Merge branch 'develop' of https://github.com/PaddlePaddle/PaddleX into develop_qh
Showing
docs/paddlex_gui/images/QR.jpg
0 → 100644
{kind=link}

56.3 KB
docs/paddlex_gui/images/ReadMe
0 → 100644
{kind=link}

258.2 KB
{kind=link}
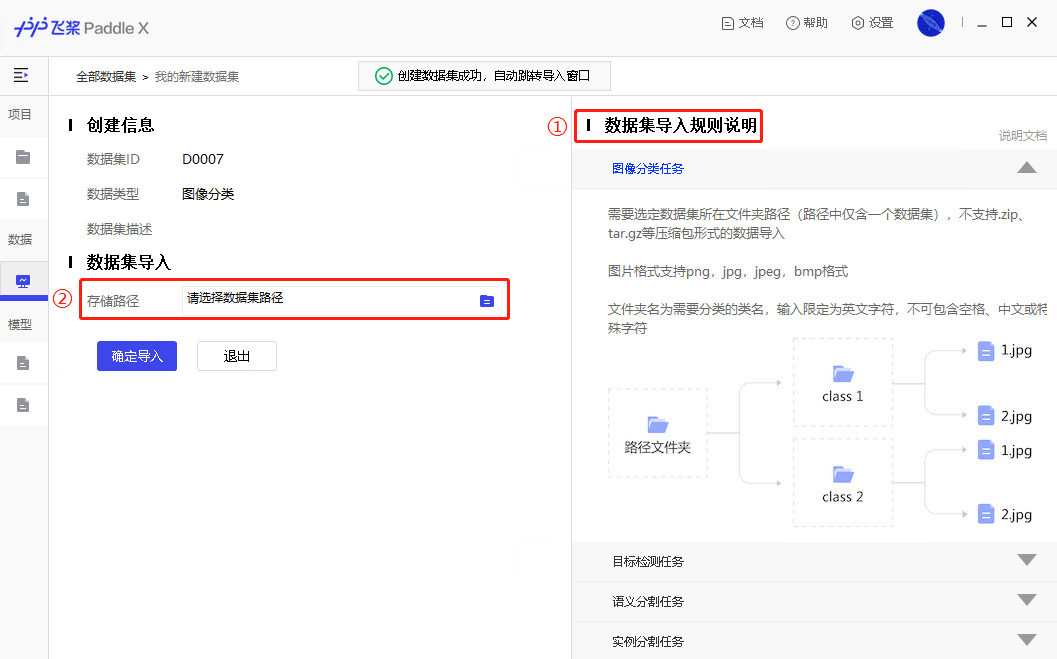
73.3 KB
{kind=link}

37.0 KB
{kind=link}

54.0 KB
{kind=link}

102.4 KB
{kind=link}

41.3 KB
{kind=link}

38.5 KB
{kind=link}

34.0 KB
{kind=link}

36.4 KB
{kind=link}

54.7 KB
{kind=link}
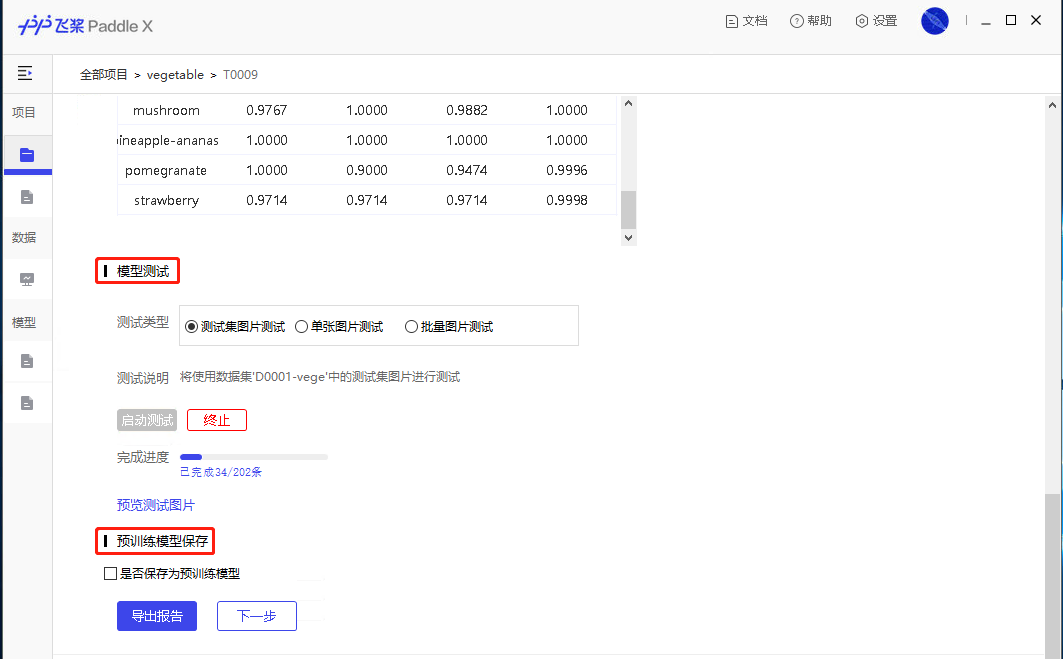
47.3 KB
new_tutorials/train/README.md
0 → 100644