Merge branch 'develop' into adaface
Showing
{kind=link}

275.2 KB
{kind=link}

230.1 KB
{kind=link}
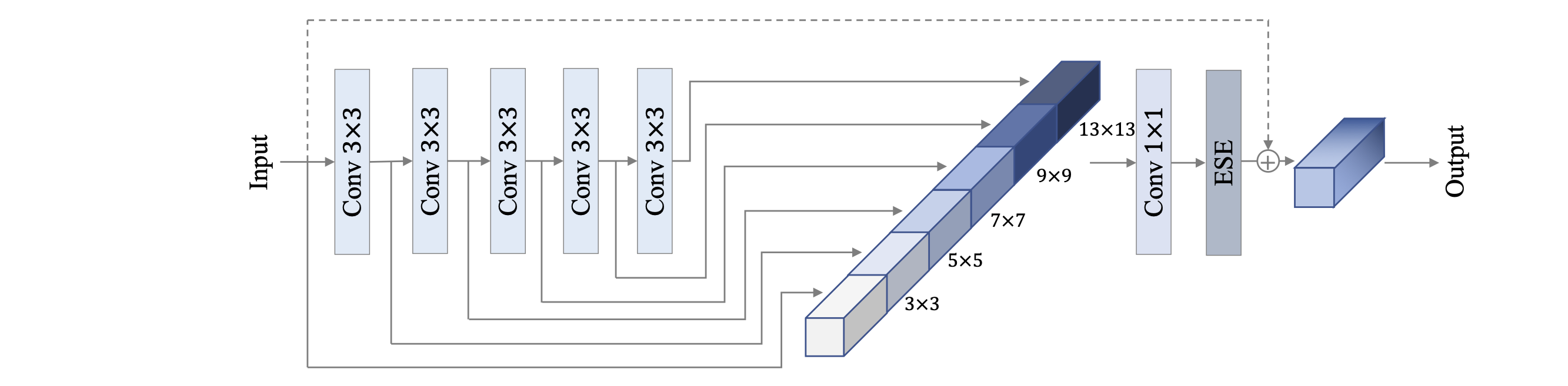
104.2 KB
docs/images/PP-HGNet/PP-HGNet.png
0 → 100644
{kind=link}
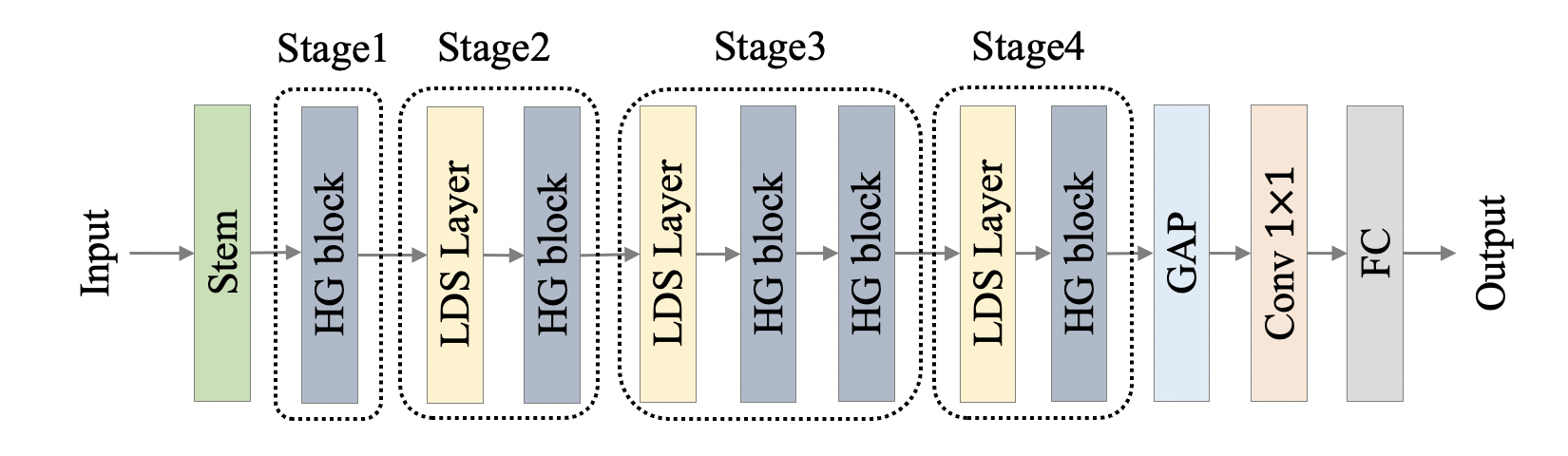
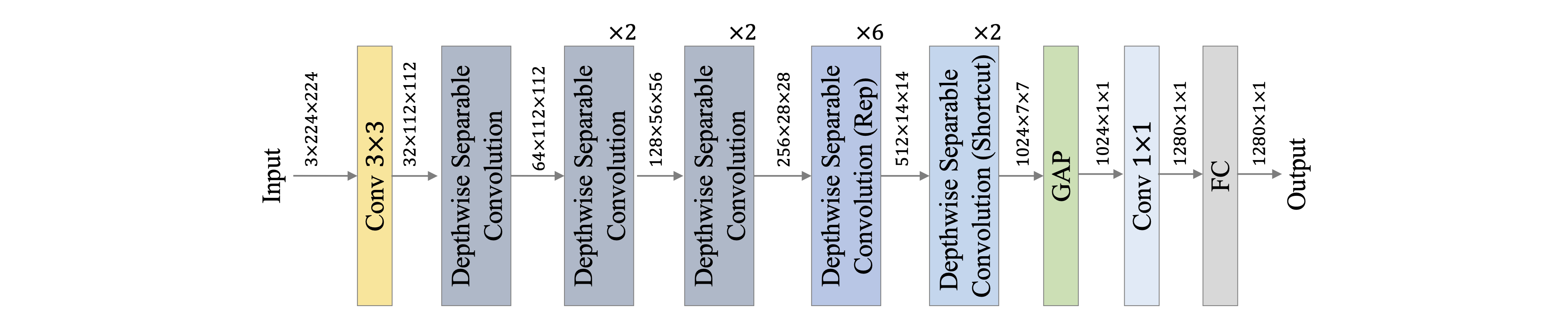
362.5 KB
docs/images/PP-LCNetV2/net.png
0 → 100644
{kind=link}
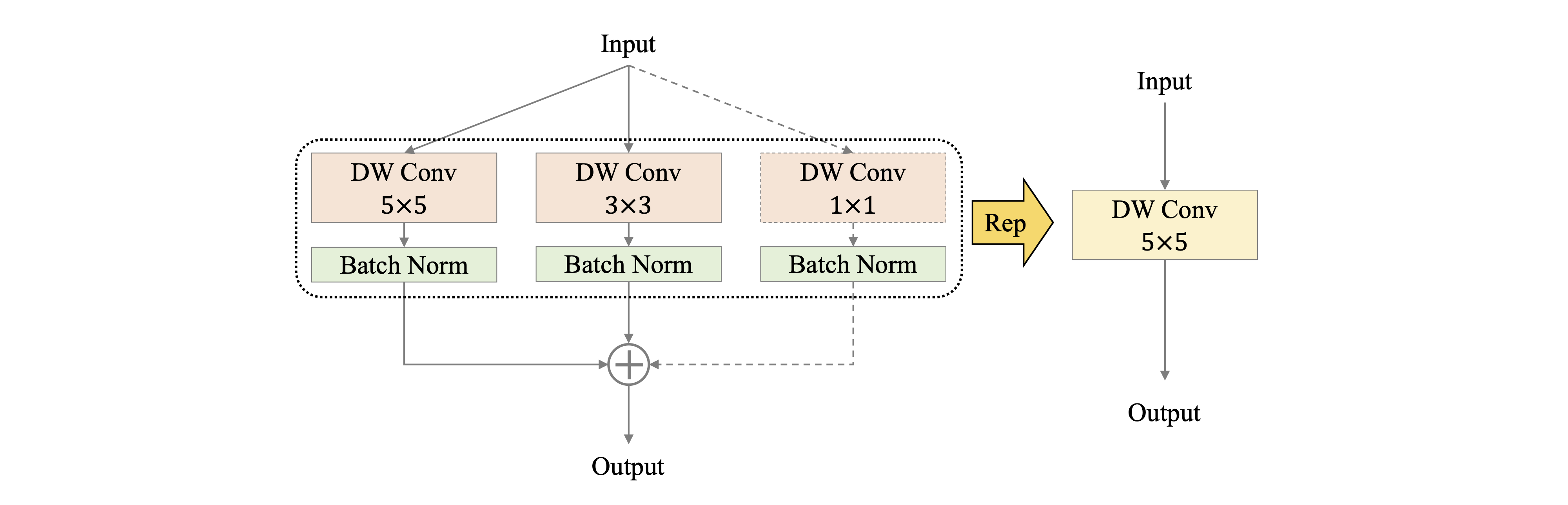
275.1 KB
docs/images/PP-LCNetV2/rep.png
0 → 100644
{kind=link}
202.7 KB
{kind=link}
99.7 KB
{kind=link}

96.6 KB
docs/zh_CN/models/PP-HGNet.md
0 → 100644
docs/zh_CN/models/PP-LCNetV2.md
0 → 100644
docs/zh_CN/samples/.gitkeep
已删除
100644 → 0
{kind=link}

734.4 KB
ppcls/loss/dkdloss.py
0 → 100644
此差异已折叠。
ppcls/metric/avg_metrics.py
0 → 100644
此差异已折叠。
| ... | @@ -9,3 +9,4 @@ scipy | ... | @@ -9,3 +9,4 @@ scipy |
| scikit-learn>=0.21.0 | scikit-learn>=0.21.0 | ||
| gast==0.3.3 | gast==0.3.3 | ||
| faiss-cpu==1.7.1.post2 | faiss-cpu==1.7.1.post2 | ||
| easydict |
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
tools/run.sh
0 → 100644
此差异已折叠。
tools/search_strategy.py
0 → 100644
此差异已折叠。