Merge pull request #192 from joey12300/doc
reconstruct deploy doc
Showing
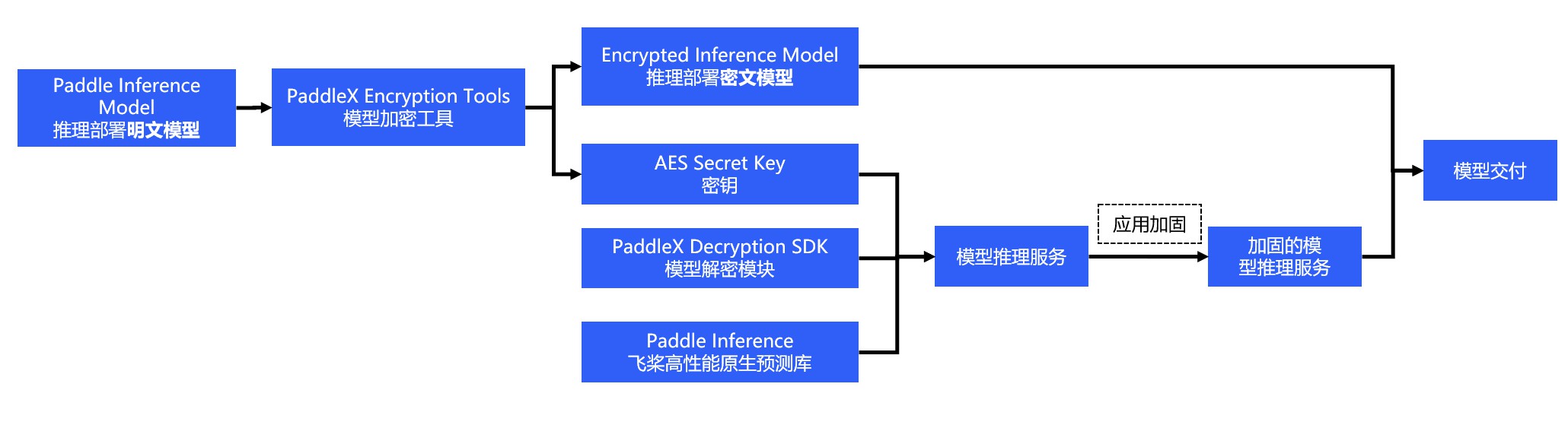
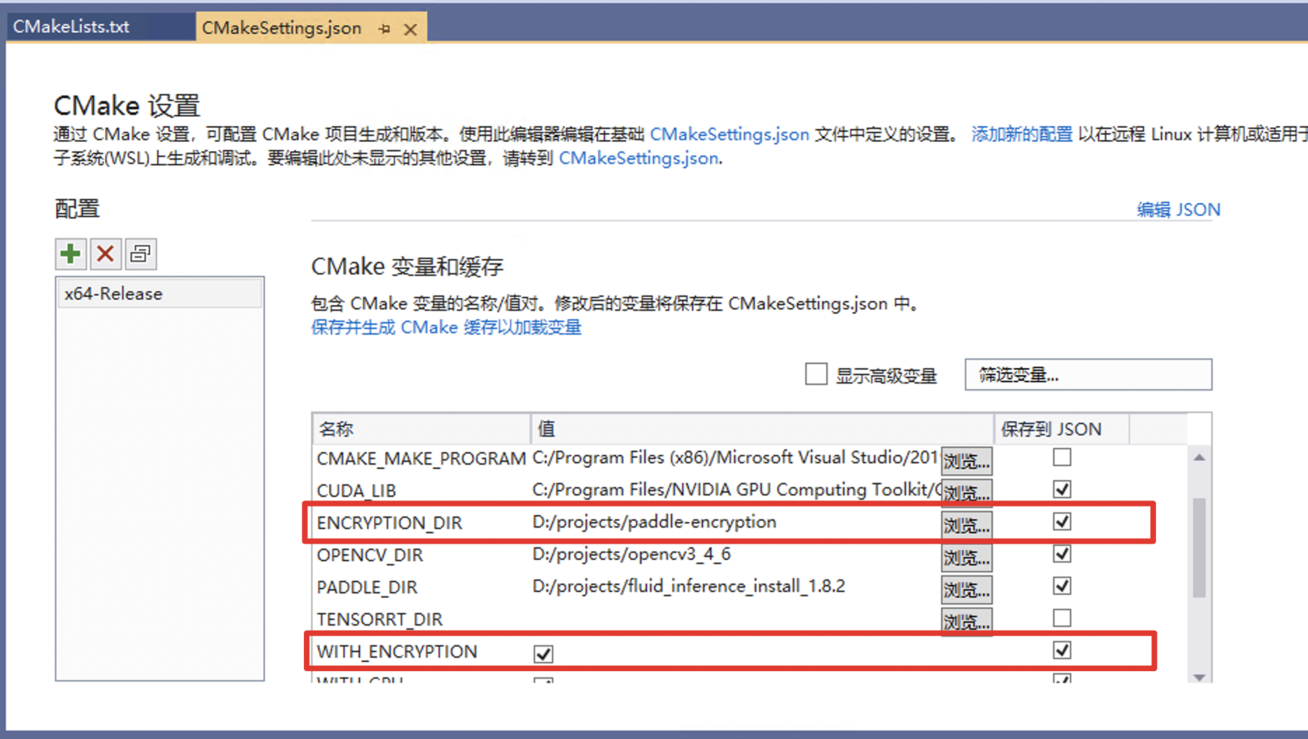
docs/deploy/images/encrypt.png
0 → 100644
{kind=link}

46.0 KB
{kind=link}
113.7 KB
{kind=link}
75.3 KB
{kind=link}
84.3 KB
{kind=link}
381.3 KB
{kind=link}
294.1 KB
{kind=link}
215.3 KB
{kind=link}
427.5 KB
{kind=link}
83.3 KB
{kind=link}
397.9 KB
docs/deploy/server/encryption.md
0 → 100644
docs/deploy/upgrade_version.md
0 → 100644