Skip to content
体验新版
项目
组织
正在加载...
登录
切换导航
打开侧边栏
PaddlePaddle
PaddleX
提交
6d6a0df1
P
PaddleX
项目概览
PaddlePaddle
/
PaddleX
通知
138
Star
4
Fork
0
代码
文件
提交
分支
Tags
贡献者
分支图
Diff
Issue
43
列表
看板
标记
里程碑
合并请求
5
Wiki
0
Wiki
分析
仓库
DevOps
项目成员
Pages
P
PaddleX
项目概览
项目概览
详情
发布
仓库
仓库
文件
提交
分支
标签
贡献者
分支图
比较
Issue
43
Issue
43
列表
看板
标记
里程碑
合并请求
5
合并请求
5
Pages
分析
分析
仓库分析
DevOps
Wiki
0
Wiki
成员
成员
收起侧边栏
关闭侧边栏
动态
分支图
创建新Issue
提交
Issue看板
提交
6d6a0df1
编写于
7月 11, 2020
作者:
C
Channingss
浏览文件
操作
浏览文件
下载
电子邮件补丁
差异文件
updata doc
上级
cc2c5fdb
变更
5
隐藏空白更改
内联
并排
Showing
5 changed file
with
8 addition
and
7 deletion
+8
-7
docs/deploy/images/paddlex_android_sdk_framework.jpg
docs/deploy/images/paddlex_android_sdk_framework.jpg
+0
-0
docs/deploy/paddlelite/android.md
docs/deploy/paddlelite/android.md
+2
-2
docs/deploy/paddlelite/slim/index.rst
docs/deploy/paddlelite/slim/index.rst
+1
-0
docs/deploy/paddlelite/slim/prune.md
docs/deploy/paddlelite/slim/prune.md
+4
-4
docs/deploy/paddlelite/slim/quant.md
docs/deploy/paddlelite/slim/quant.md
+1
-1
未找到文件。
docs/deploy/images/paddlex_android_sdk_framework.jpg
查看替换文件 @
cc2c5fdb
浏览文件 @
6d6a0df1
85.2 KB
|
W:
|
H:
266.4 KB
|
W:
|
H:
2-up
Swipe
Onion skin
docs/deploy/paddlelite/android.md
浏览文件 @
6d6a0df1
...
...
@@ -12,7 +12,7 @@ PaddleX的安卓端部署由PaddleLite实现,部署的流程如下,首先将
## step 1. 将PaddleX模型导出为inference模型
参考
[
导出inference模型
](
../export_model.html
)
将模型导出为inference格式模型。
**注意:由于PaddleX代码的持续更新,版本低于1.0.0的模型暂时无法直接用于预测部署,参考[模型版本升级](./upgrade_version.md)对模型版本进行升级。**
**注意:由于PaddleX代码的持续更新,版本低于1.0.0的模型暂时无法直接用于预测部署,参考[模型版本升级](.
.
/upgrade_version.md)对模型版本进行升级。**
## step 2. 将inference模型优化为PaddleLite模型
...
...
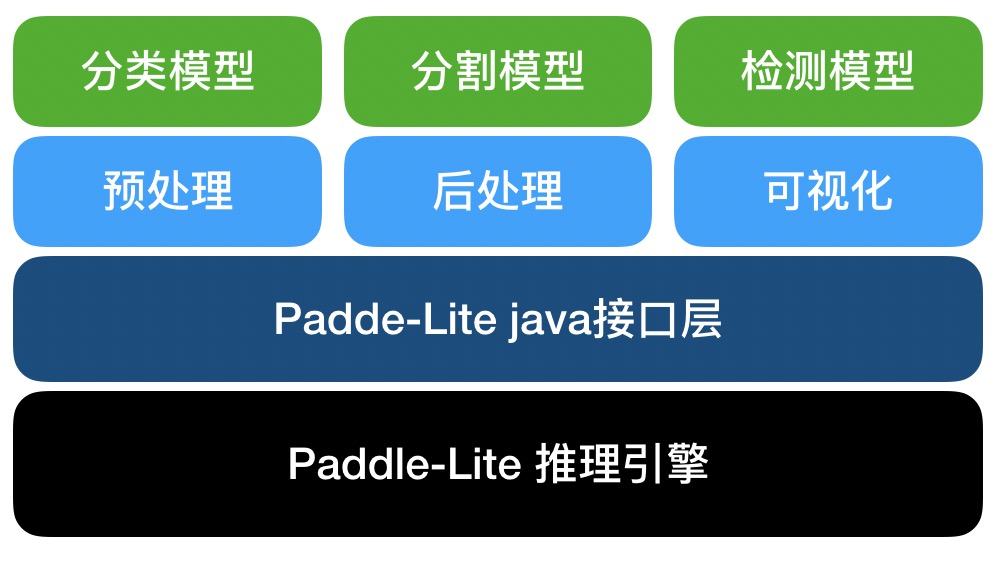
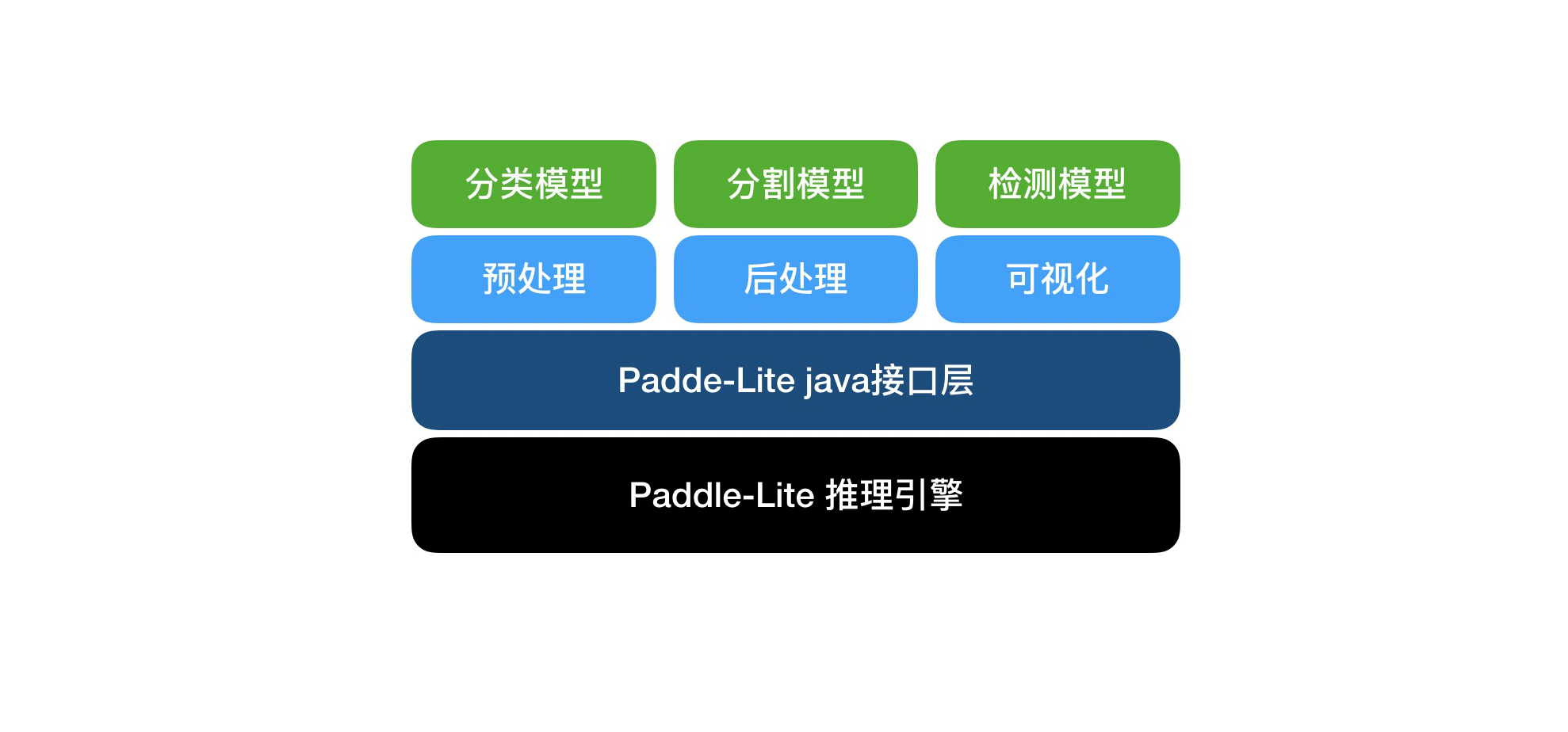
@@ -79,7 +79,7 @@ PaddleX Android SDK是PaddleX基于Paddle-Lite开发的安卓端AI推理工具
-
Paddle-Lite接口层,以Java接口封装了底层c++推理库。
-
PaddleX业务层,封装了PaddleX导出模型的预处理,推理和后处理,以及可视化,支持PaddleX导出的检测、分割、分类模型。
<img
width=
"600"
src=
"../images/paddlex_android_sdk_framework.jpg"
/>

#### 3.3.1 SDK安装
...
...
docs/deploy/paddlelite/slim/index.rst
浏览文件 @
6d6a0df1
...
...
@@ -8,3 +8,4 @@
quant.md
prune.md
tutorials/index
docs/deploy/paddlelite/slim/prune.md
浏览文件 @
6d6a0df1
...
...
@@ -25,10 +25,10 @@ PaddleX提供了两种方式:
> 注:各模型内置的裁剪方案分别依据的数据集为: 图像分类——ImageNet数据集、目标检测——PascalVOC数据集、语义分割——CityScape数据集
## 裁剪实验
基于上述两种方案,我们在PaddleX上使用样例数据进行了实验,在Tesla P40上实验指标如下所示
,使用方法见
[
使用教程-模型压缩
](
../../../../tutorials/compress/README.html
)
基于上述两种方案,我们在PaddleX上使用样例数据进行了实验,在Tesla P40上实验指标如下所示
:
### 图像分类
实验背景:使用MobileNetV2模型,数据集为蔬菜分类示例数据
实验背景:使用MobileNetV2模型,数据集为蔬菜分类示例数据
,使用方法见
[
使用教程-模型压缩-图像分类
](
./tutorials/classification.html
)
| 模型 | 裁剪情况 | 模型大小 | Top1准确率(%) |GPU预测速度 | CPU预测速度 |
| :-----| :--------| :-------- | :---------- |:---------- |:----------|
...
...
@@ -37,7 +37,7 @@ PaddleX提供了两种方式:
|MobileNetV2 | 方案二(eval_metric_loss=0.10) | 6.0M | 99.58 |5.42ms |29.06ms |
### 目标检测
实验背景:使用YOLOv3-MobileNetV1模型,数据集为昆虫检测示例数据
实验背景:使用YOLOv3-MobileNetV1模型,数据集为昆虫检测示例数据
,使用方法见
[
使用教程-模型压缩-目标检测
](
./tutorials/detection.html
)
| 模型 | 裁剪情况 | 模型大小 | MAP(%) |GPU预测速度 | CPU预测速度 |
| :-----| :--------| :-------- | :---------- |:---------- | :---------|
...
...
@@ -46,7 +46,7 @@ PaddleX提供了两种方式:
|YOLOv3-MobileNetV1 | 方案二(eval_metric_loss=0.05) | 29M | 50.27| 9.43ms |360.46ms |
### 语义分割
实验背景:使用UNet模型,数据集为视盘分割示例数据
实验背景:使用UNet模型,数据集为视盘分割示例数据
,使用方法见
[
使用教程-模型压缩-语义分割
](
./tutorials/segmentation.html
)
| 模型 | 裁剪情况 | 模型大小 | mIOU(%) |GPU预测速度 | CPU预测速度 |
| :-----| :--------| :-------- | :---------- |:---------- | :---------|
...
...
docs/deploy/paddlelite/slim/quant.md
浏览文件 @
6d6a0df1
...
...
@@ -6,7 +6,7 @@
定点量化使用更少的比特数(如8-bit、3-bit、2-bit等)表示神经网络的权重和激活值,从而加速模型推理速度。PaddleX提供了训练后量化技术,其原理可参见
[
训练后量化原理
](
https://paddlepaddle.github.io/PaddleSlim/algo/algo.html#id14
)
,该量化使用KL散度确定量化比例因子,将FP32模型转成INT8模型,且不需要重新训练,可以快速得到量化模型。
## 使用PaddleX量化模型
PaddleX提供了
`export_quant_model`
接口,让用户以接口的形式完成模型以post_quantization方式量化并导出。点击查看
[
量化接口使用文档
](
../../apis/slim.html
)
。
PaddleX提供了
`export_quant_model`
接口,让用户以接口的形式完成模型以post_quantization方式量化并导出。点击查看
[
量化接口使用文档
](
../../
../
apis/slim.html
)
。
## 量化性能对比
模型量化后的性能对比指标请查阅
[
PaddleSlim模型库
](
https://paddlepaddle.github.io/PaddleSlim/model_zoo.html
)
编辑
预览
Markdown
is supported
0%
请重试
或
添加新附件
.
添加附件
取消
You are about to add
0
people
to the discussion. Proceed with caution.
先完成此消息的编辑!
取消
想要评论请
注册
或
登录
{kind=link}
{kind=link}