
add 04.word2vec ce (#716)
* add ce * add ce * add 02.recognize_digits ce files * modify ce file code style of 01.fit_a_line and 02.recognize_digits * add 04.word2vec ce
Showing
01.fit_a_line/.run_ce.sh
0 → 100644
01.fit_a_line/_ce.py
0 → 100644
{kind=link}
{kind=link}
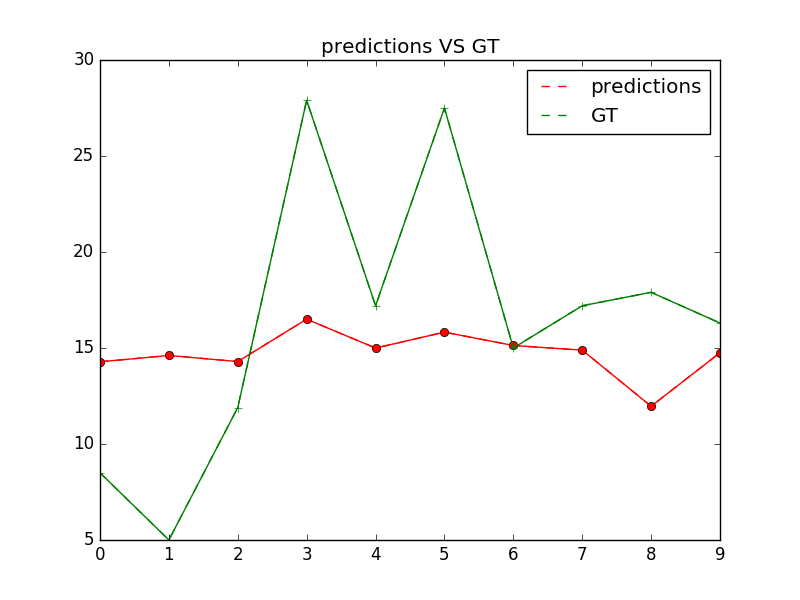
| W: | H:
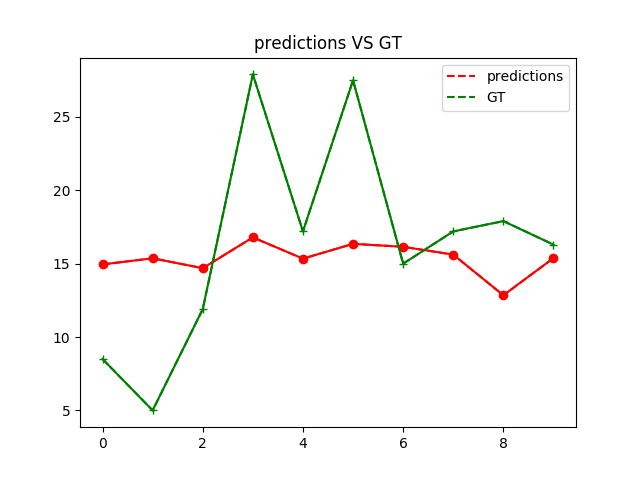
| W: | H:
{kind=link}
{kind=link}
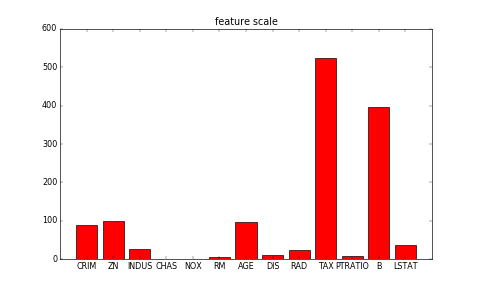
| W: | H:
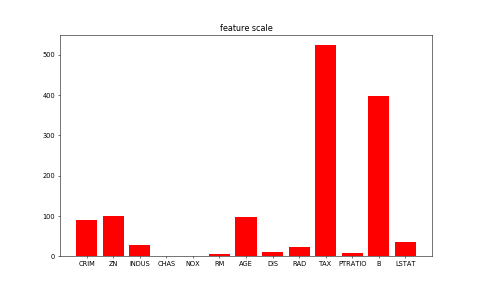
| W: | H:
02.recognize_digits/.run_ce.sh
0 → 100644
02.recognize_digits/_ce.py
0 → 100644
04.word2vec/.run_ce.sh
0 → 100644
04.word2vec/_ce.py
0 → 100644