Merge branch 'develop' of https://github.com/PaddlePaddle/PaddleX into develop_qh
Showing
docs/FAQ.md
已删除
100755 → 0
docs/README.md
100755 → 100644
文件模式从 100755 更改为 100644
docs/apis/datasets/index.rst
已删除
100755 → 0
docs/apis/deploy.md
已删除
100755 → 0
docs/apis/interpret.md
0 → 100644
docs/appendix/datasets.md
已删除
100644 → 0
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
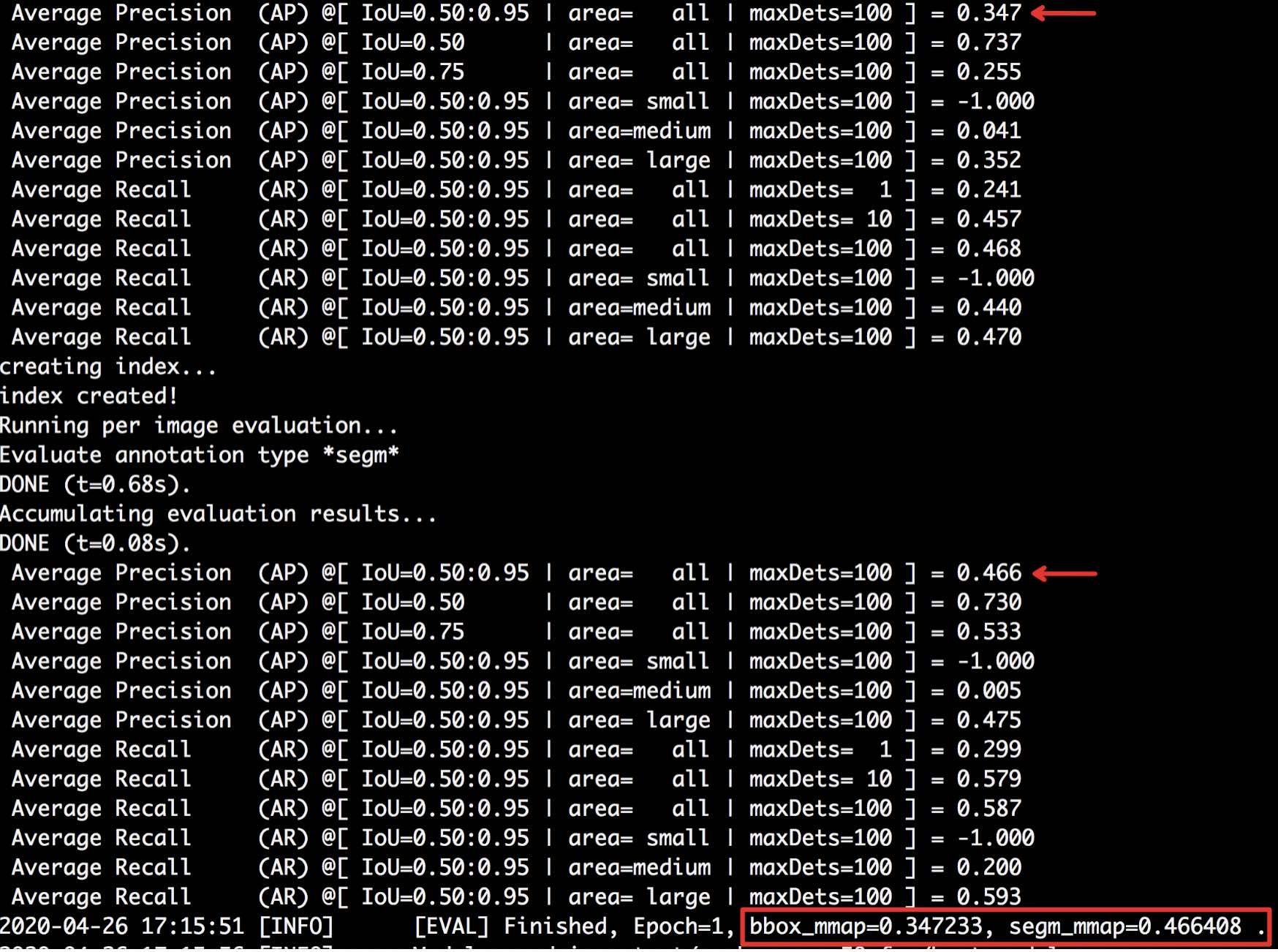
288.0 KB
{kind=link}
docs/appendix/images/normlime.png
0 → 100644
{kind=link}

277.0 KB
{kind=link}
{kind=link}
{kind=link}
{kind=link}
docs/change_log.md
0 → 100644
docs/cv_solutions.md
已删除
100755 → 0
docs/data/annotation.md
0 → 100755
docs/data/format/detection.md
0 → 100644
docs/data/format/segmentation.md
0 → 100644
docs/data/index.rst
0 → 100755
docs/datasets.md
已删除
100644 → 0
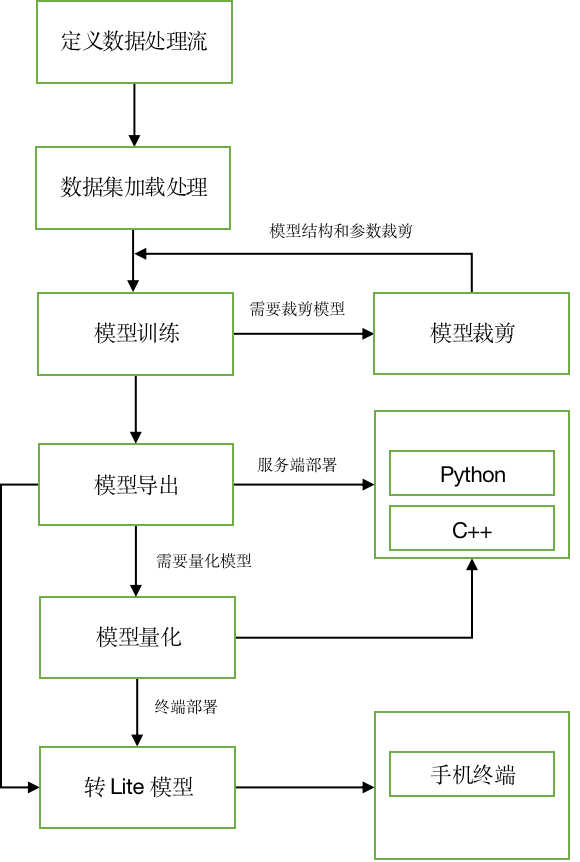
docs/deploy/export_model.md
0 → 100644
{kind=link}
{kind=link}
文件已移动
{kind=link}
文件已移动
{kind=link}
文件已移动
{kind=link}
文件已移动
{kind=link}
文件已移动
{kind=link}
文件已移动
{kind=link}
文件已移动
{kind=link}
文件已移动
{kind=link}
文件已移动
docs/deploy/index.rst
0 → 100755
docs/deploy/nvidia-jetson.md
0 → 100644
docs/deploy/openvino/index.rst
0 → 100755
docs/deploy/openvino/linux.md
0 → 100644
docs/deploy/openvino/windows.md
0 → 100644
docs/deploy/paddlelite/android.md
0 → 100644
docs/deploy/paddlelite/index.rst
0 → 100755
docs/deploy/server/cpp/index.rst
0 → 100755
docs/examples/index.rst
0 → 100755
docs/examples/solutions.md
0 → 100644
docs/images/00_loaddata.png
已删除
100755 → 0
{kind=link}
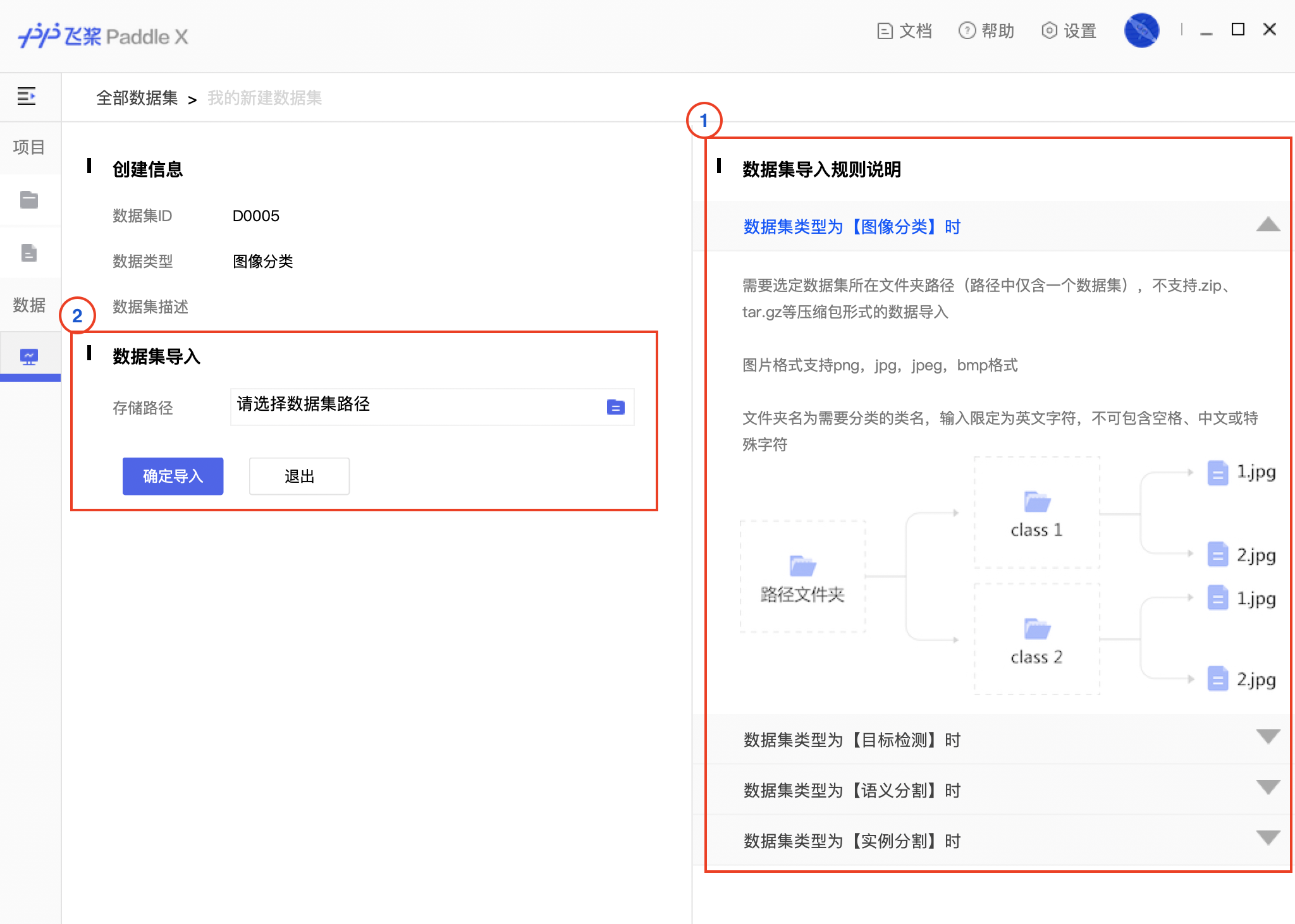
456.5 KB
docs/images/01_datasplit.png
已删除
100755 → 0
{kind=link}
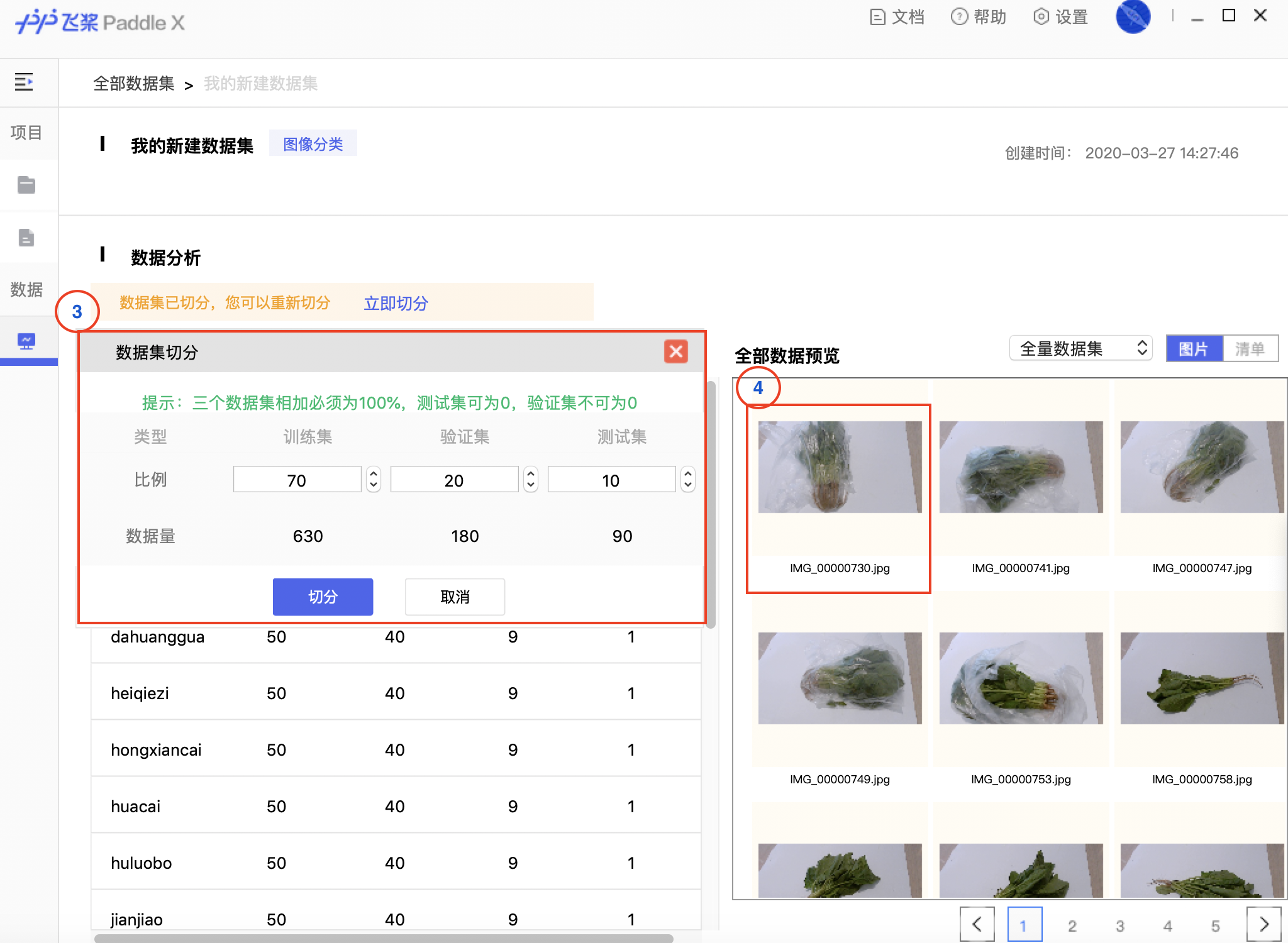
898.1 KB
docs/images/02_newproject.png
已删除
100755 → 0
{kind=link}
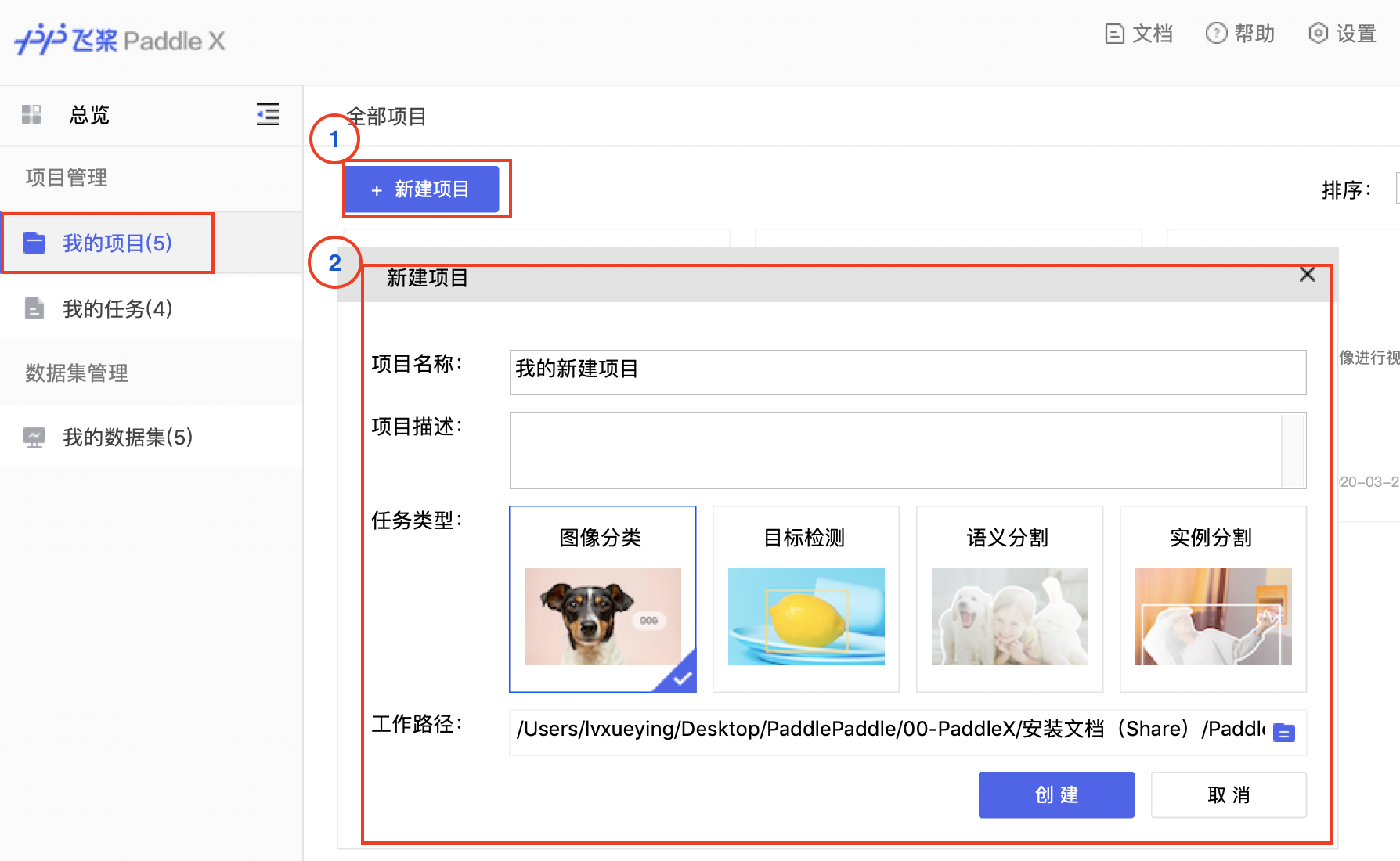
423.2 KB
docs/images/03_choosedata.png
已删除
100755 → 0
{kind=link}
108.7 KB
docs/images/04_parameter.png
已删除
100755 → 0
{kind=link}
392.2 KB
docs/images/05_train.png
已删除
100755 → 0
{kind=link}
174.0 KB
docs/images/06_VisualDL.png
已删除
100755 → 0
{kind=link}
196.3 KB
docs/images/07_evaluate.png
已删除
100755 → 0
{kind=link}
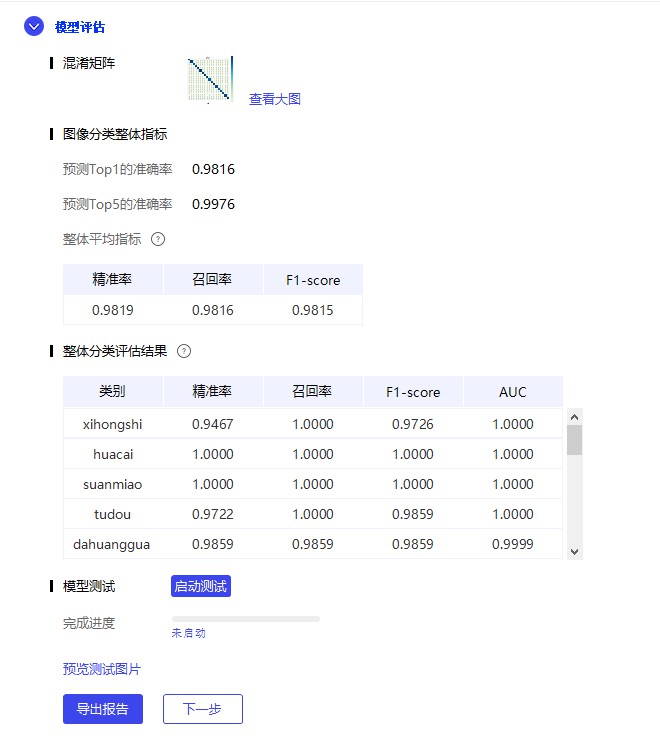
59.7 KB
docs/images/08_deploy.png
已删除
100755 → 0
{kind=link}
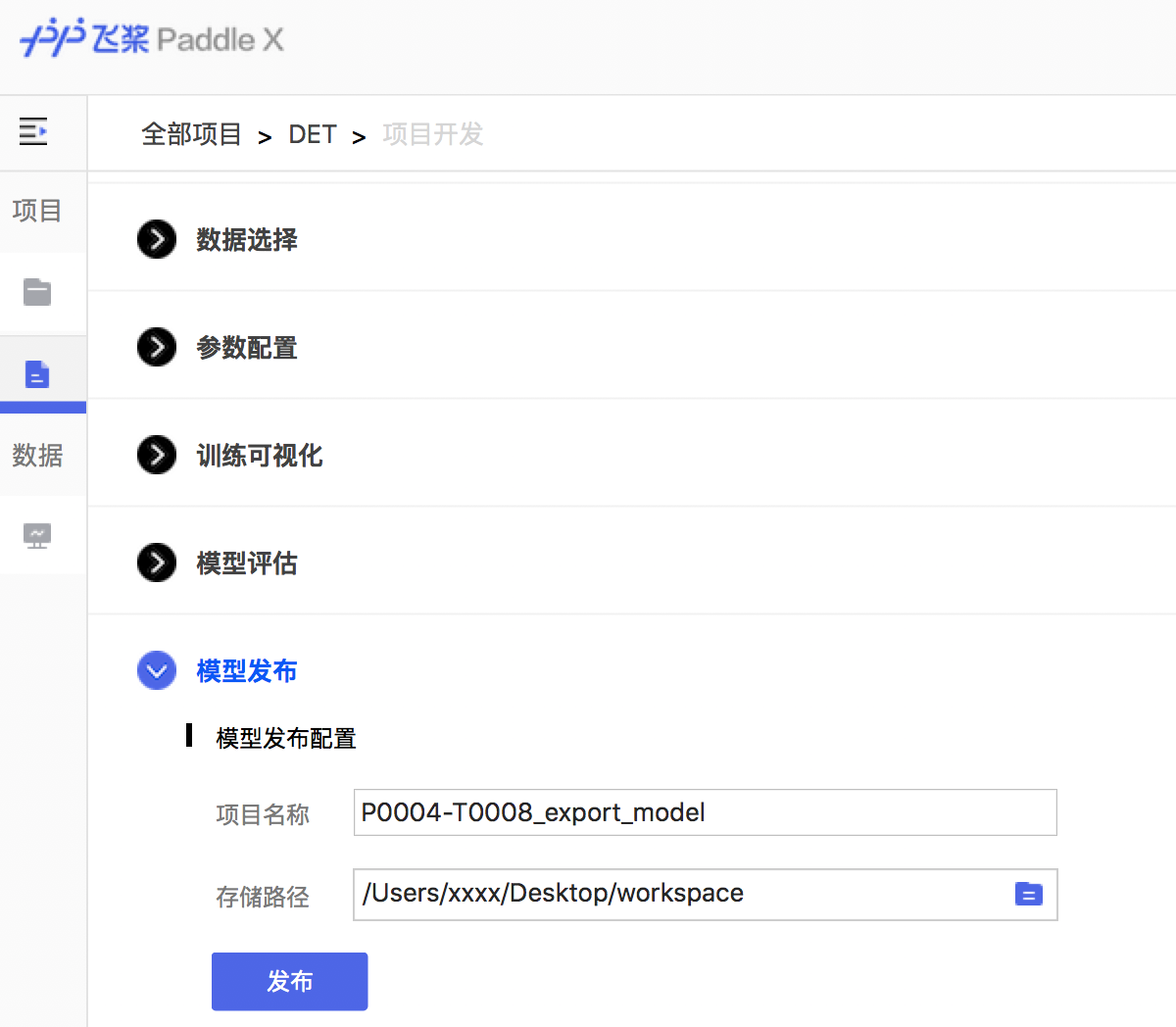
194.1 KB
{kind=link}
48.4 KB
docs/images/QQGroup.jpeg
已删除
100755 → 0
{kind=link}
此差异已折叠。
docs/images/garbage.bmp
已删除
100755 → 0
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
docs/images/mask_eval.png
已删除
100755 → 0
{kind=link}
此差异已折叠。
docs/images/normlime.png
已删除
100644 → 0
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
docs/images/paddlex.jpg
已删除
100755 → 0
{kind=link}
此差异已折叠。
docs/images/paddlex.png
已删除
100755 → 0
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
docs/images/vdl1.jpg
已删除
100644 → 0
{kind=link}
此差异已折叠。
docs/images/vdl2.jpg
已删除
100644 → 0
{kind=link}
此差异已折叠。
docs/images/vdl3.jpg
已删除
100644 → 0
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
此差异已折叠。
此差异已折叠。
docs/metrics.md
已删除
100644 → 0
此差异已折叠。
docs/model_zoo.md
已删除
100644 → 0
此差异已折叠。
docs/paddlex.png
0 → 100644
{kind=link}
此差异已折叠。
docs/paddlex_gui/download.md
已删除
100644 → 0
此差异已折叠。
此差异已折叠。
{kind=link}
此差异已折叠。
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
docs/paddlex_gui/xx.md
已删除
100644 → 0
此差异已折叠。
此差异已折叠。
docs/slim/prune.md
已删除
100644 → 0
此差异已折叠。
docs/slim/quant.md
已删除
100644 → 0
此差异已折叠。
docs/test.cpp
已删除
100644 → 0
此差异已折叠。
docs/train/classification.md
0 → 100644
此差异已折叠。
docs/train/index.rst
0 → 100755
此差异已折叠。
此差异已折叠。
docs/train/object_detection.md
0 → 100644
此差异已折叠。
docs/train/prediction.md
0 → 100644
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
docs/tutorials/datasets.md
已删除
100755 → 0
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
docs/tutorials/index.rst
已删除
100755 → 0
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
docs/update.md
已删除
100644 → 0
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。