Skip to content
体验新版
项目
组织
正在加载...
登录
切换导航
打开侧边栏
PaddlePaddle
book
提交
120103b6
B
book
项目概览
PaddlePaddle
/
book
通知
17
Star
4
Fork
0
代码
文件
提交
分支
Tags
贡献者
分支图
Diff
Issue
40
列表
看板
标记
里程碑
合并请求
37
Wiki
5
Wiki
分析
仓库
DevOps
项目成员
Pages
B
book
项目概览
项目概览
详情
发布
仓库
仓库
文件
提交
分支
标签
贡献者
分支图
比较
Issue
40
Issue
40
列表
看板
标记
里程碑
合并请求
37
合并请求
37
Pages
分析
分析
仓库分析
DevOps
Wiki
5
Wiki
成员
成员
收起侧边栏
关闭侧边栏
动态
分支图
创建新Issue
提交
Issue看板
提交
120103b6
编写于
2月 15, 2019
作者:
C
ceci
浏览文件
操作
浏览文件
下载
电子邮件补丁
差异文件
fit a line
上级
b170a71e
变更
4
隐藏空白更改
内联
并排
Showing
4 changed file
with
197 addition
and
90 deletion
+197
-90
01.fit_a_line/README.cn.md
01.fit_a_line/README.cn.md
+90
-45
01.fit_a_line/image/prediction_gt.png
01.fit_a_line/image/prediction_gt.png
+0
-0
01.fit_a_line/index.cn.html
01.fit_a_line/index.cn.html
+90
-45
01.fit_a_line/train.py
01.fit_a_line/train.py
+17
-0
未找到文件。
01.fit_a_line/README.cn.md
浏览文件 @
120103b6
...
...
@@ -37,6 +37,12 @@ $$MSE=\frac{1}{n}\sum_{i=1}^{n}{(\hat{Y_i}-Y_i)}^2$$
即对于一个大小为$n$的测试集,$MSE$是$n$个数据预测结果误差平方的均值。
对损失函数进行优化所采用的方法一般为梯度下降法。梯度下降法是一种一阶最优化算法。如果$f(x)$在点$x_n$有定义且可微,则认为$f(x)$在点$x_n$沿着梯度的负方向$-▽f(x_n)$下降的是最快的。反复调节$x$,使得$f(x)$接近最小值或者极小值,调节的方式为:
$$x_n+1=x_n-λ▽f(x), n≧0$$
其中λ代表学习率。这种调节的方法称为梯度下降法。
### 训练过程
定义好模型结构之后,我们要通过以下几个步骤进行模型训练
...
...
@@ -131,30 +137,50 @@ test_reader = paddle.batch(
batch_size
=
BATCH_SIZE
)
```
如果想直接从txt文件中读取数据的话,可以参考以下代码。
```
python
filename
=
'housing.data'
feature_name
=
[
'CRIM'
,
'ZN'
,
'INDUS'
,
'CHAS'
,
'NOX'
,
'RM'
,
'AGE'
,
'DIS'
,
'RAD'
,
'TAX'
,
'PTRATIO'
,
'B'
,
'LSTAT'
,
'convert'
]
feature_num
=
len
(
feature_name
)
data
=
numpy
.
fromfile
(
filename
,
sep
=
' '
)
# 读取原始数据
data
=
data
.
reshape
(
data
.
shape
[
0
]
//
feature_num
,
feature_num
)
maximums
,
minimums
,
avgs
=
data
.
max
(
axis
=
0
),
data
.
min
(
axis
=
0
),
data
.
sum
(
axis
=
0
)
/
data
.
shape
[
0
]
for
i
in
six
.
moves
.
range
(
feature_num
-
1
):
data
[:,
i
]
=
(
data
[:,
i
]
-
avgs
[
i
])
/
(
maximums
[
i
]
-
minimums
[
i
])
ratio
=
0.8
# 训练集和验证集的划分比例
offset
=
int
(
data
.
shape
[
0
]
*
ratio
)
train_data
=
data
[:
offset
]
test_data
=
data
[
offset
:]
```
### 配置训练程序
训练程序的目的是定义一个训练模型的网络结构。对于线性回归来讲,它就是一个从输入到输出的简单的全连接层。更加复杂的结果,比如卷积神经网络,递归神经网络等会在随后的章节中介绍。训练程序必须返回
`平均损失`
作为第一个返回值,因为它会被后面反向传播算法所用到。
```
python
x
=
fluid
.
layers
.
data
(
name
=
'x'
,
shape
=
[
13
],
dtype
=
'float32'
)
y
=
fluid
.
layers
.
data
(
name
=
'y'
,
shape
=
[
1
],
dtype
=
'float32'
)
y_predict
=
fluid
.
layers
.
fc
(
input
=
x
,
size
=
1
,
act
=
None
)
x
=
fluid
.
layers
.
data
(
name
=
'x'
,
shape
=
[
13
],
dtype
=
'float32'
)
# 定义输入的形状和数据类型
y
=
fluid
.
layers
.
data
(
name
=
'y'
,
shape
=
[
1
],
dtype
=
'float32'
)
# 定义输出的形状和数据类型
y_predict
=
fluid
.
layers
.
fc
(
input
=
x
,
size
=
1
,
act
=
None
)
# 连接输入和输出的全连接层
main_program
=
fluid
.
default_main_program
()
startup_program
=
fluid
.
default_startup_program
()
main_program
=
fluid
.
[
default_main_program
](
http
:
//
www
.
paddlepaddle
.
org
/
documentation
/
docs
/
zh
/
develop
/
api_cn
/
fluid_cn
.
html
#default-main-program)
()
startup_program
=
fluid
.
[
default_startup_program
](
http
:
//
www
.
paddlepaddle
.
org
/
documentation
/
docs
/
zh
/
develop
/
api_cn
/
fluid_cn
.
html
#default-startup-program)
()
cost
=
fluid
.
layers
.
square_error_cost
(
input
=
y_predict
,
label
=
y
)
avg_loss
=
fluid
.
layers
.
mean
(
cost
)
cost
=
fluid
.
layers
.
square_error_cost
(
input
=
y_predict
,
label
=
y
)
# 利用标签数据和输出的预测数据估计方差
avg_loss
=
fluid
.
layers
.
mean
(
cost
)
# 对方差求均值,得到平均损失
```
### Optimizer Function 配置
在下面的
`SGD optimizer`
,
`learning_rate`
是
训练的速度
,与网络的训练收敛速度有关系。
在下面的
`SGD optimizer`
,
`learning_rate`
是
学习率
,与网络的训练收敛速度有关系。
```
python
sgd_optimizer
=
fluid
.
optimizer
.
SGD
(
learning_rate
=
0.001
)
sgd_optimizer
.
minimize
(
avg_loss
)
#
clone a test_program
#
克隆main_program得到test_program,有些operator在训练和测试之间的操作是不同的,例如batch_norm,使用参数for_test来区分该程序是用来训练还是用来测试,该api不会删除任何操作符,请在backward和optimization之前使用。
test_program
=
main_program
.
clone
(
for_test
=
True
)
```
...
...
@@ -163,26 +189,15 @@ test_program = main_program.clone(for_test=True)
```
python
use_cuda
=
False
place
=
fluid
.
CUDAPlace
(
0
)
if
use_cuda
else
fluid
.
CPUPlace
()
place
=
fluid
.
CUDAPlace
(
0
)
if
use_cuda
else
fluid
.
CPUPlace
()
# 指明executor的执行场所
###executor可以接受传入的program,并根据feed map(输入映射表)和fetch list(结果获取表)向program中添加数据输入算子和结果获取算子。使用close()关闭该executor,调用run(...)执行program,更多使用详情请参考[fluid.executor](http://www.paddlepaddle.org/documentation/docs/zh/develop/api_cn/fluid_cn.html#permalink-15-executor)
exe
=
fluid
.
Executor
(
place
)
```
除此之外,还可以通过画图,来展现
`训练进程`
:
```
python
# Plot data
from
paddle.utils.plot
import
Ploter
train_prompt
=
"Train cost"
test_prompt
=
"Test cost"
plot_prompt
=
Ploter
(
train_prompt
,
test_prompt
)
```
### 创建训练过程
训练需要有一个训练程序和一些必要参数,并构建了一个获取训练过程中测试误差的函数。
训练需要有一个训练程序和一些必要参数,并构建了一个获取训练过程中测试误差的函数。
必要参数有executor,program,reader,feeder,fetch_list,executor表示之前创建的执行器,program表示执行器所执行的program,是之前创建的program,如果该项参数没有给定的话则默认使用defalut_main_program,reader表示读取到的数据,feeder表示前向输入的变量,fetch_list表示用户想得到的变量或者命名的结果。
```
python
num_epochs
=
100
...
...
@@ -195,15 +210,34 @@ def train_test(executor, program, reader, feeder, fetch_list):
outs
=
executor
.
run
(
program
=
program
,
feed
=
feeder
.
feed
(
data_test
),
fetch_list
=
fetch_list
)
accumulated
=
[
x_c
[
0
]
+
x_c
[
1
][
0
]
for
x_c
in
zip
(
accumulated
,
outs
)]
count
+=
1
return
[
x_d
/
count
for
x_d
in
accumulated
]
accumulated
=
[
x_c
[
0
]
+
x_c
[
1
][
0
]
for
x_c
in
zip
(
accumulated
,
outs
)]
# 累加测试过程中的损失值
count
+=
1
# 累加测试集中的样本数量
return
[
x_d
/
count
for
x_d
in
accumulated
]
# 计算平均损失
```
可以直接输出损失值来观察
`训练进程`
:
```
python
train_prompt
=
"train cost"
test_prompt
=
"test cost"
print
(
"%s', out %f"
%
(
train_prompt
,
out
))
print
(
"%s', out %f"
%
(
test_prompt
,
out
))
```
除此之外,还可以通过画图,来展现
`训练进程`
:
```
python
# plot data
from
paddle.utils.plot
import
ploter
plot_prompt
=
ploter
(
train_prompt
,
test_prompt
)
```
### 训练主循环
PaddlePaddle提供了读取数据者发生器机制来读取训练数据。读取数据者会一次提供多列数据,因此我们需要一个Python的list来定义读取顺序。我们构建一个循环来进行训练,直到训练结果足够好或者循环次数足够多。
如果训练顺利,可以把训练参数保存到
`params_dirname`
。
首先给出需要存储的目录名,并初始化一个执行器
。
```
python
%
matplotlib
inline
...
...
@@ -215,8 +249,12 @@ naive_exe.run(startup_program)
step
=
0
exe_test
=
fluid
.
Executor
(
place
)
```
# main train loop.
paddlepaddle提供了reader机制来读取训练数据。reader会一次提供多列数据,因此我们需要一个python的列表来定义读取顺序。我们构建一个循环来进行训练,直到训练结果足够好或者循环次数足够多。
如果训练迭代次数满足参数保存的迭代次数,可以把训练参数保存到
`params_dirname`
。
其次设置训练主循环
```
python
for
pass_id
in
range
(
num_epochs
):
for
data_train
in
train_reader
():
avg_loss_value
,
=
exe
.
run
(
main_program
,
...
...
@@ -234,17 +272,19 @@ for pass_id in range(num_epochs):
plot_prompt
.
append
(
test_prompt
,
step
,
test_metics
[
0
])
plot_prompt
.
plot
()
# If the accuracy is good enough, we can stop the training.
if
test_metics
[
0
]
<
10.0
:
if
test_metics
[
0
]
<
10.0
:
# 如果准确率达到要求,则停止训练
break
step
+=
1
if
math
.
isnan
(
float
(
avg_loss_value
[
0
])):
sys
.
exit
(
"got NaN loss, training failed."
)
if
params_dirname
is
not
None
:
# We can save the trained parameters for the inferences later
fluid
.
io
.
save_inference_model
(
params_dirname
,
[
'x'
],
[
y_predict
],
exe
)
```
保存训练参数到之前给定的路径中
```
python
if
params_dirname
is
not
None
:
fluid
.
io
.
save_inference_model
(
params_dirname
,
[
'x'
],
[
y_predict
],
exe
)
```
## 预测
...
...
@@ -264,30 +304,35 @@ inference_scope = fluid.core.Scope()
```
python
with
fluid
.
scope_guard
(
inference_scope
):
[
inference_program
,
feed_target_names
,
fetch_targets
]
=
fluid
.
io
.
load_inference_model
(
params_dirname
,
infer_exe
)
fetch_targets
]
=
fluid
.
io
.
load_inference_model
(
params_dirname
,
infer_exe
)
# 载入预训练模型
batch_size
=
10
infer_reader
=
paddle
.
batch
(
paddle
.
dataset
.
uci_housing
.
test
(),
batch_size
=
batch_size
)
paddle
.
dataset
.
uci_housing
.
test
(),
batch_size
=
batch_size
)
# 准备测试集
infer_data
=
next
(
infer_reader
())
infer_feat
=
numpy
.
array
(
[
data
[
0
]
for
data
in
infer_data
]).
astype
(
"float32"
)
[
data
[
0
]
for
data
in
infer_data
]).
astype
(
"float32"
)
# 提取测试集中的数据
infer_label
=
numpy
.
array
(
[
data
[
1
]
for
data
in
infer_data
]).
astype
(
"float32"
)
[
data
[
1
]
for
data
in
infer_data
]).
astype
(
"float32"
)
# 提取测试集中的标签
assert
feed_target_names
[
0
]
==
'x'
results
=
infer_exe
.
run
(
inference_program
,
feed
=
{
feed_target_names
[
0
]:
numpy
.
array
(
infer_feat
)},
fetch_list
=
fetch_targets
)
fetch_list
=
fetch_targets
)
# 进行预测
```
打印预测结果和标签并可视化结果
```
python
print
(
"infer results: (House Price)"
)
for
idx
,
val
in
enumerate
(
results
[
0
]):
print
(
"%d: %.2f"
%
(
idx
,
val
))
# 打印预测结果
print
(
"infer results: (House Price)
"
)
for
idx
,
val
in
enumerate
(
results
[
0
]
):
print
(
"%d: %.2f"
%
(
idx
,
val
))
print
(
"
\n
ground truth:
"
)
for
idx
,
val
in
enumerate
(
infer_label
):
print
(
"%d: %.2f"
%
(
idx
,
val
))
# 打印标签值
print
(
"
\n
ground truth:"
)
for
idx
,
val
in
enumerate
(
infer_label
):
print
(
"%d: %.2f"
%
(
idx
,
val
))
save_result
(
results
[
0
],
infer_label
)
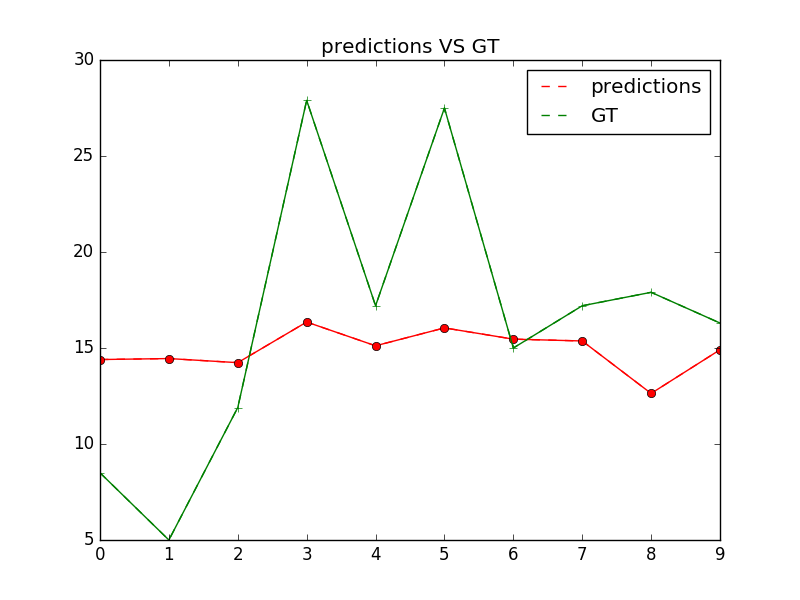
# 保存图片,该函数实现在train.py中
```
## 总结
...
...
01.fit_a_line/image/prediction_gt.png
0 → 100644
浏览文件 @
120103b6
42.4 KB
01.fit_a_line/index.cn.html
浏览文件 @
120103b6
...
...
@@ -79,6 +79,12 @@ $$MSE=\frac{1}{n}\sum_{i=1}^{n}{(\hat{Y_i}-Y_i)}^2$$
即对于一个大小为$n$的测试集,$MSE$是$n$个数据预测结果误差平方的均值。
对损失函数进行优化所采用的方法一般为梯度下降法。梯度下降法是一种一阶最优化算法。如果$f(x)$在点$x_n$有定义且可微,则认为$f(x)$在点$x_n$沿着梯度的负方向$-▽f(x_n)$下降的是最快的。反复调节$x$,使得$f(x)$接近最小值或者极小值,调节的方式为:
$$x_n+1=x_n-λ▽f(x), n≧0$$
其中λ代表学习率。这种调节的方法称为梯度下降法。
### 训练过程
定义好模型结构之后,我们要通过以下几个步骤进行模型训练
...
...
@@ -173,30 +179,50 @@ test_reader = paddle.batch(
batch_size=BATCH_SIZE)
```
如果想直接从txt文件中读取数据的话,可以参考以下代码。
```python
filename = 'housing.data'
feature_name = ['CRIM', 'ZN', 'INDUS', 'CHAS', 'NOX', 'RM', 'AGE',
'DIS', 'RAD', 'TAX', 'PTRATIO', 'B', 'LSTAT', 'convert']
feature_num = len(feature_name)
data = numpy.fromfile(filename, sep=' ') # 读取原始数据
data = data.reshape(data.shape[0] // feature_num, feature_num)
maximums, minimums, avgs = data.max(axis=0), data.min(axis=0), data.sum(axis=0)/data.shape[0]
for i in six.moves.range(feature_num-1):
data[:, i] = (data[:, i] - avgs[i]) / (maximums[i] - minimums[i])
ratio = 0.8 # 训练集和验证集的划分比例
offset = int(data.shape[0]*ratio)
train_data = data[:offset]
test_data = data[offset:]
```
### 配置训练程序
训练程序的目的是定义一个训练模型的网络结构。对于线性回归来讲,它就是一个从输入到输出的简单的全连接层。更加复杂的结果,比如卷积神经网络,递归神经网络等会在随后的章节中介绍。训练程序必须返回`平均损失`作为第一个返回值,因为它会被后面反向传播算法所用到。
```python
x = fluid.layers.data(name='x', shape=[13], dtype='float32')
y = fluid.layers.data(name='y', shape=[1], dtype='float32')
y_predict = fluid.layers.fc(input=x, size=1, act=None)
x = fluid.layers.data(name='x', shape=[13], dtype='float32')
# 定义输入的形状和数据类型
y = fluid.layers.data(name='y', shape=[1], dtype='float32')
# 定义输出的形状和数据类型
y_predict = fluid.layers.fc(input=x, size=1, act=None)
# 连接输入和输出的全连接层
main_program = fluid.
default_main_program
()
startup_program = fluid.
default_startup_program
()
main_program = fluid.
[default_main_program](http://www.paddlepaddle.org/documentation/docs/zh/develop/api_cn/fluid_cn.html#default-main-program)
()
startup_program = fluid.
[default_startup_program](http://www.paddlepaddle.org/documentation/docs/zh/develop/api_cn/fluid_cn.html#default-startup-program)
()
cost = fluid.layers.square_error_cost(input=y_predict, label=y)
avg_loss = fluid.layers.mean(cost)
cost = fluid.layers.square_error_cost(input=y_predict, label=y)
# 利用标签数据和输出的预测数据估计方差
avg_loss = fluid.layers.mean(cost)
# 对方差求均值,得到平均损失
```
### Optimizer Function 配置
在下面的 `SGD optimizer`,`learning_rate` 是
训练的速度
,与网络的训练收敛速度有关系。
在下面的 `SGD optimizer`,`learning_rate` 是
学习率
,与网络的训练收敛速度有关系。
```python
sgd_optimizer = fluid.optimizer.SGD(learning_rate=0.001)
sgd_optimizer.minimize(avg_loss)
#
clone a test_program
#
克隆main_program得到test_program,有些operator在训练和测试之间的操作是不同的,例如batch_norm,使用参数for_test来区分该程序是用来训练还是用来测试,该api不会删除任何操作符,请在backward和optimization之前使用。
test_program = main_program.clone(for_test=True)
```
...
...
@@ -205,26 +231,15 @@ test_program = main_program.clone(for_test=True)
```python
use_cuda = False
place = fluid.CUDAPlace(0) if use_cuda else fluid.CPUPlace()
place = fluid.CUDAPlace(0) if use_cuda else fluid.CPUPlace()
# 指明executor的执行场所
###executor可以接受传入的program,并根据feed map(输入映射表)和fetch list(结果获取表)向program中添加数据输入算子和结果获取算子。使用close()关闭该executor,调用run(...)执行program,更多使用详情请参考[fluid.executor](http://www.paddlepaddle.org/documentation/docs/zh/develop/api_cn/fluid_cn.html#permalink-15-executor)
exe = fluid.Executor(place)
```
除此之外,还可以通过画图,来展现`训练进程`:
```python
# Plot data
from paddle.utils.plot import Ploter
train_prompt = "Train cost"
test_prompt = "Test cost"
plot_prompt = Ploter(train_prompt, test_prompt)
```
### 创建训练过程
训练需要有一个训练程序和一些必要参数,并构建了一个获取训练过程中测试误差的函数。
训练需要有一个训练程序和一些必要参数,并构建了一个获取训练过程中测试误差的函数。
必要参数有executor,program,reader,feeder,fetch_list,executor表示之前创建的执行器,program表示执行器所执行的program,是之前创建的program,如果该项参数没有给定的话则默认使用defalut_main_program,reader表示读取到的数据,feeder表示前向输入的变量,fetch_list表示用户想得到的变量或者命名的结果。
```python
num_epochs = 100
...
...
@@ -237,15 +252,34 @@ def train_test(executor, program, reader, feeder, fetch_list):
outs = executor.run(program=program,
feed=feeder.feed(data_test),
fetch_list=fetch_list)
accumulated = [x_c[0] + x_c[1][0] for x_c in zip(accumulated, outs)]
count += 1
return [x_d / count for x_d in accumulated]
accumulated = [x_c[0] + x_c[1][0] for x_c in zip(accumulated, outs)] # 累加测试过程中的损失值
count += 1 # 累加测试集中的样本数量
return [x_d / count for x_d in accumulated] # 计算平均损失
```
可以直接输出损失值来观察`训练进程`:
```python
train_prompt = "train cost"
test_prompt = "test cost"
print("%s', out %f" % (train_prompt, out))
print("%s', out %f" % (test_prompt, out))
```
除此之外,还可以通过画图,来展现`训练进程`:
```python
# plot data
from paddle.utils.plot import ploter
plot_prompt = ploter(train_prompt, test_prompt)
```
### 训练主循环
PaddlePaddle提供了读取数据者发生器机制来读取训练数据。读取数据者会一次提供多列数据,因此我们需要一个Python的list来定义读取顺序。我们构建一个循环来进行训练,直到训练结果足够好或者循环次数足够多。
如果训练顺利,可以把训练参数保存到`params_dirname`
。
首先给出需要存储的目录名,并初始化一个执行器
。
```python
%matplotlib inline
...
...
@@ -257,8 +291,12 @@ naive_exe.run(startup_program)
step = 0
exe_test = fluid.Executor(place)
```
# main train loop.
paddlepaddle提供了reader机制来读取训练数据。reader会一次提供多列数据,因此我们需要一个python的列表来定义读取顺序。我们构建一个循环来进行训练,直到训练结果足够好或者循环次数足够多。
如果训练迭代次数满足参数保存的迭代次数,可以把训练参数保存到`params_dirname`。
其次设置训练主循环
```python
for pass_id in range(num_epochs):
for data_train in train_reader():
avg_loss_value, = exe.run(main_program,
...
...
@@ -276,17 +314,19 @@ for pass_id in range(num_epochs):
plot_prompt.append(test_prompt, step, test_metics[0])
plot_prompt.plot()
# If the accuracy is good enough, we can stop the training.
if test_metics[0]
<
10.0
:
if test_metics[0]
<
10.0
:
#
如果准确率达到要求
,
则停止训练
break
step
+=
1
if
math.isnan
(
float
(
avg_loss_value
[0]))
:
sys.exit
("
got
NaN
loss
,
training
failed.
")
if
params_dirname
is
not
None:
#
We
can
save
the
trained
parameters
for
the
inferences
later
fluid.io.save_inference_model
(
params_dirname
,
['
x
'],
[
y_predict
],
exe
)
```
保存训练参数到之前给定的路径中
```
python
if
params_dirname
is
not
None:
fluid.io.save_inference_model
(
params_dirname
,
['
x
'],
[
y_predict
],
exe
)
```
##
预测
...
...
@@ -306,30 +346,35 @@ inference_scope = fluid.core.Scope()
```
python
with
fluid.scope_guard
(
inference_scope
)
:
[
inference_program
,
feed_target_names
,
fetch_targets] =
fluid.io.load_inference_model(params_dirname,
infer_exe
)
fetch_targets] =
fluid.io.load_inference_model(params_dirname,
infer_exe
)
#
载入预训练模型
batch_size =
10
infer_reader =
paddle.batch(
paddle.dataset.uci_housing.test
(),
batch_size=
batch_size)
paddle.dataset.uci_housing.test
(),
batch_size=
batch_size)
#
准备测试集
infer_data =
next(infer_reader())
infer_feat =
numpy.array(
[
data
[0]
for
data
in
infer_data
]).
astype
("
float32
")
[
data
[0]
for
data
in
infer_data
]).
astype
("
float32
")
#
提取测试集中的数据
infer_label =
numpy.array(
[
data
[1]
for
data
in
infer_data
]).
astype
("
float32
")
[
data
[1]
for
data
in
infer_data
]).
astype
("
float32
")
#
提取测试集中的标签
assert
feed_target_names[0] =
=
'
x
'
results =
infer_exe.run(inference_program,
feed=
{feed_target_names[0]:
numpy.array
(
infer_feat
)},
fetch_list=
fetch_targets)
fetch_list=
fetch_targets)
#
进行预测
```
打印预测结果和标签并可视化结果
```
python
print
("
infer
results:
(
House
Price
)")
for
idx
,
val
in
enumerate
(
results
[0])
:
print
("%
d:
%.2
f
"
%
(
idx
,
val
))
#
打印预测结果
print
("
infer
results:
(
House
Price
)
")
for
idx
,
val
in
enumerate
(
results
[0]
)
:
print
("%
d:
%.2
f
"
%
(
idx
,
val
))
print
("\
nground
truth:
")
for
idx
,
val
in
enumerate
(
infer_label
)
:
print
("%
d:
%.2
f
"
%
(
idx
,
val
))
#
打印标签值
print
("\
nground
truth:
")
for
idx
,
val
in
enumerate
(
infer_label
)
:
print
("%
d:
%.2
f
"
%
(
idx
,
val
))
save_result
(
results
[0],
infer_label
)
#
保存图片
,
该函数实现在train.py中
```
##
总结
...
...
01.fit_a_line/train.py
浏览文件 @
120103b6
...
...
@@ -33,6 +33,21 @@ def train_test(executor, program, reader, feeder, fetch_list):
return
[
x_d
/
count
for
x_d
in
accumulated
]
def
save_result
(
points1
,
points2
):
import
matplotlib
matplotlib
.
use
(
'Agg'
)
import
matplotlib.pyplot
as
plt
x1
=
[
idx
for
idx
in
range
(
len
(
points1
))]
y1
=
points1
y2
=
points2
l1
=
plt
.
plot
(
x1
,
y1
,
'r--'
,
label
=
'predictions'
)
l2
=
plt
.
plot
(
x1
,
y2
,
'g--'
,
label
=
'GT'
)
plt
.
plot
(
x1
,
y1
,
'ro-'
,
x1
,
y2
,
'g+-'
)
plt
.
title
(
'predictions VS GT'
)
plt
.
legend
()
plt
.
savefig
(
'./image/prediction_gt.png'
)
def
main
():
batch_size
=
20
train_reader
=
paddle
.
batch
(
...
...
@@ -141,6 +156,8 @@ def main():
for
idx
,
val
in
enumerate
(
infer_label
):
print
(
"%d: %.2f"
%
(
idx
,
val
))
save_result
(
results
[
0
],
infer_label
)
if
__name__
==
'__main__'
:
main
()
编辑
预览
Markdown
is supported
0%
请重试
或
添加新附件
.
添加附件
取消
You are about to add
0
people
to the discussion. Proceed with caution.
先完成此消息的编辑!
取消
想要评论请
注册
或
登录
{kind=link}