Merge from github
Showing
cmake/cuda.cmake
0 → 100644
{kind=link}

30.0 KB
{kind=link}

38.5 KB
{kind=link}

31.0 KB
{kind=link}

20.1 KB
{kind=link}

33.8 KB
{kind=link}

63.1 KB
{kind=link}

43.8 KB
{kind=link}

26.7 KB
{kind=link}

29.7 KB
{kind=link}

18.4 KB
demo-client/data/images/val.txt
0 → 100644
demo-client/src/ximage_press.cpp
0 → 100644
doc/client-side-proxy.png
0 → 100755
{kind=link}
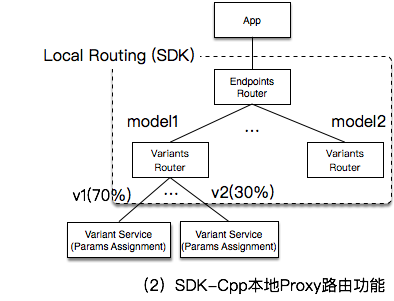
19.8 KB
doc/framework.png
0 → 100755
{kind=link}
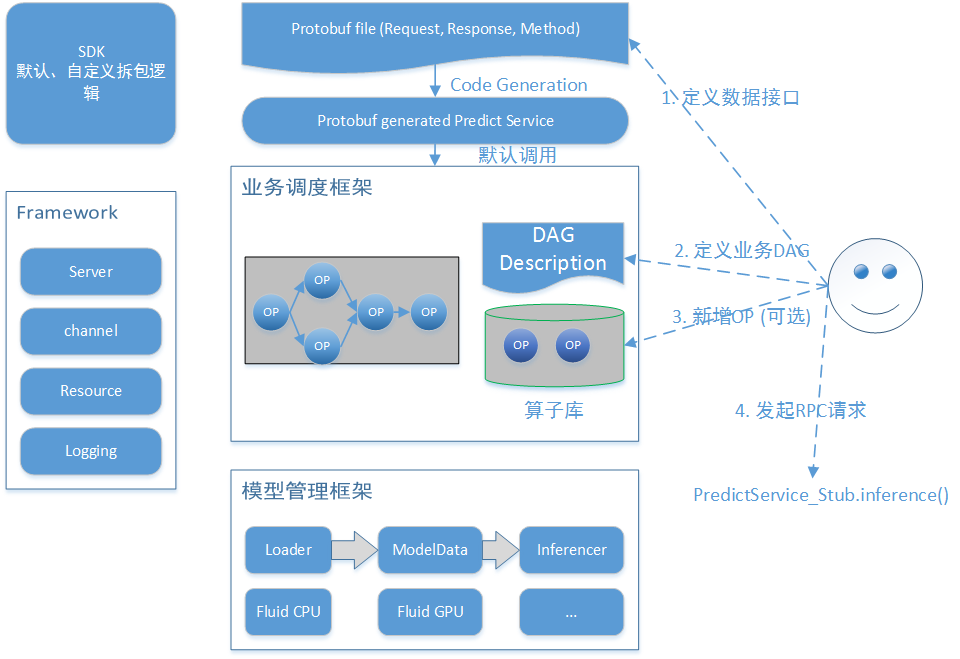
75.0 KB
doc/multi-service.png
0 → 100755
{kind=link}

18.3 KB
doc/multi-variants.png
0 → 100755
{kind=link}
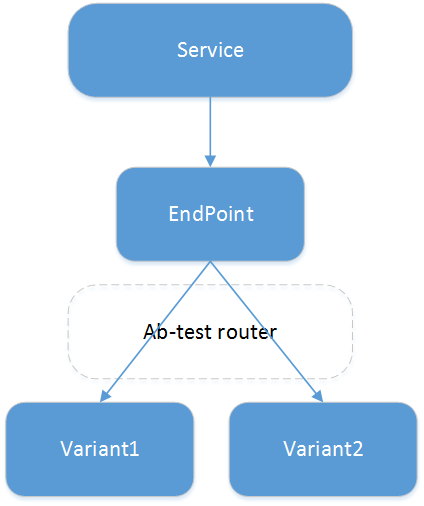
17.9 KB
doc/predict-service.png
0 → 100755
{kind=link}
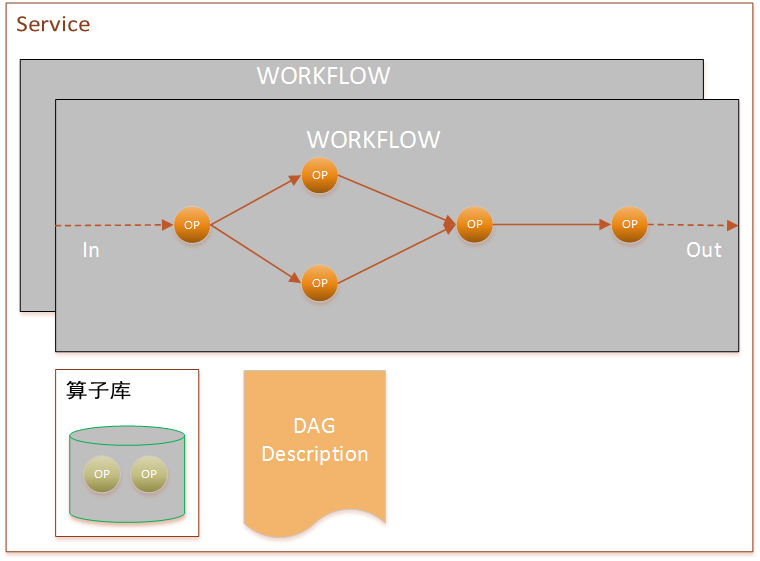
30.8 KB
doc/server-side.png
0 → 100755
{kind=link}

32.0 KB