diff --git a/08.machine_translation/README.cn.md b/08.machine_translation/README.cn.md
index 5b91c74caa2d1abec88242a8f92a10218acba14e..a8c9071e6885d9ccf5f0d047615044c3eae5bde7 100644
--- a/08.machine_translation/README.cn.md
+++ b/08.machine_translation/README.cn.md
@@ -2,6 +2,11 @@
本教程源代码目录在[book/machine_translation](https://github.com/PaddlePaddle/book/tree/develop/08.machine_translation),初次使用请您参考[Book文档使用说明](https://github.com/PaddlePaddle/book/blob/develop/README.cn.md#运行这本书)。
+### 说明
+1. 硬件要求 本文可支持在CPU、GPU下运行
+2. 对docker file cuda/cudnn的支持 如果您使用了本文配套的docker镜像,请注意:该镜像对GPU的支持仅限于CUDA 8,cuDNN 5
+3. 文档中代码和train.py不一致的问题 请注意:为使本文更加易读易用,我们拆分、调整了train.py的代码并放入本文。本文中代码与train.py的运行结果一致,如希望直接看到训练脚本输出效果,可运行[train.py](https://github.com/PaddlePaddle/book/blob/develop/08.machine_translation/train.py)。
+
## 背景介绍
机器翻译(machine translation, MT)是用计算机来实现不同语言之间翻译的技术。被翻译的语言通常称为源语言(source language),翻译成的结果语言称为目标语言(target language)。机器翻译即实现从源语言到目标语言转换的过程,是自然语言处理的重要研究领域之一。
@@ -37,7 +42,21 @@
## 模型概览
-本节依次介绍双向循环神经网络(Bi-directional Recurrent Neural Network),NMT模型中典型的编码器-解码器(Encoder-Decoder)框架以及柱搜索(beam search)算法。
+本节依次介绍GRU(Gated Recurrent Unit,门控循环单元),双向循环神经网络(Bi-directional Recurrent Neural Network),NMT模型中典型的编码器-解码器(Encoder-Decoder)框架和注意力(Attention)机制,以及柱搜索(beam search)算法。
+
+### GRU
+
+我们已经在[情感分析](https://github.com/PaddlePaddle/book/blob/develop/06.understand_sentiment/README.cn.md)一章中介绍了循环神经网络(RNN)及长短时间记忆网络(LSTM)。相比于简单的RNN,LSTM增加了记忆单元(memory cell)、输入门(input gate)、遗忘门(forget gate)及输出门(output gate),这些门及记忆单元组合起来大大提升了RNN处理远距离依赖问题的能力。
+
+GRU\[[2](#参考文献)\]是Cho等人在LSTM上提出的简化版本,也是RNN的一种扩展,如下图所示。GRU单元只有两个门:
+- 重置门(reset gate):如果重置门关闭,会忽略掉历史信息,即历史不相干的信息不会影响未来的输出。
+- 更新门(update gate):将LSTM的输入门和遗忘门合并,用于控制历史信息对当前时刻隐层输出的影响。如果更新门接近1,会把历史信息传递下去。
+
+
+图2. GRU(门控循环单元)
+
+
+一般来说,具有短距离依赖属性的序列,其重置门比较活跃;相反,具有长距离依赖属性的序列,其更新门比较活跃。另外,Chung等人\[[3](#参考文献)\]通过多组实验表明,GRU虽然参数更少,但是在多个任务上都和LSTM有相近的表现。
### 双向循环神经网络
@@ -81,19 +100,56 @@
机器翻译任务的训练过程中,解码阶段的目标是最大化下一个正确的目标语言词的概率。思路是:
1. 每一个时刻,根据源语言句子的编码信息(又叫上下文向量,context vector)$c$、真实目标语言序列的第$i$个词$u_i$和$i$时刻RNN的隐层状态$z_i$,计算出下一个隐层状态$z_{i+1}$。计算公式如下:
-$$z_{i+1}=\phi_{\theta '} \left ( c,u_i,z_i \right )$$
+
+
+

+
`,表示解码开始;$z_i$是$i$时刻解码RNN的隐层状态,$z_0$是一个全零的向量。
-2. 将$z_{i+1}$通过`softmax`归一化,得到目标语言序列的第$i+1$个单词的概率分布$p_{i+1}$。概率分布公式如下:
-$$p\left ( u_{i+1}|u_{<i+1},\mathbf{x} \right )=softmax(W_sz_{i+1}+b_z)$$
+1. 将$z_{i+1}$通过`softmax`归一化,得到目标语言序列的第$i+1$个单词的概率分布$p_{i+1}$。概率分布公式如下:
+
+
+

+
+

+
+
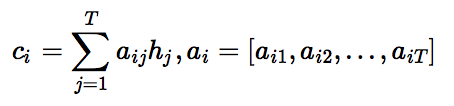
+
+

+
+
+图6. 基于注意力机制的解码器
+
+
### 柱搜索算法
@@ -114,7 +170,7 @@ $$p\left ( u_{i+1}|u_{<i+1},\mathbf{x} \right )=softmax(W_sz_{i+1}+b_z)$$
## 数据介绍
-本教程使用[WMT-14](http://www-lium.univ-lemans.fr/~schwenk/cslm_joint_paper/)数据集中的[bitexts(after selection)](http://www-lium.univ-lemans.fr/~schwenk/cslm_joint_paper/data/bitexts.tgz)作为训练集,[dev+test data](http://www-lium.univ-lemans.fr/~schwenk/cslm_joint_paper/data/dev+test.tgz)作为测试集和生成集。
+本教程使用[WMT-16](http://www.statmt.org/wmt16/)新增的[multimodal task](http://www.statmt.org/wmt16/multimodal-task.html)中的[translation task](http://www.statmt.org/wmt16/multimodal-task.html#task1)的数据集。该数据集为英德翻译数据,包含29001条训练数据,1000条测试数据。
### 数据预处理
@@ -130,347 +186,408 @@ $$p\left ( u_{i+1}|u_{<i+1},\mathbf{x} \right )=softmax(W_sz_{i+1}+b_z)$$
### 示例数据
-因为完整的数据集数据量较大,为了验证训练流程,PaddlePaddle接口paddle.dataset.wmt14中默认提供了一个经过预处理的[较小规模的数据集](http://paddlepaddle.bj.bcebos.com/demo/wmt_shrinked_data/wmt14.tgz)。
-
-该数据集有193319条训练数据,6003条测试数据,词典长度为30000。因为数据规模限制,使用该数据集训练出来的模型效果无法保证。
+为了验证训练流程,PaddlePaddle接口`paddle.dataset.wmt16`中提供了对该数据集预处理后的版本(http://paddlemodels.bj.bcebos.com/wmt/wmt16.tar.gz),调用该接口即可直接使用,因为数据规模限制,这里只作为示例使用,在相应的测试集上具有一定效果但在更多测试数据上的效果无法保证。
## 模型配置说明
-下面我们开始根据输入数据的形式配置模型。首先引入所需的库函数以及定义全局变量。
+下面我们开始根据输入数据的形式配置模型。首先引入所需的库函数以及定义全局变量:
```python
from __future__ import print_function
-import contextlib
+import os
+import six
-import numpy as np
import paddle
import paddle.fluid as fluid
-import paddle.fluid.framework as framework
-import paddle.fluid.layers as pd
-from paddle.fluid.executor import Executor
-from functools import partial
-import os
-try:
- from paddle.fluid.contrib.trainer import *
- from paddle.fluid.contrib.inferencer import *
-except ImportError:
- print(
- "In the fluid 1.0, the trainer and inferencer are moving to paddle.fluid.contrib",
- file=sys.stderr)
- from paddle.fluid.trainer import *
- from paddle.fluid.inferencer import *
-
-dict_size = 30000 # 字典维度
-source_dict_dim = target_dict_dim = dict_size # 源/目标语言字典维度
-hidden_dim = 32 # 编码器中的隐层大小
-word_dim = 16 # 词向量维度
-batch_size = 2 # batch 中的样本数
-max_length = 8 # 生成句子的最大长度
-beam_size = 2 # 柱宽度
-
-decoder_size = hidden_dim # 解码器中的隐层大小
+
+dict_size = 30000 # 词典大小
+source_dict_size = target_dict_size = dict_size # 源/目标语言字典大小
+word_dim = 512 # 词向量维度
+hidden_dim = 512 # 编码器中的隐层大小
+decoder_size = hidden_dim # 解码器中的隐层大小
+max_length = 256 # 解码生成句子的最大长度
+beam_size = 4 # beam search的柱宽度
+batch_size = 64 # batch 中的样本数
+
+is_sparse = True
+model_save_dir = "machine_translation.inference.model"
```
然后如下实现编码器框架:
- ```python
- def encoder(is_sparse):
+```python
+def encoder():
# 定义源语言id序列的输入数据
- src_word_id = pd.data(
+ src_word_id = fluid.layers.data(
name="src_word_id", shape=[1], dtype='int64', lod_level=1)
# 将上述编码映射到低维语言空间的词向量
- src_embedding = pd.embedding(
+ src_embedding = fluid.layers.embedding(
input=src_word_id,
- size=[dict_size, word_dim],
+ size=[source_dict_size, word_dim],
dtype='float32',
- is_sparse=is_sparse,
- param_attr=fluid.ParamAttr(name='vemb'))
- # LSTM层:fc + dynamic_lstm
- fc1 = pd.fc(input=src_embedding, size=hidden_dim * 4, act='tanh')
- lstm_hidden0, lstm_0 = pd.dynamic_lstm(input=fc1, size=hidden_dim * 4)
- # 取源语言序列编码后的最后一个状态
- encoder_out = pd.sequence_last_step(input=lstm_hidden0)
- return encoder_out
- ```
-
-再实现训练模式下的解码器:
+ is_sparse=is_sparse)
+ # 用双向GRU编码源语言序列,拼接两个GRU的编码结果得到h
+ fc_forward = fluid.layers.fc(
+ input=src_embedding, size=hidden_dim * 3, bias_attr=False)
+ src_forward = fluid.layers.dynamic_gru(input=fc_forward, size=hidden_dim)
+ fc_backward = fluid.layers.fc(
+ input=src_embedding, size=hidden_dim * 3, bias_attr=False)
+ src_backward = fluid.layers.dynamic_gru(
+ input=fc_backward, size=hidden_dim, is_reverse=True)
+ encoded_vector = fluid.layers.concat(
+ input=[src_forward, src_backward], axis=1)
+ return encoded_vector
+```
+
+再实现基于注意力机制的解码器:
+ - 首先定义解码器中单步的计算,即$z_{i+1}=\phi _{\theta '}\left ( c_i,u_i,z_i \right )$,如下:
+
+ ```python
+ # 定义RNN中的单步计算
+ def cell(x, hidden, encoder_out, encoder_out_proj):
+ # 定义attention用以计算context,即 c_i,这里使用Bahdanau attention机制
+ def simple_attention(encoder_vec, encoder_proj, decoder_state):
+ decoder_state_proj = fluid.layers.fc(
+ input=decoder_state, size=decoder_size, bias_attr=False)
+ # sequence_expand将单步内容扩展为与encoder输出相同的序列
+ decoder_state_expand = fluid.layers.sequence_expand(
+ x=decoder_state_proj, y=encoder_proj)
+ mixed_state = fluid.layers.elementwise_add(encoder_proj,
+ decoder_state_expand)
+ attention_weights = fluid.layers.fc(
+ input=mixed_state, size=1, bias_attr=False)
+ attention_weights = fluid.layers.sequence_softmax(
+ input=attention_weights)
+ weigths_reshape = fluid.layers.reshape(x=attention_weights, shape=[-1])
+ scaled = fluid.layers.elementwise_mul(
+ x=encoder_vec, y=weigths_reshape, axis=0)
+ context = fluid.layers.sequence_pool(input=scaled, pool_type='sum')
+ return context
+
+ context = simple_attention(encoder_out, encoder_out_proj, hidden)
+ out = fluid.layers.fc(
+ input=[x, context], size=decoder_size * 3, bias_attr=False)
+ out = fluid.layers.gru_unit(
+ input=out, hidden=hidden, size=decoder_size * 3)[0]
+ return out, out
+ ```
+
+ - 基于定义的单步计算,使用`DynamicRNN`实现多步循环的训练模式下解码器,如下:
+
+ ```python
+ def train_decoder(encoder_out):
+ # 获取编码器输出的最后一步并进行非线性映射以构造解码器RNN的初始状态
+ encoder_last = fluid.layers.sequence_last_step(input=encoder_out)
+ encoder_last_proj = fluid.layers.fc(
+ input=encoder_last, size=decoder_size, act='tanh')
+ # 编码器输出在attention中计算结果的cache
+ encoder_out_proj = fluid.layers.fc(
+ input=encoder_out, size=decoder_size, bias_attr=False)
+
+ # 定义目标语言id序列的输入数据,并映射到低维语言空间的词向量
+ trg_language_word = fluid.layers.data(
+ name="target_language_word", shape=[1], dtype='int64', lod_level=1)
+ trg_embedding = fluid.layers.embedding(
+ input=trg_language_word,
+ size=[target_dict_size, word_dim],
+ dtype='float32',
+ is_sparse=is_sparse)
+
+ rnn = fluid.layers.DynamicRNN()
+ with rnn.block():
+ # 获取当前步目标语言输入的词向量
+ x = rnn.step_input(trg_embedding)
+ # 获取隐层状态
+ pre_state = rnn.memory(init=encoder_last_proj, need_reorder=True)
+ # 在DynamicRNN中需使用static_input获取encoder相关的内容
+ # 对decoder来说这些内容在每个时间步都是固定的
+ encoder_out = rnn.static_input(encoder_out)
+ encoder_out_proj = rnn.static_input(encoder_out_proj)
+ # 执行单步的计算单元
+ out, current_state = cell(x, pre_state, encoder_out, encoder_out_proj)
+ # 计算归一化的单词预测概率
+ prob = fluid.layers.fc(input=out, size=target_dict_size, act='softmax')
+ # 更新隐层状态
+ rnn.update_memory(pre_state, current_state)
+ # 输出预测概率
+ rnn.output(prob)
+
+ return rnn()
+ ```
+
+接着就可以使用编码器和解码器定义整个训练网络;为了进行训练还需要定义优化器,如下:
```python
- def train_decoder(context, is_sparse):
- # 定义目标语言id序列的输入数据,并映射到低维语言空间的词向量
- trg_language_word = pd.data(
- name="target_language_word", shape=[1], dtype='int64', lod_level=1)
- trg_embedding = pd.embedding(
- input=trg_language_word,
- size=[dict_size, word_dim],
- dtype='float32',
- is_sparse=is_sparse,
- param_attr=fluid.ParamAttr(name='vemb'))
-
- rnn = pd.DynamicRNN()
- with rnn.block(): # 使用 DynamicRNN 定义每一步的计算
- # 获取当前步目标语言输入的词向量
- current_word = rnn.step_input(trg_embedding)
- # 获取隐层状态
- pre_state = rnn.memory(init=context)
- # 解码器计算单元:单层前馈网络
- current_state = pd.fc(input=[current_word, pre_state],
- size=decoder_size,
- act='tanh')
- # 计算归一化的单词预测概率
- current_score = pd.fc(input=current_state,
- size=target_dict_dim,
- act='softmax')
- # 更新RNN的隐层状态
- rnn.update_memory(pre_state, current_state)
- # 输出预测概率
- rnn.output(current_score)
-
- return rnn()
+def train_model():
+ encoder_out = encoder()
+ rnn_out = train_decoder(encoder_out)
+ label = fluid.layers.data(
+ name="target_language_next_word", shape=[1], dtype='int64', lod_level=1)
+ # 定义损失函数
+ cost = fluid.layers.cross_entropy(input=rnn_out, label=label)
+ avg_cost = fluid.layers.mean(cost)
+ return avg_cost
+
+def optimizer_func():
+ # 设置梯度裁剪
+ fluid.clip.set_gradient_clip(
+ clip=fluid.clip.GradientClipByGlobalNorm(clip_norm=5.0))
+ # 定义先增后降的学习率策略
+ lr_decay = fluid.layers.learning_rate_scheduler.noam_decay(hidden_dim, 1000)
+ return fluid.optimizer.Adam(
+ learning_rate=lr_decay,
+ regularization=fluid.regularizer.L2DecayRegularizer(
+ regularization_coeff=1e-4))
```
-实现推测模式下的解码器:
+以上是训练所需的模型构件,预测(生成)模式下基于beam search的解码器需要借助`while_op`实现,如下:
```python
-def decode(context, is_sparse):
- init_state = context
- # 定义解码过程循环计数变量
- array_len = pd.fill_constant(shape=[1], dtype='int64', value=max_length)
- counter = pd.zeros(shape=[1], dtype='int64', force_cpu=True)
+def infer_decoder(encoder_out):
+ # 获取编码器输出的最后一步并进行非线性映射以构造解码器RNN的初始状态
+ encoder_last = fluid.layers.sequence_last_step(input=encoder_out)
+ encoder_last_proj = fluid.layers.fc(
+ input=encoder_last, size=decoder_size, act='tanh')
+ # 编码器输出在attention中计算结果的cache
+ encoder_out_proj = fluid.layers.fc(
+ input=encoder_out, size=decoder_size, bias_attr=False)
+
+ # 最大解码步数
+ max_len = fluid.layers.fill_constant(
+ shape=[1], dtype='int64', value=max_length)
+ # 解码步数计数变量
+ counter = fluid.layers.zeros(shape=[1], dtype='int64', force_cpu=True)
# 定义 tensor array 用以保存各个时间步的内容,并写入初始id,score和state
- state_array = pd.create_array('float32')
- pd.array_write(init_state, array=state_array, i=counter)
-
- ids_array = pd.create_array('int64')
- scores_array = pd.create_array('float32')
-
- init_ids = pd.data(name="init_ids", shape=[1], dtype="int64", lod_level=2)
- init_scores = pd.data(
+ init_ids = fluid.layers.data(
+ name="init_ids", shape=[1], dtype="int64", lod_level=2)
+ init_scores = fluid.layers.data(
name="init_scores", shape=[1], dtype="float32", lod_level=2)
-
- pd.array_write(init_ids, array=ids_array, i=counter)
- pd.array_write(init_scores, array=scores_array, i=counter)
+ ids_array = fluid.layers.array_write(init_ids, i=counter)
+ scores_array = fluid.layers.array_write(init_scores, i=counter)
+ state_array = fluid.layers.array_write(encoder_last_proj, i=counter)
# 定义循环终止条件变量
- cond = pd.less_than(x=counter, y=array_len)
- # 定义 while_op
- while_op = pd.While(cond=cond)
- with while_op.block(): # 定义每一步的计算
+ cond = fluid.layers.less_than(x=counter, y=max_len)
+ while_op = fluid.layers.While(cond=cond)
+ with while_op.block():
# 获取解码器在当前步的输入,包括上一步选择的id,对应的score和上一步的state
- pre_ids = pd.array_read(array=ids_array, i=counter)
- pre_state = pd.array_read(array=state_array, i=counter)
- pre_score = pd.array_read(array=scores_array, i=counter)
-
- # 更新输入的state为上一步选择id对应的state
- pre_state_expanded = pd.sequence_expand(pre_state, pre_score)
- # 同训练模式下解码器中的计算逻辑,包括获取输入向量,解码器计算单元计算和
- # 归一化单词预测概率的计算
- pre_ids_emb = pd.embedding(
+ pre_ids = fluid.layers.array_read(array=ids_array, i=counter)
+ pre_score = fluid.layers.array_read(array=scores_array, i=counter)
+ pre_state = fluid.layers.array_read(array=state_array, i=counter)
+
+ # 同train_decoder中的内容,进行RNN的单步计算
+ pre_ids_emb = fluid.layers.embedding(
input=pre_ids,
- size=[dict_size, word_dim],
+ size=[target_dict_size, word_dim],
dtype='float32',
is_sparse=is_sparse)
- current_state = pd.fc(input=[pre_state_expanded, pre_ids_emb],
- size=decoder_size,
- act='tanh')
- current_state_with_lod = pd.lod_reset(x=current_state, y=pre_score)
- current_score = pd.fc(input=current_state_with_lod,
- size=target_dict_dim,
- act='softmax')
- topk_scores, topk_indices = pd.topk(current_score, k=beam_size)
+ out, current_state = cell(pre_ids_emb, pre_state, encoder_out,
+ encoder_out_proj)
+ prob = fluid.layers.fc(
+ input=current_state, size=target_dict_size, act='softmax')
# 计算累计得分,进行beam search
- accu_scores = pd.elementwise_add(
- x=pd.log(topk_scores), y=pd.reshape(pre_score, shape=[-1]), axis=0)
- selected_ids, selected_scores = pd.beam_search(
- pre_ids,
- pre_score,
- topk_indices,
- accu_scores,
- beam_size,
- end_id=10,
- level=0)
-
- pd.increment(x=counter, value=1, in_place=True)
- # 将 search 结果和对应的隐层状态写入 tensor array 中
- pd.array_write(current_state, array=state_array, i=counter)
- pd.array_write(selected_ids, array=ids_array, i=counter)
- pd.array_write(selected_scores, array=scores_array, i=counter)
+ topk_scores, topk_indices = fluid.layers.topk(prob, k=beam_size)
+ accu_scores = fluid.layers.elementwise_add(
+ x=fluid.layers.log(topk_scores),
+ y=fluid.layers.reshape(pre_score, shape=[-1]),
+ axis=0)
+ accu_scores = fluid.layers.lod_reset(x=accu_scores, y=pre_ids)
+ selected_ids, selected_scores = fluid.layers.beam_search(
+ pre_ids, pre_score, topk_indices, accu_scores, beam_size, end_id=1)
+
+ fluid.layers.increment(x=counter, value=1, in_place=True)
+ # 将 search 结果写入 tensor array 中
+ fluid.layers.array_write(selected_ids, array=ids_array, i=counter)
+ fluid.layers.array_write(selected_scores, array=scores_array, i=counter)
+ # sequence_expand 作为 gather 使用以获取search结果对应的状态,并更新
+ current_state = fluid.layers.sequence_expand(current_state,
+ selected_ids)
+ fluid.layers.array_write(current_state, array=state_array, i=counter)
+ current_enc_out = fluid.layers.sequence_expand(encoder_out,
+ selected_ids)
+ fluid.layers.assign(current_enc_out, encoder_out)
+ current_enc_out_proj = fluid.layers.sequence_expand(
+ encoder_out_proj, selected_ids)
+ fluid.layers.assign(current_enc_out_proj, encoder_out_proj)
# 更新循环终止条件
- length_cond = pd.less_than(x=counter, y=array_len)
- finish_cond = pd.logical_not(pd.is_empty(x=selected_ids))
- pd.logical_and(x=length_cond, y=finish_cond, out=cond)
+ length_cond = fluid.layers.less_than(x=counter, y=max_len)
+ finish_cond = fluid.layers.logical_not(
+ fluid.layers.is_empty(x=selected_ids))
+ fluid.layers.logical_and(x=length_cond, y=finish_cond, out=cond)
- translation_ids, translation_scores = pd.beam_search_decode(
- ids=ids_array, scores=scores_array, beam_size=beam_size, end_id=10)
+ # 根据保存的每一步的结果,回溯生成最终解码结果
+ translation_ids, translation_scores = fluid.layers.beam_search_decode(
+ ids=ids_array, scores=scores_array, beam_size=beam_size, end_id=1)
return translation_ids, translation_scores
```
-进而,我们定义一个`train_program`来使用`inference_program`计算出的结果,在标记数据的帮助下来计算误差。我们还定义了一个`optimizer_func`来定义优化器。
+使用编码器和预测模式的解码器,预测网络定义如下:
```python
-def train_program(is_sparse):
- context = encoder(is_sparse)
- rnn_out = train_decoder(context, is_sparse)
- label = pd.data(
- name="target_language_next_word", shape=[1], dtype='int64', lod_level=1)
- cost = pd.cross_entropy(input=rnn_out, label=label)
- avg_cost = pd.mean(cost)
- return avg_cost
-
-
-def optimizer_func():
- return fluid.optimizer.Adagrad(
- learning_rate=1e-4,
- regularization=fluid.regularizer.L2DecayRegularizer(
- regularization_coeff=0.1))
+def infer_model():
+ encoder_out = encoder()
+ translation_ids, translation_scores = infer_decoder(encoder_out)
+ return translation_ids, translation_scores
```
## 训练模型
-### 定义训练环境
-定义您的训练环境,可以指定训练是发生在CPU还是GPU上。
-
-```python
-use_cuda = False
-place = fluid.CUDAPlace(0) if use_cuda else fluid.CPUPlace()
-```
+### 构建训练程序
-### 定义数据提供器
-下一步是为训练和测试定义数据提供器。提供器读入一个大小为 `BATCH_SIZE`的数据。`paddle.dataset.wmt.train` 每次会在乱序化后提供一个大小为`BATCH_SIZE`的数据,乱序化的大小为缓存大小`buf_size`。
+定义用于训练的`Program`,在其中创建训练的网络结构并添加优化器。同时还要定义用于初始化的`Program`,在创建训练网络的同时隐式的加入参数初始化的操作。
```python
-train_reader = paddle.batch(
- paddle.reader.shuffle(
- paddle.dataset.wmt14.train(dict_size), buf_size=1000),
- batch_size=batch_size)
+train_prog = fluid.Program()
+startup_prog = fluid.Program()
+with fluid.program_guard(train_prog, startup_prog):
+ with fluid.unique_name.guard():
+ avg_cost = train_model()
+ optimizer = optimizer_func()
+ optimizer.minimize(avg_cost)
```
-### 构造训练器(trainer)
-训练器需要一个训练程序和一个训练优化函数。
+### 定义训练环境与执行器
+
+定义您的训练环境,可以指定训练是发生在CPU还是GPU上;并基于这个训练环境定义执行器。
```python
-is_sparse = False
-trainer = Trainer(
- train_func=partial(train_program, is_sparse),
- place=place,
- optimizer_func=optimizer_func)
+use_cuda = False
+# 定义使用设备和执行器
+place = fluid.CUDAPlace(0) if use_cuda else fluid.CPUPlace()
+exe = fluid.Executor(place)
```
-### 提供数据
+### 构建数据提供器
-`feed_order`用来定义每条产生的数据和`paddle.layer.data`之间的映射关系。比如,`wmt14.train`产生的第一列的数据对应的是`src_word_id`这个特征。
+使用封装的`paddle.dataset.wmt16.train`接口定义数据生成器,其每次产生一条样本,shuffle和组完batch后作为训练的输入;另外还需要指明输入数据中各字段和`data_layer`定义的各输入的对应关系,这可以通过`DataFeeder`完成, 下面的feeder将产生数据的第一列映射到`src_word_id`这个输入。
```python
-feed_order = [
+# 定义训练数据生成器
+train_data = paddle.batch(
+ paddle.reader.shuffle(
+ paddle.dataset.wmt16.train(source_dict_size, target_dict_size),
+ buf_size=10000),
+ batch_size=batch_size)
+# DataFeeder完成
+feeder = fluid.DataFeeder(
+ feed_list=[
'src_word_id', 'target_language_word', 'target_language_next_word'
- ]
+ ],
+ place=place,
+ program=train_prog)
```
-### 事件处理器
-回调函数`event_handler`在一个之前定义好的事件发生后会被调用。例如,我们可以在每步训练结束后查看误差。
+### 训练主循环
-```python
-def event_handler(event):
- if isinstance(event, EndStepEvent):
- if event.step % 10 == 0:
- print('pass_id=' + str(event.epoch) + ' batch=' + str(event.step))
-
- if event.step == 20:
- trainer.stop()
-```
-
-### 开始训练
-最后,我们传入训练循环数(`num_epoch`)和一些别的参数,调用 `trainer.train` 来开始训练。
+通过训练循环数(EPOCH_NUM)来进行训练循环,并且每次循环都保存训练好的参数。注意,循环训练前要首先执行初始化的`Program`来初始化参数。另外作为示例这里EPOCH_NUM设置较小,该数据集上实际大概需要20�个epoch左右收敛。
```python
-EPOCH_NUM = 1
-
-trainer.train(
- reader=train_reader,
- num_epochs=EPOCH_NUM,
- event_handler=event_handler,
- feed_order=feed_order)
+# 执行初始化 Program,进行参数初始化
+exe.run(startup_prog)
+# 循环迭代执行训练
+EPOCH_NUM = 2
+for pass_id in six.moves.xrange(EPOCH_NUM):
+ batch_id = 0
+ for data in train_data():
+ cost = exe.run(
+ train_prog, feed=feeder.feed(data), fetch_list=[avg_cost])[0]
+ print('pass_id: %d, batch_id: %d, loss: %f' % (pass_id, batch_id,
+ cost))
+ batch_id += 1
+ # 保存模型
+ fluid.io.save_params(exe, model_save_dir, main_program=train_prog)
```
## 应用模型
-### 定义解码部分
+### 构建预测程序
-使用上面定义的 `encoder` 和 `decoder` 函数来推测翻译后的对应id和分数.
+定义用于预测的`Program`,在其中创建预测的网络结构。
```python
-context = encoder(is_sparse)
-translation_ids, translation_scores = decode(context, is_sparse)
+infer_prog = fluid.Program()
+startup_prog = fluid.Program()
+with fluid.program_guard(infer_prog, startup_prog):
+ with fluid.unique_name.guard():
+ translation_ids, translation_scores = infer_model()
```
-### 定义数据
+### 构建数据提供器
-我们先初始化id和分数来生成tensors来作为输入数据。在这个预测例子中,我们用`wmt14.test`数据中的第一个记录来做推测,最后我们用"源字典"和"目标字典"来列印对应的句子结果。
+和训练类似,这里使用封装的`paddle.dataset.wmt16.test`接口定义测试数据生成器,测试数据共1000条,组完batch后作为预测的输入;另外我们获取源语言和目标语言id到word的词典,以将id序列转换为明文序列打印输出。
```python
-init_ids_data = np.array([1 for _ in range(batch_size)], dtype='int64')
-init_scores_data = np.array(
- [1. for _ in range(batch_size)], dtype='float32')
-init_ids_data = init_ids_data.reshape((batch_size, 1))
-init_scores_data = init_scores_data.reshape((batch_size, 1))
-init_lod = [1] * batch_size
-init_lod = [init_lod, init_lod]
-
-init_ids = fluid.create_lod_tensor(init_ids_data, init_lod, place)
-init_scores = fluid.create_lod_tensor(init_scores_data, init_lod, place)
-
test_data = paddle.batch(
- paddle.reader.shuffle(
- paddle.dataset.wmt14.test(dict_size), buf_size=1000),
+ paddle.dataset.wmt16.test(source_dict_size, target_dict_size),
batch_size=batch_size)
-
-feed_order = ['src_word_id']
-feed_list = [
- framework.default_main_program().global_block().var(var_name)
- for var_name in feed_order
-]
-feeder = fluid.DataFeeder(feed_list, place)
-
-src_dict, trg_dict = paddle.dataset.wmt14.get_dict(dict_size)
+src_idx2word = paddle.dataset.wmt16.get_dict(
+ "en", source_dict_size, reverse=True)
+trg_idx2word = paddle.dataset.wmt16.get_dict(
+ "de", target_dict_size, reverse=True)
```
### 测试
-现在我们可以进行预测了。我们要在`feed_order`提供对应参数,放在`executor`上运行以取得id和分数结果
+首先要加载训练过程保存下来的模型,然后就可以循环测试数据进行预测了。这里每次运行我们都会创建�`data_layer`对应输入数据的`dict`传入,这个和`DataFeeder`相同的效果。生成过程对于每个测试数据都会将源语言句子和`beam_size`个生成句子打印输出。
```python
-exe = Executor(place)
-exe.run(framework.default_startup_program())
-
-for data in test_data():
- feed_data = map(lambda x: [x[0]], data)
- feed_dict = feeder.feed(feed_data)
- feed_dict['init_ids'] = init_ids
- feed_dict['init_scores'] = init_scores
-
- results = exe.run(
- framework.default_main_program(),
- feed=feed_dict,
- fetch_list=[translation_ids, translation_scores],
- return_numpy=False)
-
- result_ids = np.array(results[0])
- result_ids_lod = results[0].lod()
- result_scores = np.array(results[1])
-
- print("Original sentence:")
- print(" ".join([src_dict[w] for w in feed_data[0][0][1:-1]]))
- print("Translated score and sentence:")
- for i in xrange(beam_size):
- start_pos = result_ids_lod[1][i] + 1
- end_pos = result_ids_lod[1][i+1]
- print("%d\t%.4f\t%s\n" % (i+1, result_scores[end_pos-1],
- " ".join([trg_dict[w] for w in result_ids[start_pos:end_pos]])))
-
- break
+ fluid.io.load_params(exe, model_save_dir, main_program=infer_prog)
+
+ for data in test_data():
+ src_word_id = fluid.create_lod_tensor(
+ data=map(lambda x: x[0], data),
+ recursive_seq_lens=[[len(x[0]) for x in data]],
+ place=place)
+ # init_ids内容为start token
+ init_ids = fluid.create_lod_tensor(
+ data=np.array([[0]] * len(data), dtype='int64'),
+ recursive_seq_lens=[[1] * len(data)] * 2,
+ place=place)
+ # init_scores为beam search过程累积得分的初值
+ init_scores = fluid.create_lod_tensor(
+ data=np.array([[0.]] * len(data), dtype='float32'),
+ recursive_seq_lens=[[1] * len(data)] * 2,
+ place=place)
+ seq_ids, seq_scores = exe.run(
+ infer_prog,
+ feed={
+ 'src_word_id': src_word_id,
+ 'init_ids': init_ids,
+ 'init_scores': init_scores
+ },
+ fetch_list=[translation_ids, translation_scores],
+ return_numpy=False)
+ # 如何解析翻译结果详见 train.py 中对应代码的注释说明
+ hyps = [[] for i in range(len(seq_ids.lod()[0]) - 1)]
+ scores = [[] for i in range(len(seq_scores.lod()[0]) - 1)]
+ for i in range(len(seq_ids.lod()[0]) - 1):
+ start = seq_ids.lod()[0][i]
+ end = seq_ids.lod()[0][i + 1]
+ print("Original sentence:")
+ print(" ".join([src_idx2word[idx] for idx in data[i][0][1:-1]]))
+ print("Translated score and sentence:")
+ for j in range(end - start):
+ sub_start = seq_ids.lod()[1][start + j]
+ sub_end = seq_ids.lod()[1][start + j + 1]
+ hyps[i].append(" ".join([
+ trg_idx2word[idx]
+ for idx in np.array(seq_ids)[sub_start:sub_end][1:-1]
+ ]))
+ scores[i].append(np.array(seq_scores)[sub_end - 1])
+ print(scores[i][-1], hyps[i][-1].encode('utf8'))
+```
+可以观察到如下的预测结果输出:
+```txt
+Original sentence:
+Two adults and two children sit on a park bench .
+Translated score and sentence:
+-2.5993705 Zwei Erwachsene und zwei Kinder sitzen auf einer Parkbank .
+-2.6617606 Zwei Erwachsene und zwei Kinder spielen auf einer Parkbank .
+-3.186554 Zwei Erwachsene und zwei Kinder sitzen auf einer Bank .
+-3.4353821 Zwei Erwachsene und zwei Kinder spielen auf einer Bank .
```
## 总结
diff --git a/08.machine_translation/image/attention_decoder_formula.png b/08.machine_translation/image/attention_decoder_formula.png
new file mode 100644
index 0000000000000000000000000000000000000000..2f63489c5abbbc301cbcddaf862c4c89722eb1fd
Binary files /dev/null and b/08.machine_translation/image/attention_decoder_formula.png differ
diff --git a/08.machine_translation/image/decoder_formula.png b/08.machine_translation/image/decoder_formula.png
new file mode 100644
index 0000000000000000000000000000000000000000..94d18fadc4441614722d3de7684eecb2112dc3d9
Binary files /dev/null and b/08.machine_translation/image/decoder_formula.png differ
diff --git a/08.machine_translation/image/probability_formula.png b/08.machine_translation/image/probability_formula.png
new file mode 100644
index 0000000000000000000000000000000000000000..34e94f7efdb0eb91e50f2641e30fbb3fef2fe9b9
Binary files /dev/null and b/08.machine_translation/image/probability_formula.png differ
diff --git a/08.machine_translation/image/sum_formula.png b/08.machine_translation/image/sum_formula.png
new file mode 100644
index 0000000000000000000000000000000000000000..f220f689d52e76e4c58a1ebbebe4c02789246d87
Binary files /dev/null and b/08.machine_translation/image/sum_formula.png differ
diff --git a/08.machine_translation/image/weight_formula.png b/08.machine_translation/image/weight_formula.png
new file mode 100644
index 0000000000000000000000000000000000000000..4140746d8c12c60258eed0f7aa59d6de823e7776
Binary files /dev/null and b/08.machine_translation/image/weight_formula.png differ
diff --git a/08.machine_translation/index.cn.html b/08.machine_translation/index.cn.html
index 849f8774050a9bb7835f9da37935cb79e793d495..549cfe0e0b4f38879303fdd499be10483ce5b1dd 100644
--- a/08.machine_translation/index.cn.html
+++ b/08.machine_translation/index.cn.html
@@ -44,6 +44,11 @@
本教程源代码目录在[book/machine_translation](https://github.com/PaddlePaddle/book/tree/develop/08.machine_translation),初次使用请您参考[Book文档使用说明](https://github.com/PaddlePaddle/book/blob/develop/README.cn.md#运行这本书)。
+### 说明
+1. 硬件要求 本文可支持在CPU、GPU下运行
+2. 对docker file cuda/cudnn的支持 如果您使用了本文配套的docker镜像,请注意:该镜像对GPU的支持仅限于CUDA 8,cuDNN 5
+3. 文档中代码和train.py不一致的问题 请注意:为使本文更加易读易用,我们拆分、调整了train.py的代码并放入本文。本文中代码与train.py的运行结果一致,如希望直接看到训练脚本输出效果,可运行[train.py](https://github.com/PaddlePaddle/book/blob/develop/08.machine_translation/train.py)。
+
## 背景介绍
机器翻译(machine translation, MT)是用计算机来实现不同语言之间翻译的技术。被翻译的语言通常称为源语言(source language),翻译成的结果语言称为目标语言(target language)。机器翻译即实现从源语言到目标语言转换的过程,是自然语言处理的重要研究领域之一。
@@ -79,7 +84,21 @@
## 模型概览
-本节依次介绍双向循环神经网络(Bi-directional Recurrent Neural Network),NMT模型中典型的编码器-解码器(Encoder-Decoder)框架以及柱搜索(beam search)算法。
+本节依次介绍GRU(Gated Recurrent Unit,门控循环单元),双向循环神经网络(Bi-directional Recurrent Neural Network),NMT模型中典型的编码器-解码器(Encoder-Decoder)框架和注意力(Attention)机制,以及柱搜索(beam search)算法。
+
+### GRU
+
+我们已经在[情感分析](https://github.com/PaddlePaddle/book/blob/develop/06.understand_sentiment/README.cn.md)一章中介绍了循环神经网络(RNN)及长短时间记忆网络(LSTM)。相比于简单的RNN,LSTM增加了记忆单元(memory cell)、输入门(input gate)、遗忘门(forget gate)及输出门(output gate),这些门及记忆单元组合起来大大提升了RNN处理远距离依赖问题的能力。
+
+GRU\[[2](#参考文献)\]是Cho等人在LSTM上提出的简化版本,也是RNN的一种扩展,如下图所示。GRU单元只有两个门:
+- 重置门(reset gate):如果重置门关闭,会忽略掉历史信息,即历史不相干的信息不会影响未来的输出。
+- 更新门(update gate):将LSTM的输入门和遗忘门合并,用于控制历史信息对当前时刻隐层输出的影响。如果更新门接近1,会把历史信息传递下去。
+
+
+图2. GRU(门控循环单元)
+
+
+一般来说,具有短距离依赖属性的序列,其重置门比较活跃;相反,具有长距离依赖属性的序列,其更新门比较活跃。另外,Chung等人\[[3](#参考文献)\]通过多组实验表明,GRU虽然参数更少,但是在多个任务上都和LSTM有相近的表现。
### 双向循环神经网络
@@ -123,19 +142,56 @@
机器翻译任务的训练过程中,解码阶段的目标是最大化下一个正确的目标语言词的概率。思路是:
1. 每一个时刻,根据源语言句子的编码信息(又叫上下文向量,context vector)$c$、真实目标语言序列的第$i$个词$u_i$和$i$时刻RNN的隐层状态$z_i$,计算出下一个隐层状态$z_{i+1}$。计算公式如下:
-$$z_{i+1}=\phi_{\theta '} \left ( c,u_i,z_i \right )$$
+
+
+
+
`,表示解码开始;$z_i$是$i$时刻解码RNN的隐层状态,$z_0$是一个全零的向量。
-2. 将$z_{i+1}$通过`softmax`归一化,得到目标语言序列的第$i+1$个单词的概率分布$p_{i+1}$。概率分布公式如下:
-$$p\left ( u_{i+1}|u_{<i+1},\mathbf{x} \right )=softmax(W_sz_{i+1}+b_z)$$
+1. 将$z_{i+1}$通过`softmax`归一化,得到目标语言序列的第$i+1$个单词的概率分布$p_{i+1}$。概率分布公式如下:
+
+
+
+
+
+
+
+
+
+
+
+图6. 基于注意力机制的解码器
+
+
### 柱搜索算法
@@ -156,7 +212,7 @@ $$p\left ( u_{i+1}|u_{<i+1},\mathbf{x} \right )=softmax(W_sz_{i+1}+b_z)$$
## 数据介绍
-本教程使用[WMT-14](http://www-lium.univ-lemans.fr/~schwenk/cslm_joint_paper/)数据集中的[bitexts(after selection)](http://www-lium.univ-lemans.fr/~schwenk/cslm_joint_paper/data/bitexts.tgz)作为训练集,[dev+test data](http://www-lium.univ-lemans.fr/~schwenk/cslm_joint_paper/data/dev+test.tgz)作为测试集和生成集。
+本教程使用[WMT-16](http://www.statmt.org/wmt16/)新增的[multimodal task](http://www.statmt.org/wmt16/multimodal-task.html)中的[translation task](http://www.statmt.org/wmt16/multimodal-task.html#task1)的数据集。该数据集为英德翻译数据,包含29001条训练数据,1000条测试数据。
### 数据预处理
@@ -172,347 +228,408 @@ $$p\left ( u_{i+1}|u_{<i+1},\mathbf{x} \right )=softmax(W_sz_{i+1}+b_z)$$
### 示例数据
-因为完整的数据集数据量较大,为了验证训练流程,PaddlePaddle接口paddle.dataset.wmt14中默认提供了一个经过预处理的[较小规模的数据集](http://paddlepaddle.bj.bcebos.com/demo/wmt_shrinked_data/wmt14.tgz)。
-
-该数据集有193319条训练数据,6003条测试数据,词典长度为30000。因为数据规模限制,使用该数据集训练出来的模型效果无法保证。
+为了验证训练流程,PaddlePaddle接口`paddle.dataset.wmt16`中提供了对该数据集预处理后的版本(http://paddlemodels.bj.bcebos.com/wmt/wmt16.tar.gz),调用该接口即可直接使用,因为数据规模限制,这里只作为示例使用,在相应的测试集上具有一定效果但在更多测试数据上的效果无法保证。
## 模型配置说明
-下面我们开始根据输入数据的形式配置模型。首先引入所需的库函数以及定义全局变量。
+下面我们开始根据输入数据的形式配置模型。首先引入所需的库函数以及定义全局变量:
```python
from __future__ import print_function
-import contextlib
+import os
+import six
-import numpy as np
import paddle
import paddle.fluid as fluid
-import paddle.fluid.framework as framework
-import paddle.fluid.layers as pd
-from paddle.fluid.executor import Executor
-from functools import partial
-import os
-try:
- from paddle.fluid.contrib.trainer import *
- from paddle.fluid.contrib.inferencer import *
-except ImportError:
- print(
- "In the fluid 1.0, the trainer and inferencer are moving to paddle.fluid.contrib",
- file=sys.stderr)
- from paddle.fluid.trainer import *
- from paddle.fluid.inferencer import *
-
-dict_size = 30000 # 字典维度
-source_dict_dim = target_dict_dim = dict_size # 源/目标语言字典维度
-hidden_dim = 32 # 编码器中的隐层大小
-word_dim = 16 # 词向量维度
-batch_size = 2 # batch 中的样本数
-max_length = 8 # 生成句子的最大长度
-beam_size = 2 # 柱宽度
-
-decoder_size = hidden_dim # 解码器中的隐层大小
+
+dict_size = 30000 # 词典大小
+source_dict_size = target_dict_size = dict_size # 源/目标语言字典大小
+word_dim = 512 # 词向量维度
+hidden_dim = 512 # 编码器中的隐层大小
+decoder_size = hidden_dim # 解码器中的隐层大小
+max_length = 256 # 解码生成句子的最大长度
+beam_size = 4 # beam search的柱宽度
+batch_size = 64 # batch 中的样本数
+
+is_sparse = True
+model_save_dir = "machine_translation.inference.model"
```
然后如下实现编码器框架:
- ```python
- def encoder(is_sparse):
+```python
+def encoder():
# 定义源语言id序列的输入数据
- src_word_id = pd.data(
+ src_word_id = fluid.layers.data(
name="src_word_id", shape=[1], dtype='int64', lod_level=1)
# 将上述编码映射到低维语言空间的词向量
- src_embedding = pd.embedding(
+ src_embedding = fluid.layers.embedding(
input=src_word_id,
- size=[dict_size, word_dim],
+ size=[source_dict_size, word_dim],
dtype='float32',
- is_sparse=is_sparse,
- param_attr=fluid.ParamAttr(name='vemb'))
- # LSTM层:fc + dynamic_lstm
- fc1 = pd.fc(input=src_embedding, size=hidden_dim * 4, act='tanh')
- lstm_hidden0, lstm_0 = pd.dynamic_lstm(input=fc1, size=hidden_dim * 4)
- # 取源语言序列编码后的最后一个状态
- encoder_out = pd.sequence_last_step(input=lstm_hidden0)
- return encoder_out
- ```
-
-再实现训练模式下的解码器:
+ is_sparse=is_sparse)
+ # 用双向GRU编码源语言序列,拼接两个GRU的编码结果得到h
+ fc_forward = fluid.layers.fc(
+ input=src_embedding, size=hidden_dim * 3, bias_attr=False)
+ src_forward = fluid.layers.dynamic_gru(input=fc_forward, size=hidden_dim)
+ fc_backward = fluid.layers.fc(
+ input=src_embedding, size=hidden_dim * 3, bias_attr=False)
+ src_backward = fluid.layers.dynamic_gru(
+ input=fc_backward, size=hidden_dim, is_reverse=True)
+ encoded_vector = fluid.layers.concat(
+ input=[src_forward, src_backward], axis=1)
+ return encoded_vector
+```
+
+再实现基于注意力机制的解码器:
+ - 首先定义解码器中单步的计算,即$z_{i+1}=\phi _{\theta '}\left ( c_i,u_i,z_i \right )$,如下:
+
+ ```python
+ # 定义RNN中的单步计算
+ def cell(x, hidden, encoder_out, encoder_out_proj):
+ # 定义attention用以计算context,即 c_i,这里使用Bahdanau attention机制
+ def simple_attention(encoder_vec, encoder_proj, decoder_state):
+ decoder_state_proj = fluid.layers.fc(
+ input=decoder_state, size=decoder_size, bias_attr=False)
+ # sequence_expand将单步内容扩展为与encoder输出相同的序列
+ decoder_state_expand = fluid.layers.sequence_expand(
+ x=decoder_state_proj, y=encoder_proj)
+ mixed_state = fluid.layers.elementwise_add(encoder_proj,
+ decoder_state_expand)
+ attention_weights = fluid.layers.fc(
+ input=mixed_state, size=1, bias_attr=False)
+ attention_weights = fluid.layers.sequence_softmax(
+ input=attention_weights)
+ weigths_reshape = fluid.layers.reshape(x=attention_weights, shape=[-1])
+ scaled = fluid.layers.elementwise_mul(
+ x=encoder_vec, y=weigths_reshape, axis=0)
+ context = fluid.layers.sequence_pool(input=scaled, pool_type='sum')
+ return context
+
+ context = simple_attention(encoder_out, encoder_out_proj, hidden)
+ out = fluid.layers.fc(
+ input=[x, context], size=decoder_size * 3, bias_attr=False)
+ out = fluid.layers.gru_unit(
+ input=out, hidden=hidden, size=decoder_size * 3)[0]
+ return out, out
+ ```
+
+ - 基于定义的单步计算,使用`DynamicRNN`实现多步循环的训练模式下解码器,如下:
+
+ ```python
+ def train_decoder(encoder_out):
+ # 获取编码器输出的最后一步并进行非线性映射以构造解码器RNN的初始状态
+ encoder_last = fluid.layers.sequence_last_step(input=encoder_out)
+ encoder_last_proj = fluid.layers.fc(
+ input=encoder_last, size=decoder_size, act='tanh')
+ # 编码器输出在attention中计算结果的cache
+ encoder_out_proj = fluid.layers.fc(
+ input=encoder_out, size=decoder_size, bias_attr=False)
+
+ # 定义目标语言id序列的输入数据,并映射到低维语言空间的词向量
+ trg_language_word = fluid.layers.data(
+ name="target_language_word", shape=[1], dtype='int64', lod_level=1)
+ trg_embedding = fluid.layers.embedding(
+ input=trg_language_word,
+ size=[target_dict_size, word_dim],
+ dtype='float32',
+ is_sparse=is_sparse)
+
+ rnn = fluid.layers.DynamicRNN()
+ with rnn.block():
+ # 获取当前步目标语言输入的词向量
+ x = rnn.step_input(trg_embedding)
+ # 获取隐层状态
+ pre_state = rnn.memory(init=encoder_last_proj, need_reorder=True)
+ # 在DynamicRNN中需使用static_input获取encoder相关的内容
+ # 对decoder来说这些内容在每个时间步都是固定的
+ encoder_out = rnn.static_input(encoder_out)
+ encoder_out_proj = rnn.static_input(encoder_out_proj)
+ # 执行单步的计算单元
+ out, current_state = cell(x, pre_state, encoder_out, encoder_out_proj)
+ # 计算归一化的单词预测概率
+ prob = fluid.layers.fc(input=out, size=target_dict_size, act='softmax')
+ # 更新隐层状态
+ rnn.update_memory(pre_state, current_state)
+ # 输出预测概率
+ rnn.output(prob)
+
+ return rnn()
+ ```
+
+接着就可以使用编码器和解码器定义整个训练网络;为了进行训练还需要定义优化器,如下:
```python
- def train_decoder(context, is_sparse):
- # 定义目标语言id序列的输入数据,并映射到低维语言空间的词向量
- trg_language_word = pd.data(
- name="target_language_word", shape=[1], dtype='int64', lod_level=1)
- trg_embedding = pd.embedding(
- input=trg_language_word,
- size=[dict_size, word_dim],
- dtype='float32',
- is_sparse=is_sparse,
- param_attr=fluid.ParamAttr(name='vemb'))
-
- rnn = pd.DynamicRNN()
- with rnn.block(): # 使用 DynamicRNN 定义每一步的计算
- # 获取当前步目标语言输入的词向量
- current_word = rnn.step_input(trg_embedding)
- # 获取隐层状态
- pre_state = rnn.memory(init=context)
- # 解码器计算单元:单层前馈网络
- current_state = pd.fc(input=[current_word, pre_state],
- size=decoder_size,
- act='tanh')
- # 计算归一化的单词预测概率
- current_score = pd.fc(input=current_state,
- size=target_dict_dim,
- act='softmax')
- # 更新RNN的隐层状态
- rnn.update_memory(pre_state, current_state)
- # 输出预测概率
- rnn.output(current_score)
-
- return rnn()
+def train_model():
+ encoder_out = encoder()
+ rnn_out = train_decoder(encoder_out)
+ label = fluid.layers.data(
+ name="target_language_next_word", shape=[1], dtype='int64', lod_level=1)
+ # 定义损失函数
+ cost = fluid.layers.cross_entropy(input=rnn_out, label=label)
+ avg_cost = fluid.layers.mean(cost)
+ return avg_cost
+
+def optimizer_func():
+ # 设置梯度裁剪
+ fluid.clip.set_gradient_clip(
+ clip=fluid.clip.GradientClipByGlobalNorm(clip_norm=5.0))
+ # 定义先增后降的学习率策略
+ lr_decay = fluid.layers.learning_rate_scheduler.noam_decay(hidden_dim, 1000)
+ return fluid.optimizer.Adam(
+ learning_rate=lr_decay,
+ regularization=fluid.regularizer.L2DecayRegularizer(
+ regularization_coeff=1e-4))
```
-实现推测模式下的解码器:
+以上是训练所需的模型构件,预测(生成)模式下基于beam search的解码器需要借助`while_op`实现,如下:
```python
-def decode(context, is_sparse):
- init_state = context
- # 定义解码过程循环计数变量
- array_len = pd.fill_constant(shape=[1], dtype='int64', value=max_length)
- counter = pd.zeros(shape=[1], dtype='int64', force_cpu=True)
+def infer_decoder(encoder_out):
+ # 获取编码器输出的最后一步并进行非线性映射以构造解码器RNN的初始状态
+ encoder_last = fluid.layers.sequence_last_step(input=encoder_out)
+ encoder_last_proj = fluid.layers.fc(
+ input=encoder_last, size=decoder_size, act='tanh')
+ # 编码器输出在attention中计算结果的cache
+ encoder_out_proj = fluid.layers.fc(
+ input=encoder_out, size=decoder_size, bias_attr=False)
+
+ # 最大解码步数
+ max_len = fluid.layers.fill_constant(
+ shape=[1], dtype='int64', value=max_length)
+ # 解码步数计数变量
+ counter = fluid.layers.zeros(shape=[1], dtype='int64', force_cpu=True)
# 定义 tensor array 用以保存各个时间步的内容,并写入初始id,score和state
- state_array = pd.create_array('float32')
- pd.array_write(init_state, array=state_array, i=counter)
-
- ids_array = pd.create_array('int64')
- scores_array = pd.create_array('float32')
-
- init_ids = pd.data(name="init_ids", shape=[1], dtype="int64", lod_level=2)
- init_scores = pd.data(
+ init_ids = fluid.layers.data(
+ name="init_ids", shape=[1], dtype="int64", lod_level=2)
+ init_scores = fluid.layers.data(
name="init_scores", shape=[1], dtype="float32", lod_level=2)
-
- pd.array_write(init_ids, array=ids_array, i=counter)
- pd.array_write(init_scores, array=scores_array, i=counter)
+ ids_array = fluid.layers.array_write(init_ids, i=counter)
+ scores_array = fluid.layers.array_write(init_scores, i=counter)
+ state_array = fluid.layers.array_write(encoder_last_proj, i=counter)
# 定义循环终止条件变量
- cond = pd.less_than(x=counter, y=array_len)
- # 定义 while_op
- while_op = pd.While(cond=cond)
- with while_op.block(): # 定义每一步的计算
+ cond = fluid.layers.less_than(x=counter, y=max_len)
+ while_op = fluid.layers.While(cond=cond)
+ with while_op.block():
# 获取解码器在当前步的输入,包括上一步选择的id,对应的score和上一步的state
- pre_ids = pd.array_read(array=ids_array, i=counter)
- pre_state = pd.array_read(array=state_array, i=counter)
- pre_score = pd.array_read(array=scores_array, i=counter)
-
- # 更新输入的state为上一步选择id对应的state
- pre_state_expanded = pd.sequence_expand(pre_state, pre_score)
- # 同训练模式下解码器中的计算逻辑,包括获取输入向量,解码器计算单元计算和
- # 归一化单词预测概率的计算
- pre_ids_emb = pd.embedding(
+ pre_ids = fluid.layers.array_read(array=ids_array, i=counter)
+ pre_score = fluid.layers.array_read(array=scores_array, i=counter)
+ pre_state = fluid.layers.array_read(array=state_array, i=counter)
+
+ # 同train_decoder中的内容,进行RNN的单步计算
+ pre_ids_emb = fluid.layers.embedding(
input=pre_ids,
- size=[dict_size, word_dim],
+ size=[target_dict_size, word_dim],
dtype='float32',
is_sparse=is_sparse)
- current_state = pd.fc(input=[pre_state_expanded, pre_ids_emb],
- size=decoder_size,
- act='tanh')
- current_state_with_lod = pd.lod_reset(x=current_state, y=pre_score)
- current_score = pd.fc(input=current_state_with_lod,
- size=target_dict_dim,
- act='softmax')
- topk_scores, topk_indices = pd.topk(current_score, k=beam_size)
+ out, current_state = cell(pre_ids_emb, pre_state, encoder_out,
+ encoder_out_proj)
+ prob = fluid.layers.fc(
+ input=current_state, size=target_dict_size, act='softmax')
# 计算累计得分,进行beam search
- accu_scores = pd.elementwise_add(
- x=pd.log(topk_scores), y=pd.reshape(pre_score, shape=[-1]), axis=0)
- selected_ids, selected_scores = pd.beam_search(
- pre_ids,
- pre_score,
- topk_indices,
- accu_scores,
- beam_size,
- end_id=10,
- level=0)
-
- pd.increment(x=counter, value=1, in_place=True)
- # 将 search 结果和对应的隐层状态写入 tensor array 中
- pd.array_write(current_state, array=state_array, i=counter)
- pd.array_write(selected_ids, array=ids_array, i=counter)
- pd.array_write(selected_scores, array=scores_array, i=counter)
+ topk_scores, topk_indices = fluid.layers.topk(prob, k=beam_size)
+ accu_scores = fluid.layers.elementwise_add(
+ x=fluid.layers.log(topk_scores),
+ y=fluid.layers.reshape(pre_score, shape=[-1]),
+ axis=0)
+ accu_scores = fluid.layers.lod_reset(x=accu_scores, y=pre_ids)
+ selected_ids, selected_scores = fluid.layers.beam_search(
+ pre_ids, pre_score, topk_indices, accu_scores, beam_size, end_id=1)
+
+ fluid.layers.increment(x=counter, value=1, in_place=True)
+ # 将 search 结果写入 tensor array 中
+ fluid.layers.array_write(selected_ids, array=ids_array, i=counter)
+ fluid.layers.array_write(selected_scores, array=scores_array, i=counter)
+ # sequence_expand 作为 gather 使用以获取search结果对应的状态,并更新
+ current_state = fluid.layers.sequence_expand(current_state,
+ selected_ids)
+ fluid.layers.array_write(current_state, array=state_array, i=counter)
+ current_enc_out = fluid.layers.sequence_expand(encoder_out,
+ selected_ids)
+ fluid.layers.assign(current_enc_out, encoder_out)
+ current_enc_out_proj = fluid.layers.sequence_expand(
+ encoder_out_proj, selected_ids)
+ fluid.layers.assign(current_enc_out_proj, encoder_out_proj)
# 更新循环终止条件
- length_cond = pd.less_than(x=counter, y=array_len)
- finish_cond = pd.logical_not(pd.is_empty(x=selected_ids))
- pd.logical_and(x=length_cond, y=finish_cond, out=cond)
+ length_cond = fluid.layers.less_than(x=counter, y=max_len)
+ finish_cond = fluid.layers.logical_not(
+ fluid.layers.is_empty(x=selected_ids))
+ fluid.layers.logical_and(x=length_cond, y=finish_cond, out=cond)
- translation_ids, translation_scores = pd.beam_search_decode(
- ids=ids_array, scores=scores_array, beam_size=beam_size, end_id=10)
+ # 根据保存的每一步的结果,回溯生成最终解码结果
+ translation_ids, translation_scores = fluid.layers.beam_search_decode(
+ ids=ids_array, scores=scores_array, beam_size=beam_size, end_id=1)
return translation_ids, translation_scores
```
-进而,我们定义一个`train_program`来使用`inference_program`计算出的结果,在标记数据的帮助下来计算误差。我们还定义了一个`optimizer_func`来定义优化器。
+使用编码器和预测模式的解码器,预测网络定义如下:
```python
-def train_program(is_sparse):
- context = encoder(is_sparse)
- rnn_out = train_decoder(context, is_sparse)
- label = pd.data(
- name="target_language_next_word", shape=[1], dtype='int64', lod_level=1)
- cost = pd.cross_entropy(input=rnn_out, label=label)
- avg_cost = pd.mean(cost)
- return avg_cost
-
-
-def optimizer_func():
- return fluid.optimizer.Adagrad(
- learning_rate=1e-4,
- regularization=fluid.regularizer.L2DecayRegularizer(
- regularization_coeff=0.1))
+def infer_model():
+ encoder_out = encoder()
+ translation_ids, translation_scores = infer_decoder(encoder_out)
+ return translation_ids, translation_scores
```
## 训练模型
-### 定义训练环境
-定义您的训练环境,可以指定训练是发生在CPU还是GPU上。
-
-```python
-use_cuda = False
-place = fluid.CUDAPlace(0) if use_cuda else fluid.CPUPlace()
-```
+### 构建训练程序
-### 定义数据提供器
-下一步是为训练和测试定义数据提供器。提供器读入一个大小为 `BATCH_SIZE`的数据。`paddle.dataset.wmt.train` 每次会在乱序化后提供一个大小为`BATCH_SIZE`的数据,乱序化的大小为缓存大小`buf_size`。
+定义用于训练的`Program`,在其中创建训练的网络结构并添加优化器。同时还要定义用于初始化的`Program`,在创建训练网络的同时隐式的加入参数初始化的操作。
```python
-train_reader = paddle.batch(
- paddle.reader.shuffle(
- paddle.dataset.wmt14.train(dict_size), buf_size=1000),
- batch_size=batch_size)
+train_prog = fluid.Program()
+startup_prog = fluid.Program()
+with fluid.program_guard(train_prog, startup_prog):
+ with fluid.unique_name.guard():
+ avg_cost = train_model()
+ optimizer = optimizer_func()
+ optimizer.minimize(avg_cost)
```
-### 构造训练器(trainer)
-训练器需要一个训练程序和一个训练优化函数。
+### 定义训练环境与执行器
+
+定义您的训练环境,可以指定训练是发生在CPU还是GPU上;并基于这个训练环境定义执行器。
```python
-is_sparse = False
-trainer = Trainer(
- train_func=partial(train_program, is_sparse),
- place=place,
- optimizer_func=optimizer_func)
+use_cuda = False
+# 定义使用设备和执行器
+place = fluid.CUDAPlace(0) if use_cuda else fluid.CPUPlace()
+exe = fluid.Executor(place)
```
-### 提供数据
+### 构建数据提供器
-`feed_order`用来定义每条产生的数据和`paddle.layer.data`之间的映射关系。比如,`wmt14.train`产生的第一列的数据对应的是`src_word_id`这个特征。
+使用封装的`paddle.dataset.wmt16.train`接口定义数据生成器,其每次产生一条样本,shuffle和组完batch后作为训练的输入;另外还需要指明输入数据中各字段和`data_layer`定义的各输入的对应关系,这可以通过`DataFeeder`完成, 下面的feeder将产生数据的第一列映射到`src_word_id`这个输入。
```python
-feed_order = [
+# 定义训练数据生成器
+train_data = paddle.batch(
+ paddle.reader.shuffle(
+ paddle.dataset.wmt16.train(source_dict_size, target_dict_size),
+ buf_size=10000),
+ batch_size=batch_size)
+# DataFeeder完成
+feeder = fluid.DataFeeder(
+ feed_list=[
'src_word_id', 'target_language_word', 'target_language_next_word'
- ]
+ ],
+ place=place,
+ program=train_prog)
```
-### 事件处理器
-回调函数`event_handler`在一个之前定义好的事件发生后会被调用。例如,我们可以在每步训练结束后查看误差。
+### 训练主循环
-```python
-def event_handler(event):
- if isinstance(event, EndStepEvent):
- if event.step % 10 == 0:
- print('pass_id=' + str(event.epoch) + ' batch=' + str(event.step))
-
- if event.step == 20:
- trainer.stop()
-```
-
-### 开始训练
-最后,我们传入训练循环数(`num_epoch`)和一些别的参数,调用 `trainer.train` 来开始训练。
+通过训练循环数(EPOCH_NUM)来进行训练循环,并且每次循环都保存训练好的参数。注意,循环训练前要首先执行初始化的`Program`来初始化参数。另外作为示例这里EPOCH_NUM设置较小,该数据集上实际大概需要20�个epoch左右收敛。
```python
-EPOCH_NUM = 1
-
-trainer.train(
- reader=train_reader,
- num_epochs=EPOCH_NUM,
- event_handler=event_handler,
- feed_order=feed_order)
+# 执行初始化 Program,进行参数初始化
+exe.run(startup_prog)
+# 循环迭代执行训练
+EPOCH_NUM = 2
+for pass_id in six.moves.xrange(EPOCH_NUM):
+ batch_id = 0
+ for data in train_data():
+ cost = exe.run(
+ train_prog, feed=feeder.feed(data), fetch_list=[avg_cost])[0]
+ print('pass_id: %d, batch_id: %d, loss: %f' % (pass_id, batch_id,
+ cost))
+ batch_id += 1
+ # 保存模型
+ fluid.io.save_params(exe, model_save_dir, main_program=train_prog)
```
## 应用模型
-### 定义解码部分
+### 构建预测程序
-使用上面定义的 `encoder` 和 `decoder` 函数来推测翻译后的对应id和分数.
+定义用于预测的`Program`,在其中创建预测的网络结构。
```python
-context = encoder(is_sparse)
-translation_ids, translation_scores = decode(context, is_sparse)
+infer_prog = fluid.Program()
+startup_prog = fluid.Program()
+with fluid.program_guard(infer_prog, startup_prog):
+ with fluid.unique_name.guard():
+ translation_ids, translation_scores = infer_model()
```
-### 定义数据
+### 构建数据提供器
-我们先初始化id和分数来生成tensors来作为输入数据。在这个预测例子中,我们用`wmt14.test`数据中的第一个记录来做推测,最后我们用"源字典"和"目标字典"来列印对应的句子结果。
+和训练类似,这里使用封装的`paddle.dataset.wmt16.test`接口定义测试数据生成器,测试数据共1000条,组完batch后作为预测的输入;另外我们获取源语言和目标语言id到word的词典,以将id序列转换为明文序列打印输出。
```python
-init_ids_data = np.array([1 for _ in range(batch_size)], dtype='int64')
-init_scores_data = np.array(
- [1. for _ in range(batch_size)], dtype='float32')
-init_ids_data = init_ids_data.reshape((batch_size, 1))
-init_scores_data = init_scores_data.reshape((batch_size, 1))
-init_lod = [1] * batch_size
-init_lod = [init_lod, init_lod]
-
-init_ids = fluid.create_lod_tensor(init_ids_data, init_lod, place)
-init_scores = fluid.create_lod_tensor(init_scores_data, init_lod, place)
-
test_data = paddle.batch(
- paddle.reader.shuffle(
- paddle.dataset.wmt14.test(dict_size), buf_size=1000),
+ paddle.dataset.wmt16.test(source_dict_size, target_dict_size),
batch_size=batch_size)
-
-feed_order = ['src_word_id']
-feed_list = [
- framework.default_main_program().global_block().var(var_name)
- for var_name in feed_order
-]
-feeder = fluid.DataFeeder(feed_list, place)
-
-src_dict, trg_dict = paddle.dataset.wmt14.get_dict(dict_size)
+src_idx2word = paddle.dataset.wmt16.get_dict(
+ "en", source_dict_size, reverse=True)
+trg_idx2word = paddle.dataset.wmt16.get_dict(
+ "de", target_dict_size, reverse=True)
```
### 测试
-现在我们可以进行预测了。我们要在`feed_order`提供对应参数,放在`executor`上运行以取得id和分数结果
+首先要加载训练过程保存下来的模型,然后就可以循环测试数据进行预测了。这里每次运行我们都会创建�`data_layer`对应输入数据的`dict`传入,这个和`DataFeeder`相同的效果。生成过程对于每个测试数据都会将源语言句子和`beam_size`个生成句子打印输出。
```python
-exe = Executor(place)
-exe.run(framework.default_startup_program())
-
-for data in test_data():
- feed_data = map(lambda x: [x[0]], data)
- feed_dict = feeder.feed(feed_data)
- feed_dict['init_ids'] = init_ids
- feed_dict['init_scores'] = init_scores
-
- results = exe.run(
- framework.default_main_program(),
- feed=feed_dict,
- fetch_list=[translation_ids, translation_scores],
- return_numpy=False)
-
- result_ids = np.array(results[0])
- result_ids_lod = results[0].lod()
- result_scores = np.array(results[1])
-
- print("Original sentence:")
- print(" ".join([src_dict[w] for w in feed_data[0][0][1:-1]]))
- print("Translated score and sentence:")
- for i in xrange(beam_size):
- start_pos = result_ids_lod[1][i] + 1
- end_pos = result_ids_lod[1][i+1]
- print("%d\t%.4f\t%s\n" % (i+1, result_scores[end_pos-1],
- " ".join([trg_dict[w] for w in result_ids[start_pos:end_pos]])))
-
- break
+ fluid.io.load_params(exe, model_save_dir, main_program=infer_prog)
+
+ for data in test_data():
+ src_word_id = fluid.create_lod_tensor(
+ data=map(lambda x: x[0], data),
+ recursive_seq_lens=[[len(x[0]) for x in data]],
+ place=place)
+ # init_ids内容为start token
+ init_ids = fluid.create_lod_tensor(
+ data=np.array([[0]] * len(data), dtype='int64'),
+ recursive_seq_lens=[[1] * len(data)] * 2,
+ place=place)
+ # init_scores为beam search过程累积得分的初值
+ init_scores = fluid.create_lod_tensor(
+ data=np.array([[0.]] * len(data), dtype='float32'),
+ recursive_seq_lens=[[1] * len(data)] * 2,
+ place=place)
+ seq_ids, seq_scores = exe.run(
+ infer_prog,
+ feed={
+ 'src_word_id': src_word_id,
+ 'init_ids': init_ids,
+ 'init_scores': init_scores
+ },
+ fetch_list=[translation_ids, translation_scores],
+ return_numpy=False)
+ # 如何解析翻译结果详见 train.py 中对应代码的注释说明
+ hyps = [[] for i in range(len(seq_ids.lod()[0]) - 1)]
+ scores = [[] for i in range(len(seq_scores.lod()[0]) - 1)]
+ for i in range(len(seq_ids.lod()[0]) - 1):
+ start = seq_ids.lod()[0][i]
+ end = seq_ids.lod()[0][i + 1]
+ print("Original sentence:")
+ print(" ".join([src_idx2word[idx] for idx in data[i][0][1:-1]]))
+ print("Translated score and sentence:")
+ for j in range(end - start):
+ sub_start = seq_ids.lod()[1][start + j]
+ sub_end = seq_ids.lod()[1][start + j + 1]
+ hyps[i].append(" ".join([
+ trg_idx2word[idx]
+ for idx in np.array(seq_ids)[sub_start:sub_end][1:-1]
+ ]))
+ scores[i].append(np.array(seq_scores)[sub_end - 1])
+ print(scores[i][-1], hyps[i][-1].encode('utf8'))
+```
+可以观察到如下的预测结果输出:
+```txt
+Original sentence:
+Two adults and two children sit on a park bench .
+Translated score and sentence:
+-2.5993705 Zwei Erwachsene und zwei Kinder sitzen auf einer Parkbank .
+-2.6617606 Zwei Erwachsene und zwei Kinder spielen auf einer Parkbank .
+-3.186554 Zwei Erwachsene und zwei Kinder sitzen auf einer Bank .
+-3.4353821 Zwei Erwachsene und zwei Kinder spielen auf einer Bank .
```
## 总结
diff --git a/08.machine_translation/infer.py b/08.machine_translation/infer.py
deleted file mode 100644
index 290d8e8f3ef461911634511a166a64e96817efc1..0000000000000000000000000000000000000000
--- a/08.machine_translation/infer.py
+++ /dev/null
@@ -1,210 +0,0 @@
-# Copyright (c) 2018 PaddlePaddle Authors. All Rights Reserved.
-#
-# Licensed under the Apache License, Version 2.0 (the "License");
-# you may not use this file except in compliance with the License.
-# You may obtain a copy of the License at
-#
-# http://www.apache.org/licenses/LICENSE-2.0
-#
-# Unless required by applicable law or agreed to in writing, software
-# distributed under the License is distributed on an "AS IS" BASIS,
-# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
-# See the License for the specific language governing permissions and
-# limitations under the License.
-
-from __future__ import print_function
-import numpy as np
-import paddle
-import paddle.fluid as fluid
-import paddle.fluid.framework as framework
-import paddle.fluid.layers as pd
-from paddle.fluid.executor import Executor
-import os
-
-dict_size = 30000
-source_dict_dim = target_dict_dim = dict_size
-hidden_dim = 32
-word_dim = 32
-batch_size = 2
-max_length = 8
-topk_size = 50
-beam_size = 2
-
-is_sparse = True
-decoder_size = hidden_dim
-model_save_dir = "machine_translation.inference.model"
-
-
-def encoder():
- src_word_id = pd.data(
- name="src_word_id", shape=[1], dtype='int64', lod_level=1)
- src_embedding = pd.embedding(
- input=src_word_id,
- size=[dict_size, word_dim],
- dtype='float32',
- is_sparse=is_sparse,
- param_attr=fluid.ParamAttr(name='vemb'))
-
- fc1 = pd.fc(input=src_embedding, size=hidden_dim * 4, act='tanh')
- lstm_hidden0, lstm_0 = pd.dynamic_lstm(input=fc1, size=hidden_dim * 4)
- encoder_out = pd.sequence_last_step(input=lstm_hidden0)
- return encoder_out
-
-
-def decode(context):
- init_state = context
- array_len = pd.fill_constant(shape=[1], dtype='int64', value=max_length)
- counter = pd.zeros(shape=[1], dtype='int64', force_cpu=True)
-
- # fill the first element with init_state
- state_array = pd.create_array('float32')
- pd.array_write(init_state, array=state_array, i=counter)
-
- # ids, scores as memory
- ids_array = pd.create_array('int64')
- scores_array = pd.create_array('float32')
-
- init_ids = pd.data(name="init_ids", shape=[1], dtype="int64", lod_level=2)
- init_scores = pd.data(
- name="init_scores", shape=[1], dtype="float32", lod_level=2)
-
- pd.array_write(init_ids, array=ids_array, i=counter)
- pd.array_write(init_scores, array=scores_array, i=counter)
-
- cond = pd.less_than(x=counter, y=array_len)
-
- while_op = pd.While(cond=cond)
- with while_op.block():
- pre_ids = pd.array_read(array=ids_array, i=counter)
- pre_state = pd.array_read(array=state_array, i=counter)
- pre_score = pd.array_read(array=scores_array, i=counter)
-
- # expand the lod of pre_state to be the same with pre_score
- pre_state_expanded = pd.sequence_expand(pre_state, pre_score)
-
- pre_ids_emb = pd.embedding(
- input=pre_ids,
- size=[dict_size, word_dim],
- dtype='float32',
- is_sparse=is_sparse,
- param_attr=fluid.ParamAttr(name='vemb'))
-
- # use rnn unit to update rnn
- current_state = pd.fc(
- input=[pre_state_expanded, pre_ids_emb],
- size=decoder_size,
- act='tanh')
- current_state_with_lod = pd.lod_reset(x=current_state, y=pre_score)
- # use score to do beam search
- current_score = pd.fc(
- input=current_state_with_lod, size=target_dict_dim, act='softmax')
- topk_scores, topk_indices = pd.topk(current_score, k=beam_size)
- # calculate accumulated scores after topk to reduce computation cost
- accu_scores = pd.elementwise_add(
- x=pd.log(topk_scores), y=pd.reshape(pre_score, shape=[-1]), axis=0)
- selected_ids, selected_scores = pd.beam_search(
- pre_ids,
- pre_score,
- topk_indices,
- accu_scores,
- beam_size,
- end_id=10,
- level=0)
-
- with pd.Switch() as switch:
- with switch.case(pd.is_empty(selected_ids)):
- pd.fill_constant(
- shape=[1], value=0, dtype='bool', force_cpu=True, out=cond)
- with switch.default():
- pd.increment(x=counter, value=1, in_place=True)
-
- # update the memories
- pd.array_write(current_state, array=state_array, i=counter)
- pd.array_write(selected_ids, array=ids_array, i=counter)
- pd.array_write(selected_scores, array=scores_array, i=counter)
-
- # update the break condition: up to the max length or all candidates of
- # source sentences have ended.
- length_cond = pd.less_than(x=counter, y=array_len)
- finish_cond = pd.logical_not(pd.is_empty(x=selected_ids))
- pd.logical_and(x=length_cond, y=finish_cond, out=cond)
-
- translation_ids, translation_scores = pd.beam_search_decode(
- ids=ids_array, scores=scores_array, beam_size=beam_size, end_id=10)
-
- return translation_ids, translation_scores
-
-
-def decode_main(use_cuda):
- if use_cuda and not fluid.core.is_compiled_with_cuda():
- return
- place = fluid.CUDAPlace(0) if use_cuda else fluid.CPUPlace()
-
- exe = Executor(place)
- exe.run(framework.default_startup_program())
-
- context = encoder()
- translation_ids, translation_scores = decode(context)
- fluid.io.load_persistables(executor=exe, dirname=model_save_dir)
-
- init_ids_data = np.array([1 for _ in range(batch_size)], dtype='int64')
- init_scores_data = np.array(
- [1. for _ in range(batch_size)], dtype='float32')
- init_ids_data = init_ids_data.reshape((batch_size, 1))
- init_scores_data = init_scores_data.reshape((batch_size, 1))
- init_lod = [1] * batch_size
- init_lod = [init_lod, init_lod]
-
- init_ids = fluid.create_lod_tensor(init_ids_data, init_lod, place)
- init_scores = fluid.create_lod_tensor(init_scores_data, init_lod, place)
-
- test_data = paddle.batch(
- paddle.reader.shuffle(
- paddle.dataset.wmt14.test(dict_size), buf_size=1000),
- batch_size=batch_size)
-
- feed_order = ['src_word_id']
- feed_list = [
- framework.default_main_program().global_block().var(var_name)
- for var_name in feed_order
- ]
- feeder = fluid.DataFeeder(feed_list, place)
-
- src_dict, trg_dict = paddle.dataset.wmt14.get_dict(dict_size)
-
- for data in test_data():
- feed_data = map(lambda x: [x[0]], data)
- feed_dict = feeder.feed(feed_data)
- feed_dict['init_ids'] = init_ids
- feed_dict['init_scores'] = init_scores
-
- results = exe.run(
- framework.default_main_program(),
- feed=feed_dict,
- fetch_list=[translation_ids, translation_scores],
- return_numpy=False)
-
- result_ids = np.array(results[0])
- result_ids_lod = results[0].lod()
- result_scores = np.array(results[1])
-
- print("Original sentence:")
- print(" ".join([src_dict[w] for w in feed_data[0][0][1:-1]]))
- print("Translated score and sentence:")
- for i in xrange(beam_size):
- start_pos = result_ids_lod[1][i] + 1
- end_pos = result_ids_lod[1][i + 1]
- print("%d\t%.4f\t%s\n" % (
- i + 1, result_scores[end_pos - 1],
- " ".join([trg_dict[w] for w in result_ids[start_pos:end_pos]])))
-
- break
-
-
-def main(use_cuda):
- decode_main(False) # Beam Search does not support CUDA
-
-
-if __name__ == '__main__':
- use_cuda = os.getenv('WITH_GPU', '0') != '0'
- main(use_cuda)
diff --git a/08.machine_translation/train.py b/08.machine_translation/train.py
index 589e4dc4a49ab6833ddb3b8946b13d41b1933a21..3d186e3ecb88d18e253ce537249373d84fa6bd98 100644
--- a/08.machine_translation/train.py
+++ b/08.machine_translation/train.py
@@ -12,130 +12,315 @@
# See the License for the specific language governing permissions and
# limitations under the License.
from __future__ import print_function
+import os
+import six
+
+import numpy as np
import paddle
import paddle.fluid as fluid
-import paddle.fluid.layers as pd
-import os
-import sys
-try:
- from paddle.fluid.contrib.trainer import *
- from paddle.fluid.contrib.inferencer import *
-except ImportError:
- print(
- "In the fluid 1.0, the trainer and inferencer are moving to paddle.fluid.contrib",
- file=sys.stderr)
- from paddle.fluid.trainer import *
- from paddle.fluid.inferencer import *
dict_size = 30000
-source_dict_dim = target_dict_dim = dict_size
-hidden_dim = 32
-word_dim = 32
-batch_size = 2
-max_length = 8
-topk_size = 50
-beam_size = 2
+source_dict_size = target_dict_size = dict_size
+word_dim = 512
+hidden_dim = 512
+decoder_size = hidden_dim
+max_length = 256
+beam_size = 4
+batch_size = 64
is_sparse = True
-decoder_size = hidden_dim
model_save_dir = "machine_translation.inference.model"
def encoder():
- src_word_id = pd.data(
+ src_word_id = fluid.layers.data(
name="src_word_id", shape=[1], dtype='int64', lod_level=1)
- src_embedding = pd.embedding(
+ src_embedding = fluid.layers.embedding(
input=src_word_id,
- size=[dict_size, word_dim],
+ size=[source_dict_size, word_dim],
dtype='float32',
- is_sparse=is_sparse,
- param_attr=fluid.ParamAttr(name='vemb'))
+ is_sparse=is_sparse)
+
+ fc_forward = fluid.layers.fc(
+ input=src_embedding, size=hidden_dim * 3, bias_attr=False)
+ src_forward = fluid.layers.dynamic_gru(input=fc_forward, size=hidden_dim)
+ fc_backward = fluid.layers.fc(
+ input=src_embedding, size=hidden_dim * 3, bias_attr=False)
+ src_backward = fluid.layers.dynamic_gru(
+ input=fc_backward, size=hidden_dim, is_reverse=True)
+ encoded_vector = fluid.layers.concat(
+ input=[src_forward, src_backward], axis=1)
+ return encoded_vector
+
- fc1 = pd.fc(input=src_embedding, size=hidden_dim * 4, act='tanh')
- lstm_hidden0, lstm_0 = pd.dynamic_lstm(input=fc1, size=hidden_dim * 4)
- encoder_out = pd.sequence_last_step(input=lstm_hidden0)
- return encoder_out
+def cell(x, hidden, encoder_out, encoder_out_proj):
+ def simple_attention(encoder_vec, encoder_proj, decoder_state):
+ decoder_state_proj = fluid.layers.fc(
+ input=decoder_state, size=decoder_size, bias_attr=False)
+ decoder_state_expand = fluid.layers.sequence_expand(
+ x=decoder_state_proj, y=encoder_proj)
+ mixed_state = fluid.layers.elementwise_add(encoder_proj,
+ decoder_state_expand)
+ attention_weights = fluid.layers.fc(
+ input=mixed_state, size=1, bias_attr=False)
+ attention_weights = fluid.layers.sequence_softmax(
+ input=attention_weights)
+ weigths_reshape = fluid.layers.reshape(x=attention_weights, shape=[-1])
+ scaled = fluid.layers.elementwise_mul(
+ x=encoder_vec, y=weigths_reshape, axis=0)
+ context = fluid.layers.sequence_pool(input=scaled, pool_type='sum')
+ return context
+ context = simple_attention(encoder_out, encoder_out_proj, hidden)
+ out = fluid.layers.fc(
+ input=[x, context], size=decoder_size * 3, bias_attr=False)
+ out = fluid.layers.gru_unit(
+ input=out, hidden=hidden, size=decoder_size * 3)[0]
+ return out, out
-def train_decoder(context):
- trg_language_word = pd.data(
+
+def train_decoder(encoder_out):
+ encoder_last = fluid.layers.sequence_last_step(input=encoder_out)
+ encoder_last_proj = fluid.layers.fc(
+ input=encoder_last, size=decoder_size, act='tanh')
+ # cache the encoder_out's computed result in attention
+ encoder_out_proj = fluid.layers.fc(
+ input=encoder_out, size=decoder_size, bias_attr=False)
+
+ trg_language_word = fluid.layers.data(
name="target_language_word", shape=[1], dtype='int64', lod_level=1)
- trg_embedding = pd.embedding(
+ trg_embedding = fluid.layers.embedding(
input=trg_language_word,
- size=[dict_size, word_dim],
+ size=[target_dict_size, word_dim],
dtype='float32',
- is_sparse=is_sparse,
- param_attr=fluid.ParamAttr(name='vemb'))
+ is_sparse=is_sparse)
- rnn = pd.DynamicRNN()
+ rnn = fluid.layers.DynamicRNN()
with rnn.block():
- current_word = rnn.step_input(trg_embedding)
- pre_state = rnn.memory(init=context, need_reorder=True)
- current_state = pd.fc(
- input=[current_word, pre_state], size=decoder_size, act='tanh')
+ x = rnn.step_input(trg_embedding)
+ pre_state = rnn.memory(init=encoder_last_proj, need_reorder=True)
+ encoder_out = rnn.static_input(encoder_out)
+ encoder_out_proj = rnn.static_input(encoder_out_proj)
+ out, current_state = cell(x, pre_state, encoder_out, encoder_out_proj)
+ prob = fluid.layers.fc(input=out, size=target_dict_size, act='softmax')
- current_score = pd.fc(
- input=current_state, size=target_dict_dim, act='softmax')
rnn.update_memory(pre_state, current_state)
- rnn.output(current_score)
+ rnn.output(prob)
return rnn()
-def train_program():
- context = encoder()
- rnn_out = train_decoder(context)
- label = pd.data(
+def train_model():
+ encoder_out = encoder()
+ rnn_out = train_decoder(encoder_out)
+ label = fluid.layers.data(
name="target_language_next_word", shape=[1], dtype='int64', lod_level=1)
- cost = pd.cross_entropy(input=rnn_out, label=label)
- avg_cost = pd.mean(cost)
+ cost = fluid.layers.cross_entropy(input=rnn_out, label=label)
+ avg_cost = fluid.layers.mean(cost)
return avg_cost
def optimizer_func():
- return fluid.optimizer.Adagrad(
- learning_rate=1e-4,
+ fluid.clip.set_gradient_clip(
+ clip=fluid.clip.GradientClipByGlobalNorm(clip_norm=5.0))
+ lr_decay = fluid.layers.learning_rate_scheduler.noam_decay(hidden_dim, 1000)
+ return fluid.optimizer.Adam(
+ learning_rate=lr_decay,
regularization=fluid.regularizer.L2DecayRegularizer(
- regularization_coeff=0.1))
+ regularization_coeff=1e-4))
def train(use_cuda):
- EPOCH_NUM = 1
+ train_prog = fluid.Program()
+ startup_prog = fluid.Program()
+ with fluid.program_guard(train_prog, startup_prog):
+ with fluid.unique_name.guard():
+ avg_cost = train_model()
+ optimizer = optimizer_func()
+ optimizer.minimize(avg_cost)
- if use_cuda and not fluid.core.is_compiled_with_cuda():
- return
place = fluid.CUDAPlace(0) if use_cuda else fluid.CPUPlace()
+ exe = fluid.Executor(place)
- train_reader = paddle.batch(
+ train_data = paddle.batch(
paddle.reader.shuffle(
- paddle.dataset.wmt14.train(dict_size), buf_size=1000),
+ paddle.dataset.wmt16.train(source_dict_size, target_dict_size),
+ buf_size=10000),
batch_size=batch_size)
- feed_order = [
- 'src_word_id', 'target_language_word', 'target_language_next_word'
- ]
+ feeder = fluid.DataFeeder(
+ feed_list=[
+ 'src_word_id', 'target_language_word', 'target_language_next_word'
+ ],
+ place=place,
+ program=train_prog)
+
+ exe.run(startup_prog)
+
+ EPOCH_NUM = 20
+ for pass_id in six.moves.xrange(EPOCH_NUM):
+ batch_id = 0
+ for data in train_data():
+ cost = exe.run(
+ train_prog, feed=feeder.feed(data), fetch_list=[avg_cost])[0]
+ print('pass_id: %d, batch_id: %d, loss: %f' % (pass_id, batch_id,
+ cost))
+ batch_id += 1
+ fluid.io.save_params(exe, model_save_dir, main_program=train_prog)
+
+
+def infer_decoder(encoder_out):
+ encoder_last = fluid.layers.sequence_last_step(input=encoder_out)
+ encoder_last_proj = fluid.layers.fc(
+ input=encoder_last, size=decoder_size, act='tanh')
+ encoder_out_proj = fluid.layers.fc(
+ input=encoder_out, size=decoder_size, bias_attr=False)
+
+ max_len = fluid.layers.fill_constant(
+ shape=[1], dtype='int64', value=max_length)
+ counter = fluid.layers.zeros(shape=[1], dtype='int64', force_cpu=True)
- def event_handler(event):
- if isinstance(event, EndStepEvent):
- if event.step % 10 == 0:
- print('pass_id=' + str(event.epoch) + ' batch=' + str(
- event.step))
+ init_ids = fluid.layers.data(
+ name="init_ids", shape=[1], dtype="int64", lod_level=2)
+ init_scores = fluid.layers.data(
+ name="init_scores", shape=[1], dtype="float32", lod_level=2)
+ # create and init arrays to save selected ids, scores and states for each step
+ ids_array = fluid.layers.array_write(init_ids, i=counter)
+ scores_array = fluid.layers.array_write(init_scores, i=counter)
+ state_array = fluid.layers.array_write(encoder_last_proj, i=counter)
- if isinstance(event, EndEpochEvent):
- trainer.save_params(model_save_dir)
+ cond = fluid.layers.less_than(x=counter, y=max_len)
+ while_op = fluid.layers.While(cond=cond)
+ with while_op.block():
+ pre_ids = fluid.layers.array_read(array=ids_array, i=counter)
+ pre_score = fluid.layers.array_read(array=scores_array, i=counter)
+ pre_state = fluid.layers.array_read(array=state_array, i=counter)
+
+ pre_ids_emb = fluid.layers.embedding(
+ input=pre_ids,
+ size=[target_dict_size, word_dim],
+ dtype='float32',
+ is_sparse=is_sparse)
+ out, current_state = cell(pre_ids_emb, pre_state, encoder_out,
+ encoder_out_proj)
+ prob = fluid.layers.fc(
+ input=current_state, size=target_dict_size, act='softmax')
+
+ # beam search
+ topk_scores, topk_indices = fluid.layers.topk(prob, k=beam_size)
+ accu_scores = fluid.layers.elementwise_add(
+ x=fluid.layers.log(topk_scores),
+ y=fluid.layers.reshape(pre_score, shape=[-1]),
+ axis=0)
+ accu_scores = fluid.layers.lod_reset(x=accu_scores, y=pre_ids)
+ selected_ids, selected_scores = fluid.layers.beam_search(
+ pre_ids, pre_score, topk_indices, accu_scores, beam_size, end_id=1)
+
+ fluid.layers.increment(x=counter, value=1, in_place=True)
+ # save selected ids and corresponding scores of each step
+ fluid.layers.array_write(selected_ids, array=ids_array, i=counter)
+ fluid.layers.array_write(selected_scores, array=scores_array, i=counter)
+ # update rnn state by sequence_expand acting as gather
+ current_state = fluid.layers.sequence_expand(current_state,
+ selected_ids)
+ fluid.layers.array_write(current_state, array=state_array, i=counter)
+ current_enc_out = fluid.layers.sequence_expand(encoder_out,
+ selected_ids)
+ fluid.layers.assign(current_enc_out, encoder_out)
+ current_enc_out_proj = fluid.layers.sequence_expand(encoder_out_proj,
+ selected_ids)
+ fluid.layers.assign(current_enc_out_proj, encoder_out_proj)
+
+ # update conditional variable
+ length_cond = fluid.layers.less_than(x=counter, y=max_len)
+ finish_cond = fluid.layers.logical_not(
+ fluid.layers.is_empty(x=selected_ids))
+ fluid.layers.logical_and(x=length_cond, y=finish_cond, out=cond)
+
+ translation_ids, translation_scores = fluid.layers.beam_search_decode(
+ ids=ids_array, scores=scores_array, beam_size=beam_size, end_id=1)
+
+ return translation_ids, translation_scores
+
+
+def infer_model():
+ encoder_out = encoder()
+ translation_ids, translation_scores = infer_decoder(encoder_out)
+ return translation_ids, translation_scores
+
+
+def infer(use_cuda):
+ infer_prog = fluid.Program()
+ startup_prog = fluid.Program()
+ with fluid.program_guard(infer_prog, startup_prog):
+ with fluid.unique_name.guard():
+ translation_ids, translation_scores = infer_model()
+
+ place = fluid.CUDAPlace(0) if use_cuda else fluid.CPUPlace()
+ exe = fluid.Executor(place)
+
+ test_data = paddle.batch(
+ paddle.dataset.wmt16.test(source_dict_size, target_dict_size),
+ batch_size=batch_size)
+ src_idx2word = paddle.dataset.wmt16.get_dict(
+ "en", source_dict_size, reverse=True)
+ trg_idx2word = paddle.dataset.wmt16.get_dict(
+ "de", target_dict_size, reverse=True)
- trainer = Trainer(
- train_func=train_program, place=place, optimizer_func=optimizer_func)
+ fluid.io.load_params(exe, model_save_dir, main_program=infer_prog)
- trainer.train(
- reader=train_reader,
- num_epochs=EPOCH_NUM,
- event_handler=event_handler,
- feed_order=feed_order)
+ for data in test_data():
+ src_word_id = fluid.create_lod_tensor(
+ data=map(lambda x: x[0], data),
+ recursive_seq_lens=[[len(x[0]) for x in data]],
+ place=place)
+ init_ids = fluid.create_lod_tensor(
+ data=np.array([[0]] * len(data), dtype='int64'),
+ recursive_seq_lens=[[1] * len(data)] * 2,
+ place=place)
+ init_scores = fluid.create_lod_tensor(
+ data=np.array([[0.]] * len(data), dtype='float32'),
+ recursive_seq_lens=[[1] * len(data)] * 2,
+ place=place)
+ seq_ids, seq_scores = exe.run(
+ infer_prog,
+ feed={
+ 'src_word_id': src_word_id,
+ 'init_ids': init_ids,
+ 'init_scores': init_scores
+ },
+ fetch_list=[translation_ids, translation_scores],
+ return_numpy=False)
+ # How to parse the results:
+ # Suppose the lod of seq_ids is:
+ # [[0, 3, 6], [0, 12, 24, 40, 54, 67, 82]]
+ # then from lod[0]:
+ # there are 2 source sentences, beam width is 3.
+ # from lod[1]:
+ # the first source sentence has 3 hyps; the lengths are 12, 12, 16
+ # the second source sentence has 3 hyps; the lengths are 14, 13, 15
+ hyps = [[] for i in range(len(seq_ids.lod()[0]) - 1)]
+ scores = [[] for i in range(len(seq_scores.lod()[0]) - 1)]
+ for i in range(len(seq_ids.lod()[0]) - 1): # for each source sentence
+ start = seq_ids.lod()[0][i]
+ end = seq_ids.lod()[0][i + 1]
+ print("Original sentence:")
+ print(" ".join([src_idx2word[idx] for idx in data[i][0][1:-1]]))
+ print("Translated score and sentence:")
+ for j in range(end - start): # for each candidate
+ sub_start = seq_ids.lod()[1][start + j]
+ sub_end = seq_ids.lod()[1][start + j + 1]
+ hyps[i].append(" ".join([
+ trg_idx2word[idx]
+ for idx in np.array(seq_ids)[sub_start:sub_end][1:-1]
+ ]))
+ scores[i].append(np.array(seq_scores)[sub_end - 1])
+ print(scores[i][-1], hyps[i][-1].encode('utf8'))
def main(use_cuda):
train(use_cuda)
+ infer(use_cuda)
if __name__ == '__main__':