Rewrite machine_translation with attention model. (#740)
* Rewrite machine_translation with attention model. * Replace formula in machine_translation with picture
Showing
{kind=link}
7.7 KB
{kind=link}
7.1 KB
{kind=link}
17.3 KB
{kind=link}
11.1 KB
{kind=link}
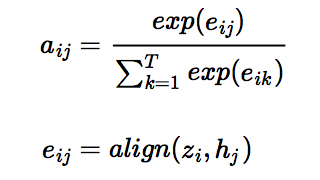
16.5 KB
* Rewrite machine_translation with attention model. * Replace formula in machine_translation with picture
7.7 KB
7.1 KB
17.3 KB
11.1 KB
16.5 KB