Merge pull request #31 from dzhwinter/model_ltr2
Add the example for pairwise and listwise LTR.
Showing
ltr/image/lambdarank.jpg
0 → 100644
{kind=link}
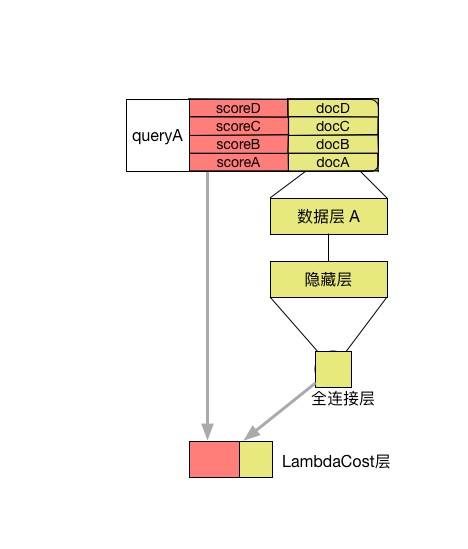
26.0 KB
ltr/image/learningToRank.jpg
0 → 100644
{kind=link}
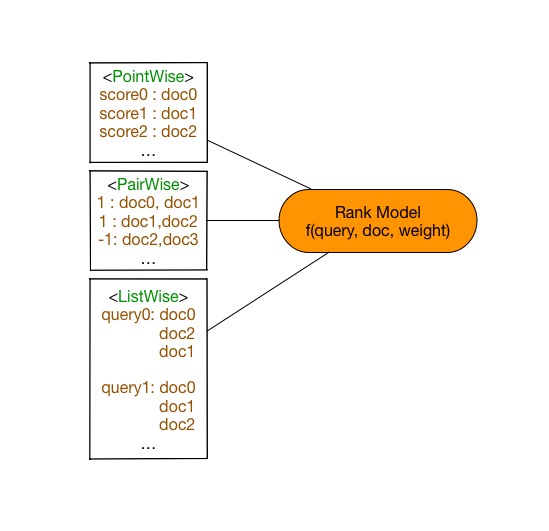
35.6 KB
ltr/image/ranknet.jpg
0 → 100644
{kind=link}
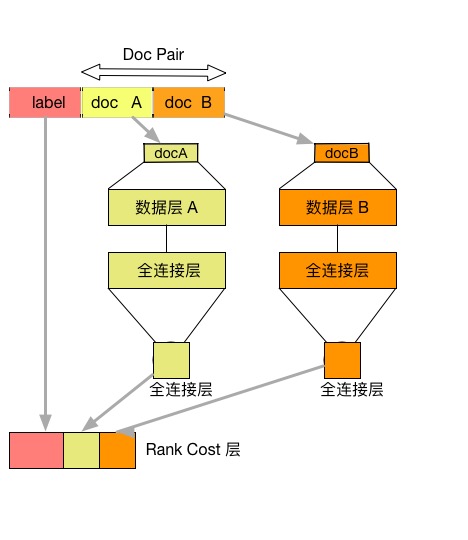
35.1 KB
{kind=link}
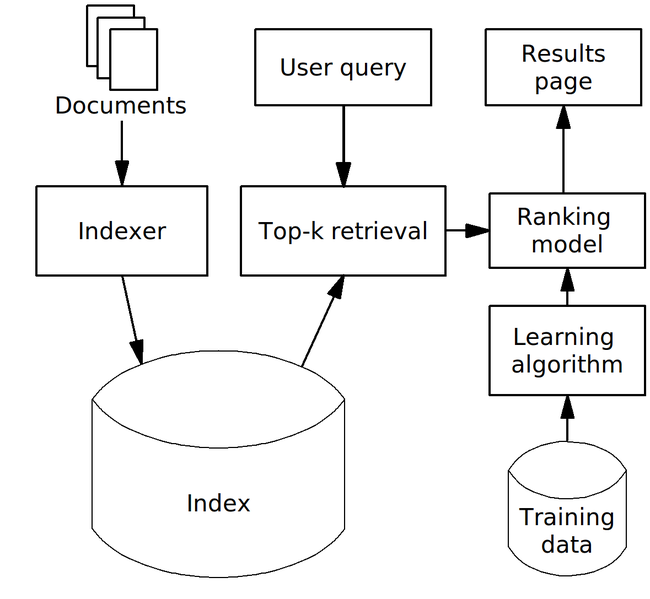
79.4 KB
ltr/lambdaRank.py
0 → 100644
ltr/metrics.py
0 → 100644
ltr/ranknet.py
0 → 100644