Skip to content
体验新版
项目
组织
正在加载...
登录
切换导航
打开侧边栏
PaddlePaddle
PaddleX
提交
38d983fa
P
PaddleX
项目概览
PaddlePaddle
/
PaddleX
通知
138
Star
4
Fork
0
代码
文件
提交
分支
Tags
贡献者
分支图
Diff
Issue
43
列表
看板
标记
里程碑
合并请求
5
Wiki
0
Wiki
分析
仓库
DevOps
项目成员
Pages
P
PaddleX
项目概览
项目概览
详情
发布
仓库
仓库
文件
提交
分支
标签
贡献者
分支图
比较
Issue
43
Issue
43
列表
看板
标记
里程碑
合并请求
5
合并请求
5
Pages
分析
分析
仓库分析
DevOps
Wiki
0
Wiki
成员
成员
收起侧边栏
关闭侧边栏
动态
分支图
创建新Issue
提交
Issue看板
未验证
提交
38d983fa
编写于
7月 12, 2020
作者:
J
Jason
提交者:
GitHub
7月 12, 2020
浏览文件
操作
浏览文件
下载
差异文件
Merge pull request #209 from Channingss/doc_clc
add lite&slim Doc
上级
cde62366
6d6a0df1
变更
6
隐藏空白更改
内联
并排
Showing
6 changed file
with
264 addition
and
2 deletion
+264
-2
docs/deploy/images/paddlex_android_sdk_framework.jpg
docs/deploy/images/paddlex_android_sdk_framework.jpg
+0
-0
docs/deploy/paddlelite/android.md
docs/deploy/paddlelite/android.md
+196
-0
docs/deploy/paddlelite/slim/index.rst
docs/deploy/paddlelite/slim/index.rst
+2
-1
docs/deploy/paddlelite/slim/prune.md
docs/deploy/paddlelite/slim/prune.md
+54
-0
docs/deploy/paddlelite/slim/quant.md
docs/deploy/paddlelite/slim/quant.md
+11
-0
docs/deploy/upgrade_version.md
docs/deploy/upgrade_version.md
+1
-1
未找到文件。
docs/deploy/images/paddlex_android_sdk_framework.jpg
0 → 100644
浏览文件 @
38d983fa
266.4 KB
docs/deploy/paddlelite/android.md
浏览文件 @
38d983fa
# Android平台
PaddleX的安卓端部署由PaddleLite实现,部署的流程如下,首先将训练好的模型导出为inference model,然后对模型进行优化,最后使用PaddleLite的预测库进行部署,PaddleLite的详细介绍和使用可参考:
[
PaddleLite文档
](
https://paddle-lite.readthedocs.io/zh/latest/
)
> PaddleX --> Inference Model --> PaddleLite Opt --> PaddleLite Inference
文章简介:
-
step1: 介绍如何将PaddleX导出为inference model
-
step2: 使用PaddleLite的OPT模块对模型进行优化
-
step3: 介绍了基于MobileNetv2的安卓demo,以及PaddleX Android SDK
## step 1. 将PaddleX模型导出为inference模型
参考
[
导出inference模型
](
../export_model.html
)
将模型导出为inference格式模型。
**注意:由于PaddleX代码的持续更新,版本低于1.0.0的模型暂时无法直接用于预测部署,参考[模型版本升级](../upgrade_version.md)对模型版本进行升级。**
## step 2. 将inference模型优化为PaddleLite模型
目前提供了两种方法将Paddle模型优化为PaddleLite模型:
-
1.python脚本优化模型,简单上手,目前支持最新的PaddleLite 2.6.1版本
-
2.bin文件优化模型(linux),支持develop版本(Commit Id:11cbd50e),适用于部署
`DeepLab模型`
的用户。
### 2.1 使用python脚本优化模型
```
bash
pip
install
paddlelite
python /PaddleX/deploy/lite/export_lite.py
--model_dir
/path/to/inference_model
--save_file
/path/to/lite_model_name
--place
place/to/run
```
| 参数 | 说明 |
| ---- | ---- |
| --model_dir | 预测模型所在路径,包含"
\_\_
model
\_\_
", "
\_\_
params
\_\_
", "model.yml"文件 |
| --save_file | 模型输出的名称,假设为/path/to/lite_model_name, 则输出为路径为/path/to/lite_model_name.nb |
| --place | 运行的平台,可选:arm
\|
opencl
\|
x86
\|
npu
\|
xpu
\|
rknpu
\|
apu,安卓部署请选择
`arm`
|
### 2.3 使用bin文件优化模型(linux)
首先下载并解压:
[
模型优化工具opt
](
https://bj.bcebos.com/paddlex/deploy/lite/model_optimize_tool_11cbd50e.tar.gz
)
```
bash
./opt
--model_file
=
<model_path>
\
--param_file
=
<param_path>
\
--valid_targets
=
arm
\
--optimize_out_type
=
naive_buffer
\
--optimize_out
=
model_output_name
```
详细的使用方法和参数含义请参考:
[
使用opt转化模型
](
https://paddle-lite.readthedocs.io/zh/latest/user_guides/opt/opt_bin.html
)
## step 3. 移动端(Android)预测
### 3.1 要求
-
Android Studio 3.4
-
Android手机或开发板
### 3.2 分类Demo
#### 3.2.1 导入工程
-
打开Android Studio,在"Welcome to Android Studio"窗口点击"Open an existing Android Studio project",在弹出的路径选择窗口中进入
`/PaddleX/deploy/lite/android/demo`
目录,然后点击右下角的"Open"按钮,导入工程;
-
通过USB连接Android手机或开发板;
-
载入工程后,点击菜单栏的Run->Run 'App'按钮,在弹出的"Select Deployment Target"窗口选择已经连接的Android设备,然后点击"OK"按钮;
#### 3.2.2 自定义模型
首先根据step1~step2描述,准备好Lite模型(.nb文件)和yml配置文件(注意:导出Lite模型时需指定--place=arm),然后在Android Studio的project视图中:
-
将paddlex.nb文件拷贝到
`/src/main/assets/model/`
目录下。
-
将model.yml文件拷贝到
`/src/main/assets/config/`
目录下。
-
根据需要,修改文件
`/src/main/res/values/strings.xml`
中的
`MODEL_PATH_DEFAULT`
和
`YAML_PATH_DEFAULT`
指定的路径。
### 3.3 PaddleX Android SDK介绍
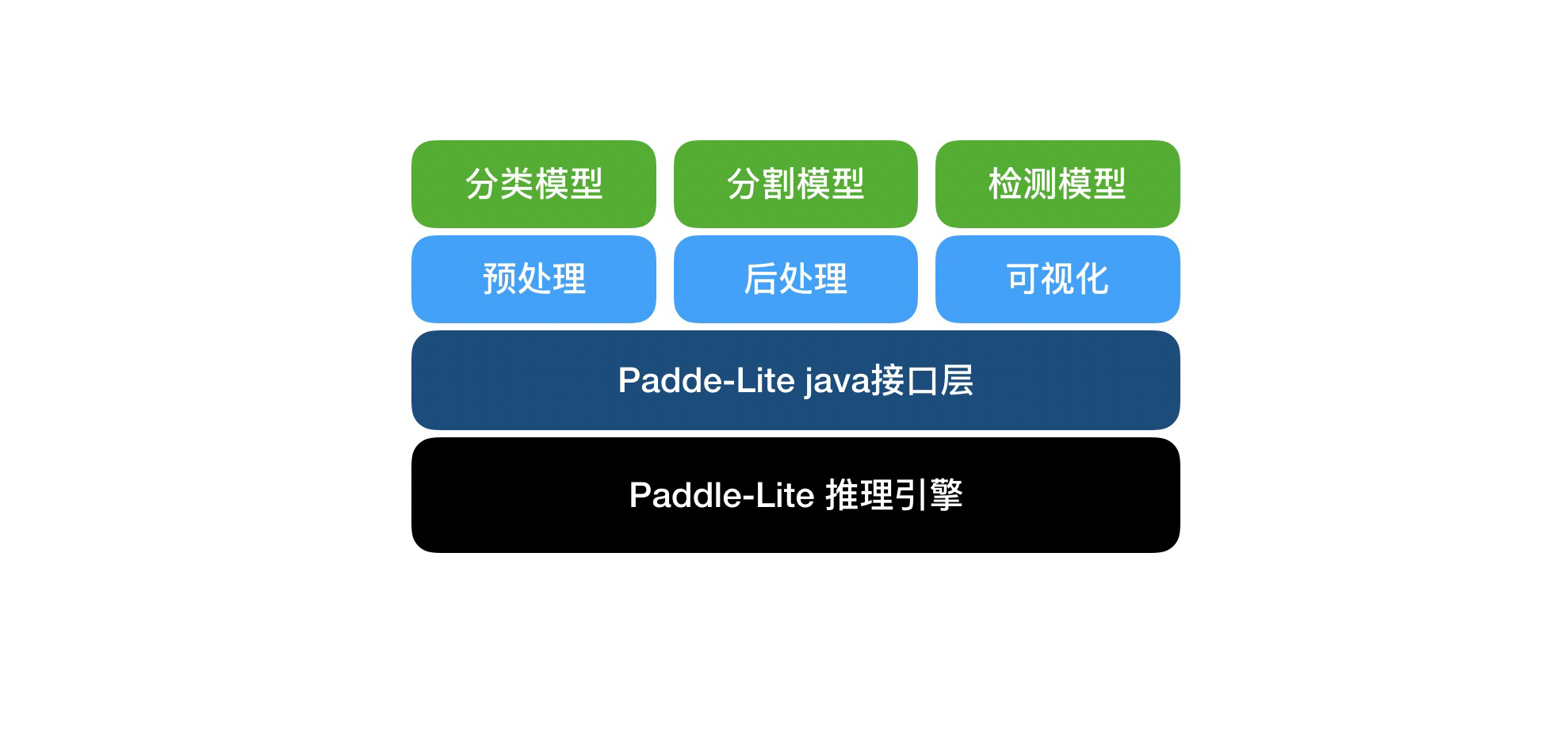
PaddleX Android SDK是PaddleX基于Paddle-Lite开发的安卓端AI推理工具,以PaddleX导出的Yaml配置文件为接口,针对不同的模型实现图片的预处理,后处理,并进行可视化,开发者可集成到业务中。
该SDK自底向上主要包括:Paddle-Lite推理引擎层,Paddle-Lite接口层以及PaddleX业务层。
-
Paddle-Lite推理引擎层,是在Android上编译好的二进制包,只涉及到Kernel 的执行,且可以单独部署,以支持极致的轻量级部署。
-
Paddle-Lite接口层,以Java接口封装了底层c++推理库。
-
PaddleX业务层,封装了PaddleX导出模型的预处理,推理和后处理,以及可视化,支持PaddleX导出的检测、分割、分类模型。

#### 3.3.1 SDK安装
首先下载并解压
[
PaddleX Android SDK
](
https://bj.bcebos.com/paddlex/deploy/lite/paddlex_lite_11cbd50e.tar.gz
)
,得到paddlex.aar文件,将拷贝到android工程目录app/libs/下面,然后为app的build.gradle添加依赖:
```
dependencies {
implementation fileTree(include: ['*.jar','*aar'], dir: 'libs')
}
```
#### 3.3.2 SDK使用用例
```
import com.baidu.paddlex.Predictor;
import com.baidu.paddlex.config.ConfigParser;
import com.baidu.paddlex.postprocess.DetResult;
import com.baidu.paddlex.postprocess.SegResult;
import com.baidu.paddlex.postprocess.ClsResult;
import com.baidu.paddlex.visual.Visualize;
// Predictor
Predictor predictor = new Predictor();
// model config
ConfigParser configParser = new ConfigParser();
// Visualize
Visualize visualize = new Visualize();
// image to predict
Mat predictMat;
// initialize
configParser.init(context, model_path, yaml_path, cpu_thread_num, cpu_power_mode);
visualize.init(configParser.getNumClasses());
predictor.init(context, configParser)
// run model
if (predictImage != null && predictor.isLoaded()) {
predictor.setInputMat(predictMat);
runModel();
}
// get result & visualize
if (configParser.getModelType().equalsIgnoreCase("segmenter")) {
SegResult segResult = predictor.getSegResult();
Mat visualizeMat = visualize.draw(segResult, predictMat, predictor.getImageBlob());
} else if (configParser.getModelType().equalsIgnoreCase("detector")) {
DetResult detResult = predictor.getDetResult();
Mat visualizeMat = visualize.draw(detResult, predictMat);
} else if (configParser.getModelType().equalsIgnoreCase("classifier")) {
ClsResult clsResult = predictor.getClsResult();
}
```
#### 3.3.3 Result成员变量
**注意**
:Result所有的成员变量以java bean的方式获取。
```
java
com
.
baidu
.
paddlex
.
postprocess
.
ClsResult
```
##### Fields
> * **type** (String|static): 值为"cls"。
> * **categoryId** (int): 类别ID。
> * **category** (String): 类别名称。
> * **score** (float): 预测置信度。
```
java
com
.
baidu
.
paddlex
.
postprocess
.
DetResult
```
##### Nested classes
> * **DetResult.Box** 模型预测的box结果。
##### Fields
> * **type** (String|static): 值为"det"。
> * **boxes** (List<DetResult.Box>): 模型预测的box结果。
```
java
com
.
baidu
.
paddlex
.
postprocess
.
DetResult
.
Box
```
##### Fields
> * **categoryId** (int): 类别ID。
> * **category** (String): 类别名称。
> * **score** (float): 预测置信度。
> * **coordinate** (float[4]): 预测框值:{xmin, ymin, xmax, ymax}。
```
java
com
.
baidu
.
paddlex
.
postprocess
.
SegResult
```
##### Nested classes
> * **SegResult.Mask**: 模型预测的mask结果。
##### Fields
> * **type** (String|static): 值为"Seg"。
> * **mask** (SegResult.Mask): 模型预测的mask结果。
```
java
com
.
baidu
.
paddlex
.
postprocess
.
SegResult
.
Mask
```
##### Fields
> * **scoreData** (float[]): 模型预测在各个类别的置信度,长度为numClass$\times\$H$\times\$W
> * **scoreShape** (long[4]): scoreData的shape信息,[1,numClass,H,W]
> * **labelData** (long[]): 模型预测置信度最高的label,长度为`H$\times\$W$\times\$1
> * **labelShape** (long[4]): labelData的shape信息,[1,H,W,1]
#### 3.3.4 SDK二次开发
-
打开Android Studio新建项目(或加载已有项目)。点击菜单File->New->Import Module,导入工程
`/PaddleX/deploy/lite/android/sdk`
, Project视图会新增名为sdk的module
-
在app的build.grade里面添加依赖:
```
dependencies {
implementation project(':sdk')
}
```
-
源代码位于sdk/main/java/下,修改源码进行二次开发后,点击菜单栏的Build->Run 'sdk'按钮可编译生成aar,文件位于sdk/build/outputs/aar/路径下。
docs/deploy/paddlelite/slim/index.rst
浏览文件 @
38d983fa
...
...
@@ -6,5 +6,6 @@
:maxdepth: 2
:caption: 文档目录:
prune.md
quant.md
prune.md
tutorials/index
docs/deploy/paddlelite/slim/prune.md
浏览文件 @
38d983fa
# 模型裁剪
为了更好地满足端侧部署场景下,低内存带宽、低功耗、低计算资源占用以及低模型存储等需求,PaddleX通过集成PaddleSlim实现
`模型裁剪`
,可提升PaddleLite端侧部署性能。
## 原理介绍
模型裁剪通过裁剪卷积层中Kernel输出通道的大小及其关联层参数大小,来减小模型大小和降低模型计算复杂度,可以加快模型部署后的预测速度,其关联裁剪的原理可参见
[
PaddleSlim相关文档
](
https://paddlepaddle.github.io/PaddleSlim/algo/algo.html#id16
)
。
**一般而言,在同等模型精度前提下,数据复杂度越低,模型可以被裁剪的比例就越高**
。
## 裁剪方法
PaddleX提供了两种方式:
**1.用户自行计算裁剪配置(推荐),整体流程包含三个步骤,**
> **第一步**: 使用数据集训练原始模型
> **第二步**:利用第一步训练好的模型,在验证数据集上计算模型中各个参数的敏感度,并将敏感度信息存储至本地文件
> **第三步**:使用数据集训练裁剪模型(与第一步差异在于需要在`train`接口中,将第二步计算得到的敏感信息文件传给接口的`sensitivities_file`参数)
> 在如上三个步骤中,**相当于模型共需要训练两遍**,分别对应第一步和第三步,但其中第三步训练的是裁剪后的模型,因此训练速度较第一步会更快。
> 第二步会遍历模型中的部分裁剪参数,分别计算各个参数裁剪后对于模型在验证集上效果的影响,**因此会反复在验证集上评估多次**。
**2.使用PaddleX内置的裁剪方案**
> PaddleX内置的模型裁剪方案是**基于标准数据集**上计算得到的参数敏感度信息,由于不同数据集特征分布会有较大差异,所以该方案相较于第1种方案训练得到的模型**精度一般而言会更低**(**且用户自定义数据集与标准数据集特征分布差异越大,导致训练的模型精度会越低**),仅在用户想节省时间的前提下可以参考使用,使用方式只需一步,
> **一步**: 使用数据集训练裁剪模型,在训练调用`train`接口时,将接口中的`sensitivities_file`参数设置为'DEFAULT'字符串
> 注:各模型内置的裁剪方案分别依据的数据集为: 图像分类——ImageNet数据集、目标检测——PascalVOC数据集、语义分割——CityScape数据集
## 裁剪实验
基于上述两种方案,我们在PaddleX上使用样例数据进行了实验,在Tesla P40上实验指标如下所示:
### 图像分类
实验背景:使用MobileNetV2模型,数据集为蔬菜分类示例数据,使用方法见
[
使用教程-模型压缩-图像分类
](
./tutorials/classification.html
)
| 模型 | 裁剪情况 | 模型大小 | Top1准确率(%) |GPU预测速度 | CPU预测速度 |
| :-----| :--------| :-------- | :---------- |:---------- |:----------|
|MobileNetV2 | 无裁剪(原模型)| 13.0M | 97.50|6.47ms |47.44ms |
|MobileNetV2 | 方案一(eval_metric_loss=0.10) | 2.1M | 99.58 |5.03ms |20.22ms |
|MobileNetV2 | 方案二(eval_metric_loss=0.10) | 6.0M | 99.58 |5.42ms |29.06ms |
### 目标检测
实验背景:使用YOLOv3-MobileNetV1模型,数据集为昆虫检测示例数据,使用方法见
[
使用教程-模型压缩-目标检测
](
./tutorials/detection.html
)
| 模型 | 裁剪情况 | 模型大小 | MAP(%) |GPU预测速度 | CPU预测速度 |
| :-----| :--------| :-------- | :---------- |:---------- | :---------|
|YOLOv3-MobileNetV1 | 无裁剪(原模型)| 139M | 67.57| 14.88ms |976.42ms |
|YOLOv3-MobileNetV1 | 方案一(eval_metric_loss=0.10) | 34M | 75.49 |10.60ms |558.49ms |
|YOLOv3-MobileNetV1 | 方案二(eval_metric_loss=0.05) | 29M | 50.27| 9.43ms |360.46ms |
### 语义分割
实验背景:使用UNet模型,数据集为视盘分割示例数据,使用方法见
[
使用教程-模型压缩-语义分割
](
./tutorials/segmentation.html
)
| 模型 | 裁剪情况 | 模型大小 | mIOU(%) |GPU预测速度 | CPU预测速度 |
| :-----| :--------| :-------- | :---------- |:---------- | :---------|
|UNet | 无裁剪(原模型)| 77M | 91.22 |33.28ms |9523.55ms |
|UNet | 方案一(eval_metric_loss=0.10) |26M | 90.37 |21.04ms |3936.20ms |
|UNet | 方案二(eval_metric_loss=0.10) |23M | 91.21 |18.61ms |3447.75ms |
docs/deploy/paddlelite/slim/quant.md
浏览文件 @
38d983fa
# 模型量化
为了更好地满足端侧部署场景下,低内存带宽、低功耗、低计算资源占用以及低模型存储等需求,PaddleX通过集成PaddleSlim实现
`模型量化`
,可提升PaddleLite端侧部署性能。
## 原理介绍
定点量化使用更少的比特数(如8-bit、3-bit、2-bit等)表示神经网络的权重和激活值,从而加速模型推理速度。PaddleX提供了训练后量化技术,其原理可参见
[
训练后量化原理
](
https://paddlepaddle.github.io/PaddleSlim/algo/algo.html#id14
)
,该量化使用KL散度确定量化比例因子,将FP32模型转成INT8模型,且不需要重新训练,可以快速得到量化模型。
## 使用PaddleX量化模型
PaddleX提供了
`export_quant_model`
接口,让用户以接口的形式完成模型以post_quantization方式量化并导出。点击查看
[
量化接口使用文档
](
../../../apis/slim.html
)
。
## 量化性能对比
模型量化后的性能对比指标请查阅
[
PaddleSlim模型库
](
https://paddlepaddle.github.io/PaddleSlim/model_zoo.html
)
docs/deploy/upgrade_version.md
浏览文件 @
38d983fa
...
...
@@ -9,6 +9,6 @@
## 版本转换
```
paddlex --export_inference --model_dir=/path/to/low_version_model --save_dir=
SS
path/to/high_version_model
paddlex --export_inference --model_dir=/path/to/low_version_model --save_dir=
/
path/to/high_version_model
```
`--model_dir`
为版本号小于1.0.0的模型路径,可以是PaddleX训练过程保存的模型,也可以是导出为inference格式的模型。
`--save_dir`
为转换为高版本的模型,后续可用于多端部署。
编辑
预览
Markdown
is supported
0%
请重试
或
添加新附件
.
添加附件
取消
You are about to add
0
people
to the discussion. Proceed with caution.
先完成此消息的编辑!
取消
想要评论请
注册
或
登录
{kind=link}