revise according to reviews
Showing
fit_a_line/.gitignore
0 → 100644
fit_a_line/data/prepare_data.py
0 → 100644
fit_a_line/dataprovider.py
0 → 100644
fit_a_line/image/predictions.png
0 → 100644
{kind=link}
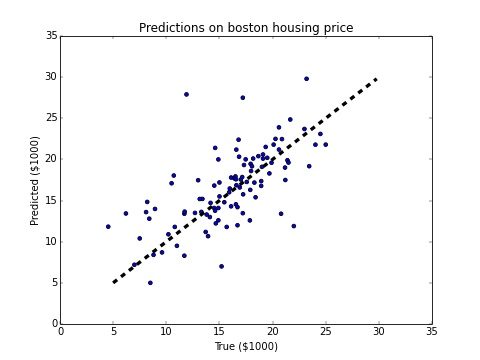
25.8 KB
fit_a_line/image/ranges.png
0 → 100644
{kind=link}
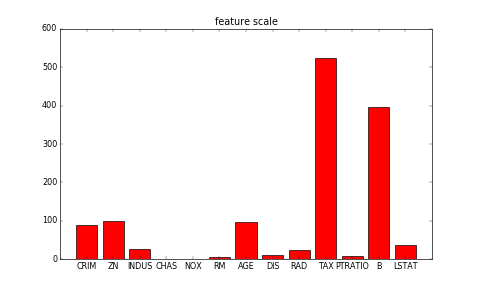
8.6 KB
fit_a_line/predict.py
0 → 100644
fit_a_line/train.sh
0 → 100755
fit_a_line/trainer_config.py
0 → 100644