fix conflict
Showing
docs/anaconda_install.md
0 → 100644
.png){kind=link}
.png)
711.2 KB
.png){kind=link}
.png)
315.9 KB
.png){kind=link}
.png)
316.4 KB
docs/client_use.md
0 → 100644
docs/images/00_loaddata.png
0 → 100644
{kind=link}
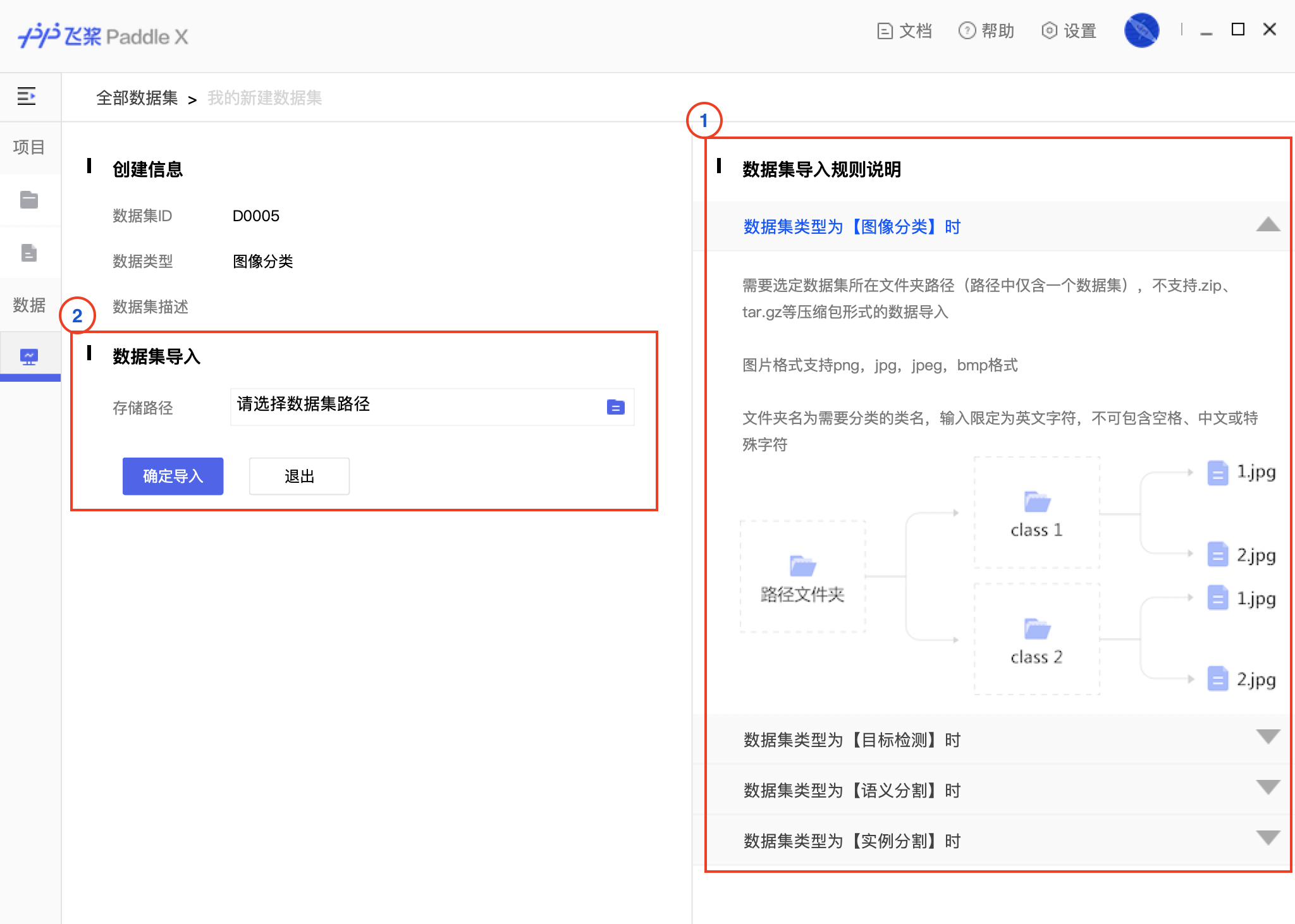
456.5 KB
docs/images/01_datasplit.png
0 → 100644
{kind=link}
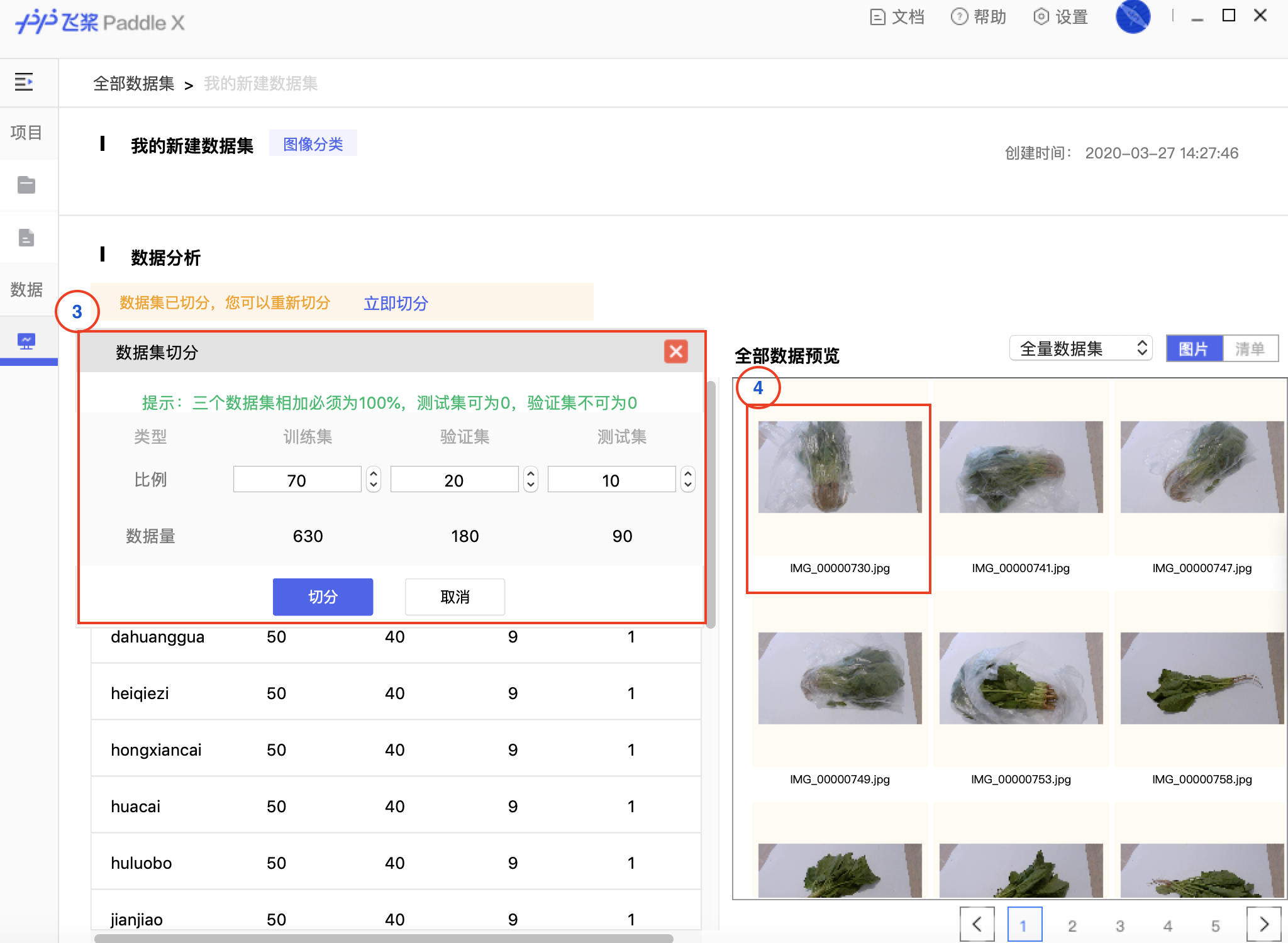
898.1 KB
docs/images/02_newproject.png
0 → 100644
{kind=link}
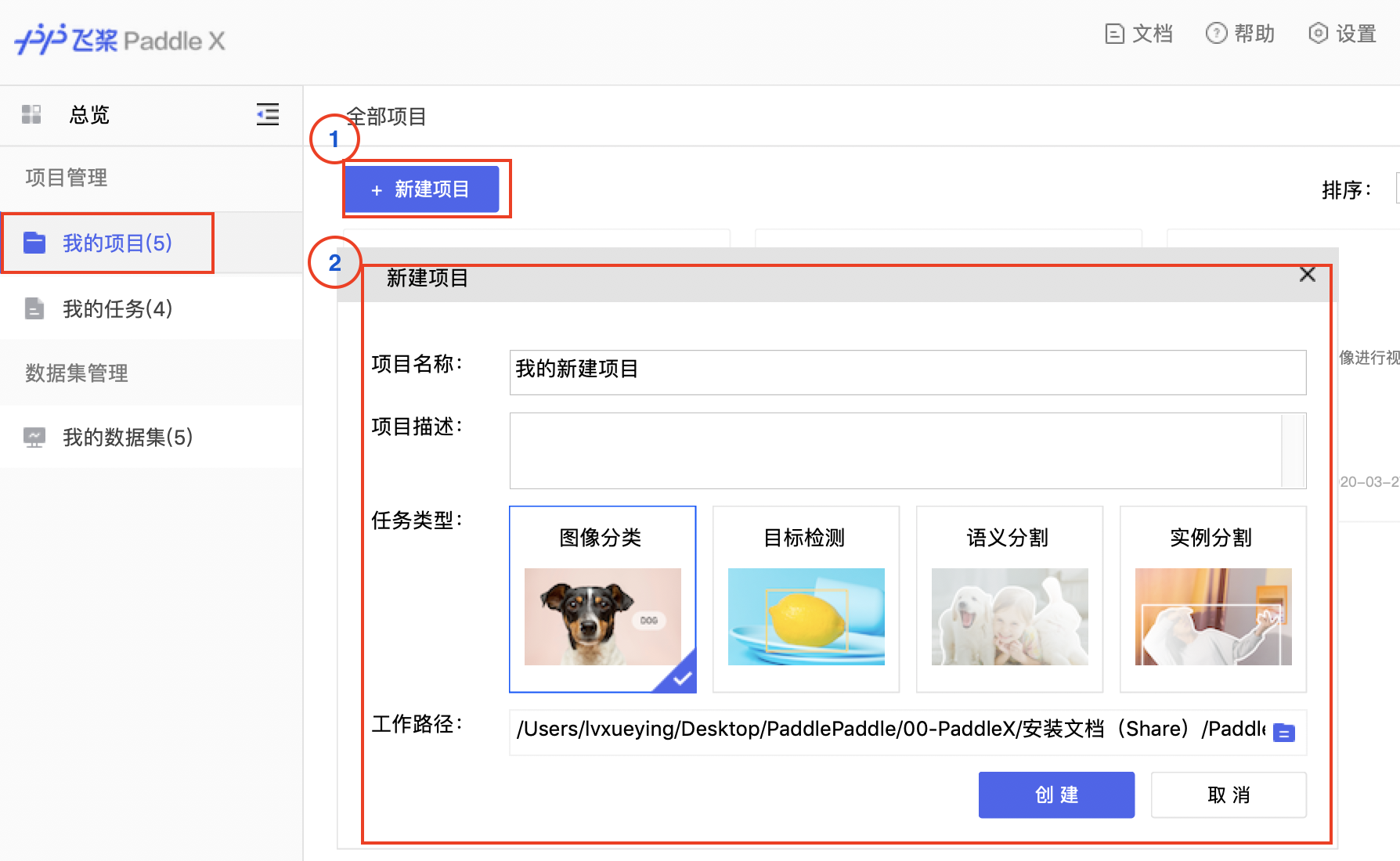
423.2 KB
docs/images/03_choosedata.png
0 → 100644
{kind=link}
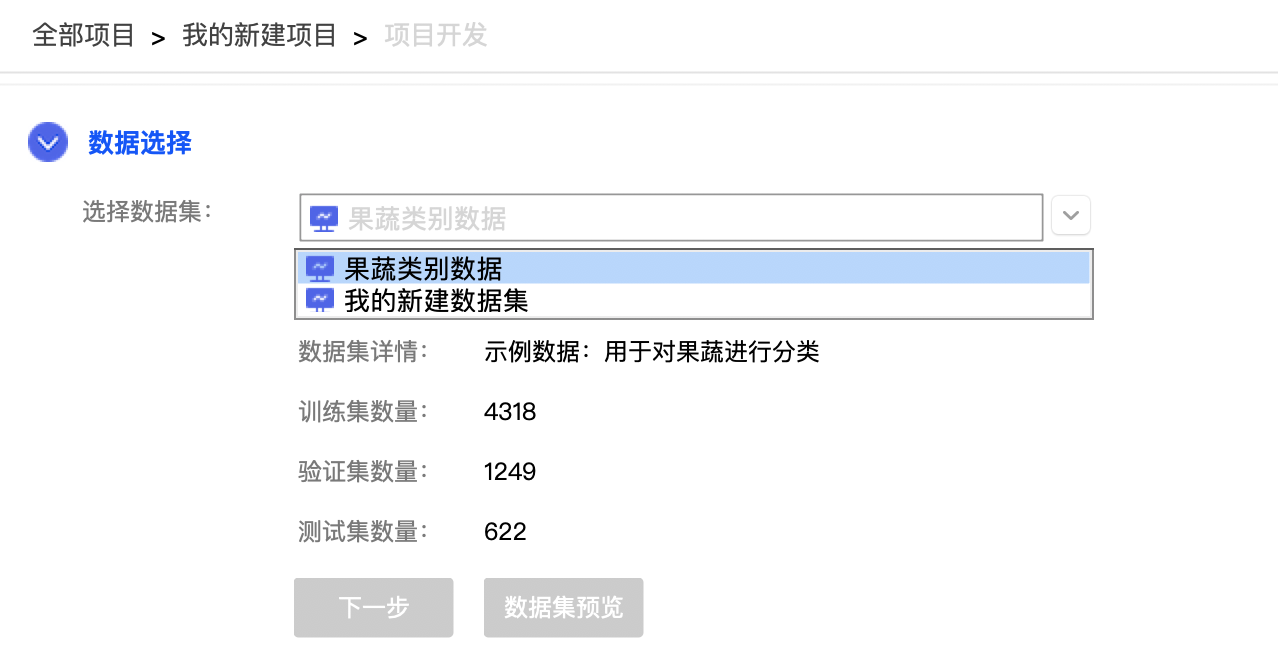
108.7 KB
docs/images/04_parameter.png
0 → 100644
{kind=link}
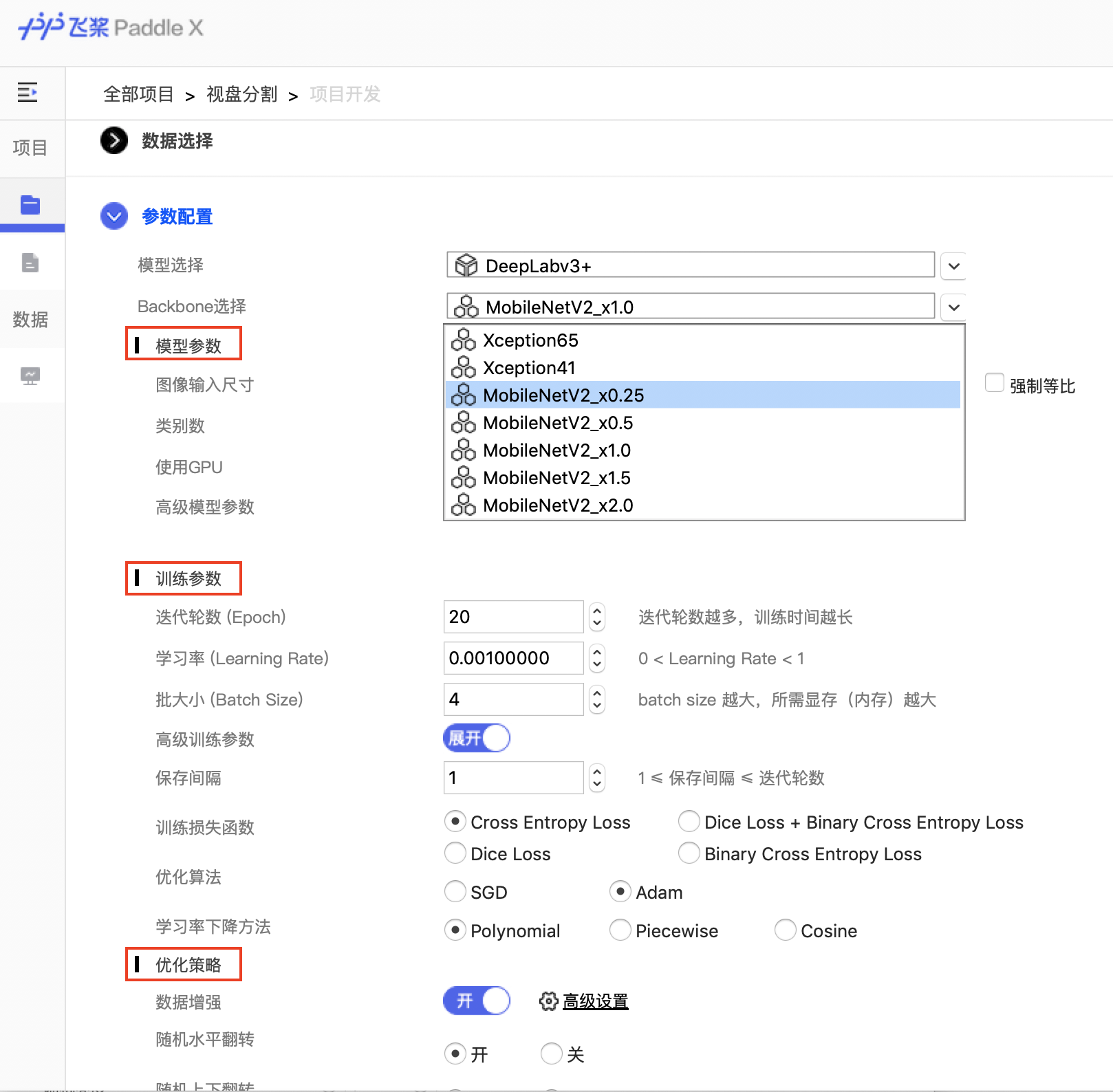
392.2 KB
docs/images/05_train.png
0 → 100644
{kind=link}
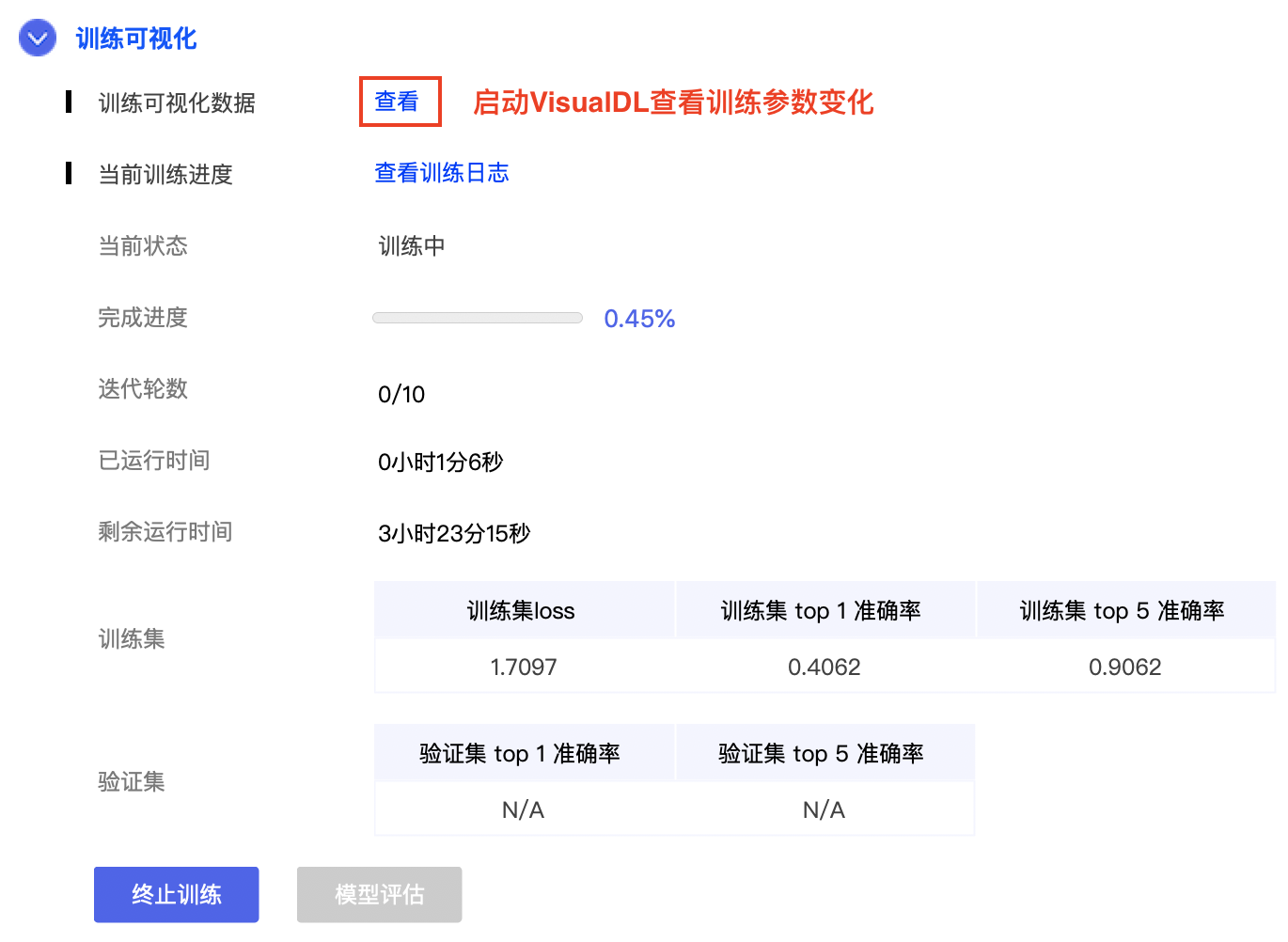
174.0 KB
docs/images/06_VisualDL.png
0 → 100644
{kind=link}
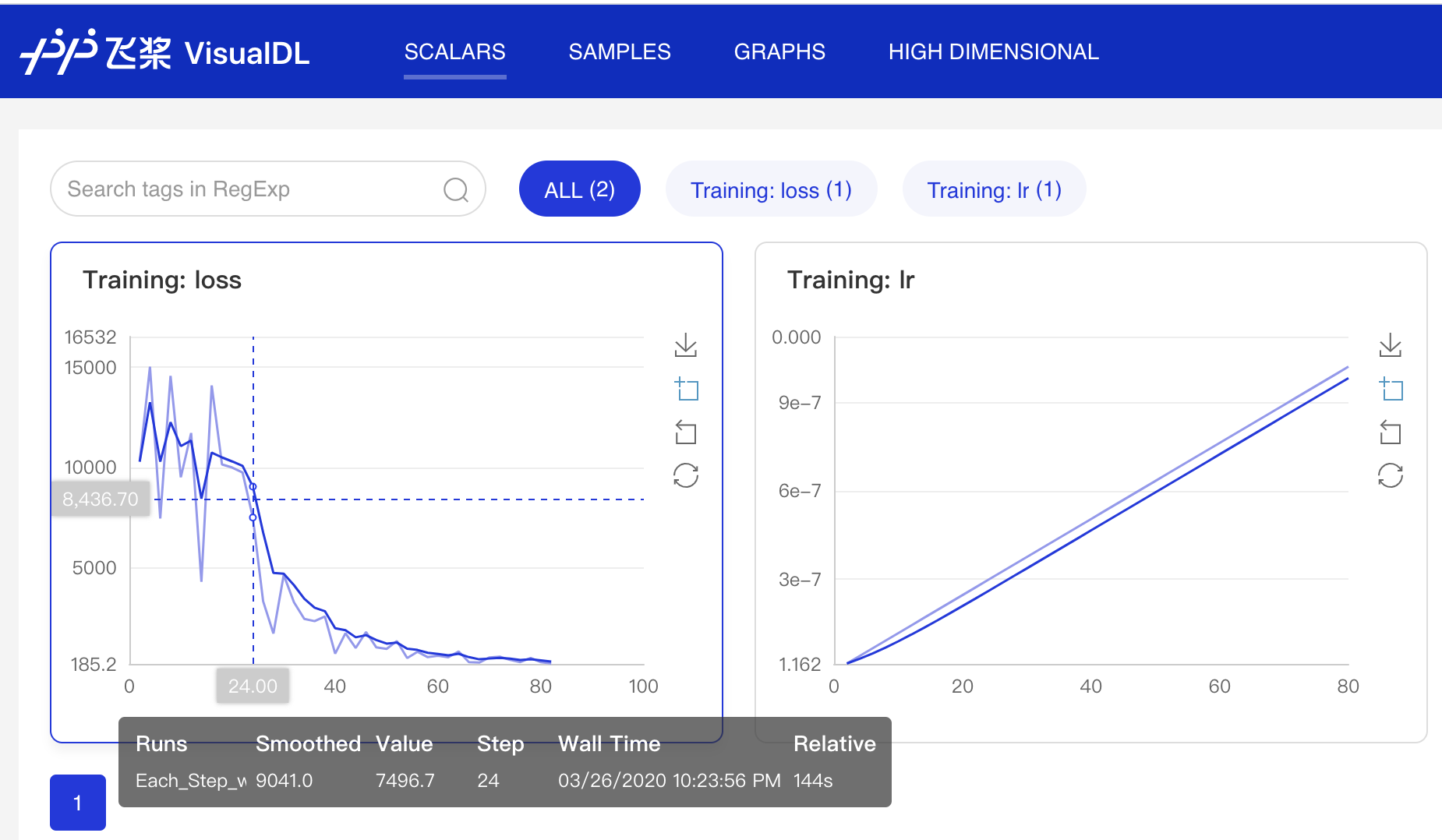
196.3 KB
docs/images/07_evaluate.png
0 → 100644
{kind=link}
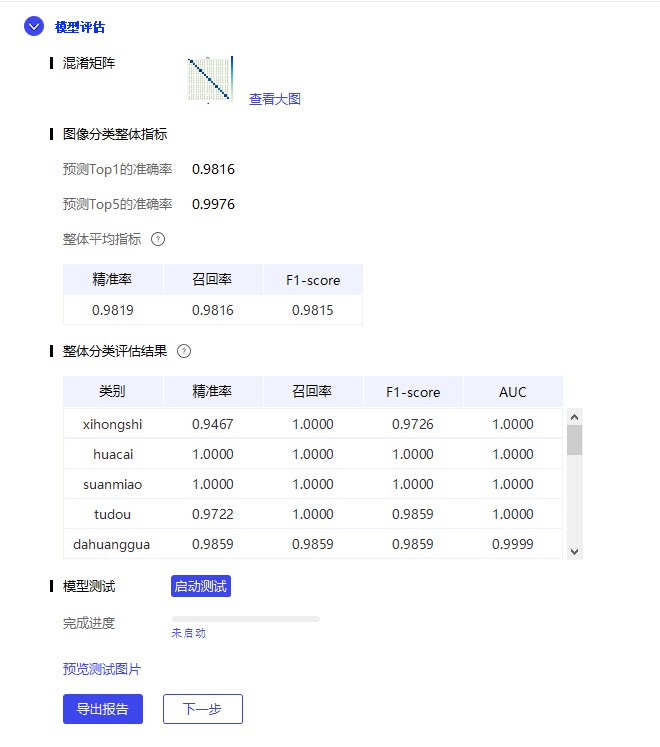
59.7 KB
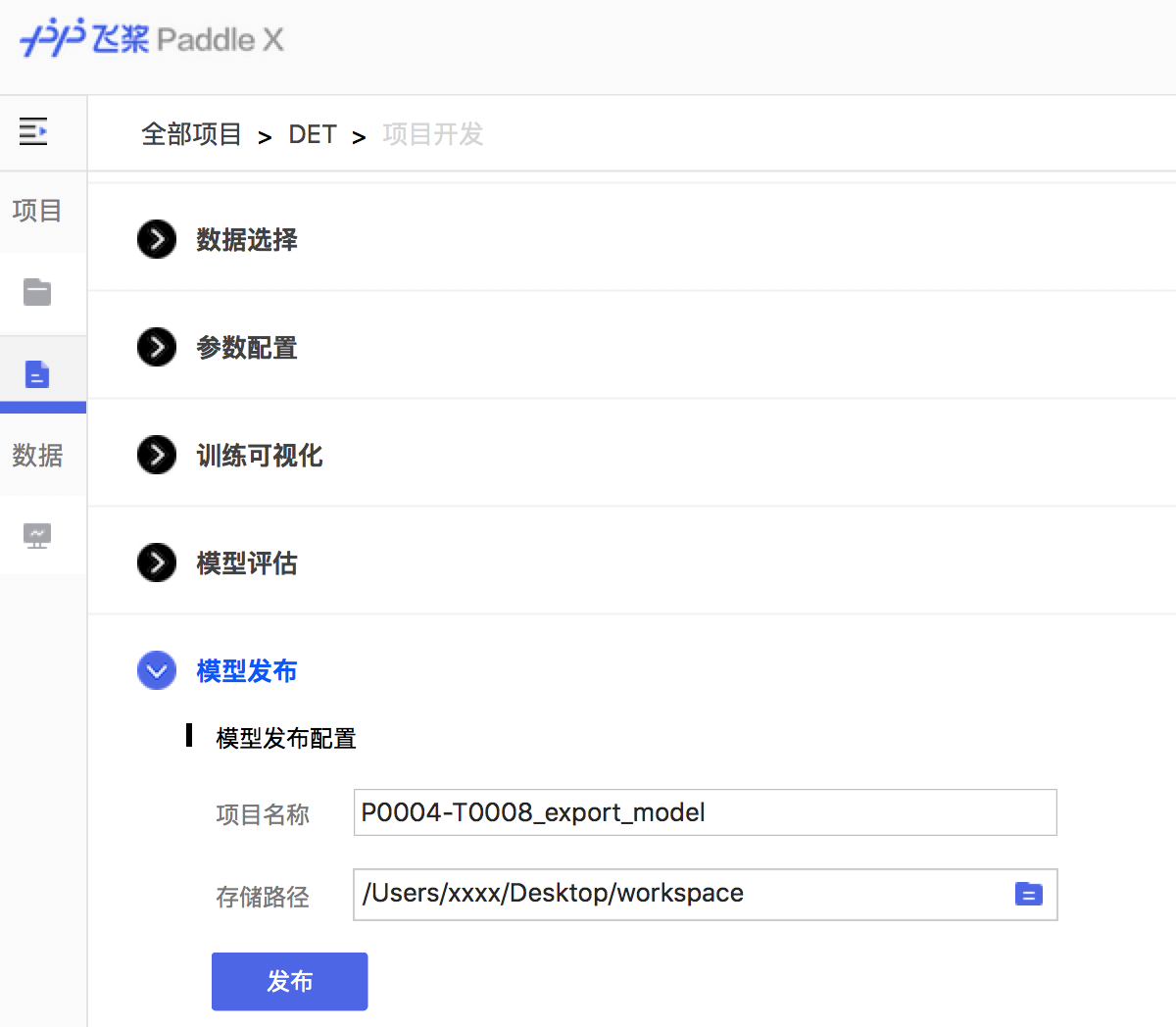
docs/images/08_deploy.png
0 → 100644
{kind=link}
194.1 KB
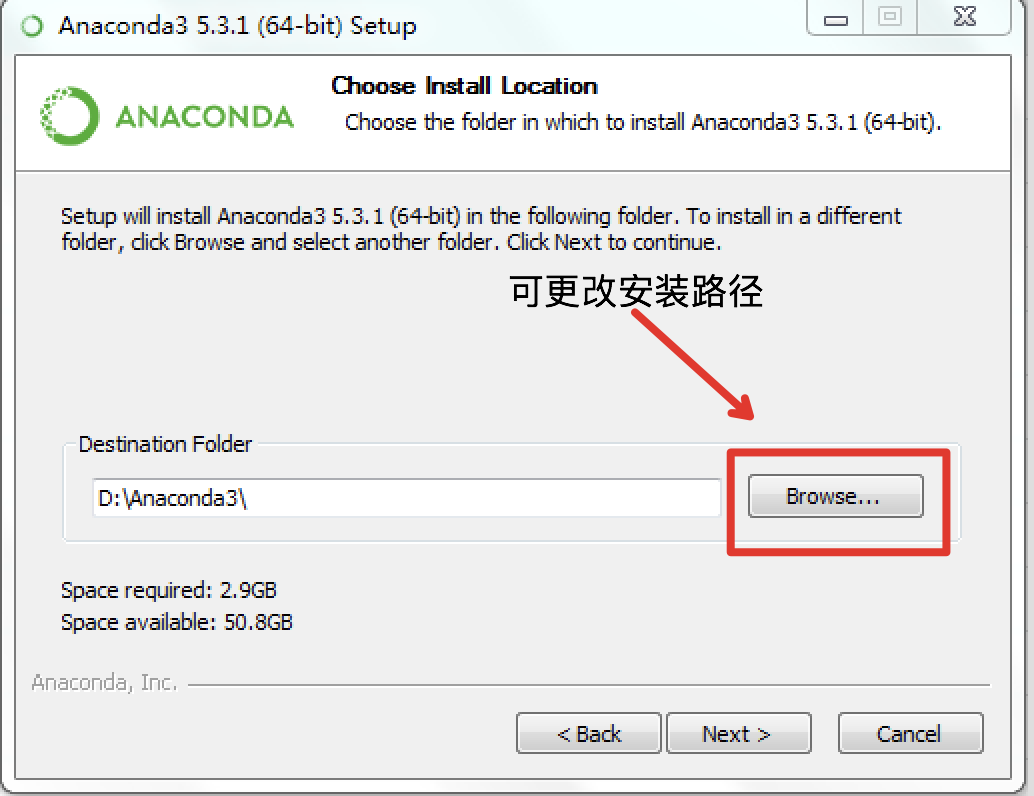
docs/images/anaconda_windows.png
0 → 100644
{kind=link}
74.6 KB
| ... | @@ -6,3 +6,4 @@ cython | ... | @@ -6,3 +6,4 @@ cython |
| pycocotools | pycocotools | ||
| visualdl=1.3.0 | visualdl=1.3.0 | ||
| paddleslim=1.0.1 | paddleslim=1.0.1 | ||
| shapely |