Merge pull request #24 from schinger/sentiment
Sentiment
Showing
understand_sentiment/.gitignore
0 → 100644
{kind=link}
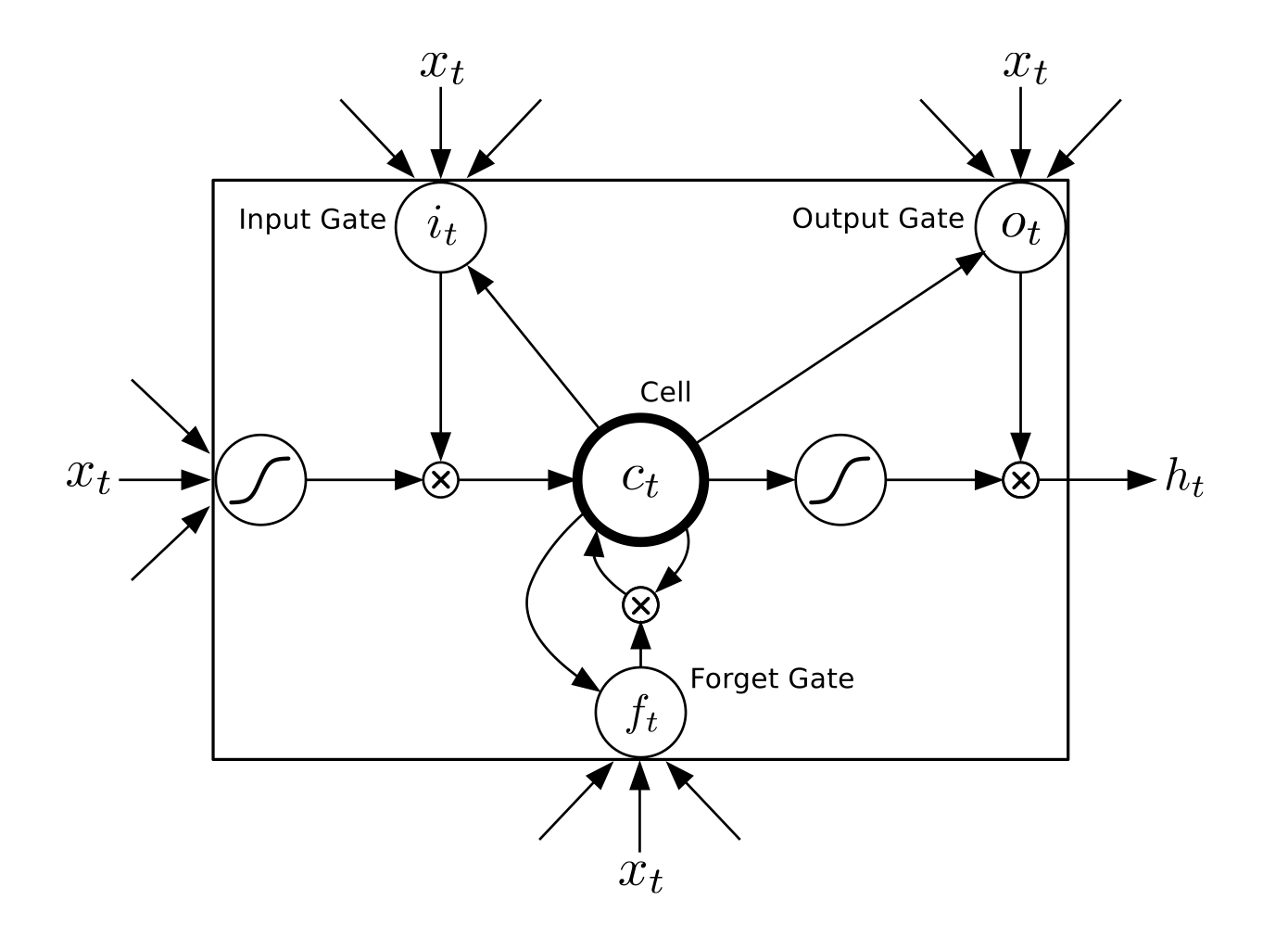
128.0 KB
{kind=link}
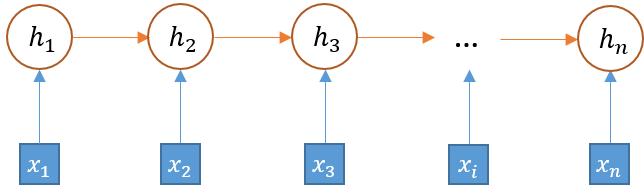
7.2 KB
{kind=link}

30.3 KB
{kind=link}
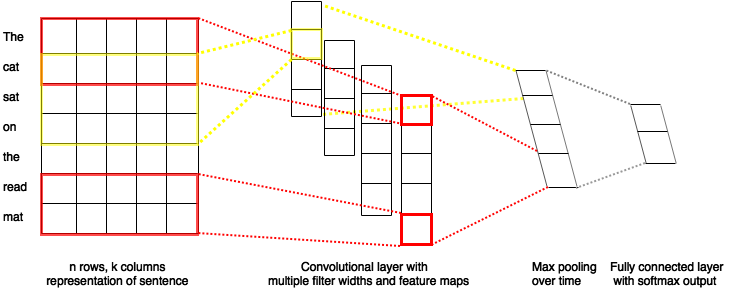
30.3 KB
understand_sentiment/predict.py
0 → 100755
understand_sentiment/predict.sh
0 → 100755
understand_sentiment/test.sh
0 → 100755
understand_sentiment/train.sh
0 → 100755