.py
0 → 100644
此差异已折叠。
fluid/language_model/train.py
0 → 100644
此差异已折叠。
此差异已折叠。
fluid/language_model/utils.py
0 → 100644
此差异已折叠。
此差异已折叠。
{kind=link}

41.1 KB
{kind=link}

37.1 KB
{kind=link}

28.9 KB
{kind=link}

65.6 KB
{kind=link}

39.0 KB
fluid/object_detection/infer.py
0 → 100644
此差异已折叠。
{kind=link}
{kind=link}

| W: | H:

| W: | H:
此差异已折叠。
此差异已折叠。