Skip to content
体验新版
项目
组织
正在加载...
登录
切换导航
打开侧边栏
PaddlePaddle
book
提交
3088707a
B
book
项目概览
PaddlePaddle
/
book
通知
17
Star
4
Fork
0
代码
文件
提交
分支
Tags
贡献者
分支图
Diff
Issue
40
列表
看板
标记
里程碑
合并请求
37
Wiki
5
Wiki
分析
仓库
DevOps
项目成员
Pages
B
book
项目概览
项目概览
详情
发布
仓库
仓库
文件
提交
分支
标签
贡献者
分支图
比较
Issue
40
Issue
40
列表
看板
标记
里程碑
合并请求
37
合并请求
37
Pages
分析
分析
仓库分析
DevOps
Wiki
5
Wiki
成员
成员
收起侧边栏
关闭侧边栏
动态
分支图
创建新Issue
提交
Issue看板
提交
3088707a
编写于
12月 27, 2016
作者:
D
dangqingqing
浏览文件
操作
浏览文件
下载
电子邮件补丁
差异文件
Update README.md
上级
6fc2713a
变更
8
隐藏空白更改
内联
并排
Showing
8 changed file
with
79 addition
and
45 deletion
+79
-45
image_classification/README.md
image_classification/README.md
+71
-43
image_classification/image/ilsvrc.png
image_classification/image/ilsvrc.png
+0
-0
image_classification/image/resnet.png
image_classification/image/resnet.png
+0
-0
image_classification/image/resnet_block.jpg
image_classification/image/resnet_block.jpg
+0
-0
image_classification/image/vgg16.png
image_classification/image/vgg16.png
+0
-0
image_classification/models/resnet.py
image_classification/models/resnet.py
+3
-0
image_classification/models/vgg.py
image_classification/models/vgg.py
+4
-1
image_classification/train.sh
image_classification/train.sh
+1
-1
未找到文件。
image_classification/README.md
浏览文件 @
3088707a
...
...
@@ -3,16 +3,25 @@
## 背景介绍
图像
分类是计算机视觉中的一个核心问题,图像分类是根据图像的语义信息将不同类别图像区分开来的方法。一般来说,图像分类包括训练和预测两个阶段。在训练阶段,输入训练图片集合和每一张训练图片对应的标签,计算机学习得到预测函数。在测试阶段,输入无标签的测试图片,计算机输出测试图片所属的类别标签
。
图像
相比文字能够提供更加生动、容易理解、有趣及更具艺术感的信息,是人们转递与交换信息的总要来源。在本教程中,我们专注于图像识别领域的重要问题之一 - 图像分类
。
在图像分类任务中,如何提取图像的特征是至关重要的。图像的颜色、纹理、形状各自描述了图像的视觉特性,但各自丢失了一部分原始图像中的信息。基于深度学习的图像分类方法,利用图像像素信息作为输入,最大程度上保留了输入图像的所有信息;与此同时,采用卷积神经网络进行特征的提取和高层抽象,从而得到远超过传统方法的分类性能。
图像分类是根据图像的语义信息将不同类别图像区分开来,是计算机视觉中重要的基本问题,也是图像检测、图像分割、物体跟踪、行为分析等其他高层视觉任务的基础。
图像分类在很多领域有广泛应用,包括安防领域的人脸识别、智能视频分析等,交通领域的交通场景识别,互联网领域基于内容的图像检索、相册自动归类,医学领域图像识别等。
一般来说,图像分类通过手工特征或特征学习方法对整个图像进行全部描述,然后使用分类器判别物体类别,因此如何提取图像的特征至关重要。在深度学习算法之前使用较多的是基于词包模型的物体分类方法,词包模型的基本框架包括底层特征学习、特征编码、空间约束、分类器设计、模型融合等多个阶段。
而基于深度学习的图像分类方法,其基本思想是通过有监督或无监督的方式学习层次化的特征描述,来对物体进行从底层到高层的描述。深度学习模型之一 — 卷积神经网络(CNN)近年来在图像领域取得了惊人的成绩,CNN直接利用图像像素信息作为输入,最大程度上保留了输入图像的所有信息,通过卷积操作进行特征的提取和高层抽象,模型输出直接是图像识别的结果。这种基于"输入-输出"直接端到端学习方法取了非常好的效果,得到了广泛的应用。
本教程主要介绍图像分类模型,以及如何使用PaddlePaddle训练CNN模型。
## 效果展示
图像分类包括通用图像分类、细粒度图像分类等。下图展示了通用图像分类效果,即模型可以正确识别图像上的主要物体。
<p
align=
"center"
>
<img
src=
"image/image_classification.png
"
><br/>
<img
src=
"image/image_classification.png
"
width=
"350"
><br/>
图1. 通用物体分类展示
</p>
...
...
@@ -26,33 +35,78 @@
</p>
一个好的模型即要对不同类别识别正确,同时也应该能够对
变形、扰动后的图像正确识别,下图展示了一些图像的扰动,较好的模型会像人
一样能够正确识别。
一个好的模型即要对不同类别识别正确,同时也应该能够对
不同视角、光照、背景、变形或部分遮挡的图像正确识别(这里我们统一称作图像扰动),下图展示了一些图像的扰动,较好的模型会像聪明的人类
一样能够正确识别。
<p
align=
"center"
>
<img
src=
"image/variations.png"
><br/>
<img
src=
"image/variations.png"
width=
"550"
><br/>
图3. 扰动图片展示
</p>
## 模型概览
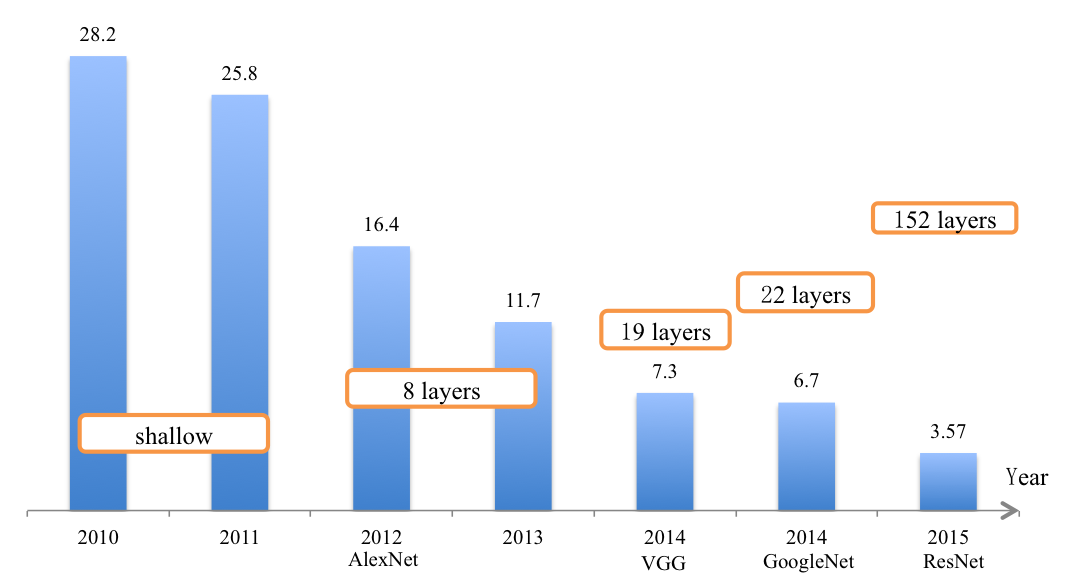
Alex Krizhevsky在2012年大规模视觉识别竞赛(ILSVRC 2012)的数据集(ImageNet)中提出的CNN模型 [1] 取得了历史性的突破,效果大幅度超越传统方法,获得了ILSVRC 2012冠军,该模型被称作AlexNet,这也是首次将深度学习用于大规模图像分类中,并使用GPU加速模型训练。从此,涌现了一系列CNN模型,不断的在ImageNet上刷新成绩。随着模型变得越来越深,Top-5的错误率也越来越低,目前降到了3.5%附近,而在同样的ImageNet数据集合上,人眼的辨识错误率大概在5.1%,也就是目前的深度学习模型的识别能力已经超过了人眼。
<p
align=
"center"
>
<img
src=
"image/ilsvrc.png"
width=
"450"
><br/>
图4. ILSVRC图像分类Top-5错误率
</p>
在本教程中我们主要采用VGG和ResNet网络结构,在介绍这两个模型之前,我们首先简单介绍CNN网络结构。
### CNN
卷积神经网络是一种使用卷积层的前向神经网络,很适合构建用于理解图片内容的模型。一个典型的神经网络如下图所示:
<p
align=
"center"
>
<img
src=
"image/lenet.png"
><br/>
图5. CNN网络示例
</p>
一个卷积神经网络包含如下层:
-
卷积层:通过卷积操作提取底层到高层的特征,并且保持了图像的空间信息。
-
池化层:是一种降采样操作,通过取卷积得到特征图中局部区块的最大值或平均值来达到降采样的目的,并在做这个过程中获得一定的不变性。
-
全连接层:使输入层到隐藏层的神经元是全部连接的。
-
非线性变化: sigmoid、tanh、relu等非线性变化增强网络表达能力。
卷积神经网络在图片分类上有着惊人的性能,这是因为它发掘出了图片的两类重要信息:局部关联性质和空间不变性质。通过交替使用卷积和池化处理, 卷积神经网络能够很好的表示这两类信息。
### VGG
[
VGG
](
https://arxiv.org/abs/1405.3531
)
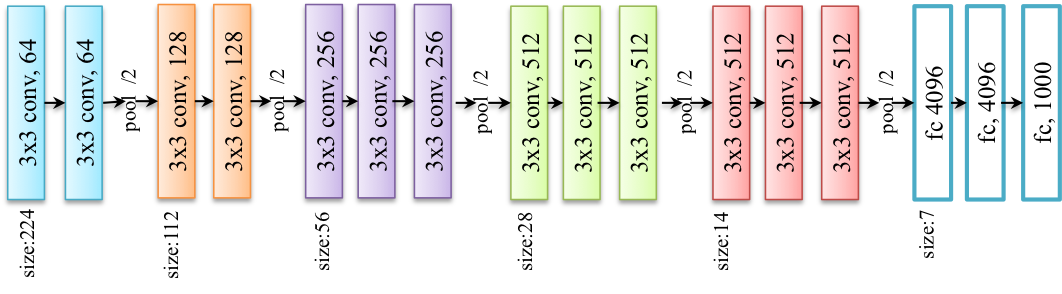
模型的核心是五组卷积操作,每两组之间做max-pooling空间降维。同一组内采用多次连续的3X3卷积,卷积核的数目由较浅组的64增多到最深组的512,同一组内的卷积核数目是一样的。卷积之后接两层全连接层,之后是分类层。VGG模型的计算量较大,收敛较慢。
[
VGG
](
https://arxiv.org/abs/1405.3531
)
模型的核心是五组卷积操作,每两组之间做max-pooling空间降维。同一组内采用多次连续的3X3卷积,卷积核的数目由较浅组的64增多到最深组的512,同一组内的卷积核数目是一样的。卷积之后接两层全连接层,之后是分类层。VGG模型的计算量较大,收敛较慢。
<p
align=
"center"
>
<img
src=
"image/vgg16.png"
width=
"500"
><br/>
图6. 基于ImageNet的VGG16网络示例
</p>
### ResNet
[
ResNet
](
https://arxiv.org/abs/1512.03385
)
是2015年ImageNet分类定位、检测比赛的冠军。针对训练卷积神经网络时加深网络导致准确度下降的问题,提出了采用残差学习。在已有设计思路(Batch Norm, 小卷积核,全卷积网络)的基础上,引入了残差模块。每个残差模块包含两条路径,其中一条路径是输入特征的直连通路,另一条路径对该特征做两到三次卷积操作得到该特征的残差,最后再将两条路径上的特征相加。ResNet成功的训练了上百乃至近千层的卷积神经网络,训练时收敛快,速度也较VGG有所提升。
[
ResNet
](
https://arxiv.org/abs/1512.03385
)
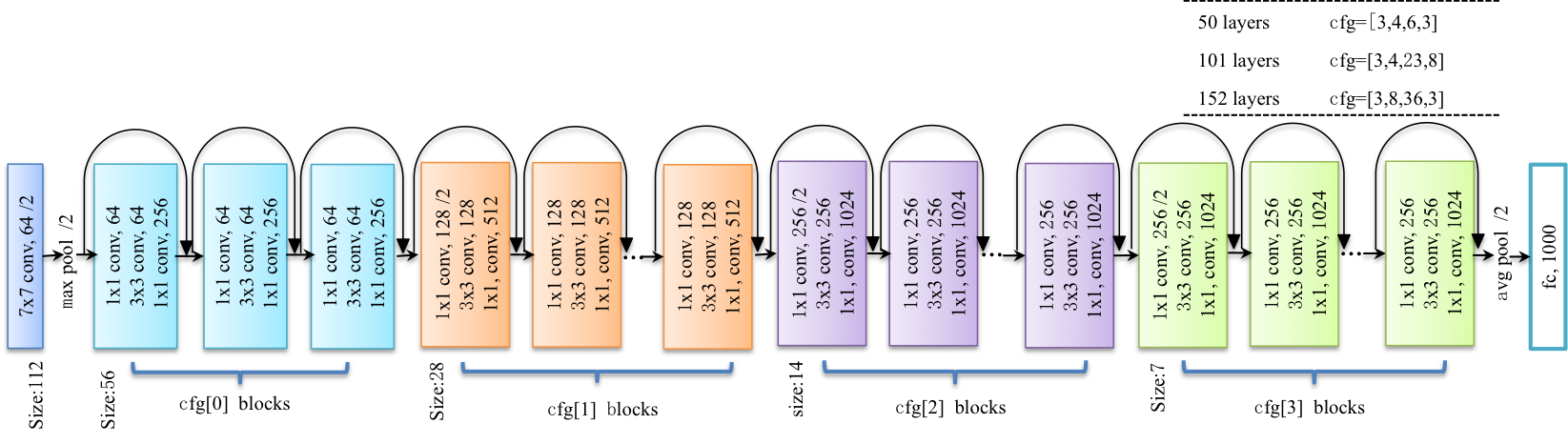
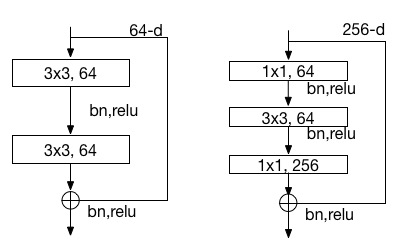
是2015年ImageNet分类定位、检测比赛的冠军。针对训练卷积神经网络时加深网络导致准确度下降的问题,提出了采用残差学习。在已有设计思路(Batch Norm, 小卷积核,全卷积网络)的基础上,引入了残差模块。每个残差模块包含两条路径,其中一条路径是输入特征的直连通路,另一条路径对该特征做两到三次卷积操作得到该特征的残差,最后再将两条路径上的特征相加。残差模块如图7所示,左边是基本模块连接方式,右边是瓶颈模块连接方式。图8展示了论文[2]中50-152层网络连接示意图。ResNet成功的训练了上百乃至近千层的卷积神经网络,训练时收敛快,速度也较VGG有所提升。
<p
align=
"center"
>
<img
src=
"image/resnet_block.jpg"
width=
"300"
><br/>
图7. 残差模块
</p>
<p
align=
"center"
>
<img
src=
"image/resnet.png"
><br/>
图8. 基于ImageNet的ResNet模型
</p>
## 数据准备
### 数据介绍与下载
在本教程中,我们使用
[
CIFAR
-10
](
<
https://www.cs.toronto.edu/~kriz/cifar.html
>
)
数据集训练一个卷积神经网络。CIFAR-
10数据集包含60,000张32x32的彩色图片,10个类别,每个类包含6,000张。其中50,000张图片作为训练集,10000张作为测试集。下图从每个类别中随机抽取了10张图片,展示了所有的类别。
在本教程中,我们使用
[
CIFAR
10
](
<
https://www.cs.toronto.edu/~kriz/cifar.html
>
)
数据集训练一个卷积神经网络。CIFAR
10数据集包含60,000张32x32的彩色图片,10个类别,每个类包含6,000张。其中50,000张图片作为训练集,10000张作为测试集。下图从每个类别中随机抽取了10张图片,展示了所有的类别。
<p
align=
"center"
>
<img
src=
"image/cifar.png"
><br/>
图3. CIFAR
-
10数据集
图3. CIFAR10数据集
</p>
...
...
@@ -64,7 +118,7 @@
### 数据提供器
我们使用Python接口传递数据给系统,下面
`dataprovider.py`
针对C
fiar-
10数据给出了完整示例。
我们使用Python接口传递数据给系统,下面
`dataprovider.py`
针对C
IFAR
10数据给出了完整示例。
`initializer`
函数进行dataprovider的初始化,这里加载图像的均值,定义了输入image和label两个字段的类型。
...
...
@@ -128,8 +182,7 @@ settings(
### 模型结构
在模型概览部分已经介绍了VGG和ResNet模型,本教程中我们提供了这两个模型的网络配置。
下面是VGG模型结构,在Cifar-10数据集上,卷积部分引入了Batch Norm和Dropout操作。
在模型概览部分已经介绍了VGG和ResNet模型,本教程中我们提供了这两个模型的网络配置。因为CIFAR10图片大小和数量相比ImageNet数据小很多,因此这里的模型针对CIFAR10数据做了一定的适配。首先介绍VGG模型结构,在CIFAR10数据集上,卷积部分引入了Batch Norm和Dropout操作。
1.
首先预定义了一组卷积网络,即conv_block, 所使用的
`img_conv_group`
是我们预定义的一个模块,由若干组
`Conv->BatchNorm->Relu->Dropout`
和 一组
`Pooling`
组成,其中卷积操作采用3x3的卷积核。下面定义中根据 groups 决定是几次连续的卷积操作。
...
...
@@ -182,12 +235,7 @@ def vgg_bn_drop(input, num_channels):
sh train.sh
```
执行脚本 train.sh 进行模型训练, 其中指定了总共需要执行500个pass。
在第一行中我们载入用于定义网络的函数。
配置创建完毕后,可以运行脚本train.sh来训练模型。
执行脚本 train.sh 进行模型训练, 其中指定配置文件、设备类型、线程个数、总共训练的轮数、模型存储路径等。
```
bash
#cfg=models/resnet.py
...
...
@@ -200,6 +248,7 @@ paddle train \
--use_gpu
=
true
\
--trainer_count
=
1
\
--log_period
=
100
\
--num_passes
=
300
\
--save_dir
=
$output
\
2>&1 |
tee
$log
```
...
...
@@ -210,7 +259,7 @@ paddle train \
-
`--log_period=100`
: 指定日志打印的batch间隔。
-
`--save_dir=$output`
: 指定模型存储路径。
一轮训练log示例如下所示,经过1个pass, 训练集上平均error为
classification_error_evaluator=0.79958 ,测试集上平均error为 classification_error_evaluator=
0.7858 。
一轮训练log示例如下所示,经过1个pass, 训练集上平均error为
0.79958 ,测试集上平均error为
0.7858 。
```
text
I1226 12:33:20.257822 25576 TrainerInternal.cpp:165] Batch=300 samples=38400 AvgCost=2.07708 CurrentCost=1.96158 Eval: classification_error_evaluator=0.81151 CurrentEval: classification_error_evaluator=0.789297
...
...
@@ -226,7 +275,7 @@ I1226 12:33:42.413450 25576 Tester.cpp:115] Test samples=10000 cost=1.99246 Eva
## 模型应用
在训练完成后,模型及参数会被保存在路径
`./
cifar_vgg_model/pass-%05d`
下。例如第300个pass的模型会被保存在
`./cifar_vgg_model
/pass-00299`
。
在训练完成后,模型及参数会被保存在路径
`./
output/pass-%05d`
下。例如第300个pass的模型会被保存在
`./output
/pass-00299`
。
要对一个图片的进行分类预测,我们可以使用
`predict.sh`
,该脚本将输出预测分类的标签:
...
...
@@ -236,36 +285,15 @@ sh predict.sh
predict.sh:
```
model=
cifar_vgg_model
/pass-00299/
model=
output
/pass-00299/
image=data/cifar-out/test/airplane/seaplane_s_000978.png
use_gpu=1
python prediction.py $model $image $use_gpu
```
## 练习
在CUB-200数据集上使用VGG模型训练一个鸟类图片分类模型。相关的鸟类数据集可以从如下地址下载,其中包含了200种鸟类的照片(主要来自北美洲)。
<http://www.vision.caltech.edu/visipedia/CUB-200.html>
## 细节探究
### 卷积神经网络
卷积神经网络是一种使用卷积层的前向神经网络,很适合构建用于理解图片内容的模型。一个典型的神经网络如下图所示:

一个卷积神经网络包含如下层:
-
卷积层:通过卷积操作从图片或特征图中提取特征
-
池化层:使用max-pooling对特征图下采样
-
全连接层:使输入层到隐藏层的神经元是全部连接的。
卷积神经网络在图片分类上有着惊人的性能,这是因为它发掘出了图片的两类重要信息:局部关联性质和空间不变性质。通过交替使用卷积和池化处理, 卷积神经网络能够很好的表示这两类信息。
关于如何定义网络中的层,以及如何在层之间进行连接,请参考Layer文档。
## 参考文献
[1]. K. Chatfield, K. Simonyan, A. Vedaldi, A. Zisserman. Return of the Devil in the Details: Delving Deep into Convolutional Nets. BMVC, 2014。
[2]. K. He, X. Zhang, S. Ren, J. Sun. Deep Residual Learning for Image Recognition. CVPR 2016.
image_classification/image/ilsvrc.png
0 → 100644
浏览文件 @
3088707a
120.5 KB
image_classification/image/resnet.png
0 → 100644
浏览文件 @
3088707a
343.4 KB
image_classification/image/resnet_block.jpg
0 → 100644
浏览文件 @
3088707a
21.9 KB
image_classification/image/vgg16.png
0 → 100644
浏览文件 @
3088707a
160.7 KB
image_classification/models/resnet.py
浏览文件 @
3088707a
...
...
@@ -120,6 +120,9 @@ if not is_predict:
settings
(
batch_size
=
128
,
learning_rate
=
0.1
/
128.0
,
learning_rate_decay_a
=
0.1
,
learning_rate_decay_b
=
50000
*
100
,
learning_rate_schedule
=
'discexp'
,
learning_method
=
MomentumOptimizer
(
0.9
),
regularization
=
L2Regularization
(
0.0005
*
128
))
...
...
image_classification/models/vgg.py
浏览文件 @
3088707a
...
...
@@ -61,8 +61,11 @@ if not is_predict:
settings
(
batch_size
=
128
,
learning_rate
=
0.1
/
128.0
,
learning_rate_decay_a
=
0.1
,
learning_rate_decay_b
=
50000
*
100
,
learning_rate_schedule
=
'discexp'
,
learning_method
=
MomentumOptimizer
(
0.9
),
regularization
=
L2Regularization
(
0.0005
*
128
))
regularization
=
L2Regularization
(
0.0005
*
128
)
,
)
data_size
=
3
*
32
*
32
class_num
=
10
...
...
image_classification/train.sh
浏览文件 @
3088707a
...
...
@@ -25,5 +25,5 @@ paddle train \
--trainer_count
=
4
\
--log_period
=
100
\
--num_passes
=
300
\
--save_dir
=
$output
\
--save_dir
=
$output
2>&1 |
tee
$log
编辑
预览
Markdown
is supported
0%
请重试
或
添加新附件
.
添加附件
取消
You are about to add
0
people
to the discussion. Proceed with caution.
先完成此消息的编辑!
取消
想要评论请
注册
或
登录
{kind=link}
{kind=link}
{kind=link}
{kind=link}