# Example to train gru4rec model with FedAvg Strategy
This document introduces how to use PaddleFL to train a model with Fl Strategy.
[Graph Convolutional Network \(GCN\)](https://arxiv.org/abs/1609.02907) is a powerful neural network designed for machine learning on graphs. Based on PGL, we reproduce GCN algorithms and reach the same level of indicators as the paper in citation network benchmarks.
### Dependencies
- paddlepaddle>=1.6
### Simple example to build GCN
To build a gcn layer, one can use our pre-defined ```pgl.layers.gcn``` or just write a gcn layer with message passing interface.
### How to install PaddleFL
```python
Please use python which has paddlepaddle installed
[Gru4rec](https://arxiv.org/abs/1511.06939) is a classical session-based recommendation model. Detailed implementations with paddlepaddle is [here](https://github.com/PaddlePaddle/models/tree/develop/PaddleRec/gru4rec).
The datasets contain three citation networks: CORA, PUBMED, CITESEER. The details for these three datasets can be found in the [paper](https://arxiv.org/abs/1609.02907).
### Dependencies
### Datasets
Public Dataset [Rsc15](https://2015.recsyschallenge.com)
- paddlepaddle>=1.4 (The speed can be faster in 1.5.)
```sh
- pgl
#download data
cd example/gru4rec_demo
sh download.sh
```
### Performance
### How to work in PaddleFL
PaddleFL has two period , CompileTime and RunTime. In CompileTime, a federated learning task is defined by fl_master. In RunTime, a federated learning job is executed on fl_server and fl_trainer in distributed cluster .
We train our models for 200 epochs and report the accuracy on the test dataset.
```sh
sh run.sh
```
| Dataset | Accuracy | Speed with paddle 1.4 <br> (epoch time) | Speed with paddle 1.5 <br> (epoch time)|
### How to work in CompileTime
| --- | --- | --- |---|
In this example, we implement it in fl_master.py
| Cora | ~81% | 0.0106s | 0.0104s |
```sh
| Pubmed | ~79% | 0.0210s | 0.0154s |
# please run fl_master to generate fl_job
| Citeseer | ~71% | 0.0175s | 0.0177s |
python fl_master.py
```
In fl_master.py, we first define FL-Strategy, User-Defined-Program and Distributed-Config. Then FL-Job-Generator generate FL-Job for federated server and worker.
```python
# define model
model=Model()
model.gru4rec_network()
# define JobGenerator and set model config
# feed_name and target_name are config for save model.
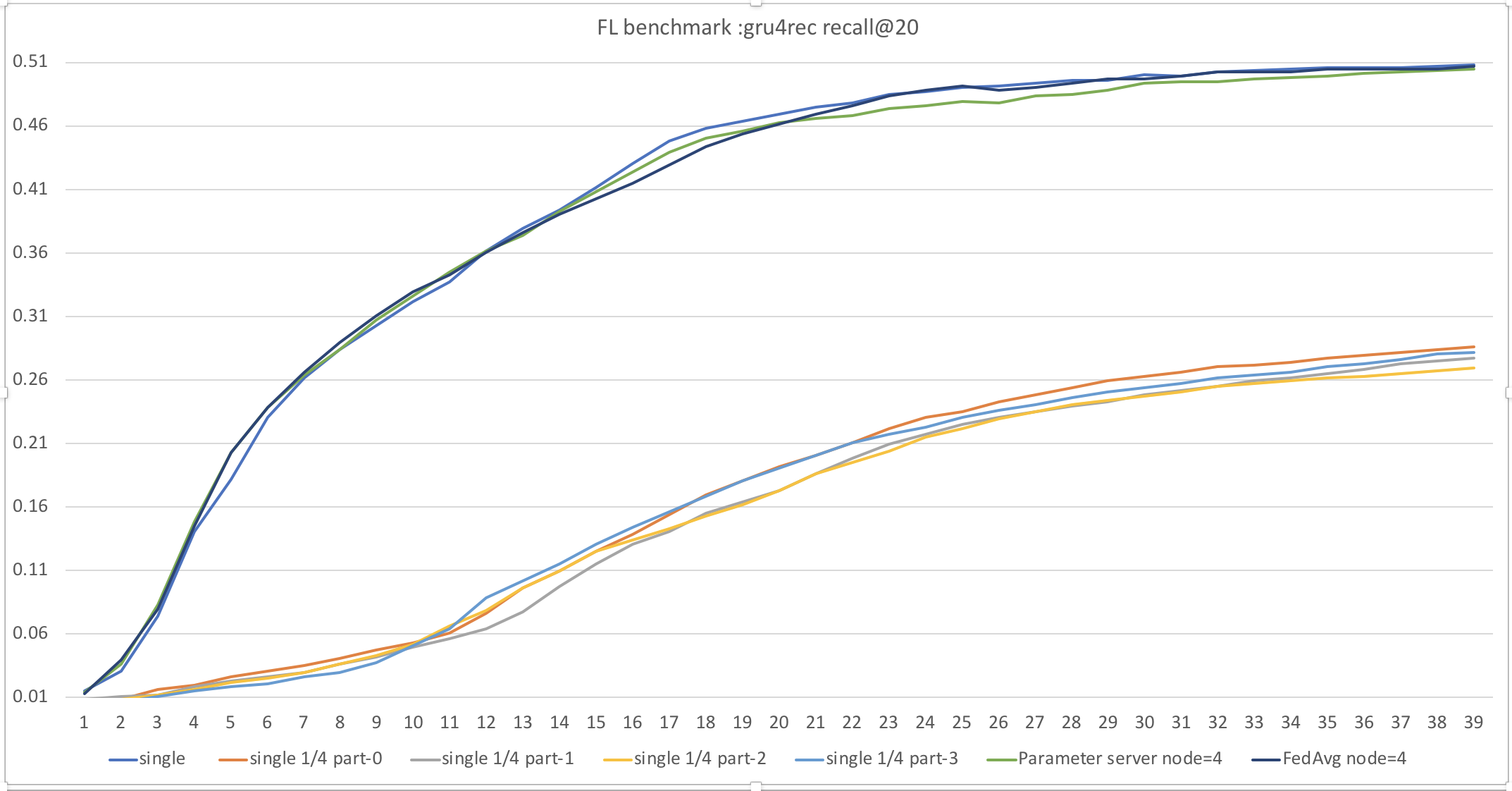
An experiment simulate the real scenarios in which everyone has only one part of the whole dataset. To evaluate the FedAvg Strategy's effectiveness, we construct baselines through simulated experiments. First baseline is the traditional way which all data stored together. We compare the single mode and distribute Parameter Server mode. The results below show that FedAvg Strategy with spilted data is same effective with traditional way. Second baseline trains model with only one part data and results show smaller data reuslt in worse precision.
{kind=link}