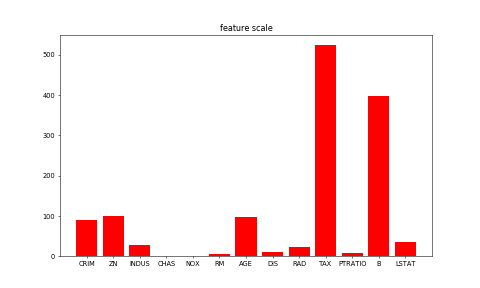
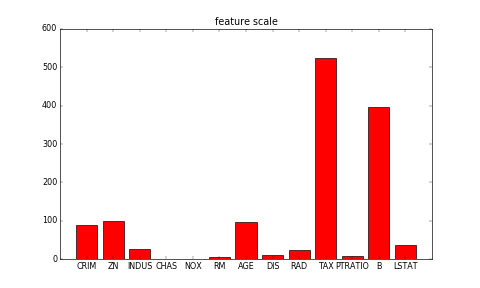
一般来说,图像分类通过手工特征或特征学习方法对整个图像进行全部描述,然后使用分类器判别物体类别,因此如何提取图像的特征至关重要。在深度学习算法之前使用较多的是基于词袋(Bag of Words)模型的物体分类方法。词袋方法从自然语言处理中引入,即一句话可以用一个装了词的袋子表示其特征,袋子中的词为句子中的单词、短语或字。对于图像而言,词袋方法需要构建字典。最简单的词袋模型框架可以设计为**底层特征抽取**、**特征编码**、**分类器设计**三个过程。
一般来说,图像分类通过手工提取特征或特征学习方法对整个图像进行全部描述,然后使用分类器判别物体类别,因此如何提取图像的特征至关重要。在深度学习算法之前使用较多的是基于词袋(Bag of Words)模型的物体分类方法。词袋方法从自然语言处理中引入,即一句话可以用一个装了词的袋子表示其特征,袋子中的词为句子中的单词、短语或字。对于图像而言,词袋方法需要构建字典。最简单的词袋模型框架可以设计为**底层特征抽取**、**特征编码**、**分类器设计**三个过程。
Alex Krizhevsky在2012年ILSVRC提出的CNN模型 \[[9](#参考文献)\] 取得了历史性的突破,效果大幅度超越传统方法,获得了ILSVRC2012冠军,该模型被称作AlexNet。这也是首次将深度学习用于大规模图像分类中。从AlexNet之后,涌现了一系列CNN模型,不断地在ImageNet上刷新成绩,如图4展示。随着模型变得越来越深以及精妙的结构设计,Top-5的错误率也越来越低,降到了3.5%附近。而在同样的ImageNet数据集上,人眼的辨识错误率大概在5.1%,也就是目前的深度学习模型的识别能力已经超过了人眼。
...
...
@@ -77,7 +77,7 @@ Alex Krizhevsky在2012年ILSVRC提出的CNN模型 \[[9](#参考文献)\] 取得
一般来说,图像分类通过手工特征或特征学习方法对整个图像进行全部描述,然后使用分类器判别物体类别,因此如何提取图像的特征至关重要。在深度学习算法之前使用较多的是基于词袋(Bag of Words)模型的物体分类方法。词袋方法从自然语言处理中引入,即一句话可以用一个装了词的袋子表示其特征,袋子中的词为句子中的单词、短语或字。对于图像而言,词袋方法需要构建字典。最简单的词袋模型框架可以设计为**底层特征抽取**、**特征编码**、**分类器设计**三个过程。
一般来说,图像分类通过手工提取特征或特征学习方法对整个图像进行全部描述,然后使用分类器判别物体类别,因此如何提取图像的特征至关重要。在深度学习算法之前使用较多的是基于词袋(Bag of Words)模型的物体分类方法。词袋方法从自然语言处理中引入,即一句话可以用一个装了词的袋子表示其特征,袋子中的词为句子中的单词、短语或字。对于图像而言,词袋方法需要构建字典。最简单的词袋模型框架可以设计为**底层特征抽取**、**特征编码**、**分类器设计**三个过程。
Alex Krizhevsky在2012年ILSVRC提出的CNN模型 \[[9](#参考文献)\] 取得了历史性的突破,效果大幅度超越传统方法,获得了ILSVRC2012冠军,该模型被称作AlexNet。这也是首次将深度学习用于大规模图像分类中。从AlexNet之后,涌现了一系列CNN模型,不断地在ImageNet上刷新成绩,如图4展示。随着模型变得越来越深以及精妙的结构设计,Top-5的错误率也越来越低,降到了3.5%附近。而在同样的ImageNet数据集上,人眼的辨识错误率大概在5.1%,也就是目前的深度学习模型的识别能力已经超过了人眼。
...
...
@@ -119,7 +119,7 @@ Alex Krizhevsky在2012年ILSVRC提出的CNN模型 \[[9](#参考文献)\] 取得
Yoshua Bengio等科学家就于2003年在著名论文 Neural Probabilistic Language Models \[[1](#参考文献)\] 中介绍如何学习一个神经元网络表示的词向量模型。文中的神经概率语言模型(Neural Network Language Model,NNLM)通过一个线性映射和一个非线性隐层连接,同时学习了语言模型和词向量,即通过学习大量语料得到词语的向量表达,通过这些向量得到整个句子的概率。用这种方法学习语言模型可以克服维度灾难(curse of dimensionality),即训练和测试数据不同导致的模型不准。注意:由于“神经概率语言模型”说法较为泛泛,我们在这里不用其NNLM的本名,考虑到其具体做法,本文中称该模型为N-gram neural model。
Yoshua Bengio等科学家就于2003年在著名论文 Neural Probabilistic Language Models \[[1](#参考文献)\] 中介绍如何学习一个神经元网络表示的词向量模型。文中的神经概率语言模型(Neural Network Language Model,NNLM)通过一个线性映射和一个非线性隐层连接,同时学习了语言模型和词向量,即通过学习大量语料得到词语的向量表达,通过这些向量得到整个句子的概率。因所有的词语都用一个低维向量来表示,用这种方法学习语言模型可以克服维度灾难(curse of dimensionality)。注意:由于“神经概率语言模型”说法较为泛泛,我们在这里不用其NNLM的本名,考虑到其具体做法,本文中称该模型为N-gram neural model。
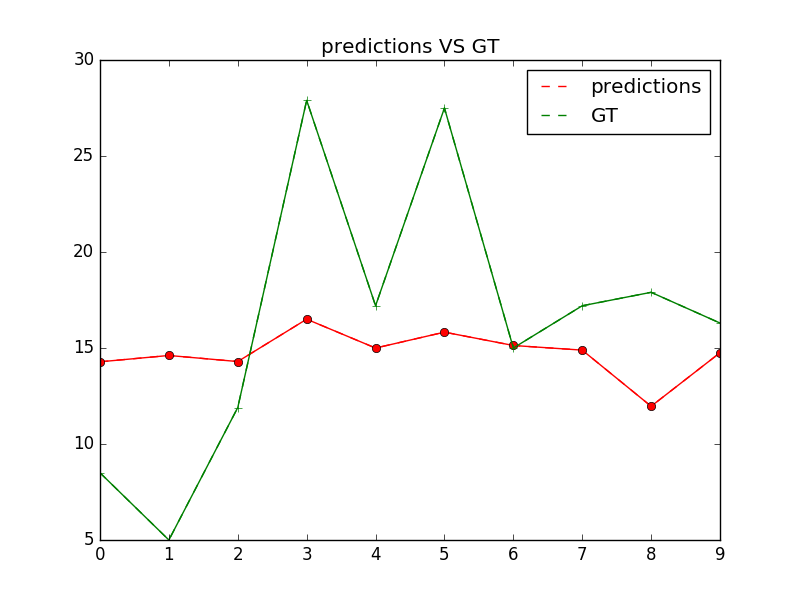
由于词向量矩阵本身比较稀疏,训练的过程如果要达到一定的精度耗时会比较长。为了能简单看到效果,教程只设置了经过很少的训练就结束并得到如下的预测。我们的模型预测 `among a group of` 的下一个词是`the`。这比较符合文法规律。如果我们训练时间更长,比如几个小时,那么我们会得到的下一个预测是 `workers`。
由于词向量矩阵本身比较稀疏,训练的过程如果要达到一定的精度耗时会比较长。为了能简单看到效果,教程只设置了经过很少的训练就结束并得到如下的预测。我们的模型预测 `among a group of` 的下一个词是`the`。这比较符合文法规律。如果我们训练时间更长,比如几个小时,那么我们会得到的下一个预测是 `workers`。预测输出的格式如下所示:
Yoshua Bengio等科学家就于2003年在著名论文 Neural Probabilistic Language Models \[[1](#参考文献)\] 中介绍如何学习一个神经元网络表示的词向量模型。文中的神经概率语言模型(Neural Network Language Model,NNLM)通过一个线性映射和一个非线性隐层连接,同时学习了语言模型和词向量,即通过学习大量语料得到词语的向量表达,通过这些向量得到整个句子的概率。用这种方法学习语言模型可以克服维度灾难(curse of dimensionality),即训练和测试数据不同导致的模型不准。注意:由于“神经概率语言模型”说法较为泛泛,我们在这里不用其NNLM的本名,考虑到其具体做法,本文中称该模型为N-gram neural model。
Yoshua Bengio等科学家就于2003年在著名论文 Neural Probabilistic Language Models \[[1](#参考文献)\] 中介绍如何学习一个神经元网络表示的词向量模型。文中的神经概率语言模型(Neural Network Language Model,NNLM)通过一个线性映射和一个非线性隐层连接,同时学习了语言模型和词向量,即通过学习大量语料得到词语的向量表达,通过这些向量得到整个句子的概率。因所有的词语都用一个低维向量来表示,用这种方法学习语言模型可以克服维度灾难(curse of dimensionality)。注意:由于“神经概率语言模型”说法较为泛泛,我们在这里不用其NNLM的本名,考虑到其具体做法,本文中称该模型为N-gram neural model。
由于词向量矩阵本身比较稀疏,训练的过程如果要达到一定的精度耗时会比较长。为了能简单看到效果,教程只设置了经过很少的训练就结束并得到如下的预测。我们的模型预测 `among a group of` 的下一个词是`the`。这比较符合文法规律。如果我们训练时间更长,比如几个小时,那么我们会得到的下一个预测是 `workers`。
由于词向量矩阵本身比较稀疏,训练的过程如果要达到一定的精度耗时会比较长。为了能简单看到效果,教程只设置了经过很少的训练就结束并得到如下的预测。我们的模型预测 `among a group of` 的下一个词是`the`。这比较符合文法规律。如果我们训练时间更长,比如几个小时,那么我们会得到的下一个预测是 `workers`。预测输出的格式如下所示:
1.[Peter Brusilovsky](https://en.wikipedia.org/wiki/Peter_Brusilovsky) (2007). *The Adaptive Web*. p. 325.
2.Robin Burke , [Hybrid Web Recommender Systems](http://www.dcs.warwick.ac.uk/~acristea/courses/CS411/2010/Book%20-%20The%20Adaptive%20Web/HybridWebRecommenderSystems.pdf), pp. 377-408, The Adaptive Web, Peter Brusilovsky, Alfred Kobsa, Wolfgang Nejdl (Ed.), Lecture Notes in Computer Science, Springer-Verlag, Berlin, Germany, Lecture Notes in Computer Science, Vol. 4321, May 2007, 978-3-540-72078-2.
3.P. Resnick, N. Iacovou, etc. “[GroupLens: An Open Architecture for Collaborative Filtering of Netnews](http://ccs.mit.edu/papers/CCSWP165.html)”, Proceedings of ACM Conference on Computer Supported Cooperative Work, CSCW 1994. pp.175-186.
4.Sarwar, Badrul, et al. "[Item-based collaborative filtering recommendation algorithms.](http://files.grouplens.org/papers/www10_sarwar.pdf)" *Proceedings of the 10th international conference on World Wide Web*. ACM, 2001.
5.Kautz, Henry, Bart Selman, and Mehul Shah. "[Referral Web: combining social networks and collaborative filtering.](http://www.cs.cornell.edu/selman/papers/pdf/97.cacm.refweb.pdf)" Communications of the ACM 40.3 (1997): 63-65. APA
1.P. Resnick, N. Iacovou, etc. “[GroupLens: An Open Architecture for Collaborative Filtering of Netnews](http://ccs.mit.edu/papers/CCSWP165.html)”, Proceedings of ACM Conference on Computer Supported Cooperative Work, CSCW 1994. pp.175-186.
2.Sarwar, Badrul, et al. "[Item-based collaborative filtering recommendation algorithms.](http://files.grouplens.org/papers/www10_sarwar.pdf)" *Proceedings of the 10th international conference on World Wide Web*. ACM, 2001.
3.Kautz, Henry, Bart Selman, and Mehul Shah. "[Referral Web: combining social networks and collaborative filtering.](http://www.cs.cornell.edu/selman/papers/pdf/97.cacm.refweb.pdf)" Communications of the ACM 40.3 (1997): 63-65. APA
4.[Peter Brusilovsky](https://en.wikipedia.org/wiki/Peter_Brusilovsky) (2007). *The Adaptive Web*. p. 325.
5.Robin Burke , [Hybrid Web Recommender Systems](http://www.dcs.warwick.ac.uk/~acristea/courses/CS411/2010/Book%20-%20The%20Adaptive%20Web/HybridWebRecommenderSystems.pdf), pp. 377-408, The Adaptive Web, Peter Brusilovsky, Alfred Kobsa, Wolfgang Nejdl (Ed.), Lecture Notes in Computer Science, Springer-Verlag, Berlin, Germany, Lecture Notes in Computer Science, Vol. 4321, May 2007, 978-3-540-72078-2.
6. Yuan, Jianbo, et al. ["Solving Cold-Start Problem in Large-scale Recommendation Engines: A Deep Learning Approach."](https://arxiv.org/pdf/1611.05480v1.pdf)*arXiv preprint arXiv:1611.05480* (2016).
7. Covington P, Adams J, Sargin E. [Deep neural networks for youtube recommendations](https://static.googleusercontent.com/media/research.google.com/zh-CN//pubs/archive/45530.pdf)[C]//Proceedings of the 10th ACM Conference on Recommender Systems. ACM, 2016: 191-198.
1. [Peter Brusilovsky](https://en.wikipedia.org/wiki/Peter_Brusilovsky) (2007). *The Adaptive Web*. p. 325.
2. Robin Burke , [Hybrid Web Recommender Systems](http://www.dcs.warwick.ac.uk/~acristea/courses/CS411/2010/Book%20-%20The%20Adaptive%20Web/HybridWebRecommenderSystems.pdf), pp. 377-408, The Adaptive Web, Peter Brusilovsky, Alfred Kobsa, Wolfgang Nejdl (Ed.), Lecture Notes in Computer Science, Springer-Verlag, Berlin, Germany, Lecture Notes in Computer Science, Vol. 4321, May 2007, 978-3-540-72078-2.
3. P. Resnick, N. Iacovou, etc. “[GroupLens: An Open Architecture for Collaborative Filtering of Netnews](http://ccs.mit.edu/papers/CCSWP165.html)”, Proceedings of ACM Conference on Computer Supported Cooperative Work, CSCW 1994. pp.175-186.
4. Sarwar, Badrul, et al. "[Item-based collaborative filtering recommendation algorithms.](http://files.grouplens.org/papers/www10_sarwar.pdf)" *Proceedings of the 10th international conference on World Wide Web*. ACM, 2001.
5. Kautz, Henry, Bart Selman, and Mehul Shah. "[Referral Web: combining social networks and collaborative filtering.](http://www.cs.cornell.edu/selman/papers/pdf/97.cacm.refweb.pdf)" Communications of the ACM 40.3 (1997): 63-65. APA
1. P. Resnick, N. Iacovou, etc. “[GroupLens: An Open Architecture for Collaborative Filtering of Netnews](http://ccs.mit.edu/papers/CCSWP165.html)”, Proceedings of ACM Conference on Computer Supported Cooperative Work, CSCW 1994. pp.175-186.
2. Sarwar, Badrul, et al. "[Item-based collaborative filtering recommendation algorithms.](http://files.grouplens.org/papers/www10_sarwar.pdf)" *Proceedings of the 10th international conference on World Wide Web*. ACM, 2001.
3. Kautz, Henry, Bart Selman, and Mehul Shah. "[Referral Web: combining social networks and collaborative filtering.](http://www.cs.cornell.edu/selman/papers/pdf/97.cacm.refweb.pdf)" Communications of the ACM 40.3 (1997): 63-65. APA
4. [Peter Brusilovsky](https://en.wikipedia.org/wiki/Peter_Brusilovsky) (2007). *The Adaptive Web*. p. 325.
5. Robin Burke , [Hybrid Web Recommender Systems](http://www.dcs.warwick.ac.uk/~acristea/courses/CS411/2010/Book%20-%20The%20Adaptive%20Web/HybridWebRecommenderSystems.pdf), pp. 377-408, The Adaptive Web, Peter Brusilovsky, Alfred Kobsa, Wolfgang Nejdl (Ed.), Lecture Notes in Computer Science, Springer-Verlag, Berlin, Germany, Lecture Notes in Computer Science, Vol. 4321, May 2007, 978-3-540-72078-2.
6. Yuan, Jianbo, et al. ["Solving Cold-Start Problem in Large-scale Recommendation Engines: A Deep Learning Approach."](https://arxiv.org/pdf/1611.05480v1.pdf) *arXiv preprint arXiv:1611.05480* (2016).
7. Covington P, Adams J, Sargin E. [Deep neural networks for youtube recommendations](https://static.googleusercontent.com/media/research.google.com/zh-CN//pubs/archive/45530.pdf)[C]//Proceedings of the 10th ACM Conference on Recommender Systems. ACM, 2016: 191-198.
对卷积神经网络来说,首先使用卷积处理输入的词向量序列,产生一个特征图(feature map),对特征图采用时间维度上的最大池化(max pooling over time)操作得到此卷积核对应的整句话的特征,最后,将所有卷积核得到的特征拼接起来即为文本的定长向量表示,对于文本分类问题,将其连接至softmax即构建出完整的模型。在实际应用中,我们会使用多个卷积核来处理句子,窗口大小相同的卷积核堆叠起来形成一个矩阵,这样可以更高效的完成运算。另外,我们也可使用窗口大小不同的卷积核来处理句子,[推荐系统](https://github.com/PaddlePaddle/book/tree/develop/05.recommender_system)一节的图3作为示意画了四个卷积核,不同颜色表示不同大小的卷积核操作。
对卷积神经网络来说,首先使用卷积处理输入的词向量序列,产生一个特征图(feature map),对特征图采用时间维度上的最大池化(max pooling over time)操作得到此卷积核对应的整句话的特征,最后,将所有卷积核得到的特征拼接起来即为文本的定长向量表示,对于文本分类问题,将其连接至softmax即构建出完整的模型。在实际应用中,我们会使用多个卷积核来处理句子,窗口大小相同的卷积核堆叠起来形成一个矩阵,这样可以更高效的完成运算。另外,我们也可使用窗口大小不同的卷积核来处理句子,[推荐系统](https://github.com/PaddlePaddle/book/tree/develop/05.recommender_system)一节的图3作为示意画了四个卷积核,既文本图1,不同颜色表示不同大小的卷积核操作。
在处理自然语言时,一般会先将词(one-hot表示)映射为其词向量(word embedding)表示,然后再作为循环神经网络每一时刻的输入$x_t$。此外,可以根据实际需要的不同在循环神经网络的隐层上连接其它层。如,可以把一个循环神经网络的隐层输出连接至下一个循环神经网络的输入构建深层(deep or stacked)循环神经网络,或者提取最后一个时刻的隐层状态作为句子表示进而使用分类模型等等。
在处理自然语言时,一般会先将词(one-hot表示)映射为其词向量表示,然后再作为循环神经网络每一时刻的输入$x_t$。此外,可以根据实际需要的不同在循环神经网络的隐层上连接其它层。如,可以把一个循环神经网络的隐层输出连接至下一个循环神经网络的输入构建深层(deep or stacked)循环神经网络,或者提取最后一个时刻的隐层状态作为句子表示进而使用分类模型等等。
LSTM通过给简单的循环神经网络增加记忆及控制门的方式,增强了其处理远距离依赖问题的能力。类似原理的改进还有Gated Recurrent Unit (GRU)\[[8](#参考文献)\],其设计更为简洁一些。**这些改进虽然各有不同,但是它们的宏观描述却与简单的循环神经网络一样(如图2所示),即隐状态依据当前输入及前一时刻的隐状态来改变,不断地循环这一过程直至输入处理完毕:**
对卷积神经网络来说,首先使用卷积处理输入的词向量序列,产生一个特征图(feature map),对特征图采用时间维度上的最大池化(max pooling over time)操作得到此卷积核对应的整句话的特征,最后,将所有卷积核得到的特征拼接起来即为文本的定长向量表示,对于文本分类问题,将其连接至softmax即构建出完整的模型。在实际应用中,我们会使用多个卷积核来处理句子,窗口大小相同的卷积核堆叠起来形成一个矩阵,这样可以更高效的完成运算。另外,我们也可使用窗口大小不同的卷积核来处理句子,[推荐系统](https://github.com/PaddlePaddle/book/tree/develop/05.recommender_system)一节的图3作为示意画了四个卷积核,不同颜色表示不同大小的卷积核操作。
对卷积神经网络来说,首先使用卷积处理输入的词向量序列,产生一个特征图(feature map),对特征图采用时间维度上的最大池化(max pooling over time)操作得到此卷积核对应的整句话的特征,最后,将所有卷积核得到的特征拼接起来即为文本的定长向量表示,对于文本分类问题,将其连接至softmax即构建出完整的模型。在实际应用中,我们会使用多个卷积核来处理句子,窗口大小相同的卷积核堆叠起来形成一个矩阵,这样可以更高效的完成运算。另外,我们也可使用窗口大小不同的卷积核来处理句子,[推荐系统](https://github.com/PaddlePaddle/book/tree/develop/05.recommender_system)一节的图3作为示意画了四个卷积核,既文本图1,不同颜色表示不同大小的卷积核操作。
在处理自然语言时,一般会先将词(one-hot表示)映射为其词向量(word embedding)表示,然后再作为循环神经网络每一时刻的输入$x_t$。此外,可以根据实际需要的不同在循环神经网络的隐层上连接其它层。如,可以把一个循环神经网络的隐层输出连接至下一个循环神经网络的输入构建深层(deep or stacked)循环神经网络,或者提取最后一个时刻的隐层状态作为句子表示进而使用分类模型等等。
在处理自然语言时,一般会先将词(one-hot表示)映射为其词向量表示,然后再作为循环神经网络每一时刻的输入$x_t$。此外,可以根据实际需要的不同在循环神经网络的隐层上连接其它层。如,可以把一个循环神经网络的隐层输出连接至下一个循环神经网络的输入构建深层(deep or stacked)循环神经网络,或者提取最后一个时刻的隐层状态作为句子表示进而使用分类模型等等。
LSTM通过给简单的循环神经网络增加记忆及控制门的方式,增强了其处理远距离依赖问题的能力。类似原理的改进还有Gated Recurrent Unit (GRU)\[[8](#参考文献)\],其设计更为简洁一些。**这些改进虽然各有不同,但是它们的宏观描述却与简单的循环神经网络一样(如图2所示),即隐状态依据当前输入及前一时刻的隐状态来改变,不断地循环这一过程直至输入处理完毕:**
Your contribution is welcome! Please feel free to file Pull Requests to add your chapter as a directory under `/pending`. Once it is going stable, the community would like to move it to `/`.
To write, run, and debug your chapters, you will need Python 2.x, Go >1.5. You can build the Docker image using [this script](https://github.com/PaddlePaddle/book/blob/develop/.tools/convert-markdown-into-ipynb-and-test.sh).
This tutorial is contributed by <axmlns:cc="http://creativecommons.org/ns#"href="http://book.paddlepaddle.org"property="cc:attributionName"rel="cc:attributionURL">PaddlePaddle</a>, and licensed under a <arel="license"href="http://creativecommons.org/licenses/by-sa/4.0/">Creative Commons Attribution-ShareAlike 4.0 International License</a>.
This tutorial is contributed by <axmlns:cc="http://creativecommons.org/ns#"href="http://www.paddlepaddle.org/"property="cc:attributionName"rel="cc:attributionURL">PaddlePaddle</a>, and licensed under a <arel="license"href="http://creativecommons.org/licenses/by-sa/4.0/">Creative Commons Attribution-ShareAlike 4.0 International License</a>.
{kind=link}
{kind=link}
{kind=link}