| 序号 | +任务 | +模型 | +压缩策略[3][4] | +精度(自建中文数据集) | +耗时[1](ms) | +整体耗时[2](ms) | +加速比 | +整体模型大小(M) | +压缩比例 | +下载链接 | +
|---|---|---|---|---|---|---|---|---|---|---|
| 0 | +检测 | +MobileNetV3_DB | +无 | +61.7 | +224 | +375 | +- | +8.6 | +- | ++ |
| 识别 | +MobileNetV3_CRNN | +无 | +62.0 | +9.52 | ++ | |||||
| 1 | +检测 | +SlimTextDet | +PACT量化训练 | +62.1 | +195 | +348 | +8% | +2.8 | +67.82% | ++ |
| 识别 | +SlimTextRec | +PACT量化训练 | +61.48 | +8.6 | ++ | |||||
| 2 | +检测 | +SlimTextDet_quat_pruning | +剪裁+PACT量化训练 | +60.86 | +142 | +288 | +30% | +2.8 | +67.82% | ++ |
| 识别 | +SlimTextRec | +PACT量化训练 | +61.48 | +8.6 | ++ | |||||
| 3 | +检测 | +SlimTextDet_pruning | +剪裁 | +61.57 | +138 | +295 | +27% | +2.9 | +66.28% | ++ |
| 识别 | +SlimTextRec | +PACT量化训练 | +61.48 | +8.6 | ++ |
+
+
+
+
+
+
-
-图1:量化前的模型结构
-
-
-图2: 量化后的模型结构
-
+ MobileNetV2's architecture can reference: [code](https://github.com/PaddlePaddle/models/blob/develop/PaddleCV/image_classification/models/mobilenet_v2.py#L29), [paper](https://arxiv.org/abs/1801.04381) + +2. MobileNetV1Space
+ MobilNetV1's architecture can reference: [code](https://github.com/PaddlePaddle/models/blob/develop/PaddleCV/image_classification/models/mobilenet_v1.py#L29), [paper](https://arxiv.org/abs/1704.04861) + +3. ResNetSpace
+ ResNetSpace's architecture can reference: [code](https://github.com/PaddlePaddle/models/blob/develop/PaddleCV/image_classification/models/resnet.py#L30), [paper](https://arxiv.org/pdf/1512.03385.pdf) + + +#### Based on block from different model: +1. MobileNetV1BlockSpace
+ MobileNetV1Block's architecture can reference: [code](https://github.com/PaddlePaddle/models/blob/develop/PaddleCV/image_classification/models/mobilenet_v1.py#L173) + +2. MobileNetV2BlockSpace
+ MobileNetV2Block's architecture can reference: [code](https://github.com/PaddlePaddle/models/blob/develop/PaddleCV/image_classification/models/mobilenet_v2.py#L174) + +3. ResNetBlockSpace
+ ResNetBlock's architecture can reference: [code](https://github.com/PaddlePaddle/models/blob/develop/PaddleCV/image_classification/models/resnet.py#L148) + +4. InceptionABlockSpace
+ InceptionABlock's architecture can reference: [code](https://github.com/PaddlePaddle/models/blob/develop/PaddleCV/image_classification/models/inception_v4.py#L140) + +5. InceptionCBlockSpace
+ InceptionCBlock's architecture can reference: [code](https://github.com/PaddlePaddle/models/blob/develop/PaddleCV/image_classification/models/inception_v4.py#L291) + + +## How to use search space +1. Only need to specify the name of search space if use the space based on origin model architecture, such as configs for class SANAS is [('MobileNetV2Space')] if you want to use origin MobileNetV2 as search space. +2. Use search space paddleslim.nas provided based on block:
+ 2.1 Use `input_size`, `output_size` and `block_num` to construct search space, such as configs for class SANAS is ('MobileNetV2BlockSpace', {'input_size': 224, 'output_size': 32, 'block_num': 10})].
+ 2.2 Use `block_mask` to construct search space, such as configs for class SANAS is [('MobileNetV2BlockSpace', {'block_mask': [0, 1, 1, 1, 1, 0, 1, 0]})]. + +## How to write yourself search space +If you want to write yourself search space, you need to inherit base class named SearchSpaceBase and overwrite following functions:
+ 1. Function to get initial tokens(function `init_tokens`), set the initial tokens which you want, every token in tokens means index of search list, such as if tokens=[0, 3, 5], it means the list of channel of current model architecture is [8, 40, 128]. + 2. Function about the length of every token in tokens(function `range_table`), range of every token in tokens. + 3. Function to get model architecture according to tokens(function `token2arch`), get model architecture according to tokens in the search process. + +For example, how to add a search space with resnet block. New search space can NOT has the same name with existing search space. + +```python +### import necessary head file +from .search_space_base import SearchSpaceBase +from .search_space_registry import SEARCHSPACE +import numpy as np + +### use decorator SEARCHSPACE.register to register yourself search space to search space NameSpace +@SEARCHSPACE.register +### define a search space class inherit the base class SearchSpaceBase +class ResNetBlockSpace2(SearchSpaceBase): + def __init__(self, input_size, output_size, block_num, block_mask): + ### define the iterm you want to search, such as the numeber of channel, the number of convolution repeat, the size of kernel. + ### self.filter_num represents the search list about the numeber of channel. + self.filter_num = np.array([8, 16, 32, 40, 64, 128, 256, 512]) + + ### define initial tokens, the length of initial tokens according to block_num or block_mask. + def init_tokens(self): + return [0] * 3 * len(self.block_mask) + + ### define the range of index in tokens. + def range_table(self): + return [len(self.filter_num)] * 3 * len(self.block_mask) + + ### transform tokens to model architecture. + def token2arch(self, tokens=None): + if tokens == None: + tokens = self.init_tokens() + + self.bottleneck_params_list = [] + for i in range(len(self.block_mask)): + self.bottleneck_params_list.append(self.filter_num[tokens[i * 3 + 0]], + self.filter_num[tokens[i * 3 + 1]], + self.filter_num[tokens[i * 3 + 2]], + 2 if self.block_mask[i] == 1 else 1) + + def net_arch(input): + for i, layer_setting in enumerate(self.bottleneck_params_list): + channel_num, stride = layer_setting[:-1], layer_setting[-1] + input = self._resnet_block(input, channel_num, stride, name='resnet_layer{}'.format(i+1)) + + return input + + return net_arch + + ### code to get block. + def _resnet_block(self, input, channel_num, stride, name=None): + shortcut_conv = self._shortcut(input, channel_num[2], stride, name=name) + input = self._conv_bn_layer(input=input, num_filters=channel_num[0], filter_size=1, act='relu', name=name + '_conv0') + input = self._conv_bn_layer(input=input, num_filters=channel_num[1], filter_size=3, stride=stride, act='relu', name=name + '_conv1') + input = self._conv_bn_layer(input=input, num_filters=channel_num[2], filter_size=1, name=name + '_conv2') + return fluid.layers.elementwise_add(x=shortcut_conv, y=input, axis=0, name=name+'_elementwise_add') + + def _shortcut(self, input, channel_num, stride, name=None): + channel_in = input.shape[1] + if channel_in != channel_num or stride != 1: + return self.conv_bn_layer(input, num_filters=channel_num, filter_size=1, stride=stride, name=name+'_shortcut') + else: + return input + + def _conv_bn_layer(self, input, num_filters, filter_size, stride=1, padding='SAME', act=None, name=None): + conv = fluid.layers.conv2d(input, num_filters, filter_size, stride, name=name+'_conv') + bn = fluid.layers.batch_norm(conv, act=act, name=name+'_bn') + return bn +``` diff --git a/docs/en/api_en/table_latency_en.md b/docs/en/api_en/table_latency_en.md new file mode 100644 index 0000000000000000000000000000000000000000..6a6c6ac665dd8fa021780b753e2287e52c16d404 --- /dev/null +++ b/docs/en/api_en/table_latency_en.md @@ -0,0 +1,144 @@ +# Table about hardware lantency + +The table about hardware latency is used to evaluate the inference time in special environment and inference engine. The following text used to introduce the format that PaddleSlim support. + +## Introduce + +The table about hardware latency saved all possible operations, one operation in the table including type and parameters, such as: type can be `conv2d`, and corresponding parameters can be the size of feature map, number of kernel, and the size of kernel. +The latency of every operation depends on hardware and inference engine. + +## Overview format +The table about hardware latency saved in the way of file or multi-line string. +The first line of the table about hardware latency saved the information about version, every line in the following represents a operation and its latency. + +## Version + +The information about version split by comma in the english format, and the detail is hardware, inference engine and timestamp. + +- ** hardware: ** Used to mark the environment of hardware, including type of architecture, version and so on. + +- ** inference engine: ** Used to mark inference engine, including the name of inference engine, version, optimize options and so on. + +- ** timestamp: ** Used to mark the time of this table created. + +## Operation + +The information about operation split by comma in the english format, the information about operation and latency split by tabs. + +### conv2d + +**format** + +```text +op_type,flag_bias,flag_relu,n_in,c_in,h_in,w_in,c_out,groups,kernel,padding,stride,dilation\tlatency +``` + +**introduce** + +- **op_type(str)** - The type of this op. +- **flag_bias (int)** - Whether has bias or not(0: donot has bias, 1: has bias). +- **flag_relu (int)** - Whether has relu or not(0: donot has relu, 1: has relu). +- **n_in (int)** - The batch size of input. +- **c_in (int)** - The number of channel about input. +- **h_in (int)** - The height of input feature map. +- **w_in (int)** - The width of input feature map. +- **c_out (int)** - The number of channel about output. +- **groups (int)** - The group of conv2d. +- **kernel (int)** - The size of kernel. +- **padding (int)** - The size of padding. +- **stride (int)** - The size of stride. +- **dilation (int)** - The size of dilation. +- **latency (float)** - The latency of this op. + +### activaiton + +**format** + +```text +op_type,n_in,c_in,h_in,w_in\tlatency +``` + +**introduce** + +- **op_type(str)** - The type of this op. +- **n_in (int)** - The batch size of input. +- **c_in (int)** - The number of channel about input. +- **h_in (int)** - The height of input feature map. +- **w_in (int)** - The width of input feature map. +- **latency (float)** - The latency of this op. + +### batch_norm + +**format** + +```text +op_type,active_type,n_in,c_in,h_in,w_in\tlatency +``` + +**introduce** + +- **op_type(str)** - The type of this op. +- **active_type (string|None)** - The type of activation function, including relu, prelu, sigmoid, relu6, tanh. +- **n_in (int)** - The batch size of input. +- **c_in (int)** - The number of channel about input. +- **h_in (int)** - The height of input feature map. +- **w_in (int)** - The width of input feature map. +- **latency (float)** - The latency of this op. + +### eltwise + +**format** + +```text +op_type,n_in,c_in,h_in,w_in\tlatency +``` + +**introduce** + +- **op_type(str)** - The type of this op. +- **n_in (int)** - The batch size of input. +- **c_in (int)** - The number of channel about input. +- **h_in (int)** - The height of input feature map. +- **w_in (int)** - The width of input feature map. +- **latency (float)** - The latency of this op. + +### pooling + +**format** + +```text +op_type,flag_global_pooling,n_in,c_in,h_in,w_in,kernel,padding,stride,ceil_mode,pool_type\tlatency +``` + +**introduce** + +- **op_type(str)** - The type of this op. +- **flag_global_pooling (int)** - Whether is global pooling or not(0: is not global, 1: is global pooling). +- **n_in (int)** - The batch size of input. +- **c_in (int)** - The number of channel about input. +- **h_in (int)** - The height of input feature map. +- **w_in (int)** - The width of input feature map. +- **kernel (int)** - The size of kernel. +- **padding (int)** - The size of padding. +- **stride (int)** - The size of stride. +- **ceil_mode (int)** - Whether to compute height and width by using ceil function(0: use floor function, 1: use ceil function). +- **pool_type (int)** - The type of pooling(1: max pooling 2: average pooling including padding 3: average pooling excluding padding). +- **latency (float)** - The latency of this op. + +### softmax + +**format** + +```text +op_type,axis,n_in,c_in,h_in,w_in\tlatency +``` + +**introduce** + +- **op_type(str)** - The type of this op. +- **axis (int)** - The index to compute softmax, index in the range of [-1, rank-1], `rank` is the rank of input. +- **n_in (int)** - The batch size of input. +- **c_in (int)** - The number of channel about input. +- **h_in (int)** - The height of input feature map. +- **w_in (int)** - The width of input feature map. +- **latency (float)** - The latency of this op. diff --git a/docs/en/conf.py b/docs/en/conf.py new file mode 100644 index 0000000000000000000000000000000000000000..30d2fd07094e3d60c62a6ae5bab72ef661391f4c --- /dev/null +++ b/docs/en/conf.py @@ -0,0 +1,171 @@ +# -*- coding: utf-8 -*- +# +# Configuration file for the Sphinx documentation builder. +# +# This file does only contain a selection of the most common options. For a +# full list see the documentation: +# http://www.sphinx-doc.org/en/master/config + +# -- Path setup -------------------------------------------------------------- + +# If extensions (or modules to document with autodoc) are in another directory, +# add these directories to sys.path here. If the directory is relative to the +# documentation root, use os.path.abspath to make it absolute, like shown here. +# +import os +import sys +sys.path.insert(0, os.path.abspath('../../')) + +# -- Project information ----------------------------------------------------- + +project = u'PaddleSlim' +copyright = u'2020, paddleslim' +author = u'paddleslim' + +# The short X.Y version +version = u'' +# The full version, including alpha/beta/rc tags +release = u'' + +# -- General configuration --------------------------------------------------- + +# If your documentation needs a minimal Sphinx version, state it here. +# +# needs_sphinx = '1.0' + +# Add any Sphinx extension module names here, as strings. They can be +# extensions coming with Sphinx (named 'sphinx.ext.*') or your custom +# ones. +extensions = [ + 'sphinx.ext.autodoc', + 'sphinx.ext.doctest', + 'sphinx.ext.coverage', + 'sphinx.ext.mathjax', + 'sphinx.ext.githubpages', + 'sphinx.ext.napoleon', + 'recommonmark', + 'sphinx_markdown_tables', +# 'm2r', +] + +# Add any paths that contain templates here, relative to this directory. +templates_path = ['_templates'] + +# The suffix(es) of source filenames. +# You can specify multiple suffix as a list of string: +# +source_suffix = ['.rst', '.md'] +#source_suffix = '.rst' + +# The master toctree document. +master_doc = 'index' + +# The language for content autogenerated by Sphinx. Refer to documentation +# for a list of supported languages. +# +# This is also used if you do content translation via gettext catalogs. +# Usually you set "language" from the command line for these cases. +language = u'en_US' + +# List of patterns, relative to source directory, that match files and +# directories to ignore when looking for source files. +# This pattern also affects html_static_path and html_extra_path. +exclude_patterns = [] + +# The name of the Pygments (syntax highlighting) style to use. +pygments_style = None + +# -- Options for HTML output ------------------------------------------------- + +# The theme to use for HTML and HTML Help pages. See the documentation for +# a list of builtin themes. +# +html_theme = 'sphinx_rtd_theme' + +# Theme options are theme-specific and customize the look and feel of a theme +# further. For a list of options available for each theme, see the +# documentation. +# +# html_theme_options = {} + +# Add any paths that contain custom static files (such as style sheets) here, +# relative to this directory. They are copied after the builtin static files, +# so a file named "default.css" will overwrite the builtin "default.css". +html_static_path = ['_static'] + +# Custom sidebar templates, must be a dictionary that maps document names +# to template names. +# +# The default sidebars (for documents that don't match any pattern) are +# defined by theme itself. Builtin themes are using these templates by +# default: ``['localtoc.html', 'relations.html', 'sourcelink.html', +# 'searchbox.html']``. +# +# html_sidebars = {} + +# -- Options for HTMLHelp output --------------------------------------------- + +# Output file base name for HTML help builder. +htmlhelp_basename = 'PaddleSlimdoc' + +# -- Options for LaTeX output ------------------------------------------------ + +latex_elements = { + # The paper size ('letterpaper' or 'a4paper'). + # + # 'papersize': 'letterpaper', + + # The font size ('10pt', '11pt' or '12pt'). + # + # 'pointsize': '10pt', + + # Additional stuff for the LaTeX preamble. + # + # 'preamble': '', + + # Latex figure (float) alignment + # + # 'figure_align': 'htbp', +} + +# Grouping the document tree into LaTeX files. List of tuples +# (source start file, target name, title, +# author, documentclass [howto, manual, or own class]). +latex_documents = [(master_doc, 'PaddleSlim.tex', u'PaddleSlim Documentation', + u'paddleslim', 'manual'), ] + +# -- Options for manual page output ------------------------------------------ + +# One entry per manual page. List of tuples +# (source start file, name, description, authors, manual section). +man_pages = [(master_doc, 'paddleslim', u'PaddleSlim Documentation', [author], + 1)] + +# -- Options for Texinfo output ---------------------------------------------- + +# Grouping the document tree into Texinfo files. List of tuples +# (source start file, target name, title, author, +# dir menu entry, description, category) +texinfo_documents = [ + (master_doc, 'PaddleSlim', u'PaddleSlim Documentation', author, + 'PaddleSlim', 'One line description of project.', 'Miscellaneous'), +] + +# -- Options for Epub output ------------------------------------------------- + +# Bibliographic Dublin Core info. +epub_title = project + +# The unique identifier of the text. This can be a ISBN number +# or the project homepage. +# +# epub_identifier = '' + +# A unique identification for the text. +# +# epub_uid = '' + +# A list of files that should not be packed into the epub file. +epub_exclude_files = ['search.html'] + +# -- Extension configuration ------------------------------------------------- diff --git a/docs/en/index.rst b/docs/en/index.rst new file mode 100644 index 0000000000000000000000000000000000000000..21bdecb667343be7e4afddd1e8b07b2ee84eac4e --- /dev/null +++ b/docs/en/index.rst @@ -0,0 +1,17 @@ +.. PaddleSlim documentation master file, created by + sphinx-quickstart on Wed Feb 5 14:04:52 2020. + You can adapt this file completely to your liking, but it should at least + contain the root `toctree` directive. + +Index +============== + +.. toctree:: + :maxdepth: 1 + + intro_en.md + install_en.md + quick_start/index_en + tutorials/index_en + api_en/index_en + model_zoo_en.md diff --git a/docs/en/install_en.md b/docs/en/install_en.md new file mode 100644 index 0000000000000000000000000000000000000000..9d0eedba8ea361e4529eccdc538f0906a78c4000 --- /dev/null +++ b/docs/en/install_en.md @@ -0,0 +1,22 @@ +# Install + +Please ensure you have installed PaddlePaddle1.7+. [How to install PaddlePaddle](https://www.paddlepaddle.org.cn/install/quick)。 + + +- Install by pip + +```bash +pip install paddleslim -i https://pypi.org/simple +``` + +- Install from source + +```bash +git clone https://github.com/PaddlePaddle/PaddleSlim.git +cd PaddleSlim +python setup.py install +``` + +- History packages + +History packages is available in [pypi.org](https://pypi.org/project/paddleslim/#history). diff --git a/docs/en/intro_en.md b/docs/en/intro_en.md new file mode 100644 index 0000000000000000000000000000000000000000..524c826f907f21863a48f331b38a04745d61c2d1 --- /dev/null +++ b/docs/en/intro_en.md @@ -0,0 +1,85 @@ +# Introduction + +PaddleSlim is a toolkit for model compression. It contains a collection of compression strategies, such as pruning, fixed point quantization, knowledge distillation, hyperparameter searching and neural architecture search. + +PaddleSlim provides solutions of compression on computer vision models, such as image classification, object detection and semantic segmentation. Meanwhile, PaddleSlim Keeps exploring advanced compression strategies for language model. Furthermore, benckmark of compression strategies on some open tasks is available for your reference. + +PaddleSlim also provides auxiliary and primitive API for developer and researcher to survey, implement and apply the method in latest papers. PaddleSlim will support developer in ability of framework and technology consulting. + +## Features + +### Pruning + + - Uniform pruning of convolution + - Sensitivity-based prunning + - Automated pruning based evolution search strategy + - Support pruning of various deep architectures such as VGG, ResNet, and MobileNet. + - Support self-defined range of pruning, i.e., layers to be pruned. + +### Fixed Point Quantization + + - **Training aware** + - Dynamic strategy: During inference, we quantize models with hyperparameters dynamically estimated from small batches of samples. + - Static strategy: During inference, we quantize models with the same hyperparameters estimated from training data. + - Support layer-wise and channel-wise quantization. + - **Post training** + +### Knowledge Distillation + + - **Naive knowledge distillation:** transfers dark knowledge by merging the teacher and student model into the same Program + - **Paddle large-scale scalable knowledge distillation framework Pantheon:** a universal solution for knowledge distillation, more flexible than the naive knowledge distillation, and easier to scale to the large-scale applications. + + - Decouple the teacher and student models --- they run in different processes in the same or different nodes, and transfer knowledge via TCP/IP ports or local files; + - Friendly to assemble multiple teacher models and each of them can work in either online or offline mode independently; + - Merge knowledge from different teachers and make batch data for the student model automatically; + - Support the large-scale knowledge prediction of teacher models on multiple devices. + +### Neural Architecture Search + + - Neural architecture search based on evolution strategy. + - Support distributed search. + - One-Shot neural architecture search. + - Differentiable Architecture Search. + - Support FLOPs and latency constrained search. + - Support the latency estimation on different hardware and platforms. + +## Performance + +### Image Classification + +Dataset: ImageNet2012; Model: MobileNetV1; + +|Method |Accuracy(baseline: 70.91%) |Model Size(baseline: 17.0M)| +|:---:|:---:|:---:| +| Knowledge Distillation(ResNet50)| **+1.06%** | | +| Knowledge Distillation(ResNet50) + int8 quantization |**+1.10%**| **-71.76%**| +| Pruning(FLOPs-50%) + int8 quantization|**-1.71%**|**-86.47%**| + + +### Object Detection + +#### Dataset: Pascal VOC; Model: MobileNet-V1-YOLOv3 + +| Method | mAP(baseline: 76.2%) | Model Size(baseline: 94MB) | +| :---------------------: | :------------: | :------------:| +| Knowledge Distillation(ResNet34-YOLOv3) | **+2.8%** | | +| Pruning(FLOPs -52.88%) | **+1.4%** | **-67.76%** | +|Knowledge DistillationResNet34-YOLOv3)+Pruning(FLOPs-69.57%)| **+2.6%**|**-67.00%**| + + +#### Dataset: COCO; Model: MobileNet-V1-YOLOv3 + +| Method | mAP(baseline: 29.3%) | Model Size| +| :---------------------: | :------------: | :------:| +| Knowledge Distillation(ResNet34-YOLOv3) | **+2.1%** |-| +| Knowledge Distillation(ResNet34-YOLOv3)+Pruning(FLOPs-67.56%) | **-0.3%** | **-66.90%**| + +### NAS + +Dataset: ImageNet2012; Model: MobileNetV2 + +|Device | Infer time cost | Top1 accuracy(baseline:71.90%) | +|:---------------:|:---------:|:--------------------:| +| RK3288 | **-23%** | +0.07% | +| Android cellphone | **-20%** | +0.16% | +| iPhone 6s | **-17%** | +0.32% | diff --git a/docs/en/model_zoo_en.md b/docs/en/model_zoo_en.md new file mode 100644 index 0000000000000000000000000000000000000000..89a83c635561c5d251d26dd5612f9aa0f0a42917 --- /dev/null +++ b/docs/en/model_zoo_en.md @@ -0,0 +1,251 @@ +# Model Zoo + +## 1. Image Classification + +Dataset:ImageNet1000 + +### 1.1 Quantization + +| Model | Method | Top-1/Top-5 Acc | Model Size(MB) | TensorRT latency(V100, ms) | Download | +|:--:|:---:|:--:|:--:|:--:|:--:| +|MobileNetV1|-|70.99%/89.68%| 17 | -| [model](http://paddle-imagenet-models-name.bj.bcebos.com/MobileNetV1_pretrained.tar) | +|MobileNetV1|quant_post|70.18%/89.25% (-0.81%/-0.43%)| 4.4 | - | [model](https://paddlemodels.bj.bcebos.com/PaddleSlim/MobileNetV1_quant_post.tar) | +|MobileNetV1|quant_aware|70.60%/89.57% (-0.39%/-0.11%)| 4.4 | -| [model](https://paddlemodels.bj.bcebos.com/PaddleSlim/MobileNetV1_quant_aware.tar) | +| MobileNetV2 | - |72.15%/90.65%| 15 | - | [model](https://paddle-imagenet-models-name.bj.bcebos.com/MobileNetV2_pretrained.tar) | +| MobileNetV2 | quant_post | 71.15%/90.11% (-1%/-0.54%)| 4.0 | - | [model](https://paddlemodels.bj.bcebos.com/PaddleSlim/MobileNetV2_quant_post.tar) | +| MobileNetV2 | quant_aware |72.05%/90.63% (-0.1%/-0.02%)| 4.0 | - | [model](https://paddlemodels.bj.bcebos.com/PaddleSlim/MobileNetV2_quant_aware.tar) | +|ResNet50|-|76.50%/93.00%| 99 | 2.71 | [model](http://paddle-imagenet-models-name.bj.bcebos.com/ResNet50_pretrained.tar) | +|ResNet50|quant_post|76.33%/93.02% (-0.17%/+0.02%)| 25.1| 1.19 | [model](https://paddlemodels.bj.bcebos.com/PaddleSlim/ResNet50_quant_post.tar) | +|ResNet50|quant_aware| 76.48%/93.11% (-0.02%/+0.11%)| 25.1 | 1.17 | [model](https://paddlemodels.bj.bcebos.com/PaddleSlim/ResNet50_quant_awre.tar) | + +PaddleLite latency(ms) + +| Device | Model | Method | armv7 Thread 1 | armv7 Thread 2 | armv7 Thread 4 | armv8 Thread 1 | armv8 Thread 2 | armv8 Thread 4 | +| ------- | ----------- | ------------- | -------------- | -------------- | -------------- | -------------- | -------------- | -------------- | +| Qualcomm 835 | MobileNetV1 | FP32 baseline | 96.1942 | 53.2058 | 32.4468 | 88.4955 | 47.95 | 27.5189 | +| Qualcomm 835 | MobileNetV1 | quant_aware | 60.8186 | 32.1931 | 16.4275 | 56.4311 | 29.5446 | 15.1053 | +| Qualcomm 835 | MobileNetV1 | quant_post | 60.5615 | 32.4016 | 16.6596 | 56.5266 | 29.7178 | 15.1459 | +| Qualcomm 835 | MobileNetV2 | FP32 baseline | 65.715 | 38.1346 | 25.155 | 61.3593 | 36.2038 | 22.849 | +| Qualcomm 835 | MobileNetV2 | quant_aware | 48.3655 | 30.2021 | 21.9303 | 46.1487 | 27.3146 | 18.3053 | +| Qualcomm 835 | MobileNetV2 | quant_post | 48.3495 | 30.3069 | 22.1506 | 45.8715 | 27.4105 | 18.2223 | +| Qualcomm 835 | ResNet50 | FP32 baseline | 526.811 | 319.6486 | 205.8345 | 506.1138 | 335.1584 | 214.8936 | +| Qualcomm 835 | ResNet50 | quant_aware | 475.4538 | 256.8672 | 139.699 | 461.7344 | 247.9506 | 145.9847 | +| Qualcomm 835 | ResNet50 | quant_post | 476.0507 | 256.5963 | 139.7266 | 461.9176 | 248.3795 | 149.353 | +| Qualcomm 855 | MobileNetV1 | FP32 baseline | 33.5086 | 19.5773 | 11.7534 | 31.3474 | 18.5382 | 10.0811 | +| Qualcomm 855 | MobileNetV1 | quant_aware | 36.7067 | 21.628 | 11.0372 | 14.0238 | 8.199 | 4.2588 | +| Qualcomm 855 | MobileNetV1 | quant_post | 37.0498 | 21.7081 | 11.0779 | 14.0947 | 8.1926 | 4.2934 | +| Qualcomm 855 | MobileNetV2 | FP32 baseline | 25.0396 | 15.2862 | 9.6609 | 22.909 | 14.1797 | 8.8325 | +| Qualcomm 855 | MobileNetV2 | quant_aware | 28.1583 | 18.3317 | 11.8103 | 16.9158 | 11.1606 | 7.4148 | +| Qualcomm 855 | MobileNetV2 | quant_post | 28.1631 | 18.3917 | 11.8333 | 16.9399 | 11.1772 | 7.4176 | +| Qualcomm 855 | ResNet50 | FP32 baseline | 185.3705 | 113.0825 | 87.0741 | 177.7367 | 110.0433 | 74.4114 | +| Qualcomm 855 | ResNet50 | quant_aware | 327.6883 | 202.4536 | 106.243 | 243.5621 | 150.0542 | 78.4205 | +| Qualcomm 855 | ResNet50 | quant_post | 328.2683 | 201.9937 | 106.744 | 242.6397 | 150.0338 | 79.8659 | +| Kirin 970 | MobileNetV1 | FP32 baseline | 101.2455 | 56.4053 | 35.6484 | 94.8985 | 51.7251 | 31.9511 | +| Kirin 970 | MobileNetV1 | quant_aware | 62.5012 | 32.1863 | 16.6018 | 57.7477 | 29.2116 | 15.0703 | +| Kirin 970 | MobileNetV1 | quant_post | 62.4412 | 32.2585 | 16.6215 | 57.825 | 29.2573 | 15.1206 | +| Kirin 970 | MobileNetV2 | FP32 baseline | 70.4176 | 42.0795 | 25.1939 | 68.9597 | 39.2145 | 22.6617 | +| Kirin 970 | MobileNetV2 | quant_aware | 52.9961 | 31.5323 | 22.1447 | 49.4858 | 28.0856 | 18.7287 | +| Kirin 970 | MobileNetV2 | quant_post | 53.0961 | 31.7987 | 21.8334 | 49.383 | 28.2358 | 18.3642 | +| Kirin 970 | ResNet50 | FP32 baseline | 586.8943 | 344.0858 | 228.2293 | 573.3344 | 351.4332 | 225.8006 | +| Kirin 970 | ResNet50 | quant_aware | 488.361 | 260.1697 | 142.416 | 479.5668 | 249.8485 | 138.1742 | +| Kirin 970 | ResNet50 | quant_post | 489.6188 | 258.3279 | 142.6063 | 480.0064 | 249.5339 | 138.5284 | + +### 1.2 Pruning + +PaddleLite: + +env: Qualcomm SnapDragon 845 + armv8 + +criterion: time cost in Thread1/Thread2/Thread4 + +PaddleLite version: v2.3 + + +|Model | Method | Top-1/Top-5 Acc | ModelSize(MB) | GFLOPs |PaddleLite cost(ms)|TensorRT speed(FPS)| download | +|:--:|:---:|:--:|:--:|:--:|:--:|:--:|:--:| +| MobileNetV1 | Baseline | 70.99%/89.68% | 17 | 1.11 |66.052\35.8014\19.5762|-| [download](http://paddle-imagenet-models-name.bj.bcebos.com/MobileNetV1_pretrained.tar) | +| MobileNetV1 | uniform -50% | 69.4%/88.66% (-1.59%/-1.02%) | 9 | 0.56 | 33.5636\18.6834\10.5076|-|[download](https://paddlemodels.bj.bcebos.com/PaddleSlim/MobileNetV1_uniform-50.tar) | +| MobileNetV1 | sensitive -30% | 70.4%/89.3% (-0.59%/-0.38%) | 12 | 0.74 | 46.5958\25.3098\13.6982|-|[download](https://paddlemodels.bj.bcebos.com/PaddleSlim/MobileNetV1_sensitive-30.tar) | +| MobileNetV1 | sensitive -50% | 69.8% / 88.9% (-1.19%/-0.78%) | 9 | 0.56 |37.9892\20.7882\11.3144|-| [download](https://paddlemodels.bj.bcebos.com/PaddleSlim/MobileNetV1_sensitive-50.tar) | +| MobileNetV2 | - | 72.15%/90.65% | 15 | 0.59 |41.7874\23.375\13.3998|-| [download](https://paddle-imagenet-models-name.bj.bcebos.com/MobileNetV2_pretrained.tar) | +| MobileNetV2 | uniform -50% | 65.79%/86.11% (-6.35%/-4.47%) | 11 | 0.296 |23.8842\13.8698\8.5572|-| [download](https://paddlemodels.bj.bcebos.com/PaddleSlim/MobileNetV2_uniform-50.tar) | +| ResNet34 | - | 74.57%/92.14% | 84 | 7.36 |217.808\139.943\96.7504|342.32| [download](https://paddle-imagenet-models-name.bj.bcebos.com/ResNet34_pretrained.tar) | +| ResNet34 | uniform -50% | 70.99%/89.95% (-3.58%/-2.19%) | 41 | 3.67 |114.787\75.0332\51.8438|452.41| [download](https://paddlemodels.bj.bcebos.com/PaddleSlim/ResNet34_uniform-50.tar) | +| ResNet34 | auto -55.05% | 70.24%/89.63% (-4.33%/-2.51%) | 33 | 3.31 |105.924\69.3222\48.0246|457.25| [download](https://paddlemodels.bj.bcebos.com/PaddleSlim/ResNet34_auto-55.tar) | + +### 1.3 Distillation + +| Model | Method | Top-1/Top-5 Acc | Model Size(MB) | Download | +|:--:|:---:|:--:|:--:|:--:| +| MobileNetV1 | student | 70.99%/89.68% | 17 | [model](http://paddle-imagenet-models-name.bj.bcebos.com/MobileNetV1_pretrained.tar) | +|ResNet50_vd|teacher|79.12%/94.44%| 99 | [model](https://paddle-imagenet-models-name.bj.bcebos.com/ResNet50_vd_pretrained.tar) | +|MobileNetV1|ResNet50_vd[1](#trans1) distill|72.77%/90.68% (+1.78%/+1.00%)| 17 | [model](https://paddlemodels.bj.bcebos.com/PaddleSlim/MobileNetV1_distilled.tar) | +| MobileNetV2 | student | 72.15%/90.65% | 15 | [model](https://paddle-imagenet-models-name.bj.bcebos.com/MobileNetV2_pretrained.tar) | +| MobileNetV2 | ResNet50_vd distill | 74.28%/91.53% (+2.13%/+0.88%) | 15 | [model](https://paddlemodels.bj.bcebos.com/PaddleSlim/MobileNetV2_distilled.tar) | +| ResNet50 | student | 76.50%/93.00% | 99 | [model](http://paddle-imagenet-models-name.bj.bcebos.com/ResNet50_pretrained.tar) | +|ResNet101|teacher|77.56%/93.64%| 173 | [model](http://paddle-imagenet-models-name.bj.bcebos.com/ResNet101_pretrained.tar) | +| ResNet50 | ResNet101 distill | 77.29%/93.65% (+0.79%/+0.65%) | 99 | [model](https://paddlemodels.bj.bcebos.com/PaddleSlim/ResNet50_distilled.tar) | + +Note: The `_vd` suffix indicates that the pre-trained model uses Mixup. Please refer to the detailed introduction: [mixup: Beyond Empirical Risk Minimization](https://arxiv.org/abs/1710.09412) + + +### 1.4 NAS + +| Model | Method | Top-1/Top-5 Acc | Volume(MB) | GFLOPs | Download | +|:--:|:---:|:--:|:--:|:--:|:--:| +| MobileNetV2 | - | 72.15%/90.65% | 15 | 0.59 | [model](https://paddle-imagenet-models-name.bj.bcebos.com/MobileNetV2_pretrained.tar) | +| MobileNetV2_NAS | SANAS | 71.518%/90.208% (-0.632%/-0.442%) | 14 | 0.295 | [model](https://paddlemodels.cdn.bcebos.com/PaddleSlim/MobileNetV2_sanas.tar) | + +Dataset: Cifar10 +| Model | Method | Acc | Params(MB) | Download | +|:---:|:--:|:--:|:--:|:--:| +| Darts | - | 97.135% | 3.767 | - | +| Darts_SA(Based on Darts) | SANAS | 97.276%(+0.141%) | 3.344(-11.2%) | - | + +Note: The token of MobileNetV2_NAS is [4, 4, 5, 1, 1, 2, 1, 1, 0, 2, 6, 2, 0, 3, 4, 5, 0, 4, 5, 5, 1, 4, 8, 0, 0]. The token of Darts_SA is [5, 5, 0, 5, 5, 10, 7, 7, 5, 7, 7, 11, 10, 12, 10, 0, 5, 3, 10, 8]. + + +## 2. Object Detection + +### 2.1 Quantization + +Dataset: COCO 2017 + +| Model | Method | Dataset | Image/GPU | Input 608 Box AP | Input 416 Box AP | Input 320 Box AP | Model Size(MB) | TensorRT latency(V100, ms) | Download | +| :----------------------------: | :---------: | :----: | :-------: | :------------: | :------------: | :------------: | :------------: | :----------: |:----------: | +| MobileNet-V1-YOLOv3 | - | COCO | 8 | 29.3 | 29.3 | 27.1 | 95 | - | [model](https://paddlemodels.bj.bcebos.com/object_detection/yolov3_mobilenet_v1.tar) | +| MobileNet-V1-YOLOv3 | quant_post | COCO | 8 | 27.9 (-1.4)| 28.0 (-1.3) | 26.0 (-1.0) | 25 | - | [model](https://paddlemodels.bj.bcebos.com/PaddleSlim/yolov3_mobilenetv1_coco_quant_post.tar) | +| MobileNet-V1-YOLOv3 | quant_aware | COCO | 8 | 28.1 (-1.2)| 28.2 (-1.1) | 25.8 (-1.2) | 26.3 | - | [model](https://paddlemodels.bj.bcebos.com/PaddleSlim/yolov3_mobilenet_coco_quant_aware.tar) | +| R34-YOLOv3 | - | COCO | 8 | 36.2 | 34.3 | 31.4 | 162 | - | [model](https://paddlemodels.bj.bcebos.com/object_detection/yolov3_r34.tar) | +| R34-YOLOv3 | quant_post | COCO | 8 | 35.7 (-0.5) | - | - | 42.7 | - | [model](https://paddlemodels.bj.bcebos.com/PaddleSlim/yolov3_r34_coco_quant_post.tar) | +| R34-YOLOv3 | quant_aware | COCO | 8 | 35.2 (-1.0) | 33.3 (-1.0) | 30.3 (-1.1)| 44 | - | [model](https://paddlemodels.bj.bcebos.com/PaddleSlim/yolov3_r34_coco_quant_aware.tar) | +| R50-dcn-YOLOv3 obj365_pretrain | - | COCO | 8 | 41.4 | - | - | 177 | 18.56 |[model](https://paddlemodels.bj.bcebos.com/object_detection/yolov3_r50vd_dcn_obj365_pretrained_coco.tar) | +| R50-dcn-YOLOv3 obj365_pretrain | quant_aware | COCO | 8 | 40.6 (-0.8) | 37.5 | 34.1 | 66 | 14.64 | [model](https://paddlemodels.bj.bcebos.com/PaddleSlim/yolov3_r50vd_dcn_obj365_pretrained_coco_quant_aware.tar) | + + + +Dataset:WIDER-FACE + + + +| Model | Method | Image/GPU | Input Size | Easy/Medium/Hard | Model Size(MB) | Download | +| :------------: | :---------: | :-------: | :--------: | :-----------------------------: | :--------------: | :----------------------------------------------------------: | +| BlazeFace | - | 8 | 640 | 91.5/89.2/79.7 | 815 | [model](https://paddlemodels.bj.bcebos.com/object_detection/blazeface_original.tar) | +| BlazeFace | quant_post | 8 | 640 | 87.8/85.1/74.9 (-3.7/-4.1/-4.8) | 228 | [model](https://paddlemodels.bj.bcebos.com/PaddleSlim/blazeface_origin_quant_post.tar) | +| BlazeFace | quant_aware | 8 | 640 | 90.5/87.9/77.6 (-1.0/-1.3/-2.1) | 228 | [model](https://paddlemodels.bj.bcebos.com/PaddleSlim/blazeface_origin_quant_aware.tar) | +| BlazeFace-Lite | - | 8 | 640 | 90.9/88.5/78.1 | 711 | [model](https://paddlemodels.bj.bcebos.com/object_detection/blazeface_lite.tar) | +| BlazeFace-Lite | quant_post | 8 | 640 | 89.4/86.7/75.7 (-1.5/-1.8/-2.4) | 211 | [model]((https://paddlemodels.bj.bcebos.com/PaddleSlim/blazeface_lite_quant_post.tar)) | +| BlazeFace-Lite | quant_aware | 8 | 640 | 89.7/87.3/77.0 (-1.2/-1.2/-1.1) | 211 | [model](https://paddlemodels.bj.bcebos.com/PaddleSlim/blazeface_lite_quant_aware.tar) | +| BlazeFace-NAS | - | 8 | 640 | 83.7/80.7/65.8 | 244 | [model](https://paddlemodels.bj.bcebos.com/object_detection/blazeface_nas.tar) | +| BlazeFace-NAS | quant_post | 8 | 640 | 81.6/78.3/63.6 (-2.1/-2.4/-2.2) | 71 | [model](https://paddlemodels.bj.bcebos.com/PaddleSlim/blazeface_nas_quant_post.tar) | +| BlazeFace-NAS | quant_aware | 8 | 640 | 83.1/79.7/64.2 (-0.6/-1.0/-1.6) | 71 | [model](https://paddlemodels.bj.bcebos.com/PaddleSlim/blazeface_nas_quant_aware.tar) | + +### 2.2 Pruning + +Dataset:Pasacl VOC & COCO 2017 + +PaddleLite: + +env: Qualcomm SnapDragon 845 + armv8 + +criterion: time cost in Thread1/Thread2/Thread4 + +PaddleLite version: v2.3 + +| Model | Method | Dataset | Image/GPU | Input 608 Box AP | Input 416 Box AP | Input 320 Box AP | Model Size(MB) | GFLOPs (608*608) | PaddleLite cost(ms)(608*608) | TensorRT speed(FPS)(608*608) | Download | +| :----------------------------: | :---------------: | :--------: | :-------: | :--------------: | :--------------: | :--------------: | :------------: | :--------------: | :--------------: | :--------------: | :----------------------------: | +| MobileNet-V1-YOLOv3 | Baseline | Pascal VOC | 8 | 76.2 | 76.7 | 75.3 | 94 | 40.49 | 1238\796.943\520.101 |60.40| [model](https://paddlemodels.bj.bcebos.com/object_detection/yolov3_mobilenet_v1_voc.tar) | +| MobileNet-V1-YOLOv3 | sensitive -52.88% | Pascal VOC | 8 | 77.6 (+1.4) | 77.7 (1.0) | 75.5 (+0.2) | 31 | 19.08 | 602.497\353.759\222.427 |99.36| [model](https://paddlemodels.bj.bcebos.com/PaddleSlim/yolov3_mobilenet_v1_voc_prune.tar) | +| MobileNet-V1-YOLOv3 | - | COCO | 8 | 29.3 | 29.3 | 27.0 | 95 | 41.35 |-|-| [model](https://paddlemodels.bj.bcebos.com/object_detection/yolov3_mobilenet_v1.tar) | +| MobileNet-V1-YOLOv3 | sensitive -51.77% | COCO | 8 | 26.0 (-3.3) | 25.1 (-4.2) | 22.6 (-4.4) | 32 | 19.94 |-|73.93| [model](https://paddlemodels.bj.bcebos.com/PaddleSlim/yolov3_mobilenet_v1_prune.tar) | +| R50-dcn-YOLOv3 | - | COCO | 8 | 39.1 | - | - | 177 | 89.60 |-|27.68| [model](https://paddlemodels.bj.bcebos.com/object_detection/yolov3_r50vd_dcn.tar) | +| R50-dcn-YOLOv3 | sensitive -9.37% | COCO | 8 | 39.3 (+0.2) | - | - | 150 | 81.20 |-|30.08| [model](https://paddlemodels.bj.bcebos.com/PaddleSlim/yolov3_r50vd_dcn_prune.tar) | +| R50-dcn-YOLOv3 | sensitive -24.68% | COCO | 8 | 37.3 (-1.8) | - | - | 113 | 67.48 |-|34.32| [model](https://paddlemodels.bj.bcebos.com/PaddleSlim/yolov3_r50vd_dcn_prune578.tar) | +| R50-dcn-YOLOv3 obj365_pretrain | - | COCO | 8 | 41.4 | - | - | 177 | 89.60 |-|-| [model](https://paddlemodels.bj.bcebos.com/object_detection/yolov3_r50vd_dcn_obj365_pretrained_coco.tar) | +| R50-dcn-YOLOv3 obj365_pretrain | sensitive -9.37% | COCO | 8 | 40.5 (-0.9) | - | - | 150 | 81.20 |-|-| [model](https://paddlemodels.bj.bcebos.com/PaddleSlim/yolov3_r50vd_dcn_obj365_pretrained_coco_prune.tar) | +| R50-dcn-YOLOv3 obj365_pretrain | sensitive -24.68% | COCO | 8 | 37.8 (-3.3) | - | - | 113 | 67.48 |-|-| [model](https://paddlemodels.bj.bcebos.com/PaddleSlim/yolov3_r50vd_dcn_obj365_pretrained_coco_prune578.tar) | + +### 2.3 Distillation + +Dataset:Pasacl VOC & COCO 2017 + + +| Model | Method | Dataset | Image/GPU | Input 608 Box AP | Input 416 Box AP | Input 320 Box AP | Model Size(MB) | Download | +| :-----------------: | :---------------------: | :--------: | :-------: | :--------------: | :--------------: | :--------------: | :--------------: | :----------------------------------------------------------: | +| MobileNet-V1-YOLOv3 | - | Pascal VOC | 8 | 76.2 | 76.7 | 75.3 | 94 | [model](https://paddlemodels.bj.bcebos.com/object_detection/yolov3_mobilenet_v1_voc.tar) | +| ResNet34-YOLOv3 | - | Pascal VOC | 8 | 82.6 | 81.9 | 80.1 | 162 | [model](https://paddlemodels.bj.bcebos.com/object_detection/yolov3_r34_voc.tar) | +| MobileNet-V1-YOLOv3 | ResNet34-YOLOv3 distill | Pascal VOC | 8 | 79.0 (+2.8) | 78.2 (+1.5) | 75.5 (+0.2) | 94 | [model](https://paddlemodels.bj.bcebos.com/PaddleSlim/yolov3_mobilenetv1_voc_distilled.tar) | +| MobileNet-V1-YOLOv3 | - | COCO | 8 | 29.3 | 29.3 | 27.0 | 95 | [model](https://paddlemodels.bj.bcebos.com/object_detection/yolov3_mobilenet_v1.tar) | +| ResNet34-YOLOv3 | - | COCO | 8 | 36.2 | 34.3 | 31.4 | 163 | [model](https://paddlemodels.bj.bcebos.com/object_detection/yolov3_r34.tar) | +| MobileNet-V1-YOLOv3 | ResNet34-YOLOv3 distill | COCO | 8 | 31.4 (+2.1) | 30.0 (+0.7) | 27.1 (+0.1) | 95 | [model](https://paddlemodels.bj.bcebos.com/PaddleSlim/yolov3_mobilenetv1_coco_distilled.tar) | + + +### 2.4 NAS + +Dataset: WIDER-FACE + +| Model | Method | Image/GPU | Input size | Easy/Medium/Hard | volume(KB) | latency(ms)| Download | +| :------------: | :---------: | :-------: | :------: | :-----------------------------: | :------------: | :------------: | :----------------------------------------------------------: | +| BlazeFace | - | 8 | 640 | 91.5/89.2/79.7 | 815 | 71.862 | [model](https://paddlemodels.bj.bcebos.com/object_detection/blazeface_original.tar) | +| BlazeFace-NAS | - | 8 | 640 | 83.7/80.7/65.8 | 244 | 21.117 |[model](https://paddlemodels.bj.bcebos.com/object_detection/blazeface_nas.tar) | +| BlazeFace-NASV2 | SANAS | 8 | 640 | 87.0/83.7/68.5 | 389 | 22.558 | [model](https://paddlemodels.bj.bcebos.com/object_detection/blazeface_nas2.tar) | + +Note: latency is based on latency_855.txt, the file is test on 855 by PaddleLite。The config of BlazeFace-NASV2 is in [there](https://github.com/PaddlePaddle/PaddleDetection/blob/master/configs/face_detection/blazeface_nas_v2.yml). + + +## 3. Image Segmentation +Dataset:Cityscapes + +### 3.1 Quantization + +| Model | Method | mIoU | Model Size(MB) | Download | +| :--------------------: | :---------: | :-----------: | :--------------: | :----------------------------------------------------------: | +| DeepLabv3+/MobileNetv1 | - | 63.26 | 6.6 | [model](https://paddlemodels.bj.bcebos.com/PaddleSlim/deeplabv3_mobilenetv1.tar ) | +| DeepLabv3+/MobileNetv1 | quant_post | 58.63 (-4.63) | 1.8 | [model](https://paddlemodels.bj.bcebos.com/PaddleSlim/deeplabv3_mobilenetv1_2049x1025_quant_post.tar) | +| DeepLabv3+/MobileNetv1 | quant_aware | 62.03 (-1.23) | 1.8 | [model](https://paddlemodels.bj.bcebos.com/PaddleSlim/deeplabv3_mobilenetv1_2049x1025_quant_aware.tar) | +| DeepLabv3+/MobileNetv2 | - | 69.81 | 7.4 | [model](https://paddleseg.bj.bcebos.com/models/mobilenet_cityscapes.tgz) | +| DeepLabv3+/MobileNetv2 | quant_post | 67.59 (-2.22) | 2.1 | [model](https://paddlemodels.bj.bcebos.com/PaddleSlim/deeplabv3_mobilenetv2_2049x1025_quant_post.tar) | +| DeepLabv3+/MobileNetv2 | quant_aware | 68.33 (-1.48) | 2.1 | [model](https://paddlemodels.bj.bcebos.com/PaddleSlim/deeplabv3_mobilenetv2_2049x1025_quant_aware.tar) | + +Image segmentation model PaddleLite latency (ms), input size 769x769 + +| Device | Model | Method | armv7 Thread 1 | armv7 Thread 2 | armv7 Thread 4 | armv8 Thread 1 | armv8 Thread 2 | armv8 Thread 4 | +| ------------ | ---------------------- | ------------- | -------------- | -------------- | -------------- | -------------- | -------------- | -------------- | +| Qualcomm 835 | Deeplabv3- MobileNetV1 | FP32 baseline | 1227.9894 | 734.1922 | 527.9592 | 1109.96 | 699.3818 | 479.0818 | +| Qualcomm 835 | Deeplabv3- MobileNetV1 | quant_aware | 848.6544 | 512.785 | 382.9915 | 752.3573 | 455.0901 | 307.8808 | +| Qualcomm 835 | Deeplabv3- MobileNetV1 | quant_post | 840.2323 | 510.103 | 371.9315 | 748.9401 | 452.1745 | 309.2084 | +| Qualcomm 835 | Deeplabv3-MobileNetV2 | FP32 baseline | 1282.8126 | 793.2064 | 653.6538 | 1193.9908 | 737.1827 | 593.4522 | +| Qualcomm 835 | Deeplabv3-MobileNetV2 | quant_aware | 976.0495 | 659.0541 | 513.4279 | 892.1468 | 582.9847 | 484.7512 | +| Qualcomm 835 | Deeplabv3-MobileNetV2 | quant_post | 981.44 | 658.4969 | 538.6166 | 885.3273 | 586.1284 | 484.0018 | +| Qualcomm 855 | Deeplabv3- MobileNetV1 | FP32 baseline | 568.8748 | 339.8578 | 278.6316 | 420.6031 | 281.3197 | 217.5222 | +| Qualcomm 855 | Deeplabv3- MobileNetV1 | quant_aware | 608.7578 | 347.2087 | 260.653 | 241.2394 | 177.3456 | 143.9178 | +| Qualcomm 855 | Deeplabv3- MobileNetV1 | quant_post | 609.0142 | 347.3784 | 259.9825 | 239.4103 | 180.1894 | 139.9178 | +| Qualcomm 855 | Deeplabv3-MobileNetV2 | FP32 baseline | 639.4425 | 390.1851 | 322.7014 | 477.7667 | 339.7411 | 262.2847 | +| Qualcomm 855 | Deeplabv3-MobileNetV2 | quant_aware | 703.7275 | 497.689 | 417.1296 | 394.3586 | 300.2503 | 239.9204 | +| Qualcomm 855 | Deeplabv3-MobileNetV2 | quant_post | 705.7589 | 474.4076 | 427.2951 | 394.8352 | 297.4035 | 264.6724 | +| Kirin 970 | Deeplabv3- MobileNetV1 | FP32 baseline | 1682.1792 | 1437.9774 | 1181.0246 | 1261.6739 | 1068.6537 | 690.8225 | +| Kirin 970 | Deeplabv3- MobileNetV1 | quant_aware | 1062.3394 | 1248.1014 | 878.3157 | 774.6356 | 710.6277 | 528.5376 | +| Kirin 970 | Deeplabv3- MobileNetV1 | quant_post | 1109.1917 | 1339.6218 | 866.3587 | 771.5164 | 716.5255 | 500.6497 | +| Kirin 970 | Deeplabv3-MobileNetV2 | FP32 baseline | 1771.1301 | 1746.0569 | 1222.4805 | 1448.9739 | 1192.4491 | 760.606 | +| Kirin 970 | Deeplabv3-MobileNetV2 | quant_aware | 1320.2905 | 921.4522 | 676.0732 | 1145.8801 | 821.5685 | 590.1713 | +| Kirin 970 | Deeplabv3-MobileNetV2 | quant_post | 1320.386 | 918.5328 | 672.2481 | 1020.753 | 820.094 | 591.4114 | + + + + + +### 3.2 Pruning + +PaddleLite: + +env: Qualcomm SnapDragon 845 + armv8 + +criterion: time cost in Thread1/Thread2/Thread4 + +PaddleLite version: v2.3 + +| Model | Method | mIoU | Model Size(MB) | GFLOPs | PaddleLite cost(ms) | TensorRT speed(FPS) | Download | +| :-------: | :---------------: | :-----------: | :--------------: | :----: | :--------------: | :----: | :-------------------: | +| fast-scnn | baseline | 69.64 | 11 | 14.41 | 1226.36\682.96\415.664 |39.53| [model](https://paddlemodels.bj.bcebos.com/PaddleSlim/fast_scnn_cityscape.tar) | +| fast-scnn | uniform -17.07% | 69.58 (-0.06) | 8.5 | 11.95 | 1140.37\656.612\415.888 |42.01| [model](https://paddlemodels.bj.bcebos.com/PaddleSlim/fast_scnn_cityscape_uniform-17.tar) | +| fast-scnn | sensitive -47.60% | 66.68 (-2.96) | 5.7 | 7.55 | 866.693\494.467\291.748 |51.48| [model](https://paddlemodels.bj.bcebos.com/PaddleSlim/fast_scnn_cityscape_sensitive-47.tar) | diff --git a/docs/en/quick_start/distillation_tutorial_en.md b/docs/en/quick_start/distillation_tutorial_en.md new file mode 100755 index 0000000000000000000000000000000000000000..7fb410655fe086fcee84e1f84a49c1e38609cde1 --- /dev/null +++ b/docs/en/quick_start/distillation_tutorial_en.md @@ -0,0 +1,115 @@ +# Knowledge Distillation for Image Classification + +In this tutorial, you will learn how to use knowledge distillation API of PaddleSlim +by a demo of MobileNetV1 model on MNIST dataset. This tutorial following workflow: + +1. Import dependency +2. Define student_program and teacher_program +3. Select feature maps +4. Merge program and add distillation loss +5. Train distillation model + +## 1. Import dependency + +PaddleSlim dependents on Paddle1.7. Please ensure that you have installed paddle correctly. Import Paddle and PaddleSlim as below: + +``` +import paddle +import paddle.fluid as fluid +import paddleslim as slim +``` + +## 2. Define student_program and teacher_program + +This tutorial trains and verifies distillation model on the MNIST dataset. The input image shape is `[1, 28, 28] `and the number of output categories is 10. +Select `ResNet50` as the teacher to perform distillation training on the students of the` MobileNet` architecture. + +```python +model = slim.models.MobileNet() +student_program = fluid.Program() +student_startup = fluid.Program() +with fluid.program_guard(student_program, student_startup): + image = fluid.data( + name='image', shape=[None] + [1, 28, 28], dtype='float32') + label = fluid.data(name='label', shape=[None, 1], dtype='int64') + out = model.net(input=image, class_dim=10) + cost = fluid.layers.cross_entropy(input=out, label=label) + avg_cost = fluid.layers.mean(x=cost) + acc_top1 = fluid.layers.accuracy(input=out, label=label, k=1) + acc_top5 = fluid.layers.accuracy(input=out, label=label, k=5) +``` + + + +```python +model = slim.models.ResNet50() +teacher_program = fluid.Program() +teacher_startup = fluid.Program() +with fluid.program_guard(teacher_program, teacher_startup): + with fluid.unique_name.guard(): + image = fluid.data( + name='image', shape=[None] + [1, 28, 28], dtype='float32') + predict = teacher_model.net(image, class_dim=10) +exe = fluid.Executor(fluid.CPUPlace()) +exe.run(teacher_startup) +``` + +## 3. Select feature maps + +We can use the student_program's list_vars method to observe all the Variables, and select one or more variables from it to fit the corresponding variables of the teacher. + +```python +# get all student variables +student_vars = [] +for v in student_program.list_vars(): + student_vars.append((v.name, v.shape)) +#uncomment the following lines to observe student's variables for distillation +#print("="*50+"student_model_vars"+"="*50) +#print(student_vars) + +# get all teacher variables +teacher_vars = [] +for v in teacher_program.list_vars(): + teacher_vars.append((v.name, v.shape)) +#uncomment the following lines to observe teacher's variables for distillation +#print("="*50+"teacher_model_vars"+"="*50) +#print(teacher_vars) +``` + +we can see that the shape of 'bn5c_branch2b.output.1.tmp_3' in the teacher_program and the 'depthwise_conv2d_11.tmp_0' of the student are the same and can form the distillation loss function. + +## 4. Merge program and add distillation loss +The merge operation adds all Variables and Ops in teacher_program to student_Program. At the same time, in order to avoid naming conflicts caused by variables with the same name in two programs, merge will also add a unified naming prefix **name_prefix** for Variables in teacher_program, which The default value is 'teacher_'_. + +In order to ensure that the data of the teacher network and the student network are the same, the merge operation also merges the input data layers of the two programs, so you need to specify a data layer name mapping ***data_name_map***, where key is the input data name of the teacher, and value Is student's. + +```python +data_name_map = {'image': 'image'} +main = slim.dist.merge(teacher_program, student_program, data_name_map, fluid.CPUPlace()) +with fluid.program_guard(student_program, student_startup): + l2_loss = slim.dist.l2_loss('teacher_bn5c_branch2b.output.1.tmp_3', 'depthwise_conv2d_11.tmp_0', student_program) + loss = l2_loss + avg_cost + opt = fluid.optimizer.Momentum(0.01, 0.9) + opt.minimize(loss) +exe.run(student_startup) +``` + +## 5. Train distillation model + +The package `paddle.dataset.mnist` of Paddle define the downloading and reading of MNIST dataset. +Define training data reader and test data reader as below: + +```python +train_reader = paddle.fluid.io.batch( + paddle.dataset.mnist.train(), batch_size=128, drop_last=True) +train_feeder = fluid.DataFeeder(['image', 'label'], fluid.CPUPlace(), student_program) +``` + +Excute following code to run an `epoch` training: + + +```python +for data in train_reader(): + acc1, acc5, loss_np = exe.run(student_program, feed=train_feeder.feed(data), fetch_list=[acc_top1.name, acc_top5.name, loss.name]) + print("Acc1: {:.6f}, Acc5: {:.6f}, Loss: {:.6f}".format(acc1.mean(), acc5.mean(), loss_np.mean())) +``` diff --git a/docs/en/quick_start/index_en.rst b/docs/en/quick_start/index_en.rst new file mode 100644 index 0000000000000000000000000000000000000000..bd4d8ec1907bd0d15eb055f86b4aa6032a3befa9 --- /dev/null +++ b/docs/en/quick_start/index_en.rst @@ -0,0 +1,12 @@ + +Quick Start +======== + +.. toctree:: + :maxdepth: 1 + + pruning_tutorial_en.md + nas_tutorial_en.md + quant_aware_tutorial_en.md + quant_post_static_tutorial_en.md + diff --git a/docs/en/quick_start/nas_tutorial_en.md b/docs/en/quick_start/nas_tutorial_en.md new file mode 100644 index 0000000000000000000000000000000000000000..040f46530cd61c815f633fdf478b368c0d88e07e --- /dev/null +++ b/docs/en/quick_start/nas_tutorial_en.md @@ -0,0 +1,155 @@ +# Nerual Architecture Search for Image Classification + +This tutorial shows how to use [API](../api/nas_api.md) about SANAS in PaddleSlim. We start experiment based on MobileNetV2 as example. The tutorial contains follow section. + +1. necessary imports +2. initial SANAS instance +3. define function about building program +4. define function about input data +5. define function about training +6. define funciton about evaluation +7. start search + 7.1 fetch model architecture + 7.2 build program + 7.3 define input data + 7.4 train model + 7.5 evaluate model + 7.6 reture score +8. full example + + +The following chapter describes each steps in order. + +## 1. import dependency +Please make sure that you haved installed Paddle correctly, then do the necessary imports. +```python +import paddle +import paddle.fluid as fluid +import paddleslim as slim +import numpy as np +``` + +## 2. initial SANAS instance +```python +sanas = slim.nas.SANAS(configs=[('MobileNetV2Space')], server_addr=("", 8337), save_checkpoint=None) +``` + +## 3. define function about building program +Build program about training and evaluation according to the model architecture. +```python +def build_program(archs): + train_program = fluid.Program() + startup_program = fluid.Program() + with fluid.program_guard(train_program, startup_program): + data = fluid.data(name='data', shape=[None, 3, 32, 32], dtype='float32') + label = fluid.data(name='label', shape=[None, 1], dtype='int64') + output = archs(data) + output = fluid.layers.fc(input=output, size=10) + + softmax_out = fluid.layers.softmax(input=output, use_cudnn=False) + cost = fluid.layers.cross_entropy(input=softmax_out, label=label) + avg_cost = fluid.layers.mean(cost) + acc_top1 = fluid.layers.accuracy(input=softmax_out, label=label, k=1) + acc_top5 = fluid.layers.accuracy(input=softmax_out, label=label, k=5) + test_program = fluid.default_main_program().clone(for_test=True) + + optimizer = fluid.optimizer.Adam(learning_rate=0.1) + optimizer.minimize(avg_cost) + + place = fluid.CPUPlace() + exe = fluid.Executor(place) + exe.run(startup_program) + return exe, train_program, test_program, (data, label), avg_cost, acc_top1, acc_top5 +``` + +## 4. define function about input data +The dataset we used is cifar10, and `paddle.dataset.cifar` in Paddle including the download and pre-read about cifar. +```python +def input_data(inputs): + train_reader = paddle.fluid.io.batch(paddle.reader.shuffle(paddle.dataset.cifar.train10(cycle=False), buf_size=1024),batch_size=256) + train_feeder = fluid.DataFeeder(inputs, fluid.CPUPlace()) + eval_reader = paddle.fluid.io.batch(paddle.dataset.cifar.test10(cycle=False), batch_size=256) + eval_feeder = fluid.DataFeeder(inputs, fluid.CPUPlace()) + return train_reader, train_feeder, eval_reader, eval_feeder +``` + +## 5. define function about training +Start training. +```python +def start_train(program, data_reader, data_feeder): + outputs = [avg_cost.name, acc_top1.name, acc_top5.name] + for data in data_reader(): + batch_reward = exe.run(program, feed=data_feeder.feed(data), fetch_list = outputs) + print("TRAIN: loss: {}, acc1: {}, acc5:{}".format(batch_reward[0], batch_reward[1], batch_reward[2])) +``` + +## 6. define funciton about evaluation +Start evaluating. +```python +def start_eval(program, data_reader, data_feeder): + reward = [] + outputs = [avg_cost.name, acc_top1.name, acc_top5.name] + for data in data_reader(): + batch_reward = exe.run(program, feed=data_feeder.feed(data), fetch_list = outputs) + reward_avg = np.mean(np.array(batch_reward), axis=1) + reward.append(reward_avg) + print("TEST: loss: {}, acc1: {}, acc5:{}".format(batch_reward[0], batch_reward[1], batch_reward[2])) + finally_reward = np.mean(np.array(reward), axis=0) + print("FINAL TEST: avg_cost: {}, acc1: {}, acc5: {}".format(finally_reward[0], finally_reward[1], finally_reward[2])) + return finally_reward +``` + +## 7. start search +The following steps describes how to get current model architecture and what need to do after get the model architecture. If you want to start a full example directly, please jump to Step 9. + +### 7.1 fetch model architecture +Get Next model architecture by `next_archs()`. +```python +archs = sanas.next_archs()[0] +``` + +### 7.2 build program +Get program according to the function in Step3 and model architecture from Step 7.1. +```python +exe, train_program, eval_program, inputs, avg_cost, acc_top1, acc_top5 = build_program(archs) +``` + +### 7.3 define input data +```python +train_reader, train_feeder, eval_reader, eval_feeder = input_data(inputs) +``` + +### 7.4 train model +Start training according to train program and data. +```python +start_train(train_program, train_reader, train_feeder) +``` +### 7.5 evaluate model +Start evaluation according to evaluation program and data. +```python +finally_reward = start_eval(eval_program, eval_reader, eval_feeder) +``` +### 7.6 reture score +``` +sanas.reward(float(finally_reward[1])) +``` + +## 8. full example +The following is a full example about neural architecture search, it uses FLOPs as constraint and includes 3 steps, it means train 3 model architectures which is satisfied constraint, and train 7 epoch for each model architecture. +```python +for step in range(3): + archs = sanas.next_archs()[0] + exe, train_program, eval_progarm, inputs, avg_cost, acc_top1, acc_top5 = build_program(archs) + train_reader, train_feeder, eval_reader, eval_feeder = input_data(inputs) + + current_flops = slim.analysis.flops(train_program) + if current_flops > 321208544: + continue + + for epoch in range(7): + start_train(train_program, train_reader, train_feeder) + + finally_reward = start_eval(eval_program, eval_reader, eval_feeder) + + sanas.reward(float(finally_reward[1])) +``` diff --git a/docs/en/quick_start/pruning_tutorial_en.md b/docs/en/quick_start/pruning_tutorial_en.md new file mode 100755 index 0000000000000000000000000000000000000000..9107a38b58255f08ce3da78fa18274c05d844604 --- /dev/null +++ b/docs/en/quick_start/pruning_tutorial_en.md @@ -0,0 +1,90 @@ +# Channel Pruning for Image Classification + +In this tutorial, you will learn how to use channel pruning API of PaddleSlim +by a demo of MobileNetV1 model on MNIST dataset. This tutorial following workflow: + +1. Import dependency +2. Build model +3. Prune model +4. Train pruned model + +## 1. Import dependency + +PaddleSlim dependents on Paddle1.7. Please ensure that you have installed paddle correctly. Import Paddle and PaddleSlim as below: + +``` +import paddle +import paddle.fluid as fluid +import paddleslim as slim +``` + +## 2. Build Model + +This section will build a classsification model based `MobileNetV1` for MNIST task. The shape of the input is `[1, 28, 28]` and the output number is 10. + +To make the code simple, we define a function in package `paddleslim.models` to build classification model. +Excute following code to build a model, + +``` +exe, train_program, val_program, inputs, outputs = + slim.models.image_classification("MobileNet", [1, 28, 28], 10, use_gpu=False) +``` + +>Note:The functions in paddleslim.models is just used in tutorials or demos. + +## 3. Prune model + +### 3.1 Compute FLOPs bofore pruning + +``` +FLOPs = slim.analysis.flops(train_program) +print("FLOPs: {}".format(FLOPs)) +``` + +### 3.2 Pruning + +The section will prune the parameters named `conv2_1_sep_weights` and `conv2_2_sep_weights` by 20% and 30%. + +``` +pruner = slim.prune.Pruner() +pruned_program, _, _ = pruner.prune( + train_program, + fluid.global_scope(), + params=["conv2_1_sep_weights", "conv2_2_sep_weights"], + ratios=[0.33] * 2, + place=fluid.CPUPlace()) +``` + +It will change the shapes of parameters defined in `train_program`. And the parameters` values stored in `fluid.global_scope()` will be pruned. + + +### 3.3 Compute FLOPs after pruning + +``` +FLOPs = paddleslim.analysis.flops(train_program) +print("FLOPs: {}".format(FLOPs)) +``` + +## 4. Train pruned model + +### 4.1 Define dataset + +To make you easily run this demo, it will training on MNIST dataset. The package `paddle.dataset.mnist` of Paddle defines the downloading and reading of MNIST dataset. +Define training data reader and test data reader as below: + +``` +import paddle.dataset.mnist as reader +train_reader = paddle.fluid.io.batch( + reader.train(), batch_size=128, drop_last=True) +train_feeder = fluid.DataFeeder(inputs, fluid.CPUPlace()) +``` + +### 4.2 Training + +Excute following code to run an `epoch` training: + +``` +for data in train_reader(): + acc1, acc5, loss = exe.run(pruned_program, feed=train_feeder.feed(data), fetch_list=outputs) + print(acc1, acc5, loss) +``` diff --git a/docs/en/quick_start/quant_aware_tutorial_en.md b/docs/en/quick_start/quant_aware_tutorial_en.md new file mode 100644 index 0000000000000000000000000000000000000000..8b169294ce1ae7bde64ed59035b40f7b2f588d0b --- /dev/null +++ b/docs/en/quick_start/quant_aware_tutorial_en.md @@ -0,0 +1,133 @@ +# Training-aware Quantization of image classification model - quick start + +This tutorial shows how to do training-aware quantization using [API](https://paddlepaddle.github.io/PaddleSlim/api_en/paddleslim.quant.html#paddleslim.quant.quanter.quant_aware) in PaddleSlim. We use MobileNetV1 to train image classification model as example. The tutorial contains follow sections: + +1. Necessary imports +2. Model architecture +3. Train normal model +4. Quantization +5. Train model after quantization +6. Save model after quantization + +## 1. Necessary imports +PaddleSlim depends on Paddle1.7. Please make true that you have installed Paddle correctly. Then do the necessary imports: + +```python +import paddle +import paddle.fluid as fluid +import paddleslim as slim +import numpy as np +``` + +## 2. Model architecture + +The section constructs a classification model, which use ``MobileNetV1`` and MNIST dataset. The model's input size is `[1, 28, 28]` and output size is 10. In order to show tutorial conveniently, we pre-defined a method to get image classification model in `paddleslim.models`. + +>note: The APIs in `paddleslim.models` are not formal inferface in PaddleSlim. They are defined to simplify the tutorial such as the definition of model structure and the construction of Program. + + +```python +exe, train_program, val_program, inputs, outputs = \ + slim.models.image_classification("MobileNet", [1, 28, 28], 10, use_gpu=True) +``` + +## 3. Train normal model + +The section shows how to define model inputs, train and test model. The reason for training the normal image classification model first is that the quantization model's training process is performed on the well-trained model. We add quantization and dequantization operators in well-trained model and finetune using smaller learning rate. + +### 3.1 input data definition + +To speed up training process, we select MNIST dataset to train image classification model. The API `paddle.dataset.mnist` in Paddle framework contains downloading and reading the images in dataset. + +```python +import paddle.dataset.mnist as reader +train_reader = paddle.fluid.io.batch( + reader.train(), batch_size=128, drop_last=True) +test_reader = paddle.fluid.io.batch( + reader.train(), batch_size=128, drop_last=True) +train_feeder = fluid.DataFeeder(inputs, fluid.CPUPlace()) +``` + +### 3.2 training model and testing + +Define functions to train and test model. We only need call the functions when formal model training and quantization model training. The function does one epoch training because that MNIST dataset is small and top1 accuracy will reach 95% after one epoch. + +```python +def train(prog): + iter = 0 + for data in train_reader(): + acc1, acc5, loss = exe.run(prog, feed=train_feeder.feed(data), fetch_list=outputs) + if iter % 100 == 0: + print('train iter={}, top1={}, top5={}, loss={}'.format(iter, acc1.mean(), acc5.mean(), loss.mean())) + iter += 1 + +def test(prog): + iter = 0 + res = [[], []] + for data in train_reader(): + acc1, acc5, loss = exe.run(prog, feed=train_feeder.feed(data), fetch_list=outputs) + if iter % 100 == 0: + print('test iter={}, top1={}, top5={}, loss={}'.format(iter, acc1.mean(), acc5.mean(), loss.mean())) + res[0].append(acc1.mean()) + res[1].append(acc5.mean()) + iter += 1 + print('final test result top1={}, top5={}'.format(np.array(res[0]).mean(), np.array(res[1]).mean())) +``` + +Call ``train`` function to train normal classification model. ``train_program`` is defined in 2. Model architecture. + +```python +train(train_program) +``` + +Call ``test`` function to test normal classification model. ``val_program`` is defined in 2. Model architecture. + +```python +test(val_program) +``` + + +## 4. Quantization + +We call ``quant_aware`` API to add quantization and dequantization operators in ``train_program`` and ``val_program`` according to [default configuration](https://paddlepaddle.github.io/PaddleSlim/api_cn/quantization_api.html#id2). + +```python +quant_program = slim.quant.quant_aware(train_program, exe.place, for_test=False) +val_quant_program = slim.quant.quant_aware(val_program, exe.place, for_test=True) +``` + + +## 5. Train model after quantization + +Finetune the model after quantization. Test model after one epoch training. + +```python +train(quant_program) +``` + +Test model after quantization. The top1 and top5 accuracy are close to result in ``3.2 training model and testing``. We preform the training-aware quantization without loss on this image classification model. + +```python +test(val_quant_program) +``` + + +## 6. Save model after quantization + +The model in ``4. Quantization`` after calling ``slim.quant.quant_aware`` API is only suitable to train. To get the inference model, we should use [slim.quant.convert](https://paddlepaddle.github.io/PaddleSlim/api_en/paddleslim.quant.html#paddleslim.quant.quanter.convert) API to change model architecture and use [fluid.io.save_inference_model](https://www.paddlepaddle.org.cn/documentation/docs/zh/develop/api_cn/io_cn/save_inference_model_cn.html#save-inference-model) to save model. ``float_prog``'s parameters are float32 dtype but in int8's range which can be used in ``fluid`` or ``paddle-lite``. ``paddle-lite`` will change the parameters' dtype from float32 to int8 first when loading the inference model. ``int8_prog``'s parameters are int8 dtype and we can get model size after quantization by saving it. ``int8_prog`` cannot be used in ``fluid`` or ``paddle-lite``. + + +```python +float_prog, int8_prog = slim.quant.convert(val_quant_program, exe.place, save_int8=True) +target_vars = [float_prog.global_block().var(name) for name in outputs] +fluid.io.save_inference_model(dirname='./inference_model/float', + feeded_var_names=[var.name for var in inputs], + target_vars=target_vars, + executor=exe, + main_program=float_prog) +fluid.io.save_inference_model(dirname='./inference_model/int8', + feeded_var_names=[var.name for var in inputs], + target_vars=target_vars, + executor=exe, + main_program=int8_prog) +``` diff --git a/docs/en/quick_start/quant_post_static_tutorial_en.md b/docs/en/quick_start/quant_post_static_tutorial_en.md new file mode 100644 index 0000000000000000000000000000000000000000..0f7c5f414c2671aa97fe9189381358a76df7fba0 --- /dev/null +++ b/docs/en/quick_start/quant_post_static_tutorial_en.md @@ -0,0 +1,124 @@ +# Post-training Quantization of image classification model - quick start + +This tutorial shows how to do post training quantization using [API](https://paddlepaddle.github.io/PaddleSlim/api_en/paddleslim.quant.html#paddleslim.quant.quanter.quant_post) in PaddleSlim. We use MobileNetV1 to train image classification model as example. The tutorial contains follow sections: + +1. Necessary imports +2. Model architecture +3. Train normal model +4. Post training quantization + +## 1. Necessary imports +PaddleSlim depends on Paddle1.7. Please make true that you have installed Paddle correctly. Then do the necessary imports: + + +```python +import paddle +import paddle.fluid as fluid +import paddleslim as slim +import numpy as np +``` +## 2. Model architecture + +The section constructs a classification model, which use ``MobileNetV1`` and MNIST dataset. The model's input size is `[1, 28, 28]` and output size is 10. In order to show tutorial conveniently, we pre-defined a method to get image classification model in `paddleslim.models`. + +>note: The APIs in `paddleslim.models` are not formal inferface in PaddleSlim. They are defined to simplify the tutorial such as the definition of model structure and the construction of Program. + + +```python +exe, train_program, val_program, inputs, outputs = \ + slim.models.image_classification("MobileNet", [1, 28, 28], 10, use_gpu=True) +``` + +## 3. Train normal model + +The section shows how to define model inputs, train and test model. The reason for training the normal image classification model first is that the post training quantization is performed on the well-trained model. + +### 3.1 input data definition + +To speed up training process, we select MNIST dataset to train image classification model. The API `paddle.dataset.mnist` in Paddle framework contains downloading and reading the images in dataset. + +```python +import paddle.dataset.mnist as reader +train_reader = paddle.fluid.io.batch( + reader.train(), batch_size=128, drop_last=True) +test_reader = paddle.fluid.io.batch( +cs/en/quick_start/quant_aware_tutorial_en.md + reader.train(), batch_size=128, drop_last=True) +train_feeder = fluid.DataFeeder(inputs, fluid.CPUPlace()) +``` + +### 3.2 training model and testing + +Define functions to train and test model. We only need call the functions when formal model training and quantization model training. The function does one epoch training because that MNIST dataset is small and top1 accuracy will reach 95% after one epoch. + +```python +def train(prog): + iter = 0 + for data in train_reader(): + acc1, acc5, loss = exe.run(prog, feed=train_feeder.feed(data), fetch_list=outputs) + if iter % 100 == 0: + print('train', acc1.mean(), acc5.mean(), loss.mean()) + iter += 1 + +def test(prog, outputs=outputs): + iter = 0 + res = [[], []] + for data in train_reader(): + acc1, acc5, loss = exe.run(prog, feed=train_feeder.feed(data), fetch_list=outputs) + if iter % 100 == 0: + print('test', acc1.mean(), acc5.mean(), loss.mean()) + res[0].append(acc1.mean()) + res[1].append(acc5.mean()) + iter += 1 + print('final test result', np.array(res[0]).mean(), np.array(res[1]).mean()) +``` + +Call ``train`` function to train normal classification model. ``train_program`` is defined in 2. Model architecture. + + +```python +train(train_program) +``` + +Call ``test`` function to test normal classification model. ``val_program`` is defined in 2. Model architecture. + +```python +test(val_program) +``` + + +Save inference model. Save well-trained model in ``'./inference_model'``. We will load the model when doing post training quantization. + + +```python +target_vars = [val_program.global_block().var(name) for name in outputs] +fluid.io.save_inference_model(dirname='./inference_model', + feeded_var_names=[var.name for var in inputs], + target_vars=target_vars, + executor=exe, + main_program=val_program) +``` + +## 4. Post training quantization + +Call ``slim.quant.quant_post`` API to do post training quantization. The API will load the inference model in ``'./inference_model'`` first and calibrate the quantization parameters using data in sample_generator. In this tutorial, we use 10 mini-batch data to calibrate the quantization parameters. There is no need to train model but run forward to get activations for quantization scales calculation. The model after post training quantization are saved in ``'./quant_post_model'``. + +```python +slim.quant.quant_post( + executor=exe, + model_dir='./inference_model', + quantize_model_path='./quant_post_model', + sample_generator=reader.test(), + batch_nums=10) +``` + +Load the model after post training quantization in ``'./quant_post_model'`` and run ``test`` function. The top1 and top5 accuracy are close to result in ``3.2 training model and testing``. We preform the post training quantization without loss on this image classification model. + +```python +quant_post_prog, feed_target_names, fetch_targets = fluid.io.load_inference_model( + dirname='./quant_post_model', + model_filename='__model__', + params_filename='__params__', + executor=exe) +test(quant_post_prog, fetch_targets) +``` diff --git a/docs/en/tutorials/image_classification_sensitivity_analysis_tutorial_en.md b/docs/en/tutorials/image_classification_sensitivity_analysis_tutorial_en.md new file mode 100644 index 0000000000000000000000000000000000000000..043e144a1f122fd9abd1598f35c688f5bc7b6f71 --- /dev/null +++ b/docs/en/tutorials/image_classification_sensitivity_analysis_tutorial_en.md @@ -0,0 +1,263 @@ +# Pruning of image classification model - sensitivity + +In this tutorial, you will learn how to use [sensitivity API of PaddleSlim](https://paddlepaddle.github.io/PaddleSlim/api/prune_api/#sensitivity) by a demo of MobileNetV1 model on MNIST dataset。 +This tutorial following workflow: + +1. Import dependency +2. Build model +3. Define data reader +4. Define function for test +5. Training model +6. Get names of parameter +7. Compute sensitivities +8. Pruning model + + +## 1. Import dependency + +PaddleSlim dependents on Paddle1.7. Please ensure that you have installed paddle correctly. Import Paddle and PaddleSlim as below: + +```python +import paddle +import paddle.fluid as fluid +import paddleslim as slim +``` + +## 2. Build model + +This section will build a classsification model based `MobileNetV1` for MNIST task. The shape of the input is `[1, 28, 28]` and the output number is 10. + +To make the code simple, we define a function in package `paddleslim.models` to build classification model. +Excute following code to build a model, + + +```python +exe, train_program, val_program, inputs, outputs = slim.models.image_classification("MobileNet", [1, 28, 28], 10, use_gpu=True) +place = fluid.CUDAPlace(0) +``` + +>Note:The functions in paddleslim.models is just used in tutorials or demos. + +## 3 Define data reader + +MNIST dataset is used for making the demo can be executed quickly. It defines some functions for downloading and reading MNIST dataset in package `paddle.dataset.mnist`. +Show as below: + +```python +import paddle.dataset.mnist as reader +train_reader = paddle.fluid.io.batch( + reader.train(), batch_size=128, drop_last=True) +test_reader = paddle.fluid.io.batch( + reader.test(), batch_size=128, drop_last=True) +data_feeder = fluid.DataFeeder(inputs, place) +``` + +## 4. Define test function + +To get the performance of model on test dataset after pruning a convolution layer, we define a test function as below: + +```python +import numpy as np +def test(program): + acc_top1_ns = [] + acc_top5_ns = [] + for data in test_reader(): + acc_top1_n, acc_top5_n, _ = exe.run( + program, + feed=data_feeder.feed(data), + fetch_list=outputs) + acc_top1_ns.append(np.mean(acc_top1_n)) + acc_top5_ns.append(np.mean(acc_top5_n)) + print("Final eva - acc_top1: {}; acc_top5: {}".format( + np.mean(np.array(acc_top1_ns)), np.mean(np.array(acc_top5_ns)))) + return np.mean(np.array(acc_top1_ns)) +``` + +## 5. Training model + +Sensitivity analysis is dependent on pretrained model. So we should train the model defined in section 2 for some epochs. One epoch training is enough for this simple demo while more epochs may be necessary for other model. Or you can load pretrained model from filesystem. + +Training model as below: + + +```python +for data in train_reader(): + acc1, acc5, loss = exe.run(train_program, feed=data_feeder.feed(data), fetch_list=outputs) +print(np.mean(acc1), np.mean(acc5), np.mean(loss)) +``` + +Get the performance using the test function defined in section 4: + +```python +test(val_program) +``` + +## 6. Get names of parameters + +```python +params = [] +for param in train_program.global_block().all_parameters(): + if "_sep_weights" in param.name: + params.append(param.name) +print(params) +params = params[:5] +``` + +## 7. Compute sensitivities + +### 7.1 Compute in single process + +Apply sensitivity analysis on pretrained model by calling [sensitivity API](https://paddlepaddle.github.io/PaddleSlim/api/prune_api/#sensitivity). + +The sensitivities will be appended into the file given by option `sensitivities_file` during computing. +The information in this file won`t be computed repeatedly. + +Remove the file `sensitivities_0.data` in current directory: + +```python +!rm -rf sensitivities_0.data +``` + +Apart from the parameters to be analyzed, it also support for setting the ratios that each convolutoin will be pruned. + +If one model losses 90% accuracy on test dataset when its single convolution layer is pruned by 40%, then we can set `pruned_ratios` to `[0.1, 0.2, 0.3, 0.4]`. + +The granularity of `pruned_ratios` should be small to get more reasonable sensitivities. But small granularity of `pruned_ratios` will slow down the computing. + +```python +sens_0 = slim.prune.sensitivity( + val_program, + place, + params, + test, + sensitivities_file="sensitivities_0.data", + pruned_ratios=[0.1, 0.2]) +print(sens_0) +``` + +### 7.2 Expand sensitivities + +We can expand `pruned_ratios` to `[0.1, 0.2, 0.3]` based the sensitivities generated in section 7.1. + +```python +sens_0 = slim.prune.sensitivity( + val_program, + place, + params, + test, + sensitivities_file="sensitivities_0.data", + pruned_ratios=[0.3]) +print(sens_0) +``` + +### 7.3 Computing sensitivity in multi-process + +The time cost of computing sensitivities is dependent on the count of parameters and the speed of model evaluation on test dataset. We can speed up computing by multi-process. + +Split `pruned_ratios` into multi-process, and merge the sensitivities from multi-process. + +#### 7.3.1 Computing in each process + +We have compute the sensitivities when `pruned_ratios=[0.1, 0.2, 0.3]` and saved the sensitivities into file named `sensitivities_0.data`. + +在另一个进程中,The we start a task by setting `pruned_ratios=[0.4]` in another process and save result into file named `sensitivities_1.data`. Show as below: + + +```python +sens_1 = slim.prune.sensitivity( + val_program, + place, + params, + test, + sensitivities_file="sensitivities_1.data", + pruned_ratios=[0.4]) +print(sens_1) +``` + +#### 7.3.2 Load sensitivity file generated in multi-process + +```python +s_0 = slim.prune.load_sensitivities("sensitivities_0.data") +s_1 = slim.prune.load_sensitivities("sensitivities_1.data") +print(s_0) +print(s_1) +``` + +#### 7.3.3 Merge sensitivies + + +```python +s = slim.prune.merge_sensitive([s_0, s_1]) +print(s) +``` + +## 8. Pruning model + +Pruning model according to the sensitivities generated in section 7.3.3. + +### 8.1 Get pruning ratios + +Get a group of ratios by calling [get_ratios_by_loss](https://paddlepaddle.github.io/PaddleSlim/api/prune_api/#get_ratios_by_loss) fuction: + + +```python +loss = 0.01 +ratios = slim.prune.get_ratios_by_loss(s_0, loss) +print(ratios) +``` + +### 8.2 Pruning training network + + +```python +pruner = slim.prune.Pruner() +print("FLOPs before pruning: {}".format(slim.analysis.flops(train_program))) +pruned_program, _, _ = pruner.prune( + train_program, + fluid.global_scope(), + params=ratios.keys(), + ratios=ratios.values(), + place=place) +print("FLOPs after pruning: {}".format(slim.analysis.flops(pruned_program))) +``` + +### 8.3 Pruning test network + +Note:The `only_graph` should be set to True while pruning test network. [Pruner API](https://paddlepaddle.github.io/PaddleSlim/api/prune_api/#pruner) + + +```python +pruner = slim.prune.Pruner() +print("FLOPs before pruning: {}".format(slim.analysis.flops(val_program))) +pruned_val_program, _, _ = pruner.prune( + val_program, + fluid.global_scope(), + params=ratios.keys(), + ratios=ratios.values(), + place=place, + only_graph=True) +print("FLOPs after pruning: {}".format(slim.analysis.flops(pruned_val_program))) +``` + +Get accuracy of pruned model on test dataset: + +```python +test(pruned_val_program) +``` + +### 8.4 Training pruned model + +Training pruned model: + + +```python +for data in train_reader(): + acc1, acc5, loss = exe.run(pruned_program, feed=data_feeder.feed(data), fetch_list=outputs) +print(np.mean(acc1), np.mean(acc5), np.mean(loss)) +``` + +Get accuracy of model after training: + +```python +test(pruned_val_program) +``` diff --git a/docs/en/tutorials/index_en.rst b/docs/en/tutorials/index_en.rst new file mode 100644 index 0000000000000000000000000000000000000000..10bdbd38761f9f1c72a0cb427636cd3431986cd7 --- /dev/null +++ b/docs/en/tutorials/index_en.rst @@ -0,0 +1,8 @@ +Aadvanced Tutorials +======== + +.. toctree:: + :maxdepth: 1 + + image_classification_sensitivity_analysis_tutorial_en.md + diff --git a/docs/docs/images/algo/distillation_0.png b/docs/images/algo/distillation_0.png similarity index 100% rename from docs/docs/images/algo/distillation_0.png rename to docs/images/algo/distillation_0.png diff --git a/docs/docs/images/algo/light-nas-block.png b/docs/images/algo/light-nas-block.png similarity index 100% rename from docs/docs/images/algo/light-nas-block.png rename to docs/images/algo/light-nas-block.png diff --git a/docs/docs/images/algo/pruning_0.png b/docs/images/algo/pruning_0.png similarity index 100% rename from docs/docs/images/algo/pruning_0.png rename to docs/images/algo/pruning_0.png diff --git a/docs/docs/images/algo/pruning_1.png b/docs/images/algo/pruning_1.png similarity index 100% rename from docs/docs/images/algo/pruning_1.png rename to docs/images/algo/pruning_1.png diff --git a/docs/docs/images/algo/pruning_2.png b/docs/images/algo/pruning_2.png similarity index 100% rename from docs/docs/images/algo/pruning_2.png rename to docs/images/algo/pruning_2.png diff --git a/docs/docs/images/algo/pruning_3.png b/docs/images/algo/pruning_3.png similarity index 100% rename from docs/docs/images/algo/pruning_3.png rename to docs/images/algo/pruning_3.png diff --git a/docs/docs/images/algo/pruning_4.png b/docs/images/algo/pruning_4.png similarity index 100% rename from docs/docs/images/algo/pruning_4.png rename to docs/images/algo/pruning_4.png diff --git a/docs/docs/images/algo/quan_bwd.png b/docs/images/algo/quan_bwd.png similarity index 100% rename from docs/docs/images/algo/quan_bwd.png rename to docs/images/algo/quan_bwd.png diff --git a/docs/docs/images/algo/quan_forward.png b/docs/images/algo/quan_forward.png similarity index 100% rename from docs/docs/images/algo/quan_forward.png rename to docs/images/algo/quan_forward.png diff --git a/docs/docs/images/algo/quan_fwd_1.png b/docs/images/algo/quan_fwd_1.png similarity index 100% rename from docs/docs/images/algo/quan_fwd_1.png rename to docs/images/algo/quan_fwd_1.png diff --git a/docs/docs/images/algo/quan_table_0.png b/docs/images/algo/quan_table_0.png similarity index 100% rename from docs/docs/images/algo/quan_table_0.png rename to docs/images/algo/quan_table_0.png diff --git a/docs/docs/images/algo/quan_table_1.png b/docs/images/algo/quan_table_1.png similarity index 100% rename from docs/docs/images/algo/quan_table_1.png rename to docs/images/algo/quan_table_1.png diff --git a/docs/images/framework_0.png b/docs/images/framework_0.png new file mode 100644 index 0000000000000000000000000000000000000000..223f384f23775403129a69967bbe9e891dfa77ff Binary files /dev/null and b/docs/images/framework_0.png differ diff --git a/docs/images/framework_1.png b/docs/images/framework_1.png new file mode 100644 index 0000000000000000000000000000000000000000..642bc13f8e12eace8fe8e70d8f3ec04a39e4275a Binary files /dev/null and b/docs/images/framework_1.png differ diff --git a/docs/mkdocs.yml b/docs/mkdocs.yml deleted file mode 100644 index 970e4b8f7e0ee7940098ea77929c7214c49d9ba9..0000000000000000000000000000000000000000 --- a/docs/mkdocs.yml +++ /dev/null @@ -1,51 +0,0 @@ -site_name: PaddleSlim Docs -repo_url: https://github.com/PaddlePaddle/PaddleSlim -nav: -- Home: index.md -- 教程: - - 离线量化: tutorials/quant_post_demo.md - - 量化训练: tutorials/quant_aware_demo.md - - Embedding量化: tutorials/quant_embedding_demo.md - - SA搜索: tutorials/nas_demo.md - - 知识蒸馏: tutorials/distillation_demo.md -- API: - - 量化: api/quantization_api.md - - 剪枝与敏感度: api/prune_api.md - - 模型分析: api/analysis_api.md - - 知识蒸馏: api/single_distiller_api.md - - SA搜索: api/nas_api.md - - 搜索空间: api/search_space.md - - 硬件延时评估表: table_latency.md -- 算法原理: algo/algo.md - -theme: - name: readthedocs - highlightjs: true - -markdown_extensions: - - admonition - - codehilite: - guess_lang: true - linenums: true - - toc: - permalink: "#" - - footnotes - - meta - - def_list - - pymdownx.arithmatex - - pymdownx.betterem: - smart_enable: all - - pymdownx.caret - - pymdownx.critic - - pymdownx.details - - pymdownx.magiclink - - pymdownx.mark - - pymdownx.smartsymbols - - pymdownx.superfences - - pymdownx.tasklist - - pymdownx.tilde - - mdx_math - -extra_javascript: - - mathjax-config.js - - https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.0/MathJax.js?config=TeX-AMS-MML_HTMLorMML diff --git a/docs/requirements.txt b/docs/requirements.txt index aa4ce367e579b1c3e004e04c20f261a1e75548fc..b15f2f146d1b52d3f7b2c5edc870131b8c8f54c3 100644 --- a/docs/requirements.txt +++ b/docs/requirements.txt @@ -1,4 +1,5 @@ -mkdocs -markdown -python-markdown-math -pymdown-extensions +sphinx +recommonmark +sphinx_markdown_tables +sphinx_rtd_theme +m2r diff --git a/docs/zh_cn/CHANGELOG.md b/docs/zh_cn/CHANGELOG.md new file mode 100644 index 0000000000000000000000000000000000000000..43105675f071812dec17dd76c3fc30e47a95fbe4 --- /dev/null +++ b/docs/zh_cn/CHANGELOG.md @@ -0,0 +1,46 @@ +# 版本更新信息 + +## 最新版本信息 + +### v1.1.0(05/2020) + +- 量化 + - 增加无校准数据训练后量化方法,int16精度无损,int8精度损失低于0.1%。 + - 增强量化功能,完善量化OP的输出scale信息,支持CPU预测端全面适配量化模型。 +- 剪裁 + - 新增FPGM和BN scale两种剪裁策略, 在MobileNetV3-YOLOV3-COCO任务上,同等压缩率下精度提升0.6%。 + - 新增自定义剪裁策略接口,方便开发者快速新增压缩策略。 + - 剪裁功能添加对新增Operator的默认处理逻辑,扩展支持剪裁更多复杂网络。 +- NAS + - 新增DARTS系列搜索算法,并提供扩展接口,方便用户调研和实现新的模型结构搜索策略。 + - 模型结构搜索添加早停机制,提升搜索功能易用性。 + - 新增一种基于强化学习的模型结构搜索策略,并提供扩展接口,为用户调研实现新策略提供参考。 + + +## 历史版本信息 + +### v1.0.1 + + - 拆分PaddleSlim为独立repo。 + - 重构裁剪、量化、蒸馏、搜索接口,对用户开放底层接口。 + - 量化: + - 新增基于KL散度的离线量化功能,支持对Embedding层量化。 + - 新增对FC的QAT MKL-DNN量化策略支持 + - 新增PostTrainingQuantization,完整实现训练后量化功能:支持量化30种OP,支持灵活设置需要量化的OP,生成统一格式的量化模型,具有耗时短、易用性强、精度损失较小的优点。 + - 量化训练支持设定需要量化的OP类型。 + - 裁剪: 重构剪裁实现,方便扩展支持更多类型的网络。 + - 搜索: + - 支持SA搜索,增加更多的搜索空间,支持用户自定义搜索空间。 + - 新增one-shot搜索算法,搜索速度比上个版本快20倍。 + - 新增大规模可扩展知识蒸馏框架 Pantheon + - student 与 teacher 、teacher与 teacher 模型之间充分解耦,可分别独立运行在不同的物理设备上,便于充分利用计算资源; + - 支持 teacher 模型的单节点多设备大规模预测,在 BERT 等模型上测试加速比达到线性; + - 用 TCP/IP 协议实现在线蒸馏模式的通信,支持在同一网络环境下,运行在任意两个物理设备上的 teacher 模型和 student 模型之间进行知识传输; + - 统一在线和离线两种蒸馏模式的 API 接口,不同的 teacher 模型可以工作在不同的模式下; + - 在 student 端自动完成知识的归并与知识数据的 batch 重组,便于多 teacher 模型的知识融合。 + - 模型库: + - 发布ResNet50、MobileNet模型的压缩benchmark + - 打通检测库,并发布YOLOv3系列模型的压缩benchmark + - 打通分割库,并发布Deepabv3+系列分割模型的压缩benchmark + - 完善文档: + - 补充API文档;新增入门教程和高级教程;增加ModelZoo文档,覆盖分类、检测、分割任务。所有文档包含中、英文。 diff --git a/docs/zh_cn/FAQ/index.rst b/docs/zh_cn/FAQ/index.rst new file mode 100644 index 0000000000000000000000000000000000000000..a9578403444c471af3512be25e750595419b64ce --- /dev/null +++ b/docs/zh_cn/FAQ/index.rst @@ -0,0 +1,9 @@ + +FAQ +======== + +.. toctree:: + :maxdepth: 1 + + quantization_FAQ.md + diff --git a/docs/zh_cn/FAQ/quantization_FAQ.md b/docs/zh_cn/FAQ/quantization_FAQ.md new file mode 100644 index 0000000000000000000000000000000000000000..8ac10e43b3ab5bdea3ae0005c1ba76adfaa53195 --- /dev/null +++ b/docs/zh_cn/FAQ/quantization_FAQ.md @@ -0,0 +1,89 @@ +## 量化FAQ + +1. 量化训练或者离线量化后的模型体积为什么没有变小? +2. 量化训练或者离线量化后的模型使用fluid加载为什么没有加速?怎样才能加速? +3. 该怎么设置适合的量化配置? +4. 离线量化出现'KeyError: '报错 +5. 离线量化或者量化训练时出现CUDNN或者CUDA错误 +6. 量化训练时loss是nan +7. cpu上跑量化后的模型出nan + +#### 1. 量化训练或者离线量化后的模型体积为什么没有变小? + +答:这是因为量化后保存的参数是虽然是int8范围,但是类型是float。这是由于fluid没有int8 kernel, 为了方便量化后验证量化精度,必须能让fluid能够加载。 + +#### 2. 量化训练或者离线量化后的模型使用fluid加载为什么没有加速?怎样才能加速? + +答:这是因为量化后保存的参数是虽然是int8范围,但是类型是float。fluid并不具备加速量化模型的能力。量化模型必须配合使用预测库才能加速。 + +- 如果量化模型在ARM上线,则需要使用[Paddle-Lite](https://paddle-lite.readthedocs.io/zh/latest/index.html). + + - Paddle-Lite会对量化模型进行模型转化和优化,转化方法见[链接](https://paddle-lite.readthedocs.io/zh/latest/user_guides/model_quantization.html#paddle-lite)。 + + - 转化之后可以像非量化模型一样使用[Paddle-Lite API](https://paddle-lite.readthedocs.io/zh/latest/user_guides/tutorial.html#lite)进行加载预测。 + +- 如果量化模型在GPU上线,则需要使用[Paddle-TensorRT 预测接口](https://www.paddlepaddle.org.cn/documentation/docs/zh/develop/advanced_guide/performance_improving/inference_improving/paddle_tensorrt_infer.html). + + - 和非量化模型的区别在于以下参数设置: + +```python +config->EnableTensorRtEngine(1 << 20 /* workspace_size*/, + batch_size /* max_batch_size*/, + 3 /* min_subgraph_size*/, + AnalysisConfig::Precision::kInt8 /* precision*/, + false /* use_static*/, + false /* use_calib_mode*/); +``` + +- 如果量化模型在x86上线,需要使用[INT8 MKL-DNN](https://github.com/PaddlePaddle/Paddle/blob/develop/python/paddle/fluid/contrib/slim/tests/slim_int8_mkldnn_post_training_quantization.md) + + - 首先对模型进行转化,可以参考[脚本](https://github.com/PaddlePaddle/Paddle/blob/develop/python/paddle/fluid/contrib/slim/tests/save_quant_model.py) + + - 转化之后可使用预测部署API进行加载。比如[c++ API](https://www.paddlepaddle.org.cn/documentation/docs/zh/develop/advanced_guide/inference_deployment/inference/native_infer.html) + + +#### 3. 该怎么设置适合的量化配置? + +- 首先需要考虑量化模型上线的平台 + + | 平台 | 支持weight量化方式 | 支持activation量化方式 | 支持量化的OP | + | ---------------- | ------------------------------ | ------------------------------------- | ------------------------------------------------------------ | + | ARM(Paddle-Lite) | channel_wise_abs_max, abs_max | moving_average_abs_max,range_abs_max | conv2d, depthwise_conv2d, mul | + | x86(MKL-DNN) | abs_max | moving_average_abs_max,range_abs_max | conv2d, depthwise_conv2d, mul, matmul | + | GPU(TensorRT) | channel_wise_abs_max | moving_average_abs_max,range_abs_max | mul, conv2d, pool2d, depthwise_conv2d, elementwise_add, leaky_relu | + +- 部分层跳过量化 + + 如果量化后精度损失较大,可以考虑跳过部分对量化敏感的计算不量化,比如最后一层或者attention计算。 + + + +#### 4. 离线量化出现'KeyError: '报错 + + + +答: 一般是reader没写对,导致离线量化是前向一次没跑,没有收集到中间的激活值。 + + + +#### 5. 离线量化或者量化训练时出现CUDNN或者CUDA错误 + + + +答:因为离线量化或者量化训练并没有涉及到对cuda或者cudnn做修改, 因此这个错误一般是机器上的cuda或者cudnn版本和Paddle所需的cuda或者cudnn版本不一致。 + + + +#### 6. 量化训练时loss是nan + + + +答:需要适当调小学习率。如果小学习率依然不能解决问题,则需要考虑是否某些层对量化敏感,需要跳过量化,比如attention. + + + +#### 7. cpu上跑量化后的模型出nan + + + +答:可查看使用的paddle版本是否包含[pr](https://github.com/PaddlePaddle/Paddle/pull/22966), 该pr修复了在对几乎是0的tensor进行量化时的bug。 diff --git a/docs/zh_cn/Makefile b/docs/zh_cn/Makefile new file mode 100644 index 0000000000000000000000000000000000000000..141d0b25f71fd0d96f59c5f682ea537d2ba767ea --- /dev/null +++ b/docs/zh_cn/Makefile @@ -0,0 +1,19 @@ +# Minimal makefile for Sphinx documentation +# + +# You can set these variables from the command line. +SPHINXOPTS = +SPHINXBUILD = sphinx-build +SOURCEDIR = ./ +BUILDDIR = build + +# Put it first so that "make" without argument is like "make help". +help: + @$(SPHINXBUILD) -M help "$(SOURCEDIR)" "$(BUILDDIR)" $(SPHINXOPTS) $(O) + +.PHONY: help Makefile + +# Catch-all target: route all unknown targets to Sphinx using the new +# "make mode" option. $(O) is meant as a shortcut for $(SPHINXOPTS). +%: Makefile + @$(SPHINXBUILD) -M $@ "$(SOURCEDIR)" "$(BUILDDIR)" $(SPHINXOPTS) $(O) diff --git a/docs/docs/algo/algo.md b/docs/zh_cn/algo/algo.md similarity index 93% rename from docs/docs/algo/algo.md rename to docs/zh_cn/algo/algo.md index 5f268b74eb4c073d0240b1fc2d4651edeb1cf606..67977e70f1f9618352575374aa8605bde3a80a62 100644 --- a/docs/docs/algo/algo.md +++ b/docs/zh_cn/algo/algo.md @@ -1,4 +1,6 @@ -## 目录 +# 算法原理 + +## 目录 - [量化原理介绍](#1-quantization-aware-training量化介绍) - [剪裁原理介绍](#2-卷积核剪裁原理) @@ -12,14 +14,14 @@ 近年来,定点量化使用更少的比特数(如8-bit、3-bit、2-bit等)表示神经网络的权重和激活已被验证是有效的。定点量化的优点包括低内存带宽、低功耗、低计算资源占用以及低模型存储需求等。
-
+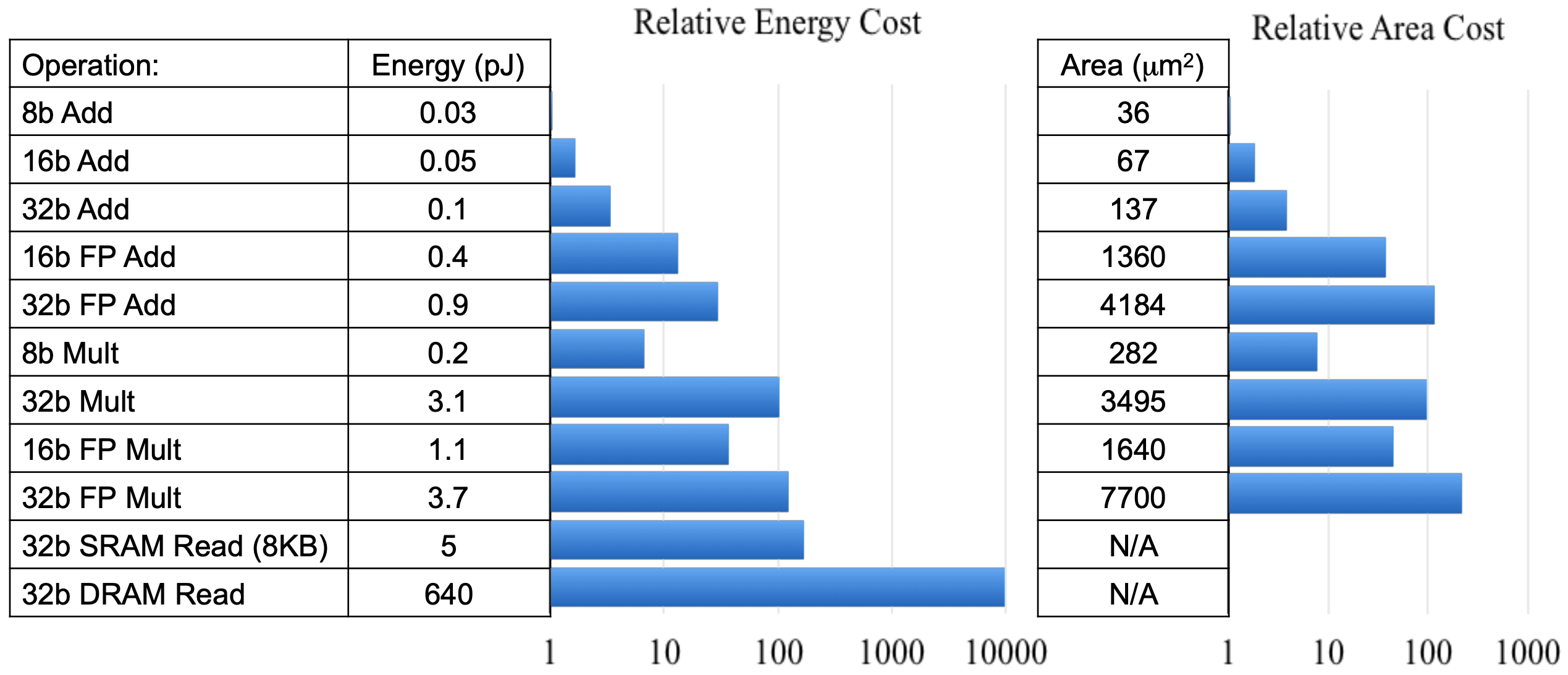
表1: 不同类型操作的开销对比
-
+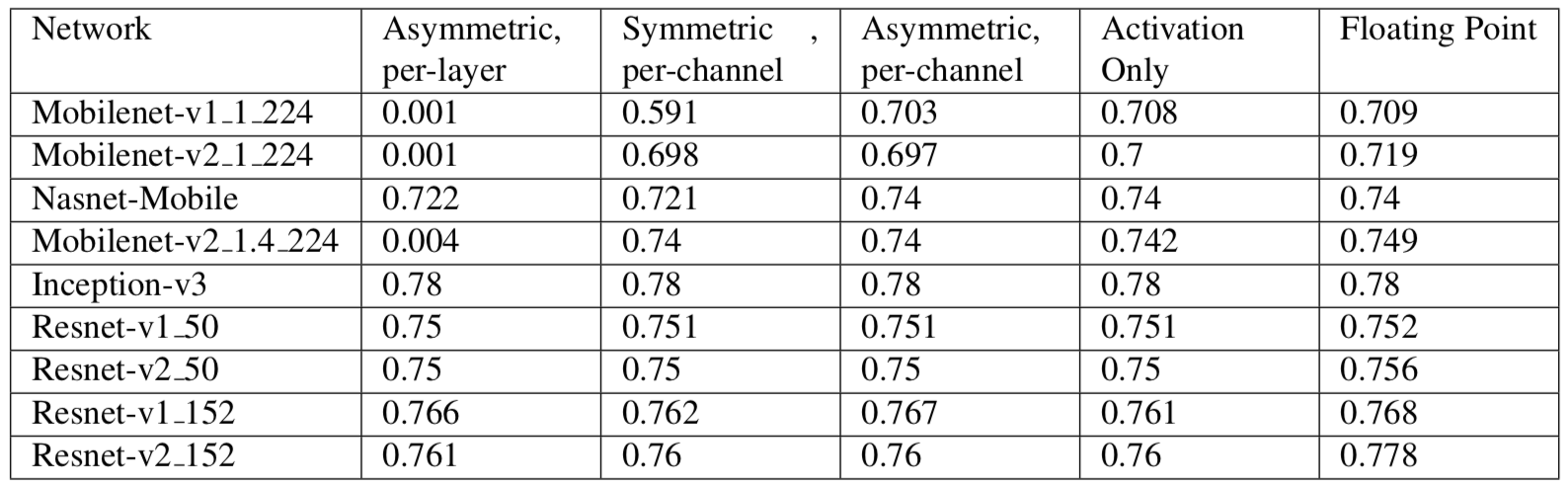
表2:模型量化前后精度对比
-
+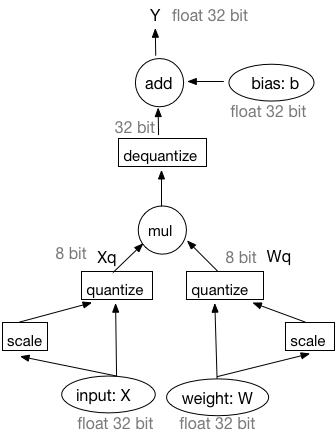
图1:基于模拟量化训练的前向过程
-
+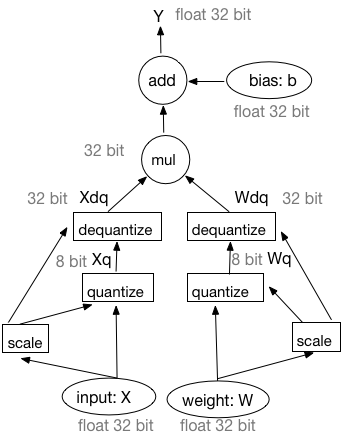
图2:基于模拟量化训练前向过程的等价工作流
-
+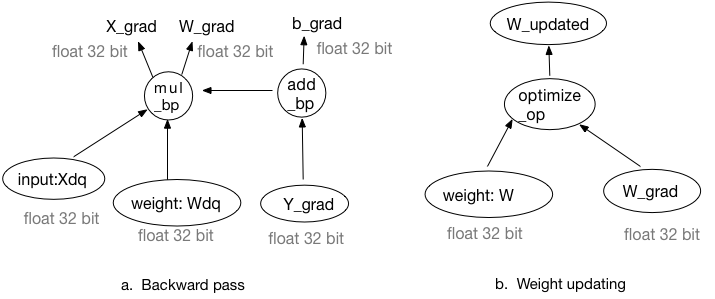
图3:基于模拟量化训练的反向传播和权重更新过程
-
+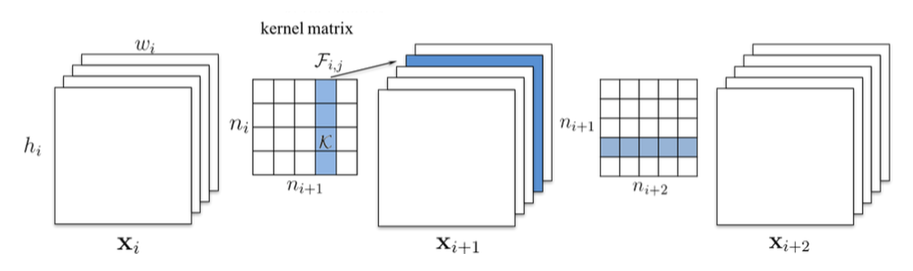
图4
-
+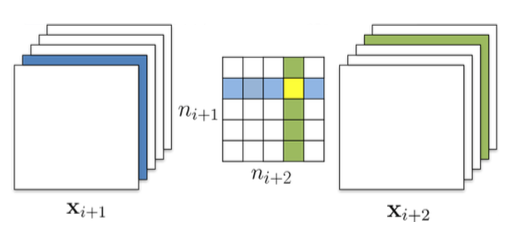
图5
-
+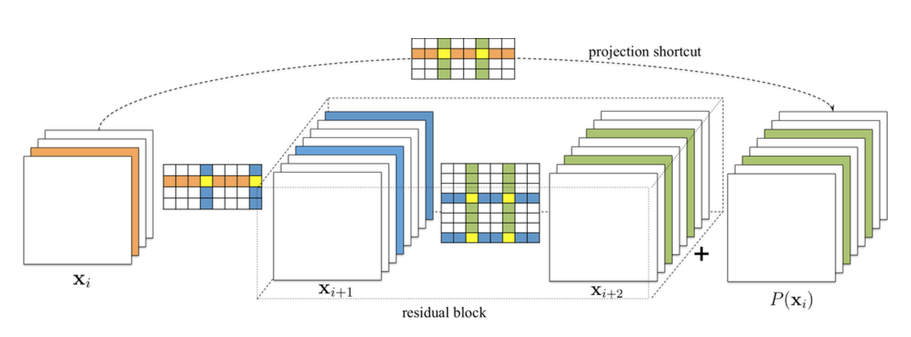
图6
-
+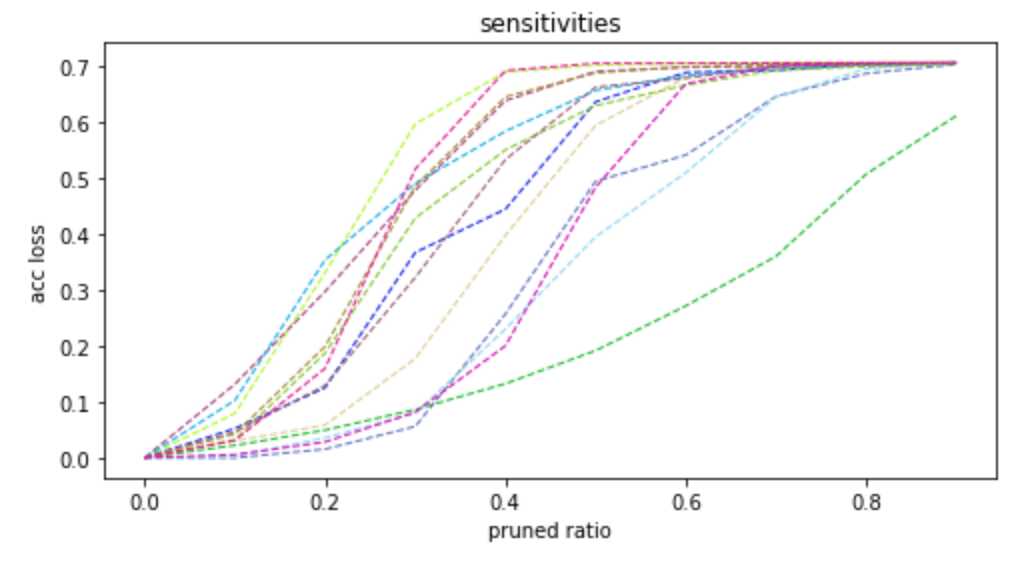
图7
-
+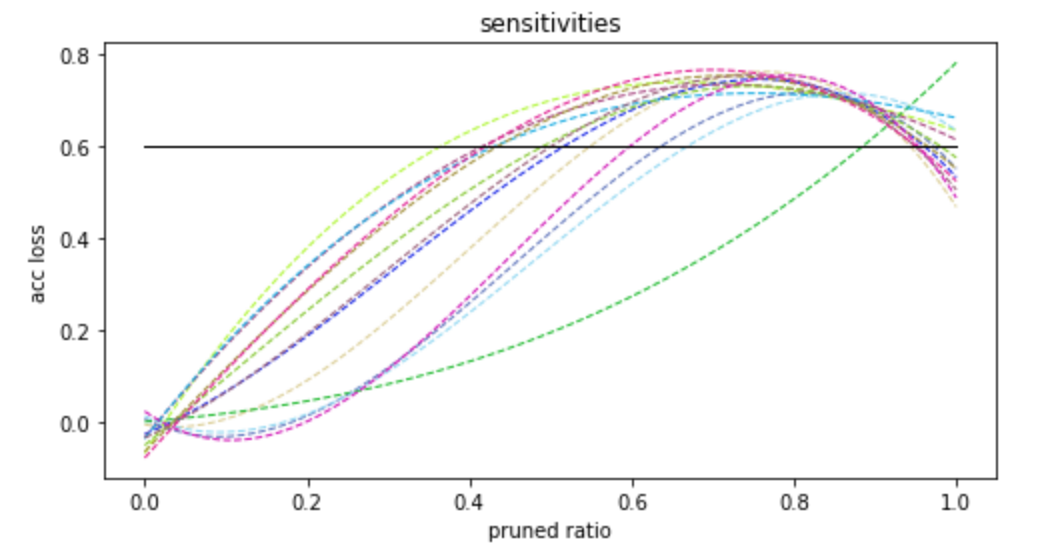
图8
-
+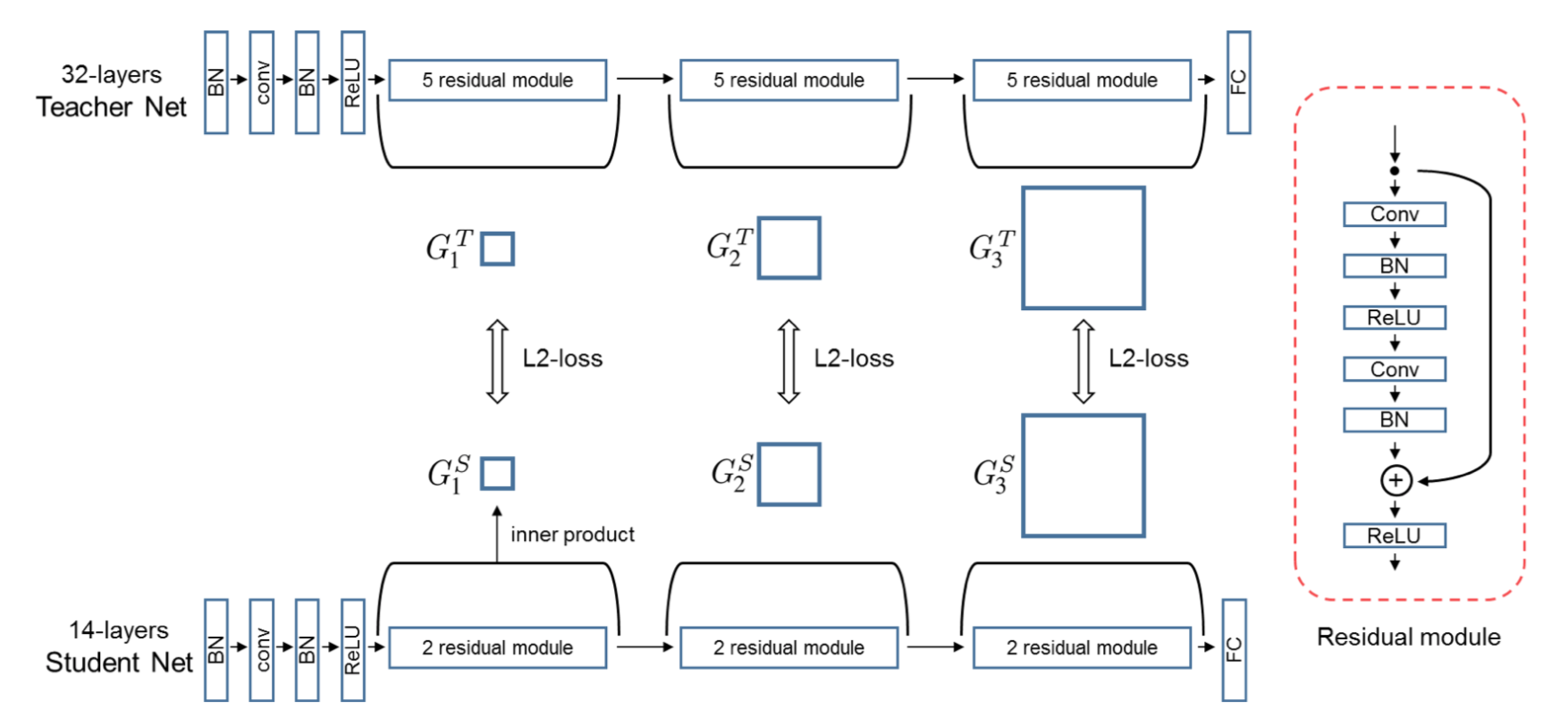
图9
-
+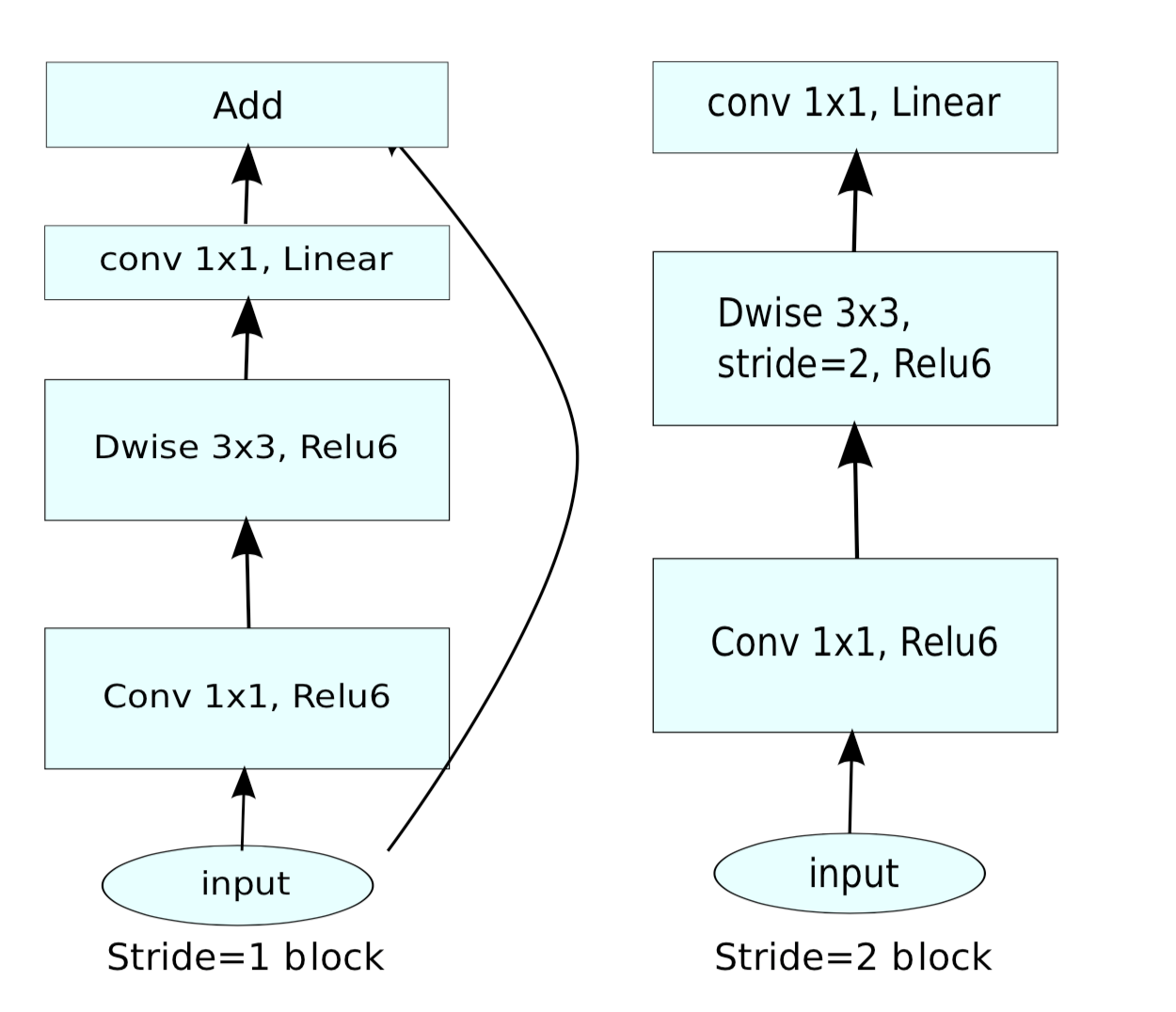
图10
+ MobileNetV2的网络结构可以参考:[代码](https://github.com/PaddlePaddle/models/blob/develop/PaddleCV/image_classification/models/mobilenet_v2.py#L29),[论文](https://arxiv.org/abs/1801.04381) -2. 根据相应模型的block构造搜索空间 +2. MobileNetV1Space
+ MobilNetV1的网络结构可以参考:[代码](https://github.com/PaddlePaddle/models/blob/develop/PaddleCV/image_classification/models/mobilenet_v1.py#L29),[论文](https://arxiv.org/abs/1704.04861) - 2.1 MobileNetV1BlockSpace - - 2.2 MobileNetV2BlockSpace - - 2.3 ResNetBlockSpace - - 2.4 InceptionABlockSpace - - 2.5 InceptionCBlockSpace +3. ResNetSpace
+ ResNetSpace的网络结构可以参考:[代码](https://github.com/PaddlePaddle/models/blob/develop/PaddleCV/image_classification/models/resnet.py#L30),[论文](https://arxiv.org/pdf/1512.03385.pdf) -##搜索空间的配置介绍: +#### 根据相应模型的block构造搜索空间: +1. MobileNetV1BlockSpace
+ MobileNetV1Block的结构可以参考:[代码](https://github.com/PaddlePaddle/models/blob/develop/PaddleCV/image_classification/models/mobilenet_v1.py#L173) -**input_size(int|None)**:`input_size`表示输入feature map的大小。 -**output_size(int|None)**:`output_size`表示输出feature map的大小。 -**block_num(int|None)**:`block_num`表示搜索空间中block的数量。 -**block_mask(list|None)**:`block_mask`表示当前的block是一个reduction block还是一个normal block,是一组由0、1组成的列表,0表示当前block是normal block,1表示当前block是reduction block。如果设置了`block_mask`,则主要以`block_mask`为主要配置,`input_size`,`output_size`和`block_num`三种配置是无效的。 +2. MobileNetV2BlockSpace
+ MobileNetV2Block的结构可以参考:[代码](https://github.com/PaddlePaddle/models/blob/develop/PaddleCV/image_classification/models/mobilenet_v2.py#L174) -**Note:** -1. reduction block表示经过这个block之后的feature map大小下降为之前的一半,normal block表示经过这个block之后feature map大小不变。 -2. `input_size`和`output_size`用来计算整个模型结构中reduction block数量。 +3. ResNetBlockSpace
+ ResNetBlock的结构可以参考:[代码](https://github.com/PaddlePaddle/models/blob/develop/PaddleCV/image_classification/models/resnet.py#L148) +4. InceptionABlockSpace
+ InceptionABlock的结构可以参考:[代码](https://github.com/PaddlePaddle/models/blob/develop/PaddleCV/image_classification/models/inception_v4.py#L140) -##搜索空间示例: +5. InceptionCBlockSpace
+ InceptionCBlock结构可以参考:[代码](https://github.com/PaddlePaddle/models/blob/develop/PaddleCV/image_classification/models/inception_v4.py#L291) -1. 使用paddleslim中提供用原本的模型结构来构造搜索空间的话,仅需要指定搜索空间名字即可。例如:如果使用原本的MobileNetV2的搜索空间进行搜索的话,传入SANAS中的config直接指定为[('MobileNetV2Space')]。 -2. 使用paddleslim中提供的block搜索空间构造搜索空间: - 2.1 使用`input_size`, `output_size`和`block_num`来构造搜索空间。例如:传入SANAS的config可以指定为[('MobileNetV2BlockSpace', {'input_size': 224, 'output_size': 32, 'block_num': 10})]。 - 2.2 使用`block_mask`构造搜索空间。例如:传入SANAS的config可以指定为[('MobileNetV2BlockSpace', {'block_mask': [0, 1, 1, 1, 1, 0, 1, 0]})]。 +## 搜索空间使用示例 -# 自定义搜索空间(search space) +1. 使用paddleslim中提供用初始的模型结构来构造搜索空间的话,仅需要指定搜索空间名字即可。例如:如果使用原本的MobileNetV2的搜索空间进行搜索的话,传入SANAS中的configs直接指定为[('MobileNetV2Space')]。 +2. 使用paddleslim中提供的block搜索空间构造搜索空间:
+ 2.1 使用`input_size`, `output_size`和`block_num`来构造搜索空间。例如:传入SANAS的configs可以指定为[('MobileNetV2BlockSpace', {'input_size': 224, 'output_size': 32, 'block_num': 10})]。
+ 2.2 使用`block_mask`构造搜索空间。例如:传入SANAS的configs可以指定为[('MobileNetV2BlockSpace', {'block_mask': [0, 1, 1, 1, 1, 0, 1, 0]})]。 -自定义搜索空间类需要继承搜索空间基类并重写以下几部分: - 1. 初始化的tokens(`init_tokens`函数),可以设置为自己想要的tokens列表, tokens列表中的每个数字指的是当前数字在相应的搜索列表中的索引。例如本示例中若tokens=[0, 3, 5],则代表当前模型结构搜索到的通道数为[8, 40, 128]。 - 2. token中每个数字的搜索列表长度(`range_table`函数),tokens中每个token的索引范围。 - 3. 根据token产生模型结构(`token2arch`函数),根据搜索到的tokens列表产生模型结构。 + +## 自定义搜索空间(search space) + +自定义搜索空间类需要继承搜索空间基类并重写以下几部分:
+ 1. 初始化的tokens(`init_tokens`函数),可以设置为自己想要的tokens列表, tokens列表中的每个数字指的是当前数字在相应的搜索列表中的索引。例如本示例中若tokens=[0, 3, 5],则代表当前模型结构搜索到的通道数为[8, 40, 128]。
+ 2. tokens中每个数字的搜索列表长度(`range_table`函数),tokens中每个token的索引范围。
+ 3. 根据tokens产生模型结构(`token2arch`函数),根据搜索到的tokens列表产生模型结构。
以新增reset block为例说明如何构造自己的search space。自定义的search space不能和已有的search space同名。 @@ -70,17 +68,18 @@ class ResNetBlockSpace2(SearchSpaceBase): def init_tokens(self): return [0] * 3 * len(self.block_mask) - ### 定义 + ### 定义token的index的取值范围 def range_table(self): return [len(self.filter_num)] * 3 * len(self.block_mask) + ### 把token转换成模型结构 def token2arch(self, tokens=None): if tokens == None: tokens = self.init_tokens() self.bottleneck_params_list = [] for i in range(len(self.block_mask)): - self.bottleneck_params_list.append(self.filter_num[tokens[i * 3 + 0]], + self.bottleneck_params_list.append(self.filter_num[tokens[i * 3 + 0]], self.filter_num[tokens[i * 3 + 1]], self.filter_num[tokens[i * 3 + 2]], 2 if self.block_mask[i] == 1 else 1) @@ -113,4 +112,4 @@ class ResNetBlockSpace2(SearchSpaceBase): conv = fluid.layers.conv2d(input, num_filters, filter_size, stride, name=name+'_conv') bn = fluid.layers.batch_norm(conv, act=act, name=name+'_bn') return bn -``` +``` diff --git a/docs/zh_cn/api_cn/single_distiller_api.rst b/docs/zh_cn/api_cn/single_distiller_api.rst new file mode 100644 index 0000000000000000000000000000000000000000..dce99541cbcede508d9953f2f308c664e71bdc56 --- /dev/null +++ b/docs/zh_cn/api_cn/single_distiller_api.rst @@ -0,0 +1,251 @@ +单进程蒸馏 +========= + +merge +--------- + +.. py:function:: paddleslim.dist.merge(teacher_program, student_program, data_name_map, place, scope=None, name_prefix='teacher_') + +`[源代码]
高通835 1.6-2倍加速
高通855 armv8 2倍加速
麒麟970 1.6-2倍加速 |[详细数据和模型下载]() | + +### 蒸馏主要结论 + +| 任务 | 模型 | 数据集 | 结论 | 更多细节和模型下载 | +|:--:|:---:|:--:|:--:|:--:| +| 分类| MobileNetV1 | ImageNet | top1 -0.39%
高通835 1.6-2倍加速
高通855 armv8 2倍加速
麒麟970 1.6-2倍加速 |[详细数据和模型下载]() | + +### 剪裁主要结论 + + +| 任务 | 模型 | 数据集 | 结论 | 更多细节和模型下载 | +|:--:|:---:|:--:|:--:|:--:| +| 分类| MobileNetV1 | ImageNet | top1 -0.39%
高通835 1.6-2倍加速
高通855 armv8 2倍加速
麒麟970 1.6-2倍加速 |[详细数据和模型下载]() | + +### nas 主要结论 + + +| 任务 | 模型 | 数据集 | 结论 | 更多细节和模型下载 | +|:--:|:---:|:--:|:--:|:--:| +| 分类| MobileNetV1 | ImageNet | top1 -0.39%
高通835 1.6-2倍加速
高通855 armv8 2倍加速
麒麟970 1.6-2倍加速 |[详细数据和模型下载]() | diff --git a/docs/zh_cn/model_zoo/nas_model_zoo.md b/docs/zh_cn/model_zoo/nas_model_zoo.md new file mode 100644 index 0000000000000000000000000000000000000000..f924d4167f0045878343d0afa9647b1bd0605144 --- /dev/null +++ b/docs/zh_cn/model_zoo/nas_model_zoo.md @@ -0,0 +1 @@ +# 模型结构搜索模型库 diff --git a/docs/zh_cn/model_zoo/prune_model_zoo.md b/docs/zh_cn/model_zoo/prune_model_zoo.md new file mode 100644 index 0000000000000000000000000000000000000000..c9e4c16f193923b838cf220317a3cef8f4693570 --- /dev/null +++ b/docs/zh_cn/model_zoo/prune_model_zoo.md @@ -0,0 +1 @@ +# 剪裁模型库 diff --git a/docs/zh_cn/model_zoo/quant_model_zoo.md b/docs/zh_cn/model_zoo/quant_model_zoo.md new file mode 100644 index 0000000000000000000000000000000000000000..c5062253a7ac12032e3b2e6df38d25758cc7fd10 --- /dev/null +++ b/docs/zh_cn/model_zoo/quant_model_zoo.md @@ -0,0 +1 @@ +# 量化模型库 diff --git a/docs/zh_cn/quick_start/distillation_tutorial.md b/docs/zh_cn/quick_start/distillation_tutorial.md new file mode 100755 index 0000000000000000000000000000000000000000..aa2dd3e9f33d6cb8dc87251c600eab1e88bfac59 --- /dev/null +++ b/docs/zh_cn/quick_start/distillation_tutorial.md @@ -0,0 +1,113 @@ +# 图像分类模型知识蒸馏-快速开始 + +该教程以图像分类模型MobileNetV1为例,说明如何快速使用[PaddleSlim的知识蒸馏接口](https://paddlepaddle.github.io/PaddleSlim/api/single_distiller_api/)。 +该示例包含以下步骤: + +1. 导入依赖 +2. 定义student_program和teacher_program +3. 选择特征图 +4. 合并program(merge)并添加蒸馏loss +5. 模型训练 + +以下章节依次介绍每个步骤的内容。 + +## 1. 导入依赖 + +PaddleSlim依赖Paddle1.7版本,请确认已正确安装Paddle,然后按以下方式导入Paddle和PaddleSlim: + +``` +import paddle +import paddle.fluid as fluid +import paddleslim as slim +``` + +## 2. 定义student_program和teacher_program + +本教程在MNIST数据集上进行知识蒸馏的训练和验证,输入图片尺寸为`[1, 28, 28]`,输出类别数为10。 +选择`ResNet50`作为teacher对`MobileNet`结构的student进行蒸馏训练。 + +```python +model = slim.models.MobileNet() +student_program = fluid.Program() +student_startup = fluid.Program() +with fluid.program_guard(student_program, student_startup): + image = fluid.data( + name='image', shape=[None] + [1, 28, 28], dtype='float32') + label = fluid.data(name='label', shape=[None, 1], dtype='int64') + out = model.net(input=image, class_dim=10) + cost = fluid.layers.cross_entropy(input=out, label=label) + avg_cost = fluid.layers.mean(x=cost) + acc_top1 = fluid.layers.accuracy(input=out, label=label, k=1) + acc_top5 = fluid.layers.accuracy(input=out, label=label, k=5) +``` + + + +```python +model = slim.models.ResNet50() +teacher_program = fluid.Program() +teacher_startup = fluid.Program() +with fluid.program_guard(teacher_program, teacher_startup): + with fluid.unique_name.guard(): + image = fluid.data( + name='image', shape=[None] + [1, 28, 28], dtype='float32') + predict = teacher_model.net(image, class_dim=10) +exe = fluid.Executor(fluid.CPUPlace()) +exe.run(teacher_startup) +``` + +## 3. 选择特征图 + +我们可以用student_的list_vars方法来观察其中全部的Variables,从中选出一个或多个变量(Variable)来拟合teacher相应的变量。 + +```python +# get all student variables +student_vars = [] +for v in student_program.list_vars(): + student_vars.append((v.name, v.shape)) +#uncomment the following lines to observe student's variables for distillation +#print("="*50+"student_model_vars"+"="*50) +#print(student_vars) + +# get all teacher variables +teacher_vars = [] +for v in teacher_program.list_vars(): + teacher_vars.append((v.name, v.shape)) +#uncomment the following lines to observe teacher's variables for distillation +#print("="*50+"teacher_model_vars"+"="*50) +#print(teacher_vars) +``` + +经过筛选我们可以看到,teacher_program中的'bn5c_branch2b.output.1.tmp_3'和student_program的'depthwise_conv2d_11.tmp_0'尺寸一致,可以组成蒸馏损失函数。 + +## 4. 合并program (merge)并添加蒸馏loss +merge操作将student_program和teacher_program中的所有Variables和Op都将被添加到同一个Program中,同时为了避免两个program中有同名变量会引起命名冲突,merge也会为teacher_program中的Variables添加一个同一的命名前缀name_prefix,其默认值是'teacher_' + +为了确保teacher网络和student网络输入的数据是一样的,merge操作也会对两个program的输入数据层进行合并操作,所以需要指定一个数据层名称的映射关系data_name_map,key是teacher的输入数据名称,value是student的 + +```python +data_name_map = {'image': 'image'} +main = slim.dist.merge(teacher_program, student_program, data_name_map, fluid.CPUPlace()) +with fluid.program_guard(student_program, student_startup): + l2_loss = slim.dist.l2_loss('teacher_bn5c_branch2b.output.1.tmp_3', 'depthwise_conv2d_11.tmp_0', student_program) + loss = l2_loss + avg_cost + opt = fluid.optimizer.Momentum(0.01, 0.9) + opt.minimize(loss) +exe.run(student_startup) +``` + +## 5. 模型训练 + +为了快速执行该示例,我们选取简单的MNIST数据,Paddle框架的`paddle.dataset.mnist`包定义了MNIST数据的下载和读取。 代码如下: + +```python +train_reader = paddle.fluid.io.batch( + paddle.dataset.mnist.train(), batch_size=128, drop_last=True) +train_feeder = fluid.DataFeeder(['image', 'label'], fluid.CPUPlace(), student_program) +``` + +```python +for data in train_reader(): + acc1, acc5, loss_np = exe.run(student_program, feed=train_feeder.feed(data), fetch_list=[acc_top1.name, acc_top5.name, loss.name]) + print("Acc1: {:.6f}, Acc5: {:.6f}, Loss: {:.6f}".format(acc1.mean(), acc5.mean(), loss_np.mean())) +``` diff --git a/docs/zh_cn/quick_start/index.rst b/docs/zh_cn/quick_start/index.rst new file mode 100644 index 0000000000000000000000000000000000000000..713218aa032c81885e08346df3fa6136d8aa96cf --- /dev/null +++ b/docs/zh_cn/quick_start/index.rst @@ -0,0 +1,13 @@ + +快速开始 +======== + +.. toctree:: + :maxdepth: 1 + + pruning_tutorial.md + distillation_tutorial.md + quant_aware_tutorial.md + quant_post_static_tutorial.md + nas_tutorial.md + diff --git a/docs/zh_cn/quick_start/nas_tutorial.md b/docs/zh_cn/quick_start/nas_tutorial.md new file mode 100644 index 0000000000000000000000000000000000000000..8fc0d6d084770c65a13f66932239bf65810a44fc --- /dev/null +++ b/docs/zh_cn/quick_start/nas_tutorial.md @@ -0,0 +1,156 @@ +# 图像分类网络结构搜索-快速开始 + +该教程以图像分类模型MobileNetV2为例,说明如何在cifar10数据集上快速使用[网络结构搜索接口](../api/nas_api.md)。 +该示例包含以下步骤: + +1. 导入依赖 +2. 初始化SANAS搜索实例 +3. 构建网络 +4. 定义输入数据函数 +5. 定义训练函数 +6. 定义评估函数 +7. 启动搜索实验 + 7.1 获取模型结构 + 7.2 构造program + 7.3 定义输入数据 + 7.4 训练模型 + 7.5 评估模型 + 7.6 回传当前模型的得分 +8. 完整示例 + + +以下章节依次介绍每个步骤的内容。 + +## 1. 导入依赖 +请确认已正确安装Paddle,导入需要的依赖包。 +```python +import paddle +import paddle.fluid as fluid +import paddleslim as slim +import numpy as np +``` + +## 2. 初始化SANAS搜索实例 +```python +sanas = slim.nas.SANAS(configs=[('MobileNetV2Space')], server_addr=("", 8337), save_checkpoint=None) +``` + +## 3. 构建网络 +根据传入的网络结构构造训练program和测试program。 +```python +def build_program(archs): + train_program = fluid.Program() + startup_program = fluid.Program() + with fluid.program_guard(train_program, startup_program): + data = fluid.data(name='data', shape=[None, 3, 32, 32], dtype='float32') + label = fluid.data(name='label', shape=[None, 1], dtype='int64') + output = archs(data) + output = fluid.layers.fc(input=output, size=10) + + softmax_out = fluid.layers.softmax(input=output, use_cudnn=False) + cost = fluid.layers.cross_entropy(input=softmax_out, label=label) + avg_cost = fluid.layers.mean(cost) + acc_top1 = fluid.layers.accuracy(input=softmax_out, label=label, k=1) + acc_top5 = fluid.layers.accuracy(input=softmax_out, label=label, k=5) + test_program = fluid.default_main_program().clone(for_test=True) + + optimizer = fluid.optimizer.Adam(learning_rate=0.1) + optimizer.minimize(avg_cost) + + place = fluid.CPUPlace() + exe = fluid.Executor(place) + exe.run(startup_program) + return exe, train_program, test_program, (data, label), avg_cost, acc_top1, acc_top5 +``` + +## 4. 定义输入数据函数 +使用的数据集为cifar10,paddle框架中`paddle.dataset.cifar`包括了cifar数据集的下载和读取,代码如下: +```python +def input_data(inputs): + train_reader = paddle.fluid.io.batch(paddle.reader.shuffle(paddle.dataset.cifar.train10(cycle=False), buf_size=1024),batch_size=256) + train_feeder = fluid.DataFeeder(inputs, fluid.CPUPlace()) + eval_reader = paddle.fluid.io.batch(paddle.dataset.cifar.test10(cycle=False), batch_size=256) + eval_feeder = fluid.DataFeeder(inputs, fluid.CPUPlace()) + return train_reader, train_feeder, eval_reader, eval_feeder +``` + +## 5. 定义训练函数 +根据训练program和训练数据进行训练。 +```python +def start_train(program, data_reader, data_feeder): + outputs = [avg_cost.name, acc_top1.name, acc_top5.name] + for data in data_reader(): + batch_reward = exe.run(program, feed=data_feeder.feed(data), fetch_list = outputs) + print("TRAIN: loss: {}, acc1: {}, acc5:{}".format(batch_reward[0], batch_reward[1], batch_reward[2])) +``` + +## 6. 定义评估函数 +根据评估program和评估数据进行评估。 +```python +def start_eval(program, data_reader, data_feeder): + reward = [] + outputs = [avg_cost.name, acc_top1.name, acc_top5.name] + for data in data_reader(): + batch_reward = exe.run(program, feed=data_feeder.feed(data), fetch_list = outputs) + reward_avg = np.mean(np.array(batch_reward), axis=1) + reward.append(reward_avg) + print("TEST: loss: {}, acc1: {}, acc5:{}".format(batch_reward[0], batch_reward[1], batch_reward[2])) + finally_reward = np.mean(np.array(reward), axis=0) + print("FINAL TEST: avg_cost: {}, acc1: {}, acc5: {}".format(finally_reward[0], finally_reward[1], finally_reward[2])) + return finally_reward +``` + +## 7. 启动搜索实验 +以下步骤拆解说明了如何获得当前模型结构以及获得当前模型结构之后应该有的步骤,如果想要看如何启动搜索实验的完整示例可以看步骤9。 + +### 7.1 获取模型结构 +调用`next_archs()`函数获取到下一个模型结构。 +```python +archs = sanas.next_archs()[0] +``` + +### 7.2 构造program +调用步骤3中的函数,根据4.1中的模型结构构造相应的program。 +```python +exe, train_program, eval_program, inputs, avg_cost, acc_top1, acc_top5 = build_program(archs) +``` + +### 7.3 定义输入数据 +```python +train_reader, train_feeder, eval_reader, eval_feeder = input_data(inputs) +``` + +### 7.4 训练模型 +根据上面得到的训练program和评估数据启动训练。 +```python +start_train(train_program, train_reader, train_feeder) +``` +### 7.5 评估模型 +根据上面得到的评估program和评估数据启动评估。 +```python +finally_reward = start_eval(eval_program, eval_reader, eval_feeder) +``` +### 7.6 回传当前模型的得分 +``` +sanas.reward(float(finally_reward[1])) +``` + +## 8. 完整示例 +以下是一个完整的搜索实验示例,示例中使用FLOPs作为约束条件,搜索实验一共搜索3个step,表示搜索到3个满足条件的模型结构进行训练,每搜索到一个网络结构训练7个epoch。 +```python +for step in range(3): + archs = sanas.next_archs()[0] + exe, train_program, eval_program, inputs, avg_cost, acc_top1, acc_top5 = build_program(archs) + train_reader, train_feeder, eval_reader, eval_feeder = input_data(inputs) + + current_flops = slim.analysis.flops(train_program) + if current_flops > 321208544: + continue + + for epoch in range(7): + start_train(train_program, train_reader, train_feeder) + + finally_reward = start_eval(eval_program, eval_reader, eval_feeder) + + sanas.reward(float(finally_reward[1])) +``` diff --git a/docs/zh_cn/quick_start/pruning_tutorial.md b/docs/zh_cn/quick_start/pruning_tutorial.md new file mode 100755 index 0000000000000000000000000000000000000000..051a740f4602f2175537efe5eaf22b62a06c10e7 --- /dev/null +++ b/docs/zh_cn/quick_start/pruning_tutorial.md @@ -0,0 +1,89 @@ +# 图像分类模型通道剪裁-快速开始 + +该教程以图像分类模型MobileNetV1为例,说明如何快速使用[PaddleSlim的卷积通道剪裁接口]()。 +该示例包含以下步骤: + +1. 导入依赖 +2. 构建模型 +3. 剪裁 +4. 训练剪裁后的模型 + +以下章节依次次介绍每个步骤的内容。 + +## 1. 导入依赖 + +PaddleSlim依赖Paddle1.7版本,请确认已正确安装Paddle,然后按以下方式导入Paddle和PaddleSlim: + +``` +import paddle +import paddle.fluid as fluid +import paddleslim as slim +``` + +## 2. 构建网络 + +该章节构造一个用于对MNIST数据进行分类的分类模型,选用`MobileNetV1`,并将输入大小设置为`[1, 28, 28]`,输出类别数为10。 +为了方便展示示例,我们在`paddleslim.models`下预定义了用于构建分类模型的方法,执行以下代码构建分类模型: + +``` +exe, train_program, val_program, inputs, outputs = + slim.models.image_classification("MobileNet", [1, 28, 28], 10, use_gpu=False) +``` + +>注意:paddleslim.models下的API并非PaddleSlim常规API,是为了简化示例而封装预定义的一系列方法,比如:模型结构的定义、Program的构建等。 + +## 3. 剪裁卷积层通道 + +### 3.1 计算剪裁之前的FLOPs + +``` +FLOPs = slim.analysis.flops(train_program) +print("FLOPs: {}".format(FLOPs)) +``` + +### 3.2 剪裁 + +我们这里对参数名为`conv2_1_sep_weights`和`conv2_2_sep_weights`的卷积层进行剪裁,分别剪掉20%和30%的通道数。 +代码如下所示: + +``` +pruner = slim.prune.Pruner() +pruned_program, _, _ = pruner.prune( + train_program, + fluid.global_scope(), + params=["conv2_1_sep_weights", "conv2_2_sep_weights"], + ratios=[0.33] * 2, + place=fluid.CPUPlace()) +``` + +以上操作会修改`train_program`中对应卷积层参数的定义,同时对`fluid.global_scope()`中存储的参数数组进行裁剪。 + +### 3.3 计算剪裁之后的FLOPs + +``` +FLOPs = paddleslim.analysis.flops(train_program) +print("FLOPs: {}".format(FLOPs)) +``` + +## 4. 训练剪裁后的模型 + +### 4.1 定义输入数据 + +为了快速执行该示例,我们选取简单的MNIST数据,Paddle框架的`paddle.dataset.mnist`包定义了MNIST数据的下载和读取。 +代码如下: + +``` +import paddle.dataset.mnist as reader +train_reader = paddle.fluid.io.batch( + reader.train(), batch_size=128, drop_last=True) +train_feeder = fluid.DataFeeder(inputs, fluid.CPUPlace()) +``` + +### 4.2 执行训练 +以下代码执行了一个`epoch`的训练: + +``` +for data in train_reader(): + acc1, acc5, loss = exe.run(pruned_program, feed=train_feeder.feed(data), fetch_list=outputs) + print(acc1, acc5, loss) +``` diff --git a/docs/zh_cn/quick_start/quant_aware_tutorial.md b/docs/zh_cn/quick_start/quant_aware_tutorial.md new file mode 100644 index 0000000000000000000000000000000000000000..bfafa2f4995bea098da7e365100c1aa87f4be451 --- /dev/null +++ b/docs/zh_cn/quick_start/quant_aware_tutorial.md @@ -0,0 +1,140 @@ +# 图像分类模型量化训练-快速开始 + +该教程以图像分类模型MobileNetV1为例,说明如何快速使用PaddleSlim的[量化训练接口](../api_cn/quantization_api.html)。 该示例包含以下步骤: + +1. 导入依赖 +2. 构建模型 +3. 训练模型 +4. 量化 +5. 训练和测试量化后的模型 +6. 保存量化后的模型 + +## 1. 导入依赖 +PaddleSlim依赖Paddle1.7版本,请确认已正确安装Paddle,然后按以下方式导入Paddle和PaddleSlim: + + +```python +import paddle +import paddle.fluid as fluid +import paddleslim as slim +import numpy as np +``` + +## 2. 构建网络 +该章节构造一个用于对MNIST数据进行分类的分类模型,选用`MobileNetV1`,并将输入大小设置为`[1, 28, 28]`,输出类别数为10。 为了方便展示示例,我们在`paddleslim.models`下预定义了用于构建分类模型的方法,执行以下代码构建分类模型: + +>注意:paddleslim.models下的API并非PaddleSlim常规API,是为了简化示例而封装预定义的一系列方法,比如:模型结构的定义、Program的构建等。 + + +```python +exe, train_program, val_program, inputs, outputs = \ + slim.models.image_classification("MobileNet", [1, 28, 28], 10, use_gpu=True) +``` + +## 3. 训练模型 +该章节介绍了如何定义输入数据和如何训练和测试分类模型。先训练分类模型的原因是量化训练过程是在训练好的模型上进行的,也就是说是在训练好的模型的基础上加入量化反量化op之后,用小学习率进行参数微调。 + +### 3.1 定义输入数据 + +为了快速执行该示例,我们选取简单的MNIST数据,Paddle框架的`paddle.dataset.mnist`包定义了MNIST数据的下载和读取。 +代码如下: + + +```python +import paddle.dataset.mnist as reader +train_reader = paddle.fluid.io.batch( + reader.train(), batch_size=128, drop_last=True) +test_reader = paddle.fluid.io.batch( + reader.train(), batch_size=128, drop_last=True) +train_feeder = fluid.DataFeeder(inputs, fluid.CPUPlace()) +``` + +### 3.2 训练和测试 +先定义训练和测试函数,正常训练和量化训练时只需要调用函数即可。在训练函数中执行了一个epoch的训练,因为MNIST数据集数据较少,一个epoch就可将top1精度训练到95%以上。 + + +```python +def train(prog): + iter = 0 + for data in train_reader(): + acc1, acc5, loss = exe.run(prog, feed=train_feeder.feed(data), fetch_list=outputs) + if iter % 100 == 0: + print('train iter={}, top1={}, top5={}, loss={}'.format(iter, acc1.mean(), acc5.mean(), loss.mean())) + iter += 1 + +def test(prog): + iter = 0 + res = [[], []] + for data in train_reader(): + acc1, acc5, loss = exe.run(prog, feed=train_feeder.feed(data), fetch_list=outputs) + if iter % 100 == 0: + print('test iter={}, top1={}, top5={}, loss={}'.format(iter, acc1.mean(), acc5.mean(), loss.mean())) + res[0].append(acc1.mean()) + res[1].append(acc5.mean()) + iter += 1 + print('final test result top1={}, top5={}'.format(np.array(res[0]).mean(), np.array(res[1]).mean())) +``` + +调用``train``函数训练分类网络,``train_program``是在第2步:构建网络中定义的。 + + +```python +train(train_program) +``` + + +调用``test``函数测试分类网络,``val_program``是在第2步:构建网络中定义的。 + + +```python +test(val_program) +``` + + +## 4. 量化 + +按照[默认配置](https://paddlepaddle.github.io/PaddleSlim/api_cn/quantization_api.html#id2)在``train_program``和``val_program``中加入量化和反量化op. + + +```python +quant_program = slim.quant.quant_aware(train_program, exe.place, for_test=False) +val_quant_program = slim.quant.quant_aware(val_program, exe.place, for_test=True) +``` + + +## 5. 训练和测试量化后的模型 +微调量化后的模型,训练一个epoch后测试。 + + +```python +train(quant_program) +``` + + +测试量化后的模型,和``3.2 训练和测试``中得到的测试结果相比,精度相近,达到了无损量化。 + + +```python +test(val_quant_program) +``` + + +## 6. 保存量化后的模型 + +在``4. 量化``中使用接口``slim.quant.quant_aware``接口得到的模型只适合训练时使用,为了得到最终使用时的模型,需要使用[slim.quant.convert](https://paddlepaddle.github.io/PaddleSlim/api_cn/quantization_api.html#convert)接口,然后使用[fluid.io.save_inference_model](https://www.paddlepaddle.org.cn/documentation/docs/zh/develop/api_cn/io_cn/save_inference_model_cn.html#save-inference-model)保存模型。``float_prog``的参数数据类型是float32,但是数据范围是int8, 保存之后可使用fluid或者paddle-lite加载使用,paddle-lite在使用时,会先将类型转换为int8。``int8_prog``的参数数据类型是int8, 保存后可看到量化后模型大小,不可加载使用。 + + +```python +float_prog, int8_prog = slim.quant.convert(val_quant_program, exe.place, save_int8=True) +target_vars = [float_prog.global_block().var(outputs[-1])] +fluid.io.save_inference_model(dirname='./inference_model/float', + feeded_var_names=[inputs[0].name], + target_vars=target_vars, + executor=exe, + main_program=float_prog) +fluid.io.save_inference_model(dirname='./inference_model/int8', + feeded_var_names=[inputs[0].name], + target_vars=target_vars, + executor=exe, + main_program=int8_prog) +``` diff --git a/docs/zh_cn/quick_start/quant_post_static_tutorial.md b/docs/zh_cn/quick_start/quant_post_static_tutorial.md new file mode 100755 index 0000000000000000000000000000000000000000..5f042f80a0d3c34ce14dc4d526484499707b5a13 --- /dev/null +++ b/docs/zh_cn/quick_start/quant_post_static_tutorial.md @@ -0,0 +1,130 @@ + # 图像分类模型静态离线量化-快速开始 + +该教程以图像分类模型MobileNetV1为例,说明如何快速使用PaddleSlim的[静态离线量化接口](../api_cn/quantization_api.html#quant-post-static)。 该示例包含以下步骤: + +1. 导入依赖 +2. 构建模型 +3. 训练模型 +4. 静态离线量化 + +## 1. 导入依赖 +PaddleSlim依赖Paddle1.7版本,请确认已正确安装Paddle,然后按以下方式导入Paddle和PaddleSlim: + + +```python +import paddle +import paddle.fluid as fluid +import paddleslim as slim +import numpy as np +``` + +## 2. 构建网络 +该章节构造一个用于对MNIST数据进行分类的分类模型,选用`MobileNetV1`,并将输入大小设置为`[1, 28, 28]`,输出类别数为10。为了方便展示示例,我们在`paddleslim.models`下预定义了用于构建分类模型的方法,执行以下代码构建分类模型: + +>注意:paddleslim.models下的API并非PaddleSlim常规API,是为了简化示例而封装预定义的一系列方法,比如:模型结构的定义、Program的构建等。 + + +```python +exe, train_program, val_program, inputs, outputs = \ + slim.models.image_classification("MobileNet", [1, 28, 28], 10, use_gpu=True) +``` + +## 3. 训练模型 +该章节介绍了如何定义输入数据和如何训练和测试分类模型。先训练分类模型的原因是离线量化需要一个训练好的模型。 + +### 3.1 定义输入数据 + +为了快速执行该示例,我们选取简单的MNIST数据,Paddle框架的`paddle.dataset.mnist`包定义了MNIST数据的下载和读取。 +代码如下: + + +```python +import paddle.dataset.mnist as reader +train_reader = paddle.fluid.io.batch( + reader.train(), batch_size=128, drop_last=True) +test_reader = paddle.fluid.io.batch( + reader.train(), batch_size=128, drop_last=True) +train_feeder = fluid.DataFeeder(inputs, fluid.CPUPlace()) +``` + +### 3.2 训练和测试 +先定义训练和测试函数。在训练函数中执行了一个epoch的训练,因为MNIST数据集数据较少,一个epoch就可将top1精度训练到95%以上。 + + + +```python +def train(prog): + iter = 0 + for data in train_reader(): + acc1, acc5, loss = exe.run(prog, feed=train_feeder.feed(data), fetch_list=outputs) + if iter % 100 == 0: + print('train', acc1.mean(), acc5.mean(), loss.mean()) + iter += 1 + +def test(prog, outputs=outputs): + iter = 0 + res = [[], []] + for data in train_reader(): + acc1, acc5, loss = exe.run(prog, feed=train_feeder.feed(data), fetch_list=outputs) + if iter % 100 == 0: + print('test', acc1.mean(), acc5.mean(), loss.mean()) + res[0].append(acc1.mean()) + res[1].append(acc5.mean()) + iter += 1 + print('final test result', np.array(res[0]).mean(), np.array(res[1]).mean()) +``` + +调用``train``函数训练分类网络,``train_program``是在第2步:构建网络中定义的。 + + +```python +train(train_program) +``` + + +调用``test``函数测试分类网络,``val_program``是在第2步:构建网络中定义的。 + + +```python +test(val_program) +``` + + +保存inference model,将训练好的分类模型保存在``'./inference_model'``下,后续进行静态离线量化时将加载保存在此处的模型。 + + +```python +target_vars = [val_program.global_block().var(name) for name in outputs] +fluid.io.save_inference_model(dirname='./inference_model', + feeded_var_names=[var.name for var in inputs], + target_vars=target_vars, + executor=exe, + main_program=val_program) +``` + +## 4. 静态离线量化 + +调用静态离线量化接口,加载文件夹``'./inference_model'``训练好的分类模型,并使用10个batch的数据进行参数校正。此过程无需训练,只需跑前向过程来计算量化所需参数。静态离线量化后的模型保存在文件夹``'./quant_post_static_model'``下。 + + +```python +slim.quant.quant_post_static( + executor=exe, + model_dir='./inference_model', + quantize_model_path='./quant_post_static_model', + sample_generator=reader.test(), + batch_nums=10) +``` + + +加载保存在文件夹``'./quant_post_static_model'``下的量化后的模型进行测试,可看到精度和``3.2 训练和测试``中得到的测试精度相近,因此静态离线量化过程对于此分类模型几乎无损。 + + +```python +quant_post_static_prog, feed_target_names, fetch_targets = fluid.io.load_inference_model( + dirname='./quant_post_static_model', + model_filename='__model__', + params_filename='__params__', + executor=exe) +test(quant_post_static_prog, fetch_targets) +``` diff --git a/docs/zh_cn/tutorials/image_classification_mkldnn_quant_tutorial.md b/docs/zh_cn/tutorials/image_classification_mkldnn_quant_tutorial.md new file mode 100644 index 0000000000000000000000000000000000000000..2a8eaa2e269cbe1a8a949ce14fa871b878d9d5dc --- /dev/null +++ b/docs/zh_cn/tutorials/image_classification_mkldnn_quant_tutorial.md @@ -0,0 +1,43 @@ +# Intel CPU上部署量化模型教程 + +在Intel Casecade Lake机器上(如:Intel(R) Xeon(R) Gold 6271),经过量化和DNNL加速,INT8模型在单线程上性能为FP32模型的3~3.7倍;在Intel SkyLake机器上(如:Intel(R) Xeon(R) Gold 6148),单线程性能为FP32模型的1.5倍,而精度仅有极小下降。图像分类量化的样例教程请参考[图像分类INT8模型在CPU优化部署和预测](https://github.com/PaddlePaddle/PaddleSlim/tree/develop/demo/mkldnn_quant/)。自然语言处理模型的量化请参考[ERNIE INT8 模型精度与性能复现](https://github.com/PaddlePaddle/benchmark/tree/master/Inference/c%2B%2B/ernie/mkldnn) + +## 图像分类INT8模型在 Xeon(R) 6271 上的精度和性能 + +>**图像分类INT8模型在 Intel(R) Xeon(R) Gold 6271 上精度** + +| Model | FP32 Top1 Accuracy | INT8 Top1 Accuracy | Top1 Diff | FP32 Top5 Accuracy | INT8 Top5 Accuracy | Top5 Diff | +|:------------:|:------------------:|:------------------:|:---------:|:------------------:|:------------------:|:---------:| +| MobileNet-V1 | 70.78% | 70.74% | -0.04% | 89.69% | 89.43% | -0.26% | +| MobileNet-V2 | 71.90% | 72.21% | 0.31% | 90.56% | 90.62% | 0.06% | +| ResNet101 | 77.50% | 77.60% | 0.10% | 93.58% | 93.55% | -0.03% | +| ResNet50 | 76.63% | 76.50% | -0.13% | 93.10% | 92.98% | -0.12% | +| VGG16 | 72.08% | 71.74% | -0.34% | 90.63% | 89.71% | -0.92% | +| VGG19 | 72.57% | 72.12% | -0.45% | 90.84% | 90.15% | -0.69% | + +>**图像分类INT8模型在 Intel(R) Xeon(R) Gold 6271 单核上性能** + +| Model | FP32 (images/s) | INT8 (images/s) | Ratio (INT8/FP32) | +|:------------:|:---------------:|:---------------:|:-----------------:| +| MobileNet-V1 | 74.05 | 216.36 | 2.92 | +| MobileNet-V2 | 88.60 | 205.84 | 2.32 | +| ResNet101 | 7.20 | 26.48 | 3.68 | +| ResNet50 | 13.23 | 50.02 | 3.78 | +| VGG16 | 3.47 | 10.67 | 3.07 | +| VGG19 | 2.83 | 9.09 | 3.21 | + +## 自然语言处理INT8模型在 Xeon(R) 6271 上的精度和性能 + +>**I. Ernie INT8 DNNL 在 Intel(R) Xeon(R) Gold 6271 的精度结果** + +| Model | FP32 Accuracy | INT8 Accuracy | Accuracy Diff | +| :---: | :-----------: | :-----------: | :-----------: | +| Ernie | 80.20% | 79.44% | -0.76% | + + +>**II. Ernie INT8 DNNL 在 Intel(R) Xeon(R) Gold 6271 上单样本耗时** + +| Threads | FP32 Latency (ms) | INT8 Latency (ms) | Ratio (FP32/INT8) | +| :--------: | :---------------: | :---------------: | :---------------: | +| 1 thread | 237.21 | 79.26 | 2.99X | +| 20 threads | 22.08 | 12.57 | 1.76X | diff --git a/docs/zh_cn/tutorials/image_classification_nas_quick_start.ipynb b/docs/zh_cn/tutorials/image_classification_nas_quick_start.ipynb new file mode 100644 index 0000000000000000000000000000000000000000..fceccb98fbb201bd873cf34478a7f396110e427a --- /dev/null +++ b/docs/zh_cn/tutorials/image_classification_nas_quick_start.ipynb @@ -0,0 +1,407 @@ +{ + "cells": [ + { + "cell_type": "markdown", + "metadata": {}, + "source": [ + "# 图像分类网络结构搜索-快速开始\n", + "\n", + "该教程以图像分类模型MobileNetV2为例,说明如何在cifar10数据集上快速使用[网络结构搜索接口](../api/nas_api.md)。\n", + "该示例包含以下步骤:\n", + "\n", + "1. 导入依赖\n", + "2. 初始化SANAS搜索实例\n", + "3. 构建网络\n", + "4. 定义输入数据函数\n", + "5. 定义训练函数\n", + "6. 定义评估函数\n", + "7. 启动搜索实验\n", + " 7.1 获取模型结构\n", + " 7.2 构造program\n", + " 7.3 定义输入数据\n", + " 7.4 训练模型\n", + " 7.5 评估模型\n", + " 7.6 回传当前模型的得分\n", + "8. 完整示例\n", + "\n", + "\n", + "以下章节依次介绍每个步骤的内容。" + ] + }, + { + "cell_type": "markdown", + "metadata": {}, + "source": [ + "## 1. 导入依赖\n", + "请确认已正确安装Paddle,导入需要的依赖包。" + ] + }, + { + "cell_type": "code", + "execution_count": 1, + "metadata": {}, + "outputs": [], + "source": [ + "import paddle\n", + "import paddle.fluid as fluid\n", + "import paddleslim as slim\n", + "import numpy as np" + ] + }, + { + "cell_type": "markdown", + "metadata": {}, + "source": [ + "## 2. 初始化SANAS搜索实例" + ] + }, + { + "cell_type": "code", + "execution_count": 2, + "metadata": {}, + "outputs": [ + { + "name": "stderr", + "output_type": "stream", + "text": [ + "2020-02-07 08:42:37,895-INFO: range table: ([0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0], [7, 5, 8, 6, 2, 5, 8, 6, 2, 5, 8, 6, 2, 5, 10, 6, 2, 5, 10, 6, 2, 5, 12, 6, 2])\n", + "2020-02-07 08:42:37,897-INFO: ControllerServer - listen on: [10.255.125.38:8339]\n", + "2020-02-07 08:42:37,899-INFO: Controller Server run...\n" + ] + } + ], + "source": [ + "sanas = slim.nas.SANAS(configs=[('MobileNetV2Space')], server_addr=(\"\", 8339), save_checkpoint=None)" + ] + }, + { + "cell_type": "markdown", + "metadata": {}, + "source": [ + "## 3. 构建网络\n", + "根据传入的网络结构构造训练program和测试program。" + ] + }, + { + "cell_type": "code", + "execution_count": 3, + "metadata": {}, + "outputs": [], + "source": [ + "def build_program(archs):\n", + " train_program = fluid.Program()\n", + " startup_program = fluid.Program()\n", + " with fluid.program_guard(train_program, startup_program):\n", + " data = fluid.data(name='data', shape=[None, 3, 32, 32], dtype='float32')\n", + " label = fluid.data(name='label', shape=[None, 1], dtype='int64')\n", + " output = archs(data)\n", + " output = fluid.layers.fc(input=output, size=10)\n", + "\n", + " softmax_out = fluid.layers.softmax(input=output, use_cudnn=False)\n", + " cost = fluid.layers.cross_entropy(input=softmax_out, label=label)\n", + " avg_cost = fluid.layers.mean(cost)\n", + " acc_top1 = fluid.layers.accuracy(input=softmax_out, label=label, k=1)\n", + " acc_top5 = fluid.layers.accuracy(input=softmax_out, label=label, k=5)\n", + " test_program = fluid.default_main_program().clone(for_test=True)\n", + "\n", + " optimizer = fluid.optimizer.Adam(learning_rate=0.1)\n", + " optimizer.minimize(avg_cost)\n", + "\n", + " place = fluid.CPUPlace()\n", + " exe = fluid.Executor(place)\n", + " exe.run(startup_program)\n", + " return exe, train_program, test_program, (data, label), avg_cost, acc_top1, acc_top5" + ] + }, + { + "cell_type": "markdown", + "metadata": {}, + "source": [ + "## 4. 定义输入数据函数\n", + "使用的数据集为cifar10,paddle框架中`paddle.dataset.cifar`包括了cifar数据集的下载和读取,代码如下:" + ] + }, + { + "cell_type": "code", + "execution_count": 4, + "metadata": {}, + "outputs": [], + "source": [ + "def input_data(inputs):\n", + " train_reader = paddle.fluid.io.batch(paddle.reader.shuffle(paddle.dataset.cifar.train10(cycle=False), buf_size=1024),batch_size=256)\n", + " train_feeder = fluid.DataFeeder(inputs, fluid.CPUPlace())\n", + " eval_reader = paddle.fluid.io.batch(paddle.dataset.cifar.test10(cycle=False), batch_size=256)\n", + " eval_feeder = fluid.DataFeeder(inputs, fluid.CPUPlace())\n", + " return train_reader, train_feeder, eval_reader, eval_feeder" + ] + }, + { + "cell_type": "markdown", + "metadata": {}, + "source": [ + "## 5. 定义训练函数\n", + "根据训练program和训练数据进行训练。" + ] + }, + { + "cell_type": "code", + "execution_count": 5, + "metadata": {}, + "outputs": [], + "source": [ + "def start_train(program, data_reader, data_feeder):\n", + " outputs = [avg_cost.name, acc_top1.name, acc_top5.name]\n", + " for data in data_reader():\n", + " batch_reward = exe.run(program, feed=data_feeder.feed(data), fetch_list = outputs)\n", + " print(\"TRAIN: loss: {}, acc1: {}, acc5:{}\".format(batch_reward[0], batch_reward[1], batch_reward[2]))" + ] + }, + { + "cell_type": "markdown", + "metadata": {}, + "source": [ + "## 6. 定义评估函数\n", + "根据评估program和评估数据进行评估。" + ] + }, + { + "cell_type": "code", + "execution_count": 6, + "metadata": {}, + "outputs": [], + "source": [ + "def start_eval(program, data_reader, data_feeder):\n", + " reward = []\n", + " outputs = [avg_cost.name, acc_top1.name, acc_top5.name]\n", + " for data in data_reader():\n", + " batch_reward = exe.run(program, feed=data_feeder.feed(data), fetch_list = outputs)\n", + " reward_avg = np.mean(np.array(batch_reward), axis=1)\n", + " reward.append(reward_avg)\n", + " print(\"TEST: loss: {}, acc1: {}, acc5:{}\".format(batch_reward[0], batch_reward[1], batch_reward[2]))\n", + " finally_reward = np.mean(np.array(reward), axis=0)\n", + " print(\"FINAL TEST: avg_cost: {}, acc1: {}, acc5: {}\".format(finally_reward[0], finally_reward[1], finally_reward[2]))\n", + " return finally_reward" + ] + }, + { + "cell_type": "markdown", + "metadata": {}, + "source": [ + "## 7. 启动搜索实验\n", + "以下步骤拆解说明了如何获得当前模型结构以及获得当前模型结构之后应该有的步骤,如果想要看如何启动搜索实验的完整示例可以看步骤9。\n", + "\n", + "### 7.1 获取模型结构\n", + "调用`next_archs()`函数获取到下一个模型结构。" + ] + }, + { + "cell_type": "code", + "execution_count": 7, + "metadata": {}, + "outputs": [ + { + "name": "stderr", + "output_type": "stream", + "text": [ + "2020-02-07 08:42:45,035-INFO: current tokens: [4, 4, 5, 1, 0, 4, 4, 2, 0, 4, 4, 3, 0, 4, 5, 2, 0, 4, 7, 2, 0, 4, 9, 0, 0]\n" + ] + } + ], + "source": [ + "archs = sanas.next_archs()[0]" + ] + }, + { + "cell_type": "markdown", + "metadata": {}, + "source": [ + "### 7.2 构造program" + ] + }, + { + "cell_type": "code", + "execution_count": 12, + "metadata": {}, + "outputs": [], + "source": [ + "exe, train_program, eval_program, inputs, avg_cost, acc_top1, acc_top5 = build_program(archs)" + ] + }, + { + "cell_type": "markdown", + "metadata": {}, + "source": [ + "### 7.3 定义输入数据" + ] + }, + { + "cell_type": "code", + "execution_count": 13, + "metadata": {}, + "outputs": [], + "source": [ + "train_reader, train_feeder, eval_reader, eval_feeder = input_data(inputs)" + ] + }, + { + "cell_type": "markdown", + "metadata": {}, + "source": [ + "### 7.4 训练模型\n", + "据上面得到的训练program和评估数据启动训练。" + ] + }, + { + "cell_type": "code", + "execution_count": 14, + "metadata": {}, + "outputs": [ + { + "name": "stdout", + "output_type": "stream", + "text": [ + "TRAIN: loss: [2.7999306], acc1: [0.1015625], acc5:[0.44140625]\n" + ] + } + ], + "source": [ + "start_train(train_program, train_reader, train_feeder)" + ] + }, + { + "cell_type": "markdown", + "metadata": {}, + "source": [ + "### 7.5 评估模型\n", + "根据上面得到的评估program和评估数据启动评估。" + ] + }, + { + "cell_type": "code", + "execution_count": 15, + "metadata": {}, + "outputs": [ + { + "name": "stdout", + "output_type": "stream", + "text": [ + "TEST: loss: [49.99942], acc1: [0.078125], acc5:[0.46484375]\n", + "FINAL TEST: avg_cost: 49.999420166, acc1: 0.078125, acc5: 0.46484375\n" + ] + } + ], + "source": [ + "finally_reward = start_eval(eval_program, eval_reader, eval_feeder)" + ] + }, + { + "cell_type": "markdown", + "metadata": {}, + "source": [ + "### 7.6 回传当前模型的得分" + ] + }, + { + "cell_type": "code", + "execution_count": 16, + "metadata": {}, + "outputs": [ + { + "name": "stderr", + "output_type": "stream", + "text": [ + "2020-02-07 08:44:26,774-INFO: Controller - iter: 1; best_reward: 0.078125, best tokens: [4, 4, 5, 1, 0, 4, 4, 2, 0, 4, 4, 3, 0, 4, 5, 2, 0, 4, 7, 2, 0, 4, 9, 0, 0], current_reward: 0.078125; current tokens: [4, 4, 5, 1, 0, 4, 4, 2, 0, 4, 4, 3, 0, 4, 5, 2, 0, 4, 7, 2, 0, 4, 9, 0, 0]\n" + ] + }, + { + "data": { + "text/plain": [ + "True" + ] + }, + "execution_count": 16, + "metadata": {}, + "output_type": "execute_result" + } + ], + "source": [ + "sanas.reward(float(finally_reward[1]))" + ] + }, + { + "cell_type": "markdown", + "metadata": {}, + "source": [ + "## 8. 完整示例\n", + "以下是一个完整的搜索实验示例,示例中使用FLOPs作为约束条件,搜索实验一共搜索3个step,表示搜索到3个满足条件的模型结构进行训练,每搜>索到一个网络结构训练7个epoch。" + ] + }, + { + "cell_type": "code", + "execution_count": null, + "metadata": {}, + "outputs": [ + { + "name": "stderr", + "output_type": "stream", + "text": [ + "2020-02-07 08:45:06,927-INFO: current tokens: [4, 4, 5, 1, 0, 4, 4, 2, 0, 4, 4, 3, 1, 4, 5, 2, 0, 4, 7, 2, 0, 4, 9, 0, 0]\n" + ] + }, + { + "name": "stdout", + "output_type": "stream", + "text": [ + "TRAIN: loss: [2.6932292], acc1: [0.08203125], acc5:[0.51953125]\n", + "TRAIN: loss: [42.387478], acc1: [0.078125], acc5:[0.47265625]\n" + ] + } + ], + "source": [ + "for step in range(3):\n", + " archs = sanas.next_archs()[0]\n", + " exe, train_program, eval_progarm, inputs, avg_cost, acc_top1, acc_top5 = build_program(archs)\n", + " train_reader, train_feeder, eval_reader, eval_feeder = input_data(inputs)\n", + "\n", + " current_flops = slim.analysis.flops(train_program)\n", + " if current_flops > 321208544:\n", + " continue\n", + "\n", + " for epoch in range(7):\n", + " start_train(train_program, train_reader, train_feeder)\n", + "\n", + " finally_reward = start_eval(eval_program, eval_reader, eval_feeder)\n", + "\n", + " sanas.reward(float(finally_reward[1]))" + ] + }, + { + "cell_type": "code", + "execution_count": null, + "metadata": {}, + "outputs": [], + "source": [] + } + ], + "metadata": { + "kernelspec": { + "display_name": "Python 2", + "language": "python", + "name": "python2" + }, + "language_info": { + "codemirror_mode": { + "name": "ipython", + "version": 2 + }, + "file_extension": ".py", + "mimetype": "text/x-python", + "name": "python", + "nbconvert_exporter": "python", + "pygments_lexer": "ipython2", + "version": "2.7.12" + } + }, + "nbformat": 4, + "nbformat_minor": 2 +} diff --git a/docs/zh_cn/tutorials/image_classification_sensitivity_analysis_tutorial.md b/docs/zh_cn/tutorials/image_classification_sensitivity_analysis_tutorial.md new file mode 100644 index 0000000000000000000000000000000000000000..6bde2f8ca4615554152aacf2983c8c5d6f369ff0 --- /dev/null +++ b/docs/zh_cn/tutorials/image_classification_sensitivity_analysis_tutorial.md @@ -0,0 +1,269 @@ +# 图像分类模型通道剪裁-敏感度分析 + +该教程以图像分类模型MobileNetV1为例,说明如何快速使用[PaddleSlim的敏感度分析接口](https://paddlepaddle.github.io/PaddleSlim/api/prune_api/#sensitivity)。 +该示例包含以下步骤: + +1. 导入依赖 +2. 构建模型 +3. 定义输入数据 +4. 定义模型评估方法 +5. 训练模型 +6. 获取待分析卷积参数名称 +7. 分析敏感度 +8. 剪裁模型 + +以下章节依次介绍每个步骤的内容。 + +## 1. 导入依赖 + +PaddleSlim依赖Paddle1.7版本,请确认已正确安装Paddle,然后按以下方式导入Paddle和PaddleSlim: + + +```python +import paddle +import paddle.fluid as fluid +import paddleslim as slim +``` + +## 2. 构建网络 + +该章节构造一个用于对MNIST数据进行分类的分类模型,选用`MobileNetV1`,并将输入大小设置为`[1, 28, 28]`,输出类别数为10。 +为了方便展示示例,我们在`paddleslim.models`下预定义了用于构建分类模型的方法,执行以下代码构建分类模型: + + +```python +exe, train_program, val_program, inputs, outputs = slim.models.image_classification("MobileNet", [1, 28, 28], 10, use_gpu=True) +place = fluid.CUDAPlace(0) +``` + +## 3 定义输入数据 + +为了快速执行该示例,我们选取简单的MNIST数据,Paddle框架的`paddle.dataset.mnist`包定义了MNIST数据的下载和读取。 +代码如下: + + +```python +import paddle.dataset.mnist as reader +train_reader = paddle.fluid.io.batch( + reader.train(), batch_size=128, drop_last=True) +test_reader = paddle.fluid.io.batch( + reader.test(), batch_size=128, drop_last=True) +data_feeder = fluid.DataFeeder(inputs, place) +``` + +## 4. 定义模型评估方法 + +在计算敏感度时,需要裁剪单个卷积层后的模型在测试数据上的效果,我们定义以下方法实现该功能: + + +```python +import numpy as np +def test(program): + acc_top1_ns = [] + acc_top5_ns = [] + for data in test_reader(): + acc_top1_n, acc_top5_n, _ = exe.run( + program, + feed=data_feeder.feed(data), + fetch_list=outputs) + acc_top1_ns.append(np.mean(acc_top1_n)) + acc_top5_ns.append(np.mean(acc_top5_n)) + print("Final eva - acc_top1: {}; acc_top5: {}".format( + np.mean(np.array(acc_top1_ns)), np.mean(np.array(acc_top5_ns)))) + return np.mean(np.array(acc_top1_ns)) +``` + +## 5. 训练模型 + +只有训练好的模型才能做敏感度分析,因为该示例任务相对简单,我这里用训练一个`epoch`产出的模型做敏感度分析。对于其它训练比较耗时的模型,您可以加载训练好的模型权重。 + +以下为模型训练代码: + + +```python +for data in train_reader(): + acc1, acc5, loss = exe.run(train_program, feed=data_feeder.feed(data), fetch_list=outputs) +print(np.mean(acc1), np.mean(acc5), np.mean(loss)) +``` + +用上节定义的模型评估方法,评估当前模型在测试集上的精度: + + +```python +test(val_program) +``` + +## 6. 获取待分析卷积参数 + +```python +params = [] +for param in train_program.global_block().all_parameters(): + if "_sep_weights" in param.name: + params.append(param.name) +print(params) +params = params[:5] +``` + +## 7. 分析敏感度 + +### 7.1 简单计算敏感度 + +调用[sensitivity接口](https://paddlepaddle.github.io/PaddleSlim/api/prune_api/#sensitivity)对训练好的模型进行敏感度分析。 + +在计算过程中,敏感度信息会不断追加保存到选项`sensitivities_file`指定的文件中,该文件中已有的敏感度信息不会被重复计算。 + +先用以下命令删除当前路径下可能已有的`sensitivities_0.data`文件: + + +```python +!rm -rf sensitivities_0.data +``` + +除了指定待分析的卷积层参数,我们还可以指定敏感度分析的粒度和范围,即单个卷积层参数分别被剪裁掉的比例。 + +如果待分析的模型比较敏感,剪掉单个卷积层的40%的通道,模型在测试集上的精度损失就达90%,那么`pruned_ratios`最大设置到0.4即可,比如: +`[0.1, 0.2, 0.3, 0.4]` + +为了得到更精确的敏感度信息,我可以适当调小`pruned_ratios`的粒度,比如:`[0.1, 0.15, 0.2, 0.25, 0.3, 0.35, 0.4]` + +`pruned_ratios`的粒度越小,计算敏感度的速度越慢。 + + +```python +sens_0 = slim.prune.sensitivity( + val_program, + place, + params, + test, + sensitivities_file="sensitivities_0.data", + pruned_ratios=[0.1, 0.2]) +print(sens_0) +``` + +### 7.2 扩展敏感度信息 + +第7.1节计算敏感度用的是`pruned_ratios=[0.1, 0.2]`, 我们可以在此基础上将其扩展到`[0.1, 0.2, 0.3]` + + +```python +sens_0 = slim.prune.sensitivity( + val_program, + place, + params, + test, + sensitivities_file="sensitivities_0.data", + pruned_ratios=[0.3]) +print(sens_0) +``` + +### 7.3 多进程加速计算敏感度信息 + +敏感度分析所用时间取决于待分析的卷积层数量和模型评估的速度,我们可以通过多进程的方式加速敏感度计算。 + +在不同的进程设置不同`pruned_ratios`, 然后将结果合并。 + +#### 7.3.1 多进程计算敏感度 + +在以上章节,我们计算了`pruned_ratios=[0.1, 0.2, 0.3]`的敏感度,并将其保存到了文件`sensitivities_0.data`中。 + +在另一个进程中,我们可以设置`pruned_ratios=[0.4]`,并将结果保存在文件`sensitivities_1.data`中。代码如下: + + +```python +sens_1 = slim.prune.sensitivity( + val_program, + place, + params, + test, + sensitivities_file="sensitivities_1.data", + pruned_ratios=[0.4]) +print(sens_1) +``` + +#### 7.3.2 加载多个进程产出的敏感度文件 + +```python +s_0 = slim.prune.load_sensitivities("sensitivities_0.data") +s_1 = slim.prune.load_sensitivities("sensitivities_1.data") +print(s_0) +print(s_1) +``` + +#### 7.3.3 合并敏感度信息 + + +```python +s = slim.prune.merge_sensitive([s_0, s_1]) +print(s) +``` + +## 8. 剪裁模型 + +根据以上章节产出的敏感度信息,对模型进行剪裁。 + +### 8.1 计算剪裁率 + +首先,调用PaddleSlim提供的[get_ratios_by_loss](https://paddlepaddle.github.io/PaddleSlim/api/prune_api/#get_ratios_by_loss)方法根据敏感度计算剪裁率,通过调整参数`loss`大小获得合适的一组剪裁率: + + +```python +loss = 0.01 +ratios = slim.prune.get_ratios_by_loss(s_0, loss) +print(ratios) +``` + +### 8.2 剪裁训练网络 + + +```python +pruner = slim.prune.Pruner() +print("FLOPs before pruning: {}".format(slim.analysis.flops(train_program))) +pruned_program, _, _ = pruner.prune( + train_program, + fluid.global_scope(), + params=ratios.keys(), + ratios=ratios.values(), + place=place) +print("FLOPs after pruning: {}".format(slim.analysis.flops(pruned_program))) +``` + +### 8.3 剪裁测试网络 + +>注意:对测试网络进行剪裁时,需要将`only_graph`设置为True,具体原因请参考[Pruner API文档](https://paddlepaddle.github.io/PaddleSlim/api/prune_api/#pruner) + + +```python +pruner = slim.prune.Pruner() +print("FLOPs before pruning: {}".format(slim.analysis.flops(val_program))) +pruned_val_program, _, _ = pruner.prune( + val_program, + fluid.global_scope(), + params=ratios.keys(), + ratios=ratios.values(), + place=place, + only_graph=True) +print("FLOPs after pruning: {}".format(slim.analysis.flops(pruned_val_program))) +``` + +测试一下剪裁后的模型在测试集上的精度: + +```python +test(pruned_val_program) +``` + +### 8.4 训练剪裁后的模型 + +对剪裁后的模型在训练集上训练一个`epoch`: + + +```python +for data in train_reader(): + acc1, acc5, loss = exe.run(pruned_program, feed=data_feeder.feed(data), fetch_list=outputs) +print(np.mean(acc1), np.mean(acc5), np.mean(loss)) +``` + +测试训练后模型的精度: + +```python +test(pruned_val_program) +``` diff --git a/docs/zh_cn/tutorials/index.rst b/docs/zh_cn/tutorials/index.rst new file mode 100644 index 0000000000000000000000000000000000000000..8e8036add2c96d031def2ea6a4a3cf3e07a97b8f --- /dev/null +++ b/docs/zh_cn/tutorials/index.rst @@ -0,0 +1,16 @@ + +进阶教程 +======== + +.. toctree:: + :maxdepth: 1 + + image_classification_sensitivity_analysis_tutorial.md + darts_nas_turorial.md + paddledetection_slim_distillation_tutorial.md + paddledetection_slim_nas_tutorial.md + paddledetection_slim_pruing_tutorial.md + paddledetection_slim_prune_dist_tutorial.md + paddledetection_slim_quantization_tutorial.md + image_classification_mkldnn_quant_tutorial.md + paddledetection_slim_sensitivy_tutorial.md diff --git a/docs/zh_cn/tutorials/paddledetection_slim_distillation_tutorial.md b/docs/zh_cn/tutorials/paddledetection_slim_distillation_tutorial.md new file mode 100644 index 0000000000000000000000000000000000000000..dbdd30fff6b4b014e907a3af234735597a20db63 --- /dev/null +++ b/docs/zh_cn/tutorials/paddledetection_slim_distillation_tutorial.md @@ -0,0 +1,32 @@ +# 目标检测模型蒸馏教程 + +教程内容请参考:https://github.com/PaddlePaddle/PaddleDetection/blob/release/0.2/slim/distillation/README.md + + +## 示例结果 + +### MobileNetV1-YOLO-V3-VOC + +| FLOPS |输入尺寸|每张GPU图片个数|推理时间(fps)|Box AP|下载| +|:-:|:-:|:-:|:-:|:-:|:-:| +|baseline|608 |16|104.291|76.2|[下载链接](https://paddlemodels.bj.bcebos.com/object_detection/yolov3_mobilenet_v1_voc.tar)| +|蒸馏后|608 |16|106.914|79.0|[下载链接](https://paddlemodels.bj.bcebos.com/PaddleSlim/yolov3_mobilenetv1_voc_distilled.tar)| +|baseline|416 |16|-|76.7|[下载链接](https://paddlemodels.bj.bcebos.com/object_detection/yolov3_mobilenet_v1_voc.tar)| +|蒸馏后|416 |16|-|78.2|[下载链接](https://paddlemodels.bj.bcebos.com/PaddleSlim/yolov3_mobilenetv1_voc_distilled.tar)| +|baseline|320 |16|-|75.3|[下载链接](https://paddlemodels.bj.bcebos.com/object_detection/yolov3_mobilenet_v1_voc.tar)| +|蒸馏后|320 |16|-|75.5|[下载链接](https://paddlemodels.bj.bcebos.com/PaddleSlim/yolov3_mobilenetv1_voc_distilled.tar)| + +> 蒸馏后的结果用ResNet34-YOLO-V3做teacher,4GPU总batch_size64训练90000 iter得到 + +### MobileNetV1-YOLO-V3-COCO + +| FLOPS |输入尺寸|每张GPU图片个数|推理时间(fps)|Box AP|下载| +|:-:|:-:|:-:|:-:|:-:|:-:| +|baseline|608 |16|78.302|29.3|[下载链接](https://paddlemodels.bj.bcebos.com/object_detection/yolov3_mobilenet_v1_voc.tar)| +|蒸馏后|608 |16|78.523|31.4|[下载链接](https://paddlemodels.bj.bcebos.com/PaddleSlim/yolov3_mobilenetv1_coco_distilled.tar)| +|baseline|416 |16|-|29.3|[下载链接](https://paddlemodels.bj.bcebos.com/object_detection/yolov3_mobilenet_v1_voc.tar)| +|蒸馏后|416 |16|-|30.0|[下载链接](https://paddlemodels.bj.bcebos.com/PaddleSlim/yolov3_mobilenetv1_coco_distilled.tar)| +|baseline|320 |16|-|27.0|[下载链接](https://paddlemodels.bj.bcebos.com/object_detection/yolov3_mobilenet_v1_voc.tar)| +|蒸馏后|320 |16|-|27.1|[下载链接](https://paddlemodels.bj.bcebos.com/PaddleSlim/yolov3_mobilenetv1_coco_distilled.tar)| + +> 蒸馏后的结果用ResNet34-YOLO-V3做teacher,4GPU总batch_size64训练600000 iter得到 diff --git a/docs/zh_cn/tutorials/paddledetection_slim_nas_tutorial.md b/docs/zh_cn/tutorials/paddledetection_slim_nas_tutorial.md new file mode 100644 index 0000000000000000000000000000000000000000..b4aa6ad133f7cadc744c11912850c66f5868dc19 --- /dev/null +++ b/docs/zh_cn/tutorials/paddledetection_slim_nas_tutorial.md @@ -0,0 +1,8 @@ +# 人脸检测模型小模型结构搜索教程 + +教程内容请参考:https://github.com/PaddlePaddle/PaddleDetection/blob/release/0.2/slim/nas/README.md + +## 概述 + +我们选取人脸检测的BlazeFace模型作为神经网络搜索示例,该示例使用PaddleSlim 辅助完成神经网络搜索实验。 +基于PaddleSlim进行搜索实验过程中,搜索限制条件可以选择是浮点运算数(FLOPs)限制还是硬件延时(latency)限制,硬件延时限制需要提供延时表。本示例提供一份基于blazeface搜索空间的硬件延时表,名称是latency_855.txt(基于PaddleLite在骁龙855上测试的延时),可以直接用该表进行blazeface的硬件延时搜索实验。 diff --git a/docs/zh_cn/tutorials/paddledetection_slim_pruing_tutorial.md b/docs/zh_cn/tutorials/paddledetection_slim_pruing_tutorial.md new file mode 100644 index 0000000000000000000000000000000000000000..defd371ccef152a00670cab2c93aa8745688bae0 --- /dev/null +++ b/docs/zh_cn/tutorials/paddledetection_slim_pruing_tutorial.md @@ -0,0 +1,3 @@ +# 目标检测模型卷积通道剪裁教程 + +请参考:https://github.com/PaddlePaddle/PaddleDetection/blob/release/0.2/slim/prune/README.md diff --git a/docs/zh_cn/tutorials/paddledetection_slim_prune_dist_tutorial.md b/docs/zh_cn/tutorials/paddledetection_slim_prune_dist_tutorial.md new file mode 100644 index 0000000000000000000000000000000000000000..5697e968da17681d1f8b4f0cdb38eb2a8d19a43d --- /dev/null +++ b/docs/zh_cn/tutorials/paddledetection_slim_prune_dist_tutorial.md @@ -0,0 +1,7 @@ +# 目标检测模型蒸馏剪裁教程 + +教程内容请参考:https://github.com/PaddlePaddle/PaddleDetection/blob/release/0.2/slim/extensions/distill_pruned_model/README.md + +## 概述 + +该文档介绍如何使用PaddleSlim的蒸馏接口和卷积通道剪裁接口对检测库中的模型进行卷积层的通道剪裁并使用较高精度模型对其蒸馏。 diff --git a/docs/zh_cn/tutorials/paddledetection_slim_quantization_tutorial.md b/docs/zh_cn/tutorials/paddledetection_slim_quantization_tutorial.md new file mode 100644 index 0000000000000000000000000000000000000000..63e17a15746caeab3f83eed934dee7b996e1c869 --- /dev/null +++ b/docs/zh_cn/tutorials/paddledetection_slim_quantization_tutorial.md @@ -0,0 +1,28 @@ +# 目标检测模型量化教程 + +教程内容请参考:https://github.com/PaddlePaddle/PaddleDetection/blob/release/0.2/slim/quantization/README.md + + +## 示例结果 + +### 训练策略 + +- 量化策略`post`为使用静态离线量化方法得到的模型,`aware`为在线量化训练方法得到的模型。 + +### YOLOv3 on COCO + +| 骨架网络 | 预训练权重 | 量化策略 | 输入尺寸 | Box AP | 下载 | +| :----------------| :--------: | :------: | :------: |:------: | :-----------------------------------------------------: | +| MobileNetV1 | ImageNet | post | 608 | 27.9 | [下载链接](https://paddlemodels.bj.bcebos.com/PaddleSlim/yolov3_mobilenetv1_coco_quant_post.tar) | +| MobileNetV1 | ImageNet | post | 416 | 28.0 | [下载链接](https://paddlemodels.bj.bcebos.com/PaddleSlim/yolov3_mobilenetv1_coco_quant_post.tar) | +| MobileNetV1 | ImageNet | post | 320 | 26.0 | [下载链接](https://paddlemodels.bj.bcebos.com/PaddleSlim/yolov3_mobilenetv1_coco_quant_post.tar) | +| MobileNetV1 | ImageNet | aware | 608 | 28.1 | [下载链接](https://paddlemodels.bj.bcebos.com/PaddleSlim/yolov3_mobilenetv1_coco_quant_aware.tar) | +| MobileNetV1 | ImageNet | aware | 416 | 28.2 | [下载链接](https://paddlemodels.bj.bcebos.com/PaddleSlim/yolov3_mobilenetv1_coco_quant_aware.tar) | +| MobileNetV1 | ImageNet | aware | 320 | 25.8 | [下载链接](https://paddlemodels.bj.bcebos.com/PaddleSlim/yolov3_mobilenetv1_coco_quant_aware.tar) | +| ResNet34 | ImageNet | post | 608 | 35.7 | [下载链接](https://paddlemodels.bj.bcebos.com/PaddleSlim/yolov3_r34_coco_quant_post.tar) | +| ResNet34 | ImageNet | aware | 608 | 35.2 | [下载链接](https://paddlemodels.bj.bcebos.com/PaddleSlim/yolov3_r34_coco_quant_aware.tar) | +| ResNet34 | ImageNet | aware | 416 | 33.3 | [下载链接](https://paddlemodels.bj.bcebos.com/PaddleSlim/yolov3_r34_coco_quant_aware.tar) | +| ResNet34 | ImageNet | aware | 320 | 30.3 | [下载链接](https://paddlemodels.bj.bcebos.com/PaddleSlim/yolov3_r34_coco_quant_aware.tar) | +| R50vd-dcn | object365 | aware | 608 | 40.6 | [下载链接](https://paddlemodels.bj.bcebos.com/PaddleSlim/yolov3_r50vd_dcn_obj365_pretrained_coco_quant_aware.tar) | +| R50vd-dcn | object365 | aware | 416 | 37.5 | [下载链接](https://paddlemodels.bj.bcebos.com/PaddleSlim/yolov3_r50vd_dcn_obj365_pretrained_coco_quant_aware.tar) | +| R50vd-dcn | object365 | aware | 320 | 34.1 | [下载链接](https://paddlemodels.bj.bcebos.com/PaddleSlim/yolov3_r50vd_dcn_obj365_pretrained_coco_quant_aware.tar) | diff --git a/docs/zh_cn/tutorials/paddledetection_slim_sensitivy_tutorial.md b/docs/zh_cn/tutorials/paddledetection_slim_sensitivy_tutorial.md new file mode 100644 index 0000000000000000000000000000000000000000..5e2c7bd54c8f5344f2348bc397a5da569548512c --- /dev/null +++ b/docs/zh_cn/tutorials/paddledetection_slim_sensitivy_tutorial.md @@ -0,0 +1,3 @@ +# 目标检测模型敏感度分析教程 + +教程内容请参考:https://github.com/PaddlePaddle/PaddleDetection/blob/release/0.2/slim/sensitive/README.md diff --git a/docs/zh_cn/tutorials/sanas_darts_space.ipynb b/docs/zh_cn/tutorials/sanas_darts_space.ipynb new file mode 100644 index 0000000000000000000000000000000000000000..658124b5ceea1b0e48fe488faffd2fbfa9b6584e --- /dev/null +++ b/docs/zh_cn/tutorials/sanas_darts_space.ipynb @@ -0,0 +1,324 @@ +{ + "cells": [ + { + "cell_type": "code", + "execution_count": 19, + "metadata": {}, + "outputs": [], + "source": [ + "import paddle\n", + "import paddle.fluid as fluid\n", + "from paddleslim.nas import SANAS\n", + "import numpy as np\n", + "\n", + "BATCH_SIZE=96\n", + "SERVER_ADDRESS = \"\"\n", + "PORT = 8377\n", + "SEARCH_STEPS = 300\n", + "RETAIN_EPOCH=30\n", + "MAX_PARAMS=3.77\n", + "IMAGE_SHAPE=[3, 32, 32]\n", + "AUXILIARY = True\n", + "AUXILIARY_WEIGHT= 0.4\n", + "TRAINSET_NUM = 50000\n", + "LR = 0.025\n", + "MOMENTUM = 0.9\n", + "WEIGHT_DECAY = 0.0003\n", + "DROP_PATH_PROBILITY = 0.2" + ] + }, + { + "cell_type": "code", + "execution_count": 2, + "metadata": {}, + "outputs": [ + { + "name": "stderr", + "output_type": "stream", + "text": [ + "2020-02-23 12:28:09,752-INFO: range table: ([0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0], [14, 14, 14, 14, 14, 14, 14, 14, 14, 14, 14, 14, 14, 14, 14, 14, 14, 14, 14, 14])\n", + "2020-02-23 12:28:09,754-INFO: ControllerServer - listen on: [127.0.0.1:8377]\n", + "2020-02-23 12:28:09,756-INFO: Controller Server run...\n" + ] + } + ], + "source": [ + "config = [('DartsSpace')]\n", + "sa_nas = SANAS(config, server_addr=(SERVER_ADDRESS, PORT), search_steps=SEARCH_STEPS, is_server=True)" + ] + }, + { + "cell_type": "code", + "execution_count": 3, + "metadata": {}, + "outputs": [], + "source": [ + "def count_parameters_in_MB(all_params, prefix='model'):\n", + " parameters_number = 0\n", + " for param in all_params:\n", + " if param.name.startswith(\n", + " prefix) and param.trainable and 'aux' not in param.name:\n", + " parameters_number += np.prod(param.shape)\n", + " return parameters_number / 1e6" + ] + }, + { + "cell_type": "code", + "execution_count": 4, + "metadata": {}, + "outputs": [], + "source": [ + "def create_data_loader(IMAGE_SHAPE, is_train):\n", + " image = fluid.data(\n", + " name=\"image\", shape=[None] + IMAGE_SHAPE, dtype=\"float32\")\n", + " label = fluid.data(name=\"label\", shape=[None, 1], dtype=\"int64\")\n", + " data_loader = fluid.io.DataLoader.from_generator(\n", + " feed_list=[image, label],\n", + " capacity=64,\n", + " use_double_buffer=True,\n", + " iterable=True)\n", + " drop_path_prob = ''\n", + " drop_path_mask = ''\n", + " if is_train:\n", + " drop_path_prob = fluid.data(\n", + " name=\"drop_path_prob\", shape=[BATCH_SIZE, 1], dtype=\"float32\")\n", + " drop_path_mask = fluid.data(\n", + " name=\"drop_path_mask\",\n", + " shape=[BATCH_SIZE, 20, 4, 2],\n", + " dtype=\"float32\")\n", + "\n", + " return data_loader, image, label, drop_path_prob, drop_path_mask" + ] + }, + { + "cell_type": "code", + "execution_count": 5, + "metadata": {}, + "outputs": [], + "source": [ + "def build_program(main_program, startup_program, IMAGE_SHAPE, archs, is_train):\n", + " with fluid.program_guard(main_program, startup_program):\n", + " data_loader, data, label, drop_path_prob, drop_path_mask = create_data_loader(\n", + " IMAGE_SHAPE, is_train)\n", + " logits, logits_aux = archs(data, drop_path_prob, drop_path_mask,\n", + " is_train, 10)\n", + " top1 = fluid.layers.accuracy(input=logits, label=label, k=1)\n", + " top5 = fluid.layers.accuracy(input=logits, label=label, k=5)\n", + " loss = fluid.layers.reduce_mean(\n", + " fluid.layers.softmax_with_cross_entropy(logits, label))\n", + "\n", + " if is_train:\n", + " if AUXILIARY:\n", + " loss_aux = fluid.layers.reduce_mean(\n", + " fluid.layers.softmax_with_cross_entropy(logits_aux, label))\n", + " loss = loss + AUXILIARY_WEIGHT * loss_aux\n", + " step_per_epoch = int(TRAINSET_NUM / BATCH_SIZE)\n", + " learning_rate = fluid.layers.cosine_decay(LR, step_per_epoch, RETAIN_EPOCH)\n", + " fluid.clip.set_gradient_clip(\n", + " clip=fluid.clip.GradientClipByGlobalNorm(clip_norm=5.0))\n", + " optimizer = fluid.optimizer.MomentumOptimizer(\n", + " learning_rate,\n", + " MOMENTUM,\n", + " regularization=fluid.regularizer.L2DecayRegularizer(\n", + " WEIGHT_DECAY))\n", + " optimizer.minimize(loss)\n", + " outs = [loss, top1, top5, learning_rate]\n", + " else:\n", + " outs = [loss, top1, top5]\n", + " return outs, data_loader" + ] + }, + { + "cell_type": "code", + "execution_count": 27, + "metadata": {}, + "outputs": [], + "source": [ + "def train(main_prog, exe, epoch_id, train_loader, fetch_list):\n", + " loss = []\n", + " top1 = []\n", + " top5 = []\n", + " for step_id, data in enumerate(train_loader()):\n", + " devices_num = len(data)\n", + " if DROP_PATH_PROBILITY > 0:\n", + " feed = []\n", + " for device_id in range(devices_num):\n", + " image = data[device_id]['image']\n", + " label = data[device_id]['label']\n", + " drop_path_prob = np.array(\n", + " [[DROP_PATH_PROBILITY * epoch_id / RETAIN_EPOCH]\n", + " for i in range(BATCH_SIZE)]).astype(np.float32)\n", + " drop_path_mask = 1 - np.random.binomial(\n", + " 1, drop_path_prob[0],\n", + " size=[BATCH_SIZE, 20, 4, 2]).astype(np.float32)\n", + " feed.append({\n", + " \"image\": image,\n", + " \"label\": label,\n", + " \"drop_path_prob\": drop_path_prob,\n", + " \"drop_path_mask\": drop_path_mask\n", + " })\n", + " else:\n", + " feed = data\n", + " loss_v, top1_v, top5_v, lr = exe.run(\n", + " main_prog, feed=feed, fetch_list=[v.name for v in fetch_list])\n", + " loss.append(loss_v)\n", + " top1.append(top1_v)\n", + " top5.append(top5_v)\n", + " if step_id % 10 == 0:\n", + " print(\n", + " \"Train Epoch {}, Step {}, Lr {:.8f}, loss {:.6f}, acc_1 {:.6f}, acc_5 {:.6f}\".\n", + " format(epoch_id, step_id, lr[0], np.mean(loss), np.mean(top1), np.mean(top5)))\n", + " return np.mean(top1)" + ] + }, + { + "cell_type": "code", + "execution_count": 23, + "metadata": {}, + "outputs": [], + "source": [ + "def valid(main_prog, exe, epoch_id, valid_loader, fetch_list):\n", + " loss = []\n", + " top1 = []\n", + " top5 = []\n", + " for step_id, data in enumerate(valid_loader()):\n", + " loss_v, top1_v, top5_v = exe.run(\n", + " main_prog, feed=data, fetch_list=[v.name for v in fetch_list])\n", + " loss.append(loss_v)\n", + " top1.append(top1_v)\n", + " top5.append(top5_v)\n", + " if step_id % 10 == 0:\n", + " print(\n", + " \"Valid Epoch {}, Step {}, loss {:.6f}, acc_1 {:.6f}, acc_5 {:.6f}\".\n", + " format(epoch_id, step_id, np.mean(loss), np.mean(top1), np.mean(top5)))\n", + " return np.mean(top1)" + ] + }, + { + "cell_type": "code", + "execution_count": 8, + "metadata": {}, + "outputs": [ + { + "name": "stderr", + "output_type": "stream", + "text": [ + "2020-02-23 12:28:57,462-INFO: current tokens: [5, 5, 5, 5, 5, 12, 7, 7, 7, 7, 7, 7, 7, 10, 10, 10, 10, 10, 10, 10]\n" + ] + } + ], + "source": [ + "archs = sa_nas.next_archs()[0]" + ] + }, + { + "cell_type": "code", + "execution_count": 9, + "metadata": {}, + "outputs": [], + "source": [ + "train_program = fluid.Program()\n", + "test_program = fluid.Program()\n", + "startup_program = fluid.Program()\n", + "train_fetch_list, train_loader = build_program(train_program, startup_program, IMAGE_SHAPE, archs, is_train=True)\n", + "test_fetch_list, test_loader = build_program(test_program, startup_program, IMAGE_SHAPE, archs, is_train=False)\n", + "test_program = test_program.clone(for_test=True)" + ] + }, + { + "cell_type": "code", + "execution_count": 10, + "metadata": {}, + "outputs": [ + { + "data": { + "text/plain": [ + "[]" + ] + }, + "execution_count": 10, + "metadata": {}, + "output_type": "execute_result" + } + ], + "source": [ + "place = fluid.CPUPlace()\n", + "exe = fluid.Executor(place)\n", + "exe.run(startup_program)" + ] + }, + { + "cell_type": "code", + "execution_count": 17, + "metadata": {}, + "outputs": [ + { + "data": { + "text/plain": [ + "
- : The next searched tokens.
"""
raise NotImplementedError('Abstract method.')
+
+
+class RLBaseController(object):
+ """ Base Controller for reforcement learning"""
+
+ def next_tokens(self, *args, **kwargs):
+ raise NotImplementedError('Abstract method.')
+
+ def update(self, *args, **kwargs):
+ raise NotImplementedError('Abstract method.')
+
+ def save_controller(self, program, output_dir):
+ fluid.save(program, output_dir)
+
+ def load_controller(self, program, load_dir):
+ fluid.load(program, load_dir)
+
+ def get_params(self, program):
+ var_dict = {}
+ for var in program.global_block().all_parameters():
+ var_dict[var.name] = np.array(fluid.global_scope().find_var(
+ var.name).get_tensor())
+ return var_dict
+
+ def set_params(self, program, params_dict, place):
+ for var in program.global_block().all_parameters():
+ fluid.global_scope().find_var(var.name).get_tensor().set(
+ params_dict[var.name], place)
diff --git a/paddleslim/common/controller_client.py b/paddleslim/common/controller_client.py
index 15c36386f1f6a754a0e0f50f119410287ed14642..ceb6ecf54ac82035b71ec92d3e2b796f82f2fdcf 100644
--- a/paddleslim/common/controller_client.py
+++ b/paddleslim/common/controller_client.py
@@ -12,6 +12,8 @@
# See the License for the specific language governing permissions and
# limitations under the License.
+import os
+import time
import logging
import socket
from .log_helper import get_logger
@@ -24,45 +26,103 @@ _logger = get_logger(__name__, level=logging.INFO)
class ControllerClient(object):
"""
Controller client.
+ Args:
+ server_ip(str): The ip that controller server listens on. None means getting the ip automatically. Default: None.
+ server_port(int): The port that controller server listens on. 0 means getting usable port automatically. Default: 0.
+ key(str): The key used to identify legal agent for controller server. Default: "light-nas"
+ client_name(str): Current client name, random generate for counting client number. Default: None.
"""
- def __init__(self, server_ip=None, server_port=None, key=None):
+ START = True
+
+ def __init__(self,
+ server_ip=None,
+ server_port=None,
+ key=None,
+ client_name=None):
"""
- Args:
- server_ip(str): The ip that controller server listens on. None means getting the ip automatically. Default: None.
- server_port(int): The port that controller server listens on. 0 means getting usable port automatically. Default: 0.
- key(str): The key used to identify legal agent for controller server. Default: "light-nas"
"""
self.server_ip = server_ip
self.server_port = server_port
- self.socket_client = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
self._key = key
+ self._client_name = client_name
def update(self, tokens, reward, iter):
"""
Update the controller according to latest tokens and reward.
+
Args:
tokens(list
- : A list of token. The length and range based on search space.:
+ Returns:
+ list
- : A list of token. The length and range based on search space.:
+ Returns:
+ list
+ 
+ The architecture for one online knowledge distillation system based on Pantheon +
+
+## Prerequisites
+
+- Python 2.7.x or 3.x
+- PaddlePaddle >= 1.7.0
+- System: MacOS/Linux
+
+## APIs
+
+Pantheon defines two classes **Teacher** and **Student** for the communication and knowledge transfer between teacher and student.
+
+- **Teacher**: used by the teacher model. Can receive queries from student and write out the knowledge from teacher model via TCP/IP port (online mode) or into a local file (offline mode).
+- **Student**: used by the student model. Can receive and merge the knowledge from teachers, and feed the student model along with local data for training.
+
+Usually, the public methods of these two classes work in the pairwise way. Their mapping relations and suitable working modes are listed in the following table.
+
+ + The architecture for one online knowledge distillation system based on Pantheon +
| Teacher | +Student | +Supported Graph | +Mode | +remarks | +||
|---|---|---|---|---|---|---|
| static | +dynamic | +online | +offline | +|||
| __init__( out_path=None, out_port=None) |
+ __init__( merge_strategy=None) |
+ [1] | +||||
| + | register_teacher(
+ in_path=None, + in_address=None) + |
+ [2] | +||||
| start() | +start() | +[3] | +||||
| send(data) | +recv(teacher_id) | +[4] | +||||
| recv() | +send(data, + teacher_ids=None) + |
+ [5] | +||||
| dump(knowledge) | ++ | [6] | +||||
| start_knowledge_service(
+ feed_list, + schema, + program, + reader_config, + exe, + buf_size=10, + use_fp16=False, + times=1) |
+ get_knowledge_desc() | +[7] | +||||
| get_knowledge_qsize() | +||||||
| get_knowledge_generator( batch_size, + drop_last=False) |
+ ||||||