The datasets contain three citation networks: CORA, PUBMED, CITESEER. The details for these three datasets can be found in the [paper](https://arxiv.org/abs/1609.02907).
### Dependencies
- paddlepaddle>=1.4 (The speed can be faster in 1.5.)
- pgl
### Performance
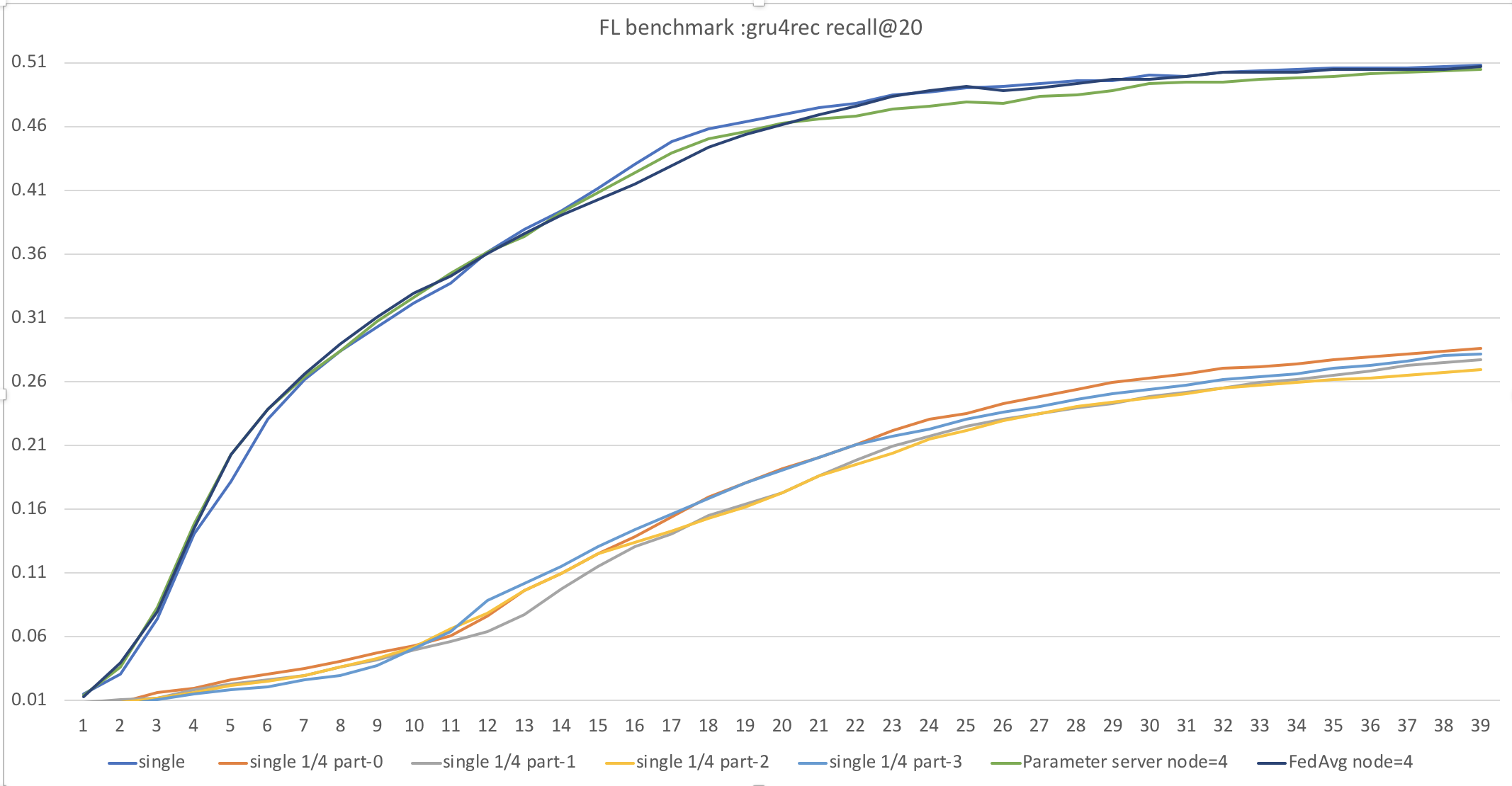
We train gru4rec model with FedAvg Strategy for 40 epochs. We use first 1/20 rsc15 data as our dataset including 40w session and 3w7 item dictionary. We also constuct baselines including standard single mode and distributed parameter server mode.
We train our models for 200 epochs and report the accuracy on the test dataset.
| Dataset | Accuracy | Speed with paddle 1.4 <br> (epoch time) | Speed with paddle 1.5 <br> (epoch time)|
| --- | --- | --- |---|
| Cora | ~81% | 0.0106s | 0.0104s |
| Pubmed | ~79% | 0.0210s | 0.0154s |
| Citeseer | ~71% | 0.0175s | 0.0177s |
### How to run
For examples, use gpu to train gcn on cora dataset.
{kind=link}