You need to sign in or sign up before continuing.
Merge pull request #12 from Zrachel/add_w2v
Add word2vec
Showing
word2vec/.gitignore
0 → 100644
此差异已折叠。
word2vec/calculate_dis.py
0 → 100755
word2vec/data/getdata.sh
0 → 100755
word2vec/dataprovider.py
0 → 100644
word2vec/format_convert.py
0 → 100755
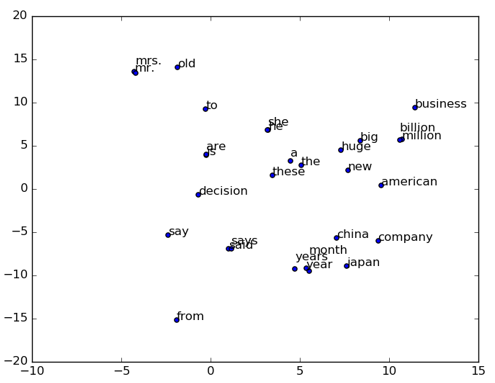
word2vec/image/2d_similarity.png
0 → 100644
{kind=link}
23.6 KB
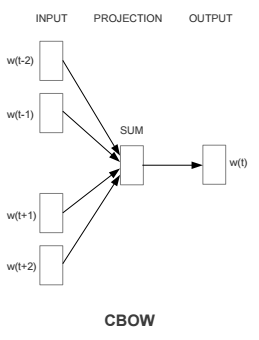
word2vec/image/cbow.png
0 → 100644
{kind=link}
11.0 KB
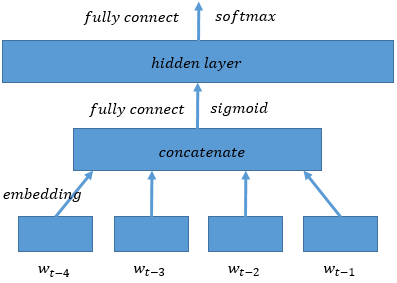
word2vec/image/ngram.png
0 → 100644
{kind=link}
9.1 KB
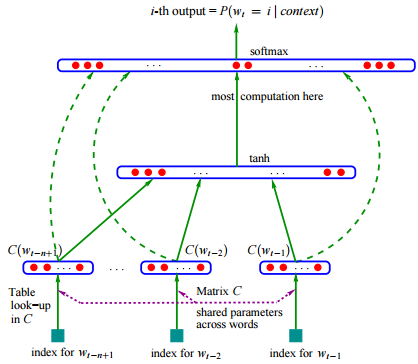
word2vec/image/nnlm.png
0 → 100644
{kind=link}
33.1 KB
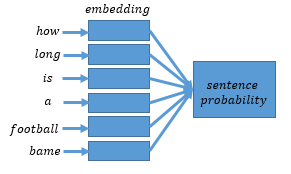
word2vec/image/sentence_emb.png
0 → 100644
{kind=link}
6.6 KB
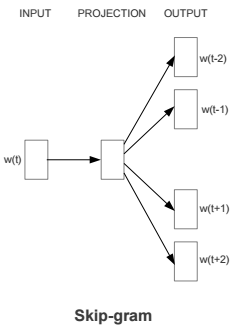
word2vec/image/skipgram.png
0 → 100644
{kind=link}
10.6 KB
word2vec/ngram.py
0 → 100644
word2vec/train.sh
0 → 100755