add doc
Showing
doc/DEPLOY.md
0 → 100644
doc/deploy/.DS_Store
0 → 100755
文件已添加
doc/deploy/cluster-info.png
0 → 100755
{kind=link}

98.2 KB
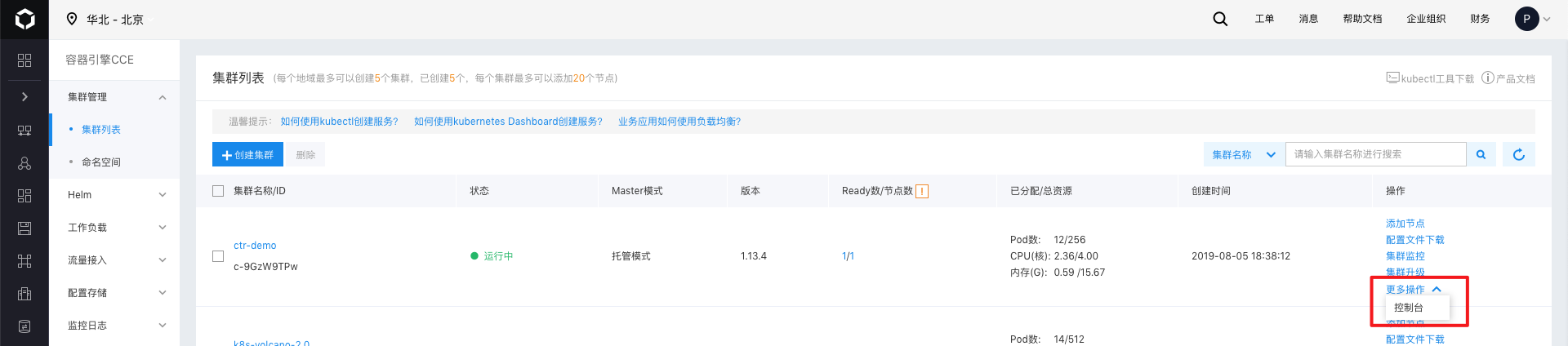
doc/deploy/concole.png
0 → 100755
{kind=link}
109.7 KB
doc/deploy/conf-download.png
0 → 100755
{kind=link}

70.9 KB
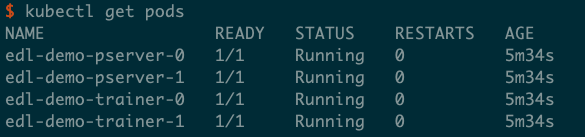
doc/deploy/ctr-running.png
0 → 100755
{kind=link}
26.1 KB
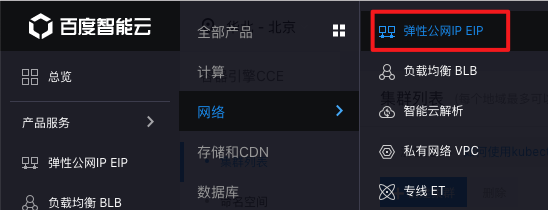
doc/deploy/eip.png
0 → 100755
{kind=link}
39.1 KB
doc/deploy/helm-version.png
0 → 100755
{kind=link}

24.7 KB
doc/deploy/kubectl-version.png
0 → 100755
{kind=link}

45.3 KB
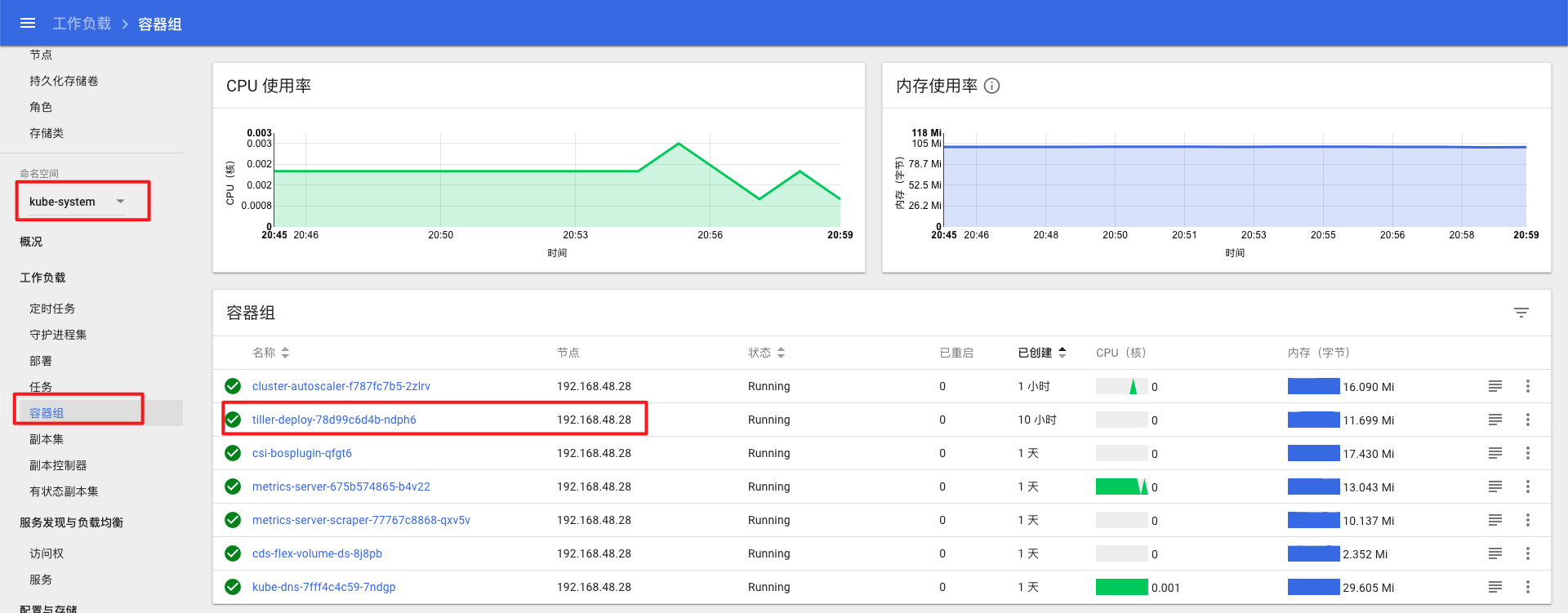
doc/deploy/tiller.png
0 → 100755
{kind=link}
163.6 KB
doc/deploy/trainer-log.png
0 → 100755
{kind=link}
138.9 KB
doc/deploy/volcano.png
0 → 100755
{kind=link}

33.9 KB
doc/deploy/workload.png
0 → 100755
{kind=link}
125.1 KB