Merge branch 'develop' of https://github.com/PaddlePaddle/PaddleSlim into update_ofa
Showing
.gitmodules
0 → 100644
.style.yapf
0 → 100644
LICENSE
0 → 100644
README_en.md
0 → 100644
demo/auto_prune/README.md
0 → 100644
demo/auto_prune/train_finetune.py
0 → 100644
demo/auto_prune/train_iterator.py
0 → 100644
demo/bert/run.sh
0 → 100644
demo/bert/train_distill.py
0 → 100755
demo/bert/train_search.py
0 → 100755
demo/bert/train_teacher.py
0 → 100644
demo/darts/README.md
0 → 100644
demo/darts/genotypes.py
0 → 100644
demo/darts/images/networks.gif
0 → 100755
{kind=link}
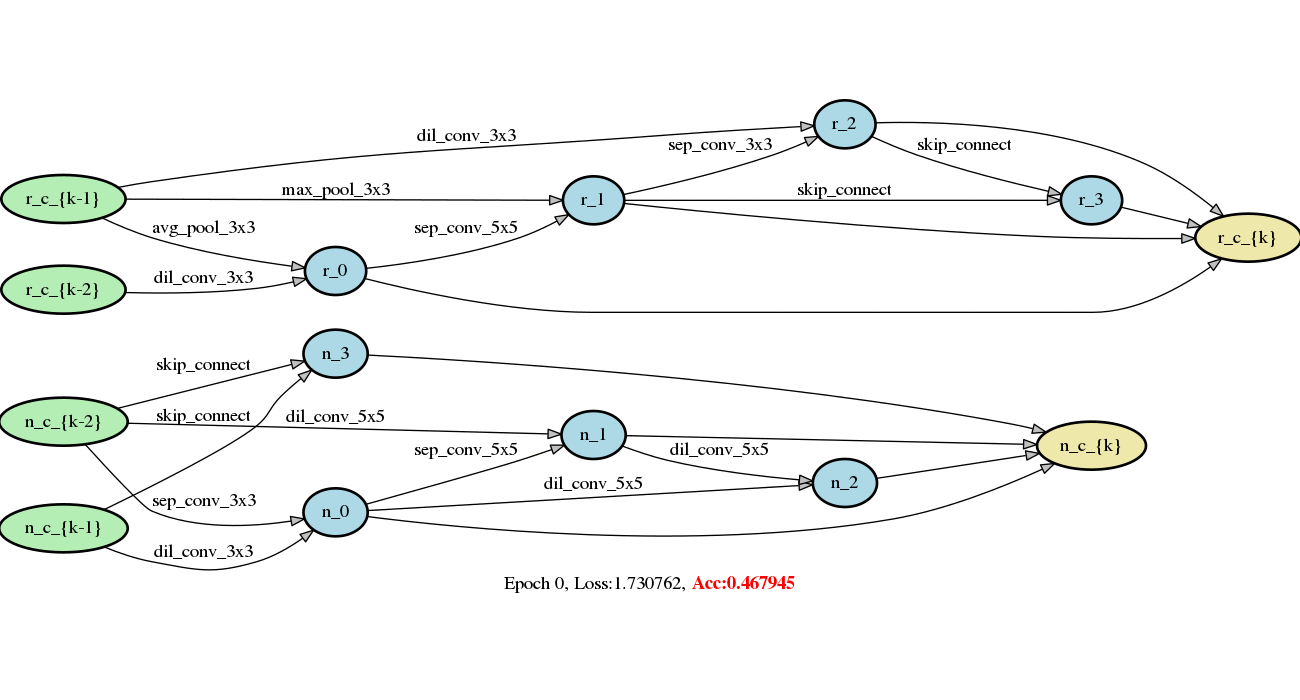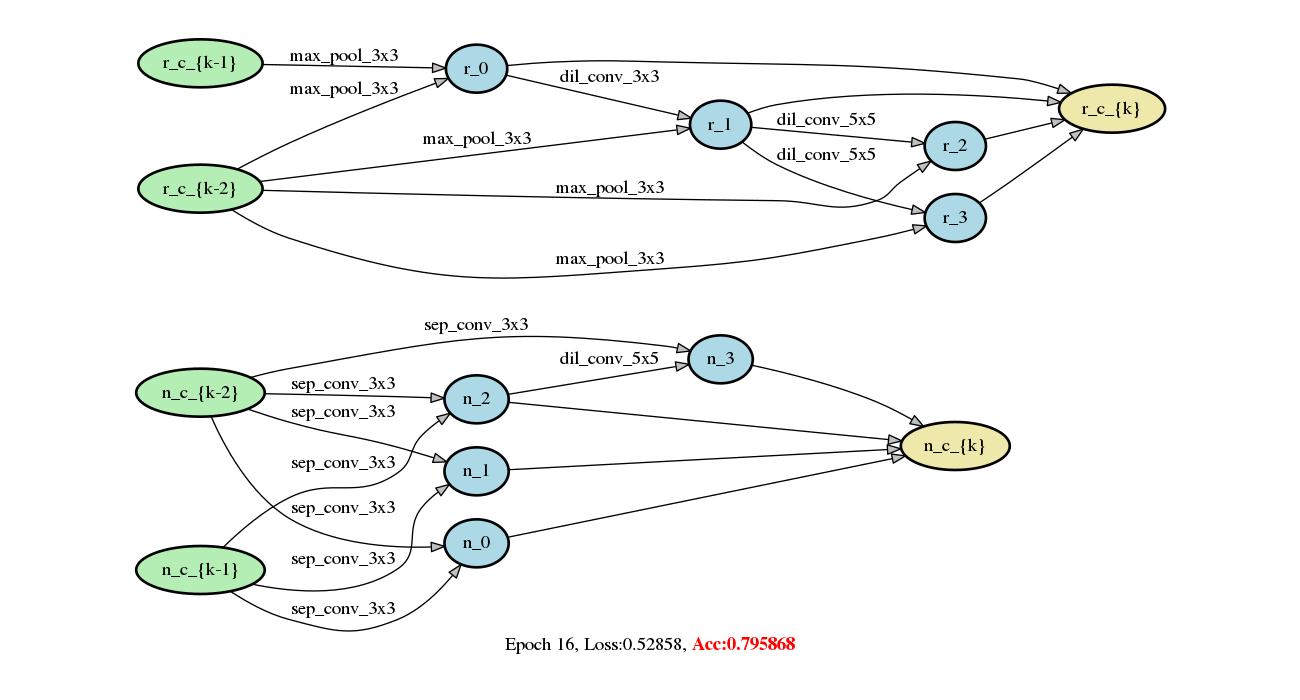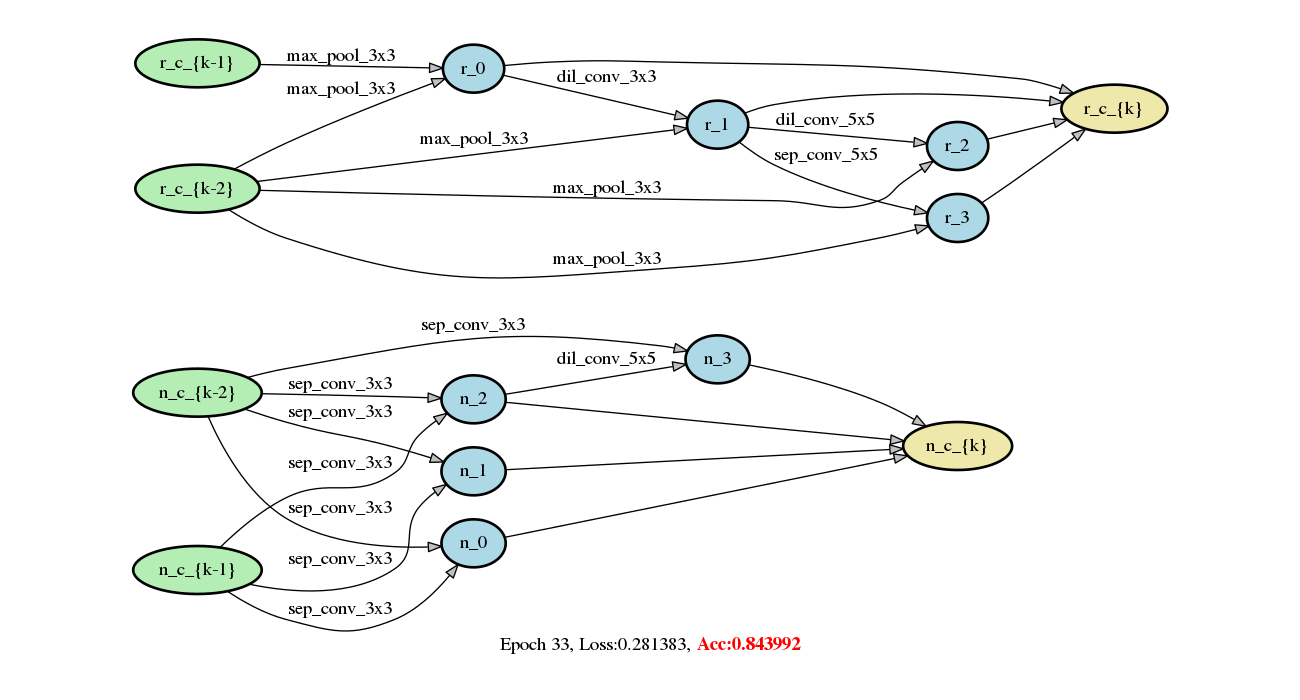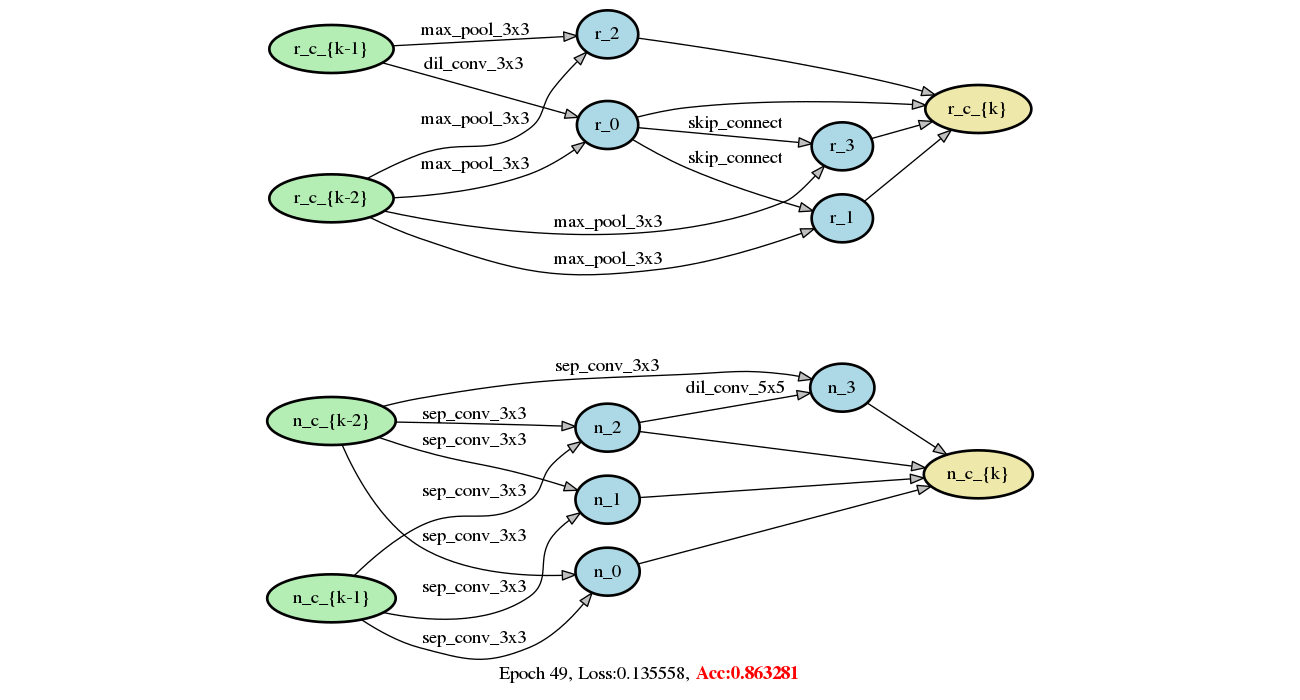
2.2 MB
demo/darts/model.py
0 → 100644
demo/darts/model_search.py
0 → 100644
demo/darts/operations.py
0 → 100644
demo/darts/reader.py
0 → 100644
demo/darts/search.py
0 → 100644
demo/darts/train.py
0 → 100644
demo/darts/train_imagenet.py
0 → 100644
demo/darts/visualize.py
0 → 100644
{kind=link}
163.1 KB
demo/detection/README.md
0 → 100644
此差异已折叠。
demo/distillation/README.md
0 → 100644
demo/mkldnn_quant/CMakeLists.txt
0 → 100644
demo/mkldnn_quant/README.md
0 → 100644
demo/mkldnn_quant/README_en.md
0 → 100644
此差异已折叠。
此差异已折叠。
此差异已折叠。
demo/mkldnn_quant/run.sh
0 → 100644
此差异已折叠。
此差异已折叠。
demo/models/mobilenet_v3.py
0 → 100644
此差异已折叠。
demo/models/pvanet.py
0 → 100644
此差异已折叠。
demo/models/resnet_vd.py
0 → 100644
此差异已折叠。
demo/models/slimfacenet.py
0 → 100644
此差异已折叠。
此差异已折叠。
demo/nas/darts_cifar10_reader.py
0 → 100644
此差异已折叠。
此差异已折叠。
demo/nas/parl_nas_mobilenetv2.py
0 → 100644
此差异已折叠。
demo/nas/rl_nas_mobilenetv2.py
0 → 100644
此差异已折叠。
demo/nas/sanas_darts_space.py
0 → 100644
此差异已折叠。
demo/ocr/README.md
0 → 100755
此差异已折叠。
demo/one_shot/ofa_train.py
0 → 100644
此差异已折叠。
demo/one_shot/train.py
0 → 100644
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
demo/pantheon/toy/README.md
0 → 100644
此差异已折叠。
demo/pantheon/toy/run_student.py
0 → 100644
此差异已折叠。
demo/pantheon/toy/run_teacher1.py
0 → 100644
此差异已折叠。
demo/pantheon/toy/run_teacher2.py
0 → 100644
此差异已折叠。
demo/pantheon/toy/utils.py
0 → 100644
此差异已折叠。
demo/prune/README.md
0 → 100755
此差异已折叠。
demo/prune/eval.py
0 → 100644
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
{kind=link}
473.4 KB
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
demo/slimfacenet/README.md
0 → 100755
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
demo/slimfacenet/lfw_eval.py
0 → 100644
此差异已折叠。
demo/slimfacenet/slim_eval.sh
0 → 100644
此差异已折叠。
demo/slimfacenet/slim_quant.sh
0 → 100644
此差异已折叠。
demo/slimfacenet/slim_train.sh
0 → 100644
此差异已折叠。
demo/slimfacenet/train_eval.py
0 → 100644
此差异已折叠。
docs/README.md
0 → 100644
此差异已折叠。
docs/docs/api/analysis_api.md
已删除
100644 → 0
此差异已折叠。
docs/docs/api/api_guide.md
已删除
100644 → 0
此差异已折叠。
docs/docs/api/nas_api.md
已删除
100644 → 0
此差异已折叠。
docs/docs/api/prune_api.md
已删除
100644 → 0
此差异已折叠。
此差异已折叠。
此差异已折叠。
docs/docs/index.md
已删除
100644 → 0
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
docs/en/Makefile
0 → 100644
此差异已折叠。
docs/en/api_en/index_en.rst
0 → 100644
此差异已折叠。
docs/en/api_en/modules.rst
0 → 100644
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
docs/en/api_en/paddleslim.nas.rst
0 → 100644
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
docs/en/api_en/paddleslim.rst
0 → 100644
此差异已折叠。
此差异已折叠。
docs/en/conf.py
0 → 100644
此差异已折叠。
docs/en/index.rst
0 → 100644
此差异已折叠。
docs/en/install_en.md
0 → 100644
此差异已折叠。
docs/en/intro_en.md
0 → 100644
此差异已折叠。
docs/en/model_zoo_en.md
0 → 100644
此差异已折叠。
此差异已折叠。
docs/en/quick_start/index_en.rst
0 → 100644
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
docs/en/tutorials/index_en.rst
0 → 100644
此差异已折叠。
{kind=link}
文件已移动
{kind=link}
文件已移动
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
docs/images/framework_0.png
0 → 100644
{kind=link}
此差异已折叠。
docs/images/framework_1.png
0 → 100644
{kind=link}
此差异已折叠。
docs/mkdocs.yml
已删除
100644 → 0
此差异已折叠。
此差异已折叠。
docs/zh_cn/CHANGELOG.md
0 → 100644
此差异已折叠。
docs/zh_cn/FAQ/index.rst
0 → 100644
此差异已折叠。
此差异已折叠。
docs/zh_cn/Makefile
0 → 100644
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
docs/zh_cn/api_cn/darts.rst
0 → 100644
此差异已折叠。
此差异已折叠。
docs/zh_cn/api_cn/early_stop.rst
0 → 100644
此差异已折叠。
docs/zh_cn/api_cn/index.rst
0 → 100644
此差异已折叠。
docs/zh_cn/api_cn/nas_api.rst
0 → 100644
此差异已折叠。
docs/zh_cn/api_cn/nas_index.rst
0 → 100644
此差异已折叠。
此差异已折叠。
docs/zh_cn/api_cn/pantheon_api.md
0 → 100644
此差异已折叠。
docs/zh_cn/api_cn/prune_api.rst
0 → 100644
此差异已折叠。
docs/zh_cn/api_cn/prune_index.rst
0 → 100644
此差异已折叠。
docs/zh_cn/api_cn/quant_index.rst
0 → 100644
此差异已折叠。
此差异已折叠。
此差异已折叠。
docs/zh_cn/conf.py
0 → 100644
此差异已折叠。
docs/zh_cn/index.rst
0 → 100644
此差异已折叠。
docs/zh_cn/install.md
0 → 100644
此差异已折叠。
docs/zh_cn/intro.md
0 → 100644
此差异已折叠。
docs/zh_cn/model_zoo.md
0 → 100644
此差异已折叠。
此差异已折叠。
docs/zh_cn/model_zoo/index.rst
0 → 100644
此差异已折叠。
docs/zh_cn/model_zoo/model_zoo.md
0 → 100644
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
docs/zh_cn/quick_start/index.rst
0 → 100644
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
docs/zh_cn/tutorials/index.rst
0 → 100644
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
paddleslim/common/client.py
0 → 100644
此差异已折叠。
paddleslim/common/meter.py
0 → 100644
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
paddleslim/common/server.py
0 → 100644
此差异已折叠。
paddleslim/dist/__init__.py
100644 → 100755
此差异已折叠。
paddleslim/dist/dml.py
0 → 100755
此差异已折叠。
此差异已折叠。
paddleslim/models/README.md
0 → 100755
此差异已折叠。
paddleslim/models/__init__.py
0 → 100644
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
paddleslim/models/mobilenet.py
0 → 100644
此差异已折叠。
paddleslim/models/mobilenet_v2.py
0 → 100644
此差异已折叠。
paddleslim/models/resnet.py
0 → 100644
此差异已折叠。
此差异已折叠。
paddleslim/models/slimfacenet.py
0 → 100644
此差异已折叠。
paddleslim/models/util.py
0 → 100644
此差异已折叠。
paddleslim/nas/darts/__init__.py
0 → 100644
此差异已折叠。
paddleslim/nas/darts/architect.py
0 → 100644
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
paddleslim/nas/ofa/__init__.py
0 → 100644
此差异已折叠。
此差异已折叠。
paddleslim/nas/ofa/layers.py
0 → 100644
此差异已折叠。
paddleslim/nas/ofa/ofa.py
0 → 100644
此差异已折叠。
此差异已折叠。
paddleslim/nas/ofa/utils/utils.py
0 → 100644
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
paddleslim/nas/rl_nas.py
0 → 100644
此差异已折叠。
此差异已折叠。
paddleslim/pantheon/README.md
0 → 100644
此差异已折叠。
paddleslim/pantheon/__init__.py
0 → 100644
此差异已折叠。
{kind=link}
此差异已折叠。
paddleslim/pantheon/student.py
0 → 100644
此差异已折叠。
paddleslim/pantheon/teacher.py
0 → 100644
此差异已折叠。
paddleslim/pantheon/utils.py
0 → 100644
此差异已折叠。
此差异已折叠。
此差异已折叠。
paddleslim/prune/criterion.py
0 → 100644
此差异已折叠。
paddleslim/prune/group_param.py
0 → 100644
此差异已折叠。
paddleslim/prune/idx_selector.py
0 → 100644
此差异已折叠。
paddleslim/prune/prune_io.py
0 → 100644
此差异已折叠。
paddleslim/prune/prune_walker.py
0 → 100644
此差异已折叠。
paddleslim/teachers/__init__.py
0 → 100644
此差异已折叠。
此差异已折叠。
paddleslim/teachers/bert/cls.py
0 → 100755
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
tests/test_autoprune.py
0 → 100644
此差异已折叠。
tests/test_client_connect.py
0 → 100644
此差异已折叠。
tests/test_darts.py
0 → 100644
此差异已折叠。
此差异已折叠。
tests/test_earlystop.py
0 → 100644
此差异已折叠。
此差异已折叠。
tests/test_fpgm_prune.py
0 → 100644
此差异已折叠。
tests/test_fsp_loss.py
0 → 100644
此差异已折叠。
tests/test_group_param.py
0 → 100644
此差异已折叠。
tests/test_l2_loss.py
0 → 100644
此差异已折叠。
tests/test_loss.py
0 → 100644
此差异已折叠。
tests/test_merge.py
0 → 100644
此差异已折叠。
此差异已折叠。
tests/test_ofa.py
0 → 100644
此差异已折叠。
tests/test_optimal_threshold.py
0 → 100644
此差异已折叠。
此差异已折叠。
tests/test_prune_walker.py
0 → 100644
此差异已折叠。
此差异已折叠。
tests/test_quant_aware.py
0 → 100644
此差异已折叠。
此差异已折叠。
tests/test_quant_embedding.py
0 → 100644
此差异已折叠。
tests/test_quant_post.py
0 → 100644
此差异已折叠。
此差异已折叠。
tests/test_rl_nas.py
0 → 100644
此差异已折叠。
此差异已折叠。
tests/test_soft_label_loss.py
0 → 100644
此差异已折叠。