add faq (#587)
* add faq * add pngs * fix mainpage * fix faq
Showing
{kind=link}
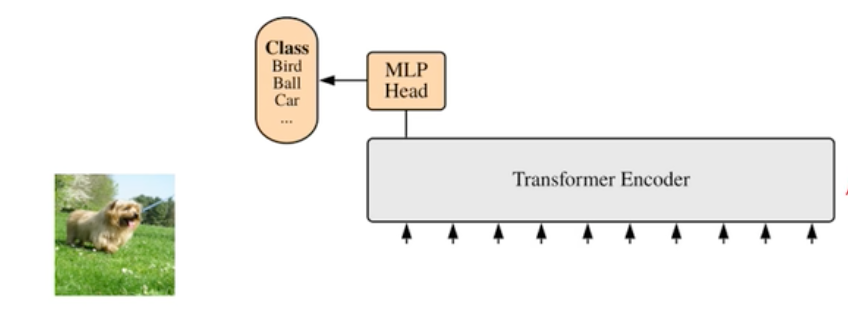
96.4 KB
docs/images/faq/ViT.png
0 → 100644
{kind=link}
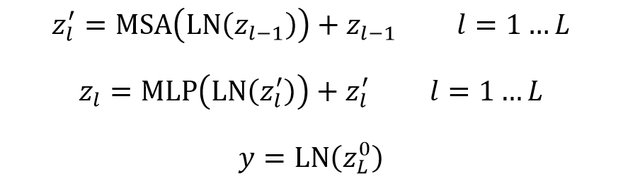
23.3 KB
docs/images/faq/ViT_structure.png
0 → 100644
{kind=link}
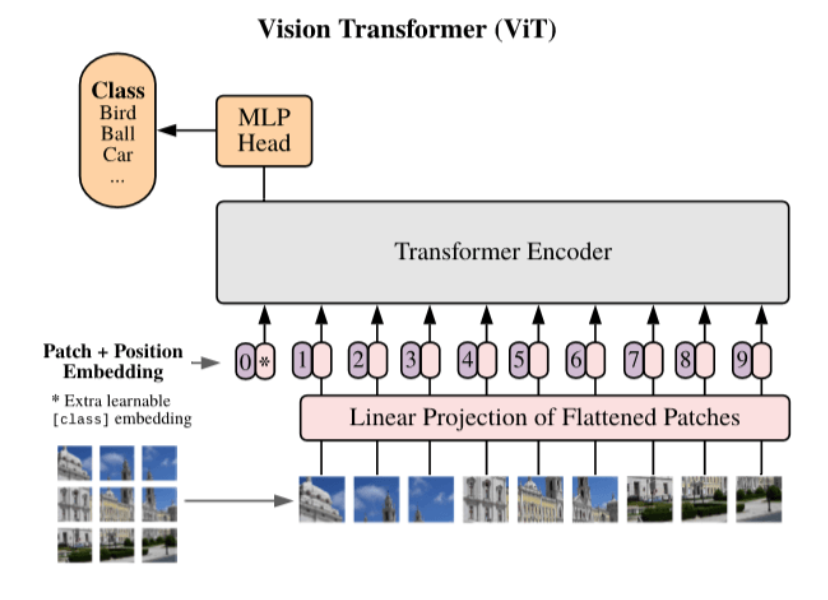
200.1 KB
* add faq * add pngs * fix mainpage * fix faq
96.4 KB
23.3 KB
200.1 KB