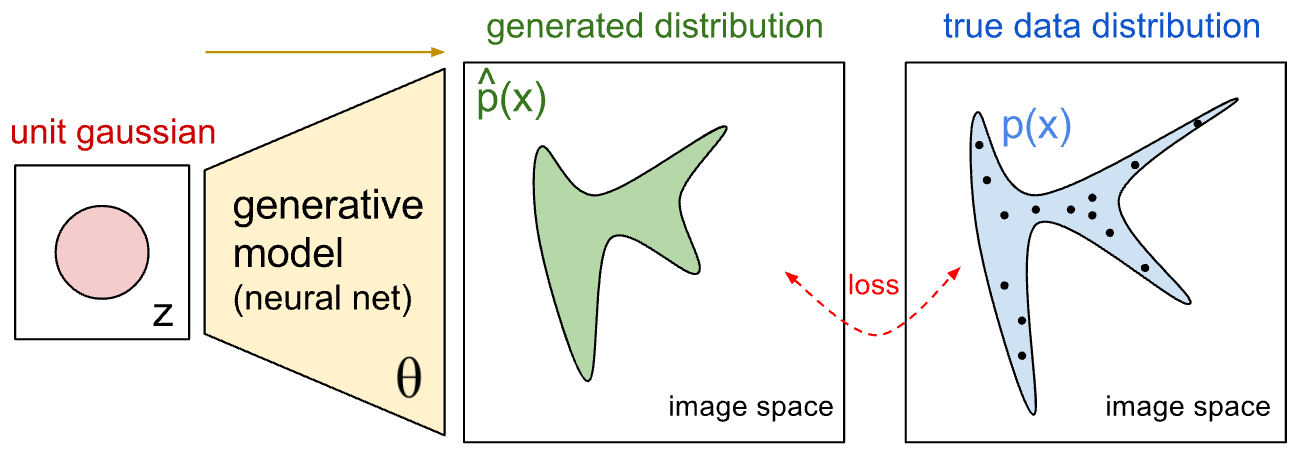
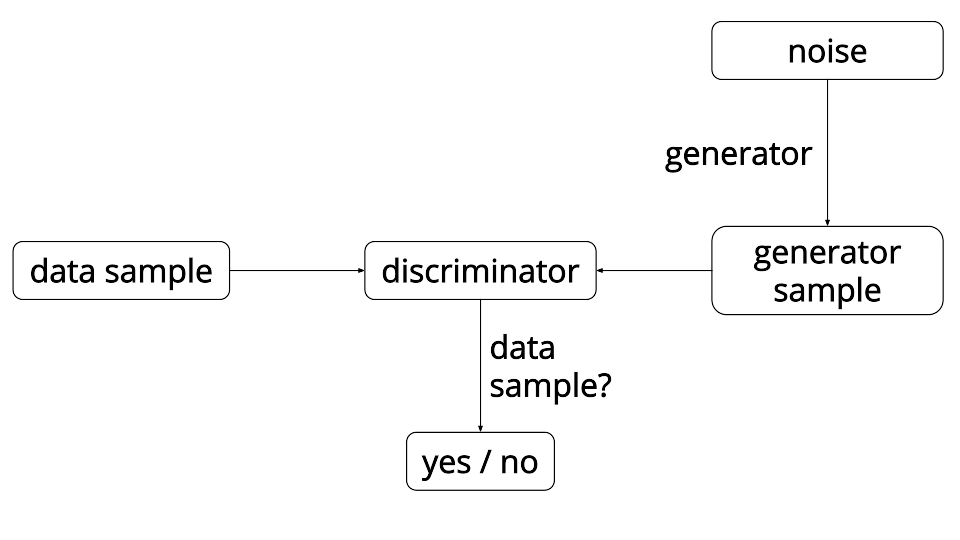
对抗式生成网络和之前的生成模型最大的创新就在于,用一个判别式神经网络来描述生成的概率分布和真实数据概率分布之间的差别。也就是说,我们用一个判别式模型 D 辅助构造优化目标函数,来训练一个生成式模型 G。G和D在训练时是处在相互对抗的角色下,G的目标是尽量生成和真实数据看起来相似的伪数据,从而使得D无法分别数据的真伪;而D的目标是能尽量分别出哪些是真实数据,哪些是G生成的伪数据。两者在竞争的条件下,能够相互提高各自的能力,最后收敛到一个均衡点:生成器生成的数据分布和真实数据分布完全一样,而判别器完全无法区分数据的真伪。
由于上面的这种网络都是由全联接层组成,所以没有办法很好的生成图片数据,也没有办法做的很深。所以在随后的论文中,人们提出了深度卷积对抗式生成网络(deep convolutional generative adversarial network or DCGAN)\[[2](#参考文献)\]。在DCGAN中,生成器 G 是由多个卷积转置层(transposed convolution)组成的,这样可以用更少的参数来生成质量更高的图片。具体网络结果可参见图4。而判别器是由多个卷积层组成。
由于上面的这种网络都是由全联接层组成,所以没有办法很好的生成图片数据,也没有办法做的很深。所以在随后的论文中,人们提出了深度卷积对抗式生成网络(deep convolutional generative adversarial network or DCGAN)\[[5](#参考文献)\]。在DCGAN中,生成器 G 是由多个卷积转置层(transposed convolution)组成的,这样可以用更少的参数来生成质量更高的图片。具体网络结果可参见图6。而判别器是由多个卷积层组成。
1. Goodfellow I, Pouget-Abadie J, Mirza M, et al. [Generative adversarial nets](https://arxiv.org/pdf/1406.2661v1.pdf)[C] Advances in Neural Information Processing Systems. 2014
2.Radford A, Metz L, Chintala S. [Unsupervised Representation Learning with Deep Convolutional Generative Adversarial Networks](https://arxiv.org/pdf/1511.06434v2.pdf)[C] arXiv preprint arXiv:1511.06434. 2015
2.van den Oord A, Kalchbrenner N and Kavukcuoglu K. [Pixel Recurrent Neural Networks](https://arxiv.org/pdf/1601.06759v3.pdf) arXiv preprint arXiv:1601.06759 (2016).
3. Kingma D.P. and Welling M. [Auto-encoding variational bayes](https://arxiv.org/pdf/1312.6114v10.pdf)[C] arXiv preprint arXiv:1312.6114. 2013
4. Hinton G and Salakhutdinov R. [Reducing the dimensionality of data with neural networks](https://www.cs.toronto.edu/~hinton/science.pdf) Science 313.5786. 2006
5. Salakhutdinov R and Hinton G. [Deep Boltzmann Machines](http://www.jmlr.org/proceedings/papers/v5/salakhutdinov09a/salakhutdinov09a.pdf)[J] AISTATS. Vol. 1. 2009
6. Larochelle H and Murray I. [The Neural Autoregressive Distribution Estimator](http://www.jmlr.org/proceedings/papers/v15/larochelle11a/larochelle11a.pdf) AISTATS. Vol. 1. 2011.
7. van den Oord A, Kalchbrenner N and Kavukcuoglu K. [Pixel Recurrent Neural Networks](https://arxiv.org/pdf/1601.06759v3.pdf) arXiv preprint arXiv:1601.06759 (2016).
4. Salakhutdinov R and Hinton G. [Deep Boltzmann Machines](http://www.jmlr.org/proceedings/papers/v5/salakhutdinov09a/salakhutdinov09a.pdf)[J] AISTATS. Vol. 1. 2009
5. Radford A, Metz L, Chintala S. [Unsupervised Representation Learning with Deep Convolutional Generative Adversarial Networks](https://arxiv.org/pdf/1511.06434v2.pdf)[C] arXiv preprint arXiv:1511.06434. 2015
{kind=link}
{kind=link}