Merge branch 'master' of https://github.com/PaddlePaddle/PaddleClas into add_dali
Showing
docs/en/change_log.md
已删除
100644 → 0
docs/en/competition_support_en.md
0 → 100644
文件已移动
docs/en/faq_en.md
0 → 100644
docs/en/models/DPN_DenseNet_en.md
0 → 100644
docs/en/models/HRNet_en.md
0 → 100644
docs/en/models/Inception_en.md
0 → 100644
docs/en/models/Mobile_en.md
0 → 100644
docs/en/models/Others_en.md
0 → 100644
docs/en/models/Tricks_en.md
0 → 100644
docs/en/models/models_intro_en.md
0 → 100644
此差异已折叠。
docs/en/update_history_en.md
0 → 100644
{kind=link}
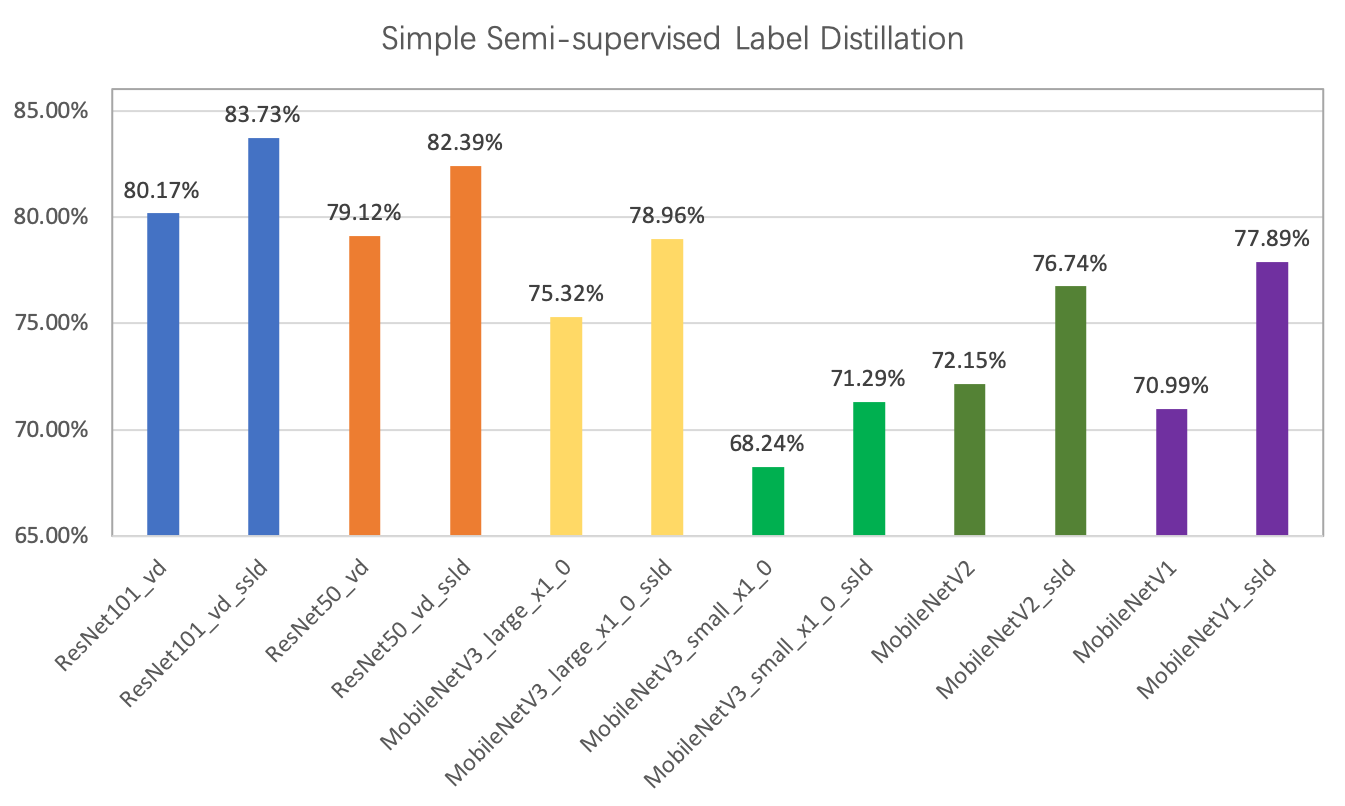
124.1 KB
{kind=link}
{kind=link}
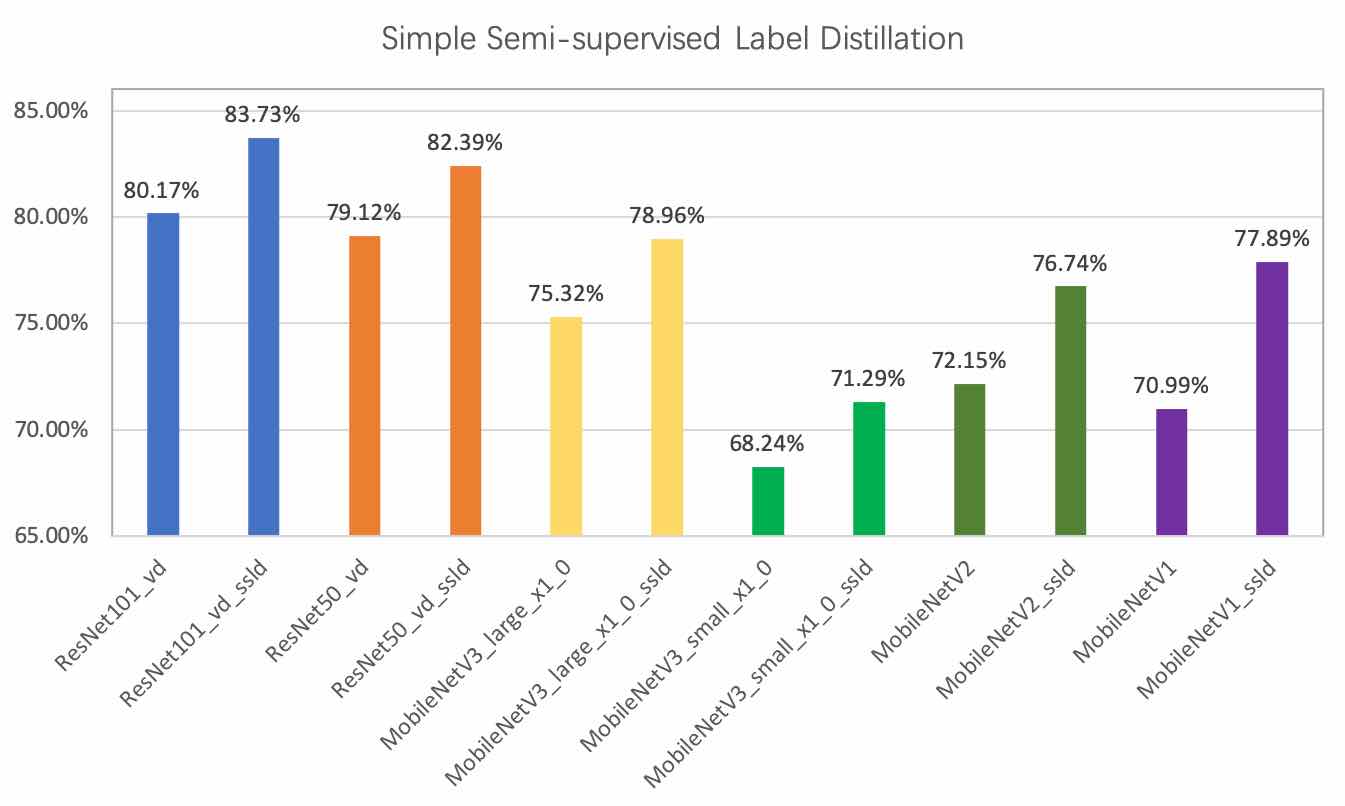
| W: | H:
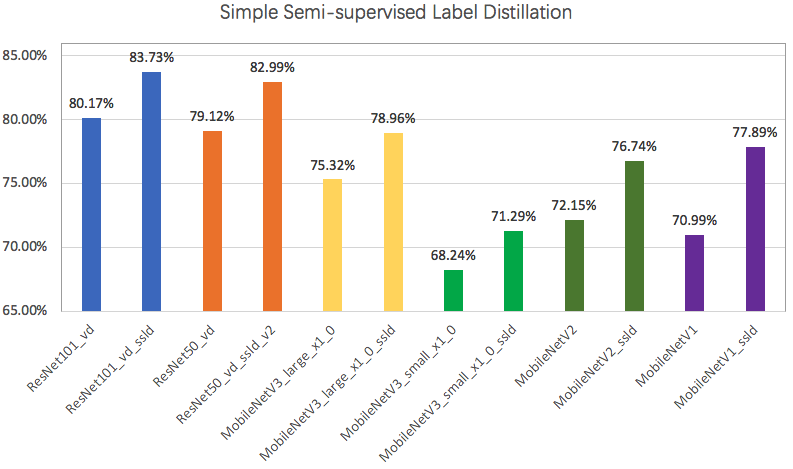
| W: | H:
{kind=link}
{kind=link}

| W: | H:

| W: | H:
{kind=link}
{kind=link}

| W: | H:

| W: | H:
{kind=link}
{kind=link}
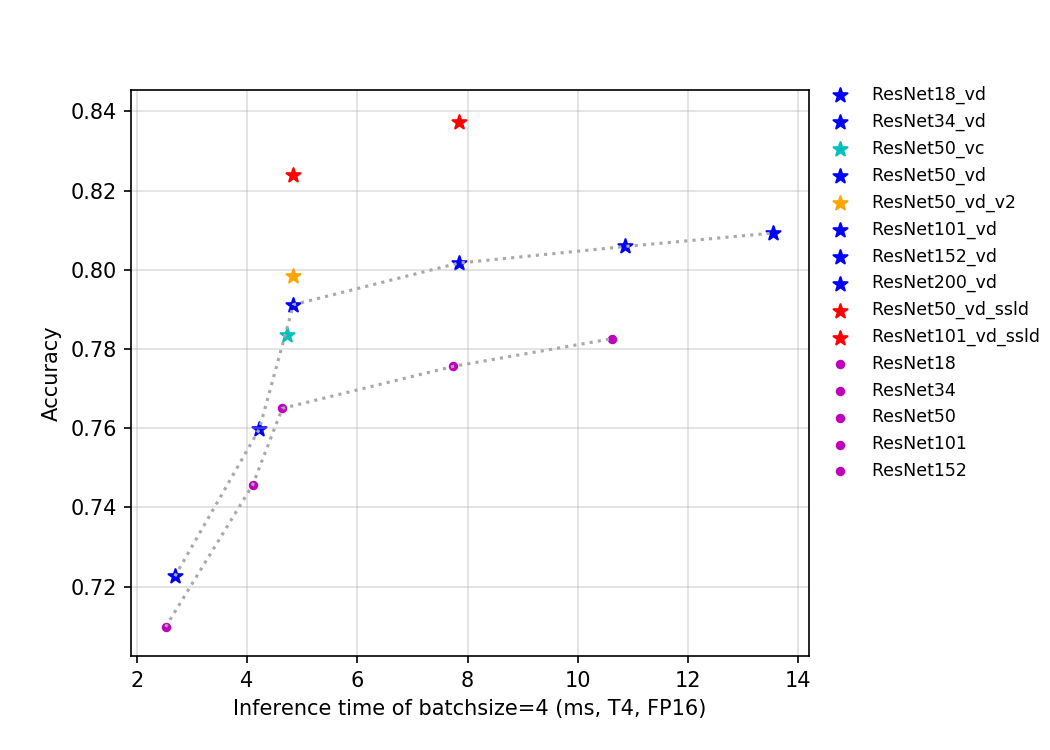
| W: | H:
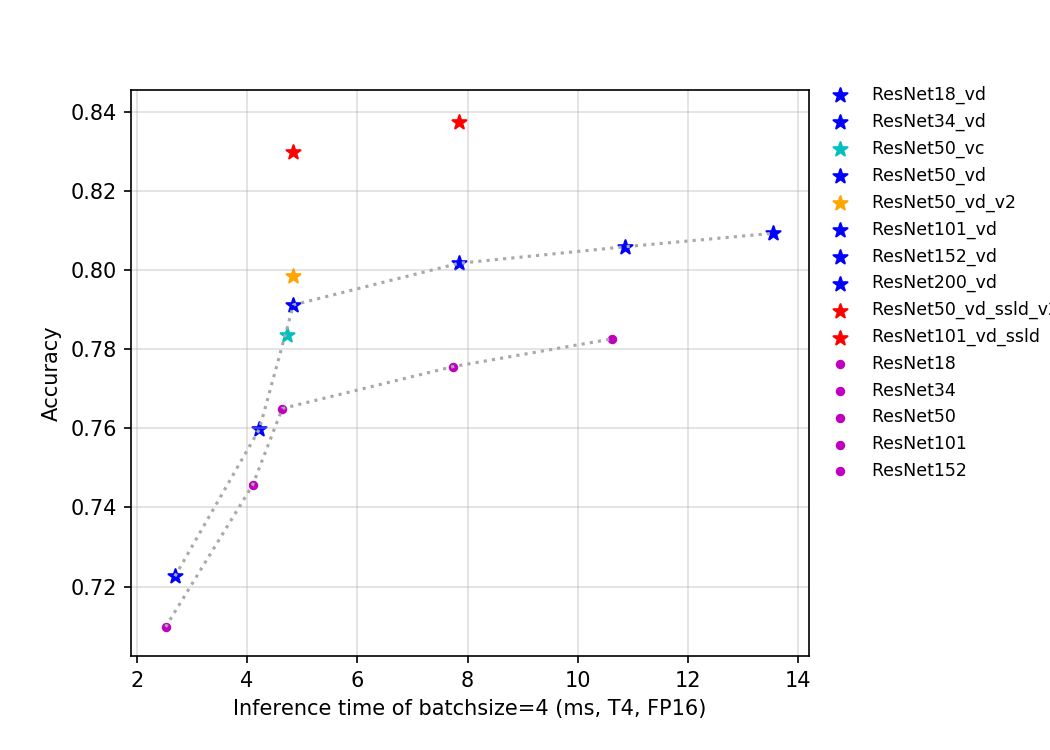
| W: | H:
{kind=link}
{kind=link}
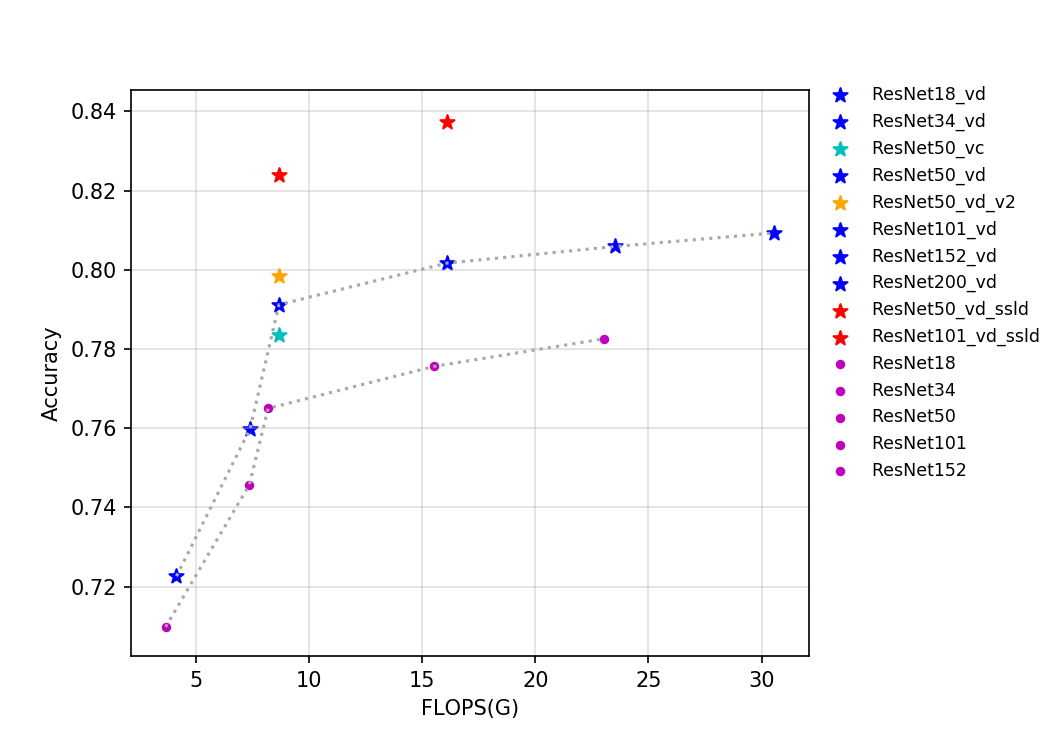
| W: | H:
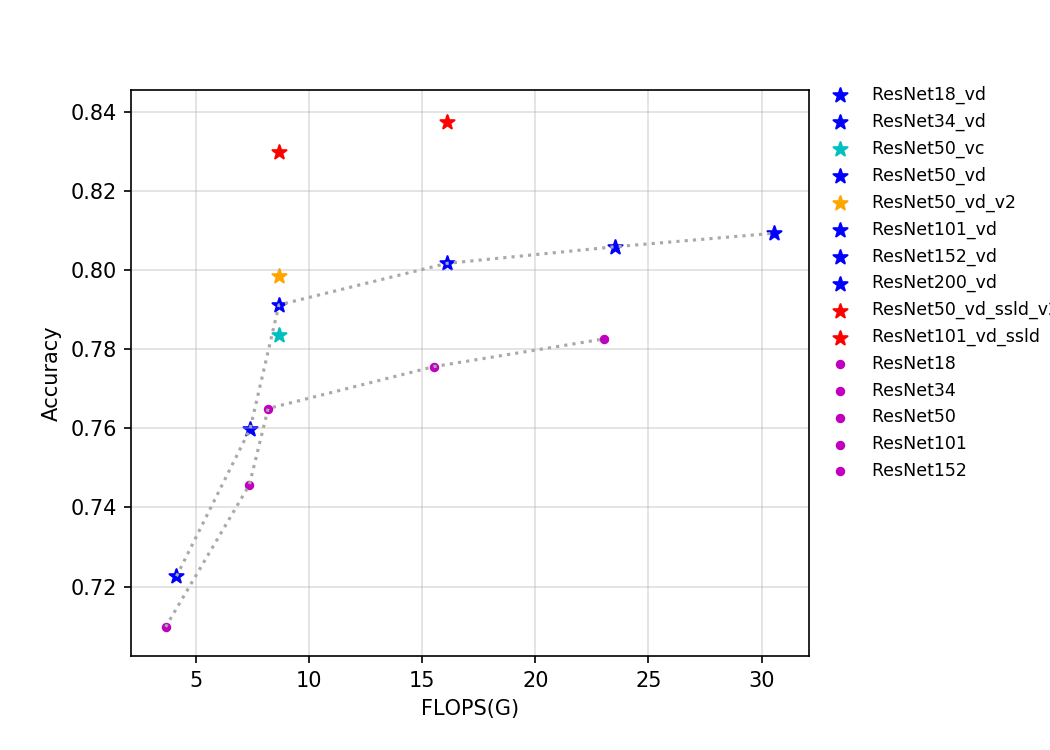
| W: | H:
{kind=link}
{kind=link}
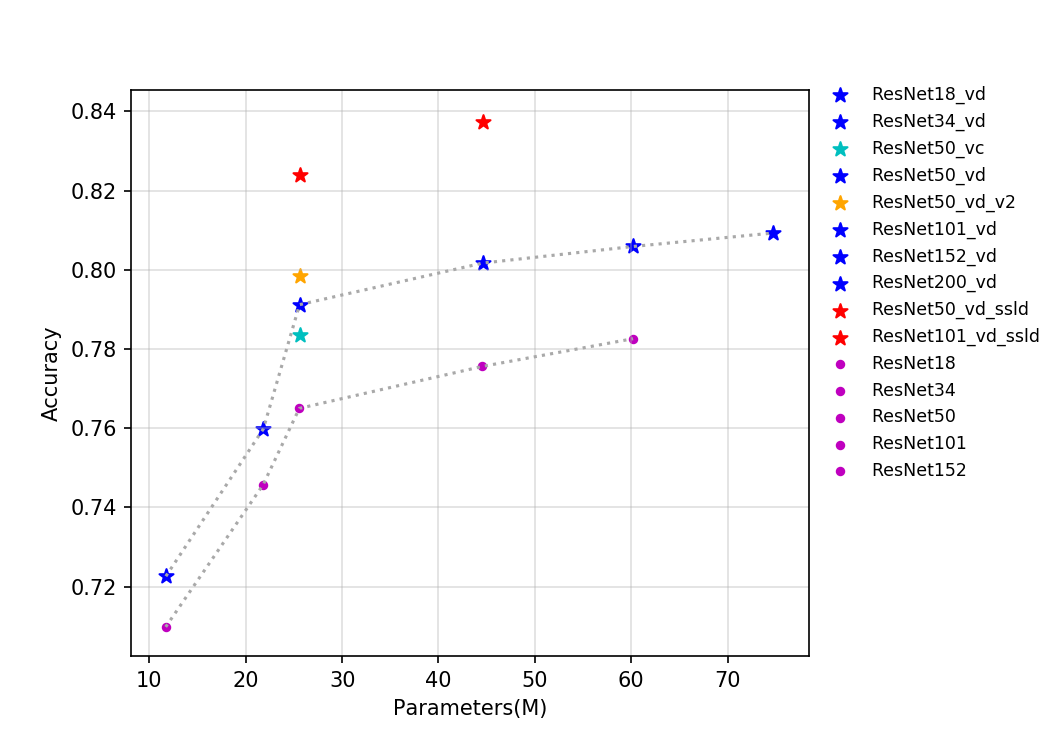
| W: | H:
| W: | H:
{kind=link}
{kind=link}
| W: | H:
| W: | H:
{kind=link}
{kind=link}
| W: | H:
| W: | H:
{kind=link}
{kind=link}
| W: | H:
| W: | H:
tools/eval_multi_platform.py
0 → 100644
tools/train_multi_platform.py
0 → 100644