Merge remote-tracking branch 'origin/dygraph' into dygraph
Showing
doc/doc_ch/application.md
已删除
100644 → 0
{kind=link}
{kind=link}
| W: | H:
| W: | H:
{kind=link}
{kind=link}
| W: | H:
| W: | H:
{kind=link}

96.6 KB
{kind=link}
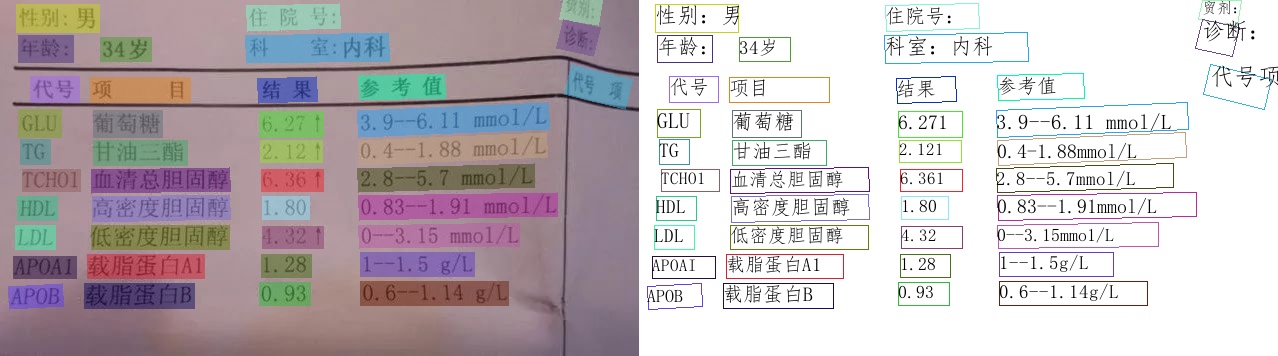
138.7 KB
{kind=link}

88.7 KB
{kind=link}
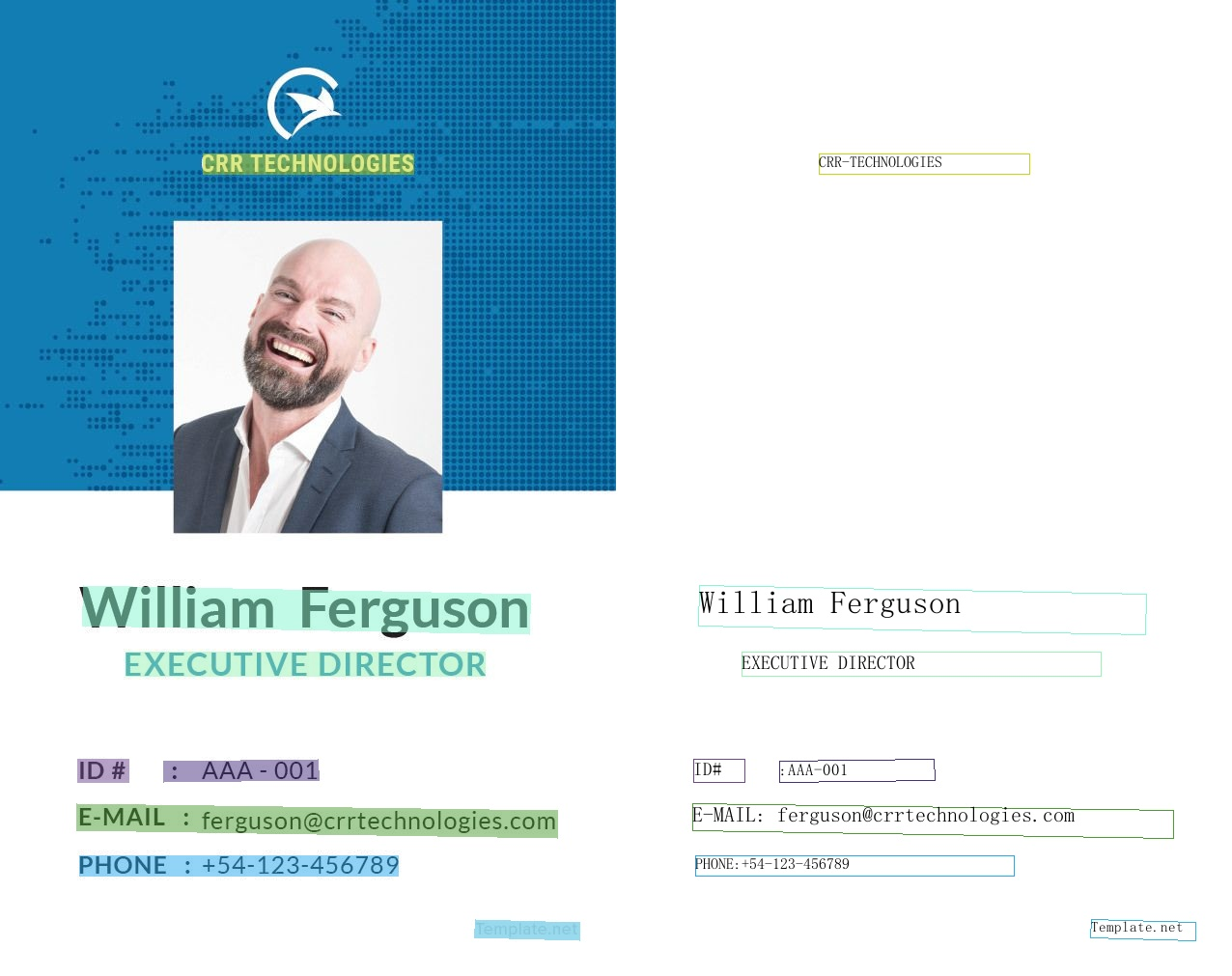
635.9 KB
{kind=link}

626.3 KB
{kind=link}

497.6 KB
{kind=link}

281.6 KB
{kind=link}

478.1 KB
{kind=link}

158.4 KB
{kind=link}
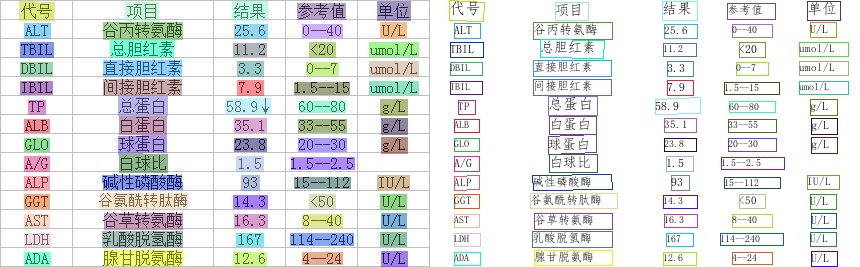
116.8 KB
{kind=link}

160.4 KB
{kind=link}

279.4 KB
{kind=link}

170.4 KB
{kind=link}

63.8 KB
doc/ppocr_v3/GTC_en.png
0 → 100644
{kind=link}
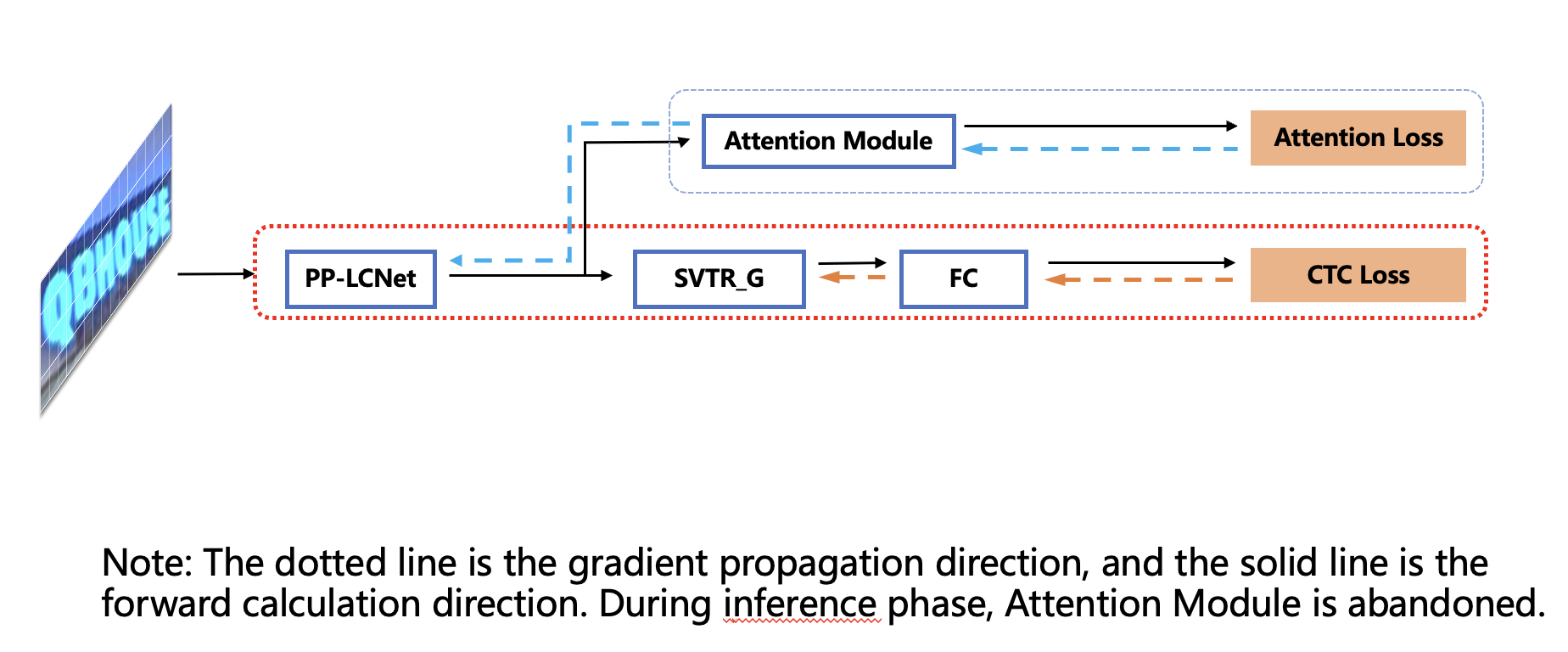
166.5 KB
doc/ppocr_v3/LCNet_SVTR_en.png
0 → 100644
{kind=link}
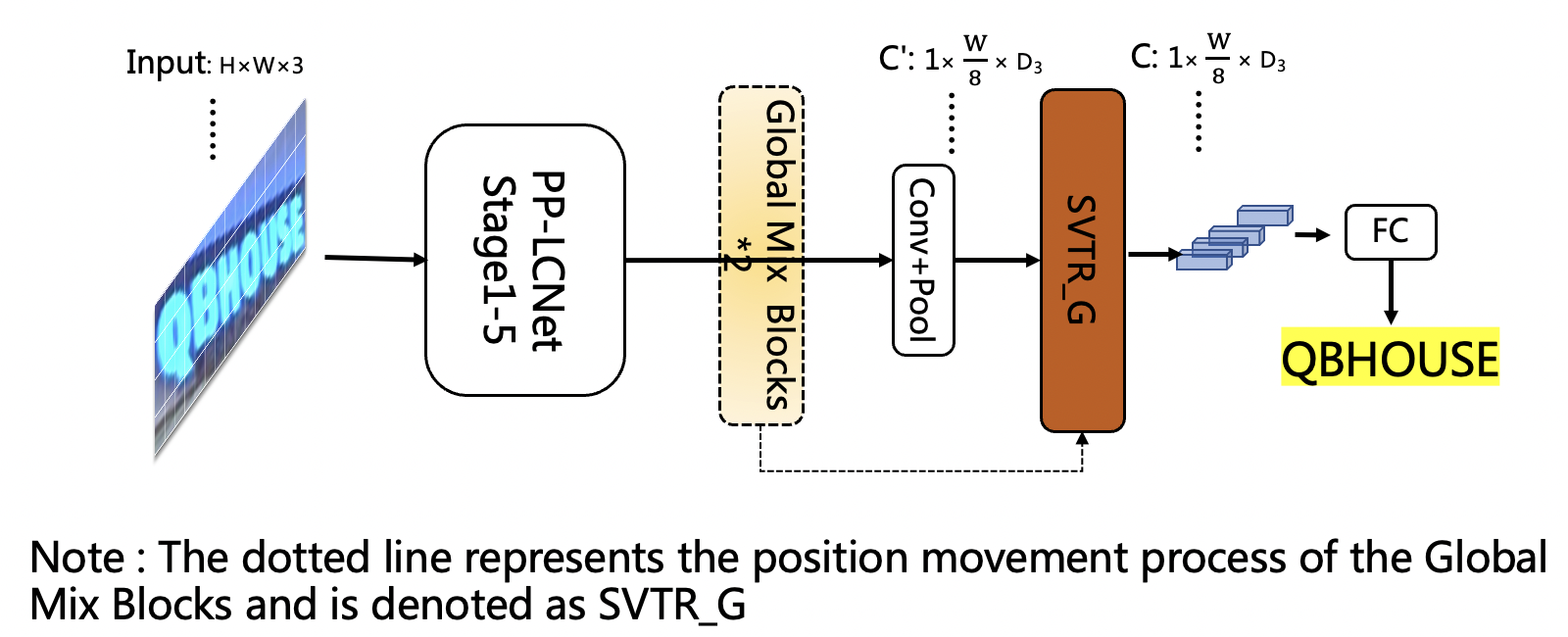
499.6 KB
{kind=link}

762.2 KB
ppstructure/recovery/README.md
0 → 100644
ppstructure/recovery/README_ch.md
0 → 100644
ppstructure/recovery/docx.py
0 → 100644