Merge branch 'develop' of https://github.com/PaddlePaddle/models into add_ner_model
Showing
ltr/image/lambdarank.jpg
0 → 100644
{kind=link}
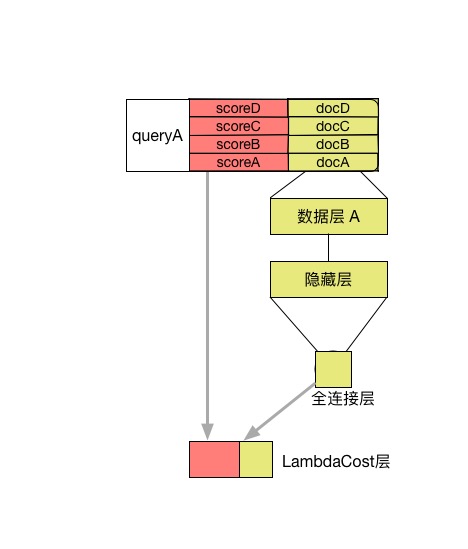
26.0 KB
ltr/image/learningToRank.jpg
0 → 100644
{kind=link}
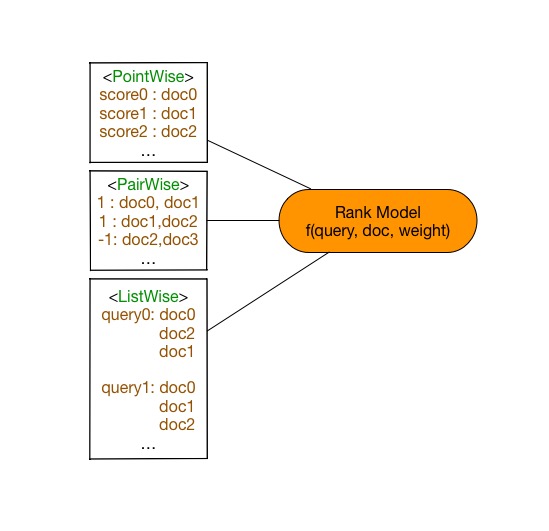
35.6 KB
ltr/image/ranknet.jpg
0 → 100644
{kind=link}
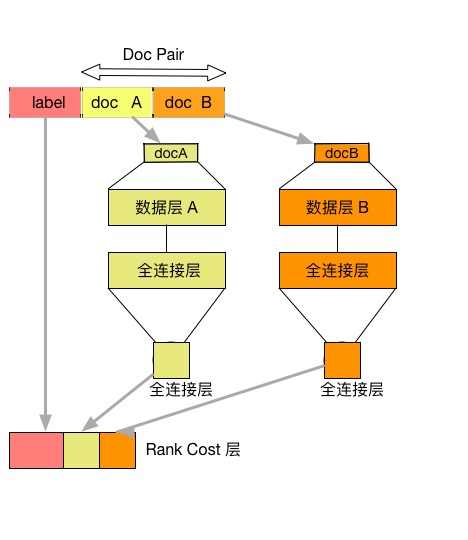
35.1 KB
{kind=link}
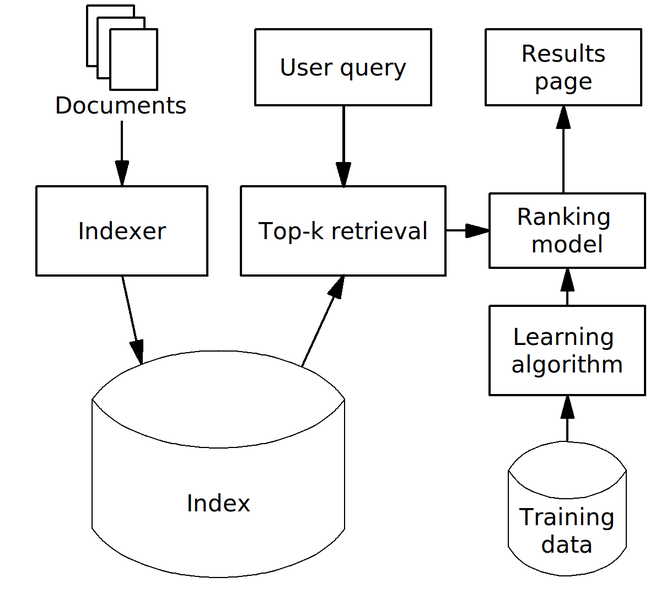
79.4 KB
ltr/lambdaRank.py
0 → 100644
ltr/metrics.py
0 → 100644
ltr/ranknet.py
0 → 100644
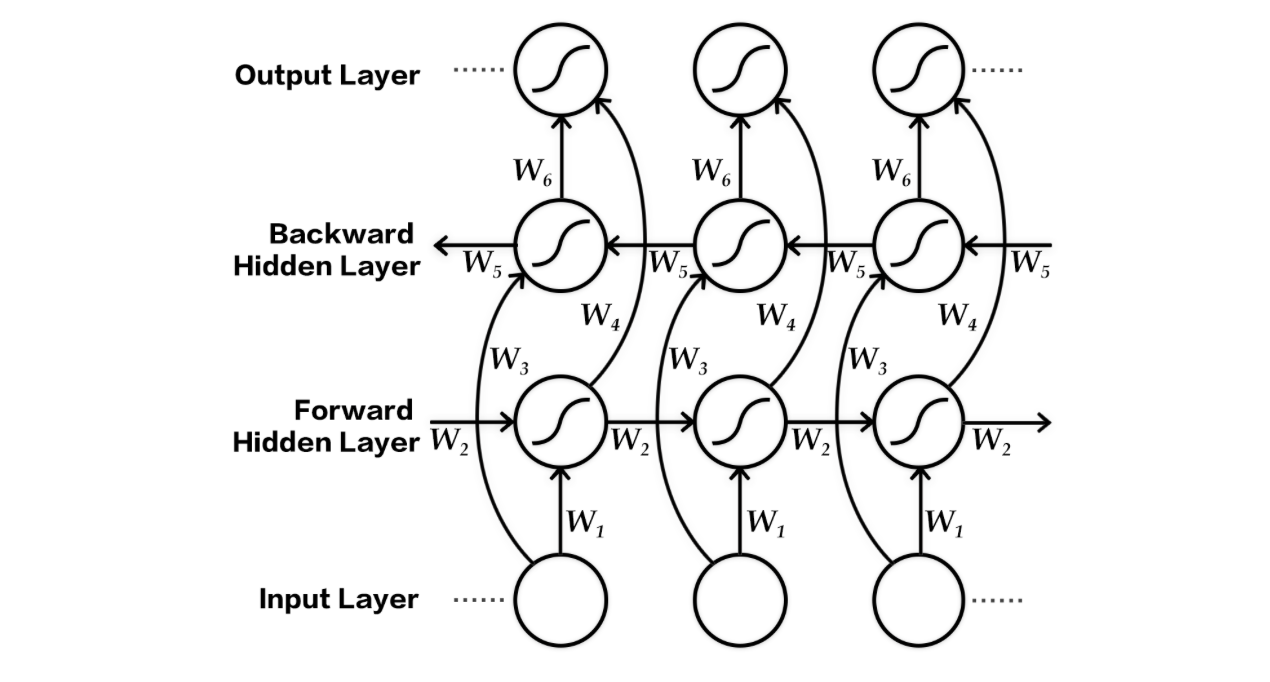
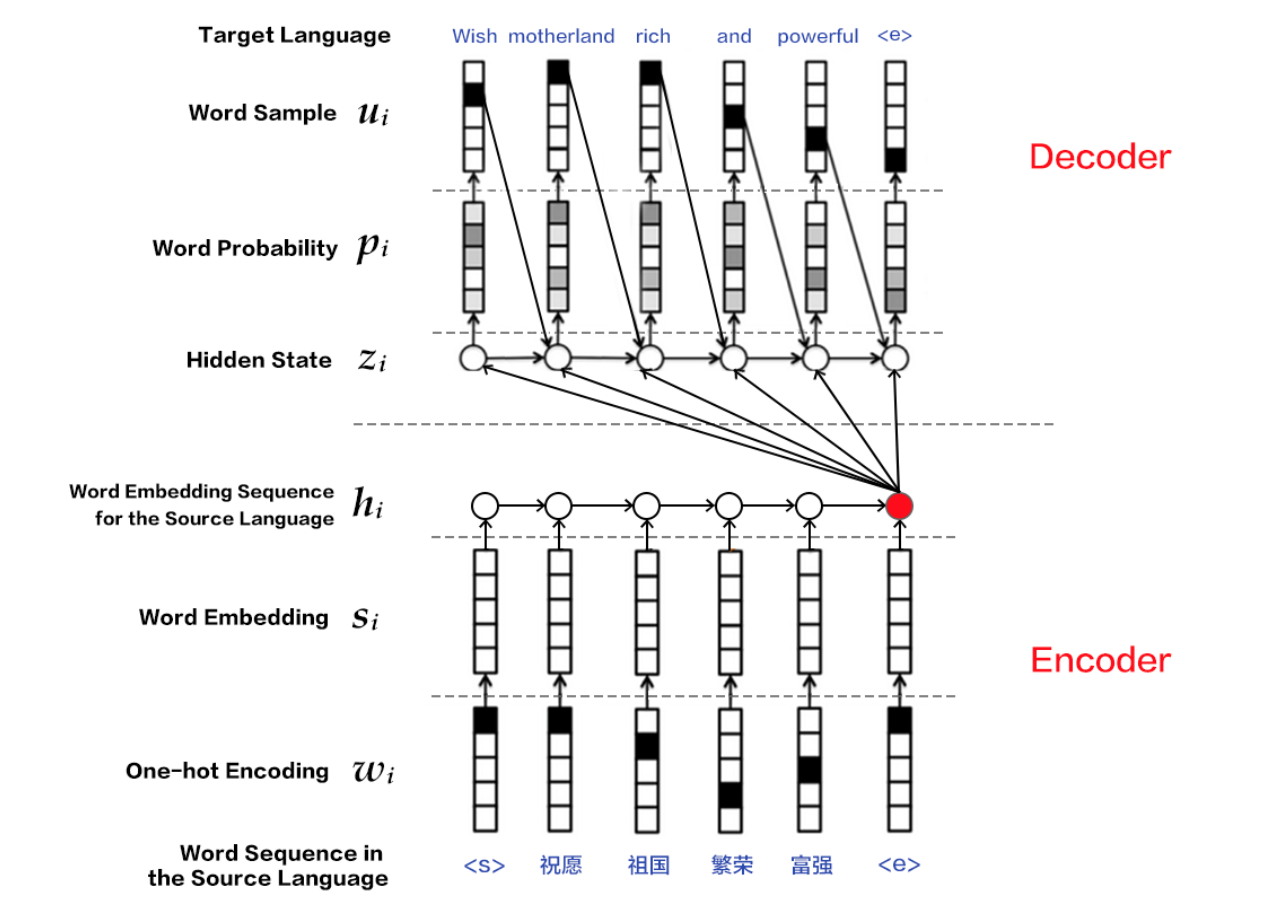
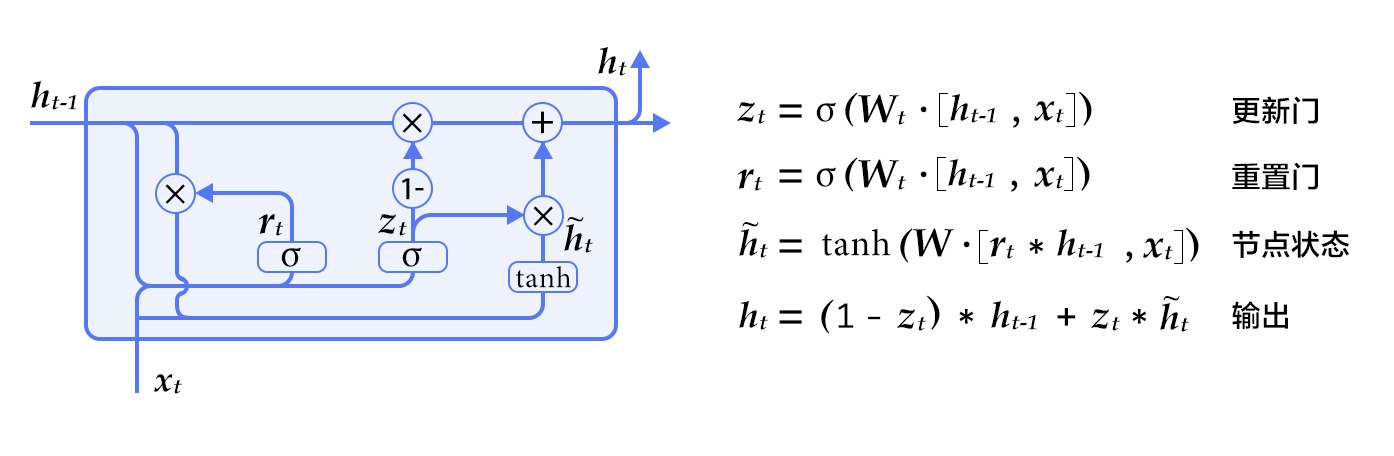
nmt_without_attention/README.md
0 → 100644
{kind=link}
246.7 KB
{kind=link}
325.3 KB
{kind=link}
45.2 KB
seq2seq/README.md
已删除
100644 → 0