
Chinese Word Embedding Model Tutorial¶
This tutorial is to guide you through the process of using a Pretrained Chinese Word Embedding Model in the PaddlePaddle standard format.
We thank @lipeng for the pull request that defined the model schemas and pretrained the models.
Introduction¶
Chinese Word Dictionary¶
Our Chinese-word dictionary is created on Baidu ZhiDao and Baidu Baike by using in-house word segmentor. For example, the participle of “《红楼梦》” is “《”,”红楼梦”,”》”,and “《红楼梦》”. Our dictionary (using UTF-8 format) has has two columns: word and its frequency. The total word count is 3206326, including 4 special token:
<s>: the start of a sequence<e>: the end of a sequencePALCEHOLDER_JUST_IGNORE_THE_EMBEDDING: a placeholder, just ignore it and its embedding<unk>: a word not included in dictionary
Pretrained Chinese Word Embedding Model¶
Inspired by paper A Neural Probabilistic Language Model, our model architecture (Embedding joint of six words->FullyConnect->SoftMax) is as following graph. And for our dictionary, we pretrain four models with different word vector dimenstions, i.e 32, 64, 128, 256.
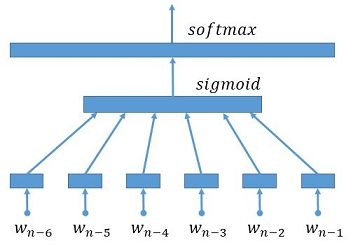
Download and Extract¶
To download and extract our dictionary and pretrained model, run the following commands.
cd $PADDLE_ROOT/demo/model_zoo/embedding
./pre_DictAndModel.sh
Chinese Paraphrasing Example¶
We provide a paraphrasing task to show the usage of pretrained Chinese Word Dictionary and Embedding Model.
Data Preparation and Preprocess¶
First, run the following commands to download and extract the in-house dataset. The dataset (using UTF-8 format) has 20 training samples, 5 testing samples and 2 generating samples.
cd $PADDLE_ROOT/demo/seqToseq/data
./paraphrase_data.sh
Second, preprocess data and build dictionary on train data by running the following commands, and the preprocessed dataset is stored in $PADDLE_SOURCE_ROOT/demo/seqToseq/data/pre-paraphrase:
cd $PADDLE_ROOT/demo/seqToseq/
python preprocess.py -i data/paraphrase [--mergeDict]
--mergeDict: if using this option, the source and target dictionary are merged, i.e, two dictionaries have the same context. Here, as source and target data are all chinese words, this option can be used.
User Specified Embedding Model¶
The general command of extracting desired parameters from the pretrained embedding model based on user dictionary is:
cd $PADDLE_ROOT/demo/model_zoo/embedding
python extract_para.py --preModel PREMODEL --preDict PREDICT --usrModel USRMODEL--usrDict USRDICT -d DIM
--preModel PREMODEL: the name of pretrained embedding model--preDict PREDICT: the name of pretrained dictionary--usrModel USRMODEL: the name of extracted embedding model--usrDict USRDICT: the name of user specified dictionary-d DIM: dimension of parameter
Here, you can simply run the command:
cd $PADDLE_ROOT/demo/seqToseq/data/
./paraphrase_model.sh
And you will see following embedding model structure:
paraphrase_model
|--- _source_language_embedding
|--- _target_language_embedding
Training Model in PaddlePaddle¶
First, create a model config file, see example demo/seqToseq/paraphrase/train.conf:
from seqToseq_net import *
is_generating = False
################## Data Definition #####################
train_conf = seq_to_seq_data(data_dir = "./data/pre-paraphrase",
job_mode = job_mode)
############## Algorithm Configuration ##################
settings(
learning_method = AdamOptimizer(),
batch_size = 50,
learning_rate = 5e-4)
################# Network configure #####################
gru_encoder_decoder(train_conf, is_generating, word_vector_dim = 32)
This config is almost the same as demo/seqToseq/translation/train.conf.
Then, train the model by running the command:
cd $PADDLE_SOURCE_ROOT/demo/seqToseq/paraphrase
./train.sh
where train.sh is almost the same as demo/seqToseq/translation/train.sh, the only difference is following two command arguments:
--init_model_path: path of the initialization model, here isdata/paraphrase_model--load_missing_parameter_strategy: operations when model file is missing, here use a normal distibution to initialize the other parameters except for the embedding layer
For users who want to understand the dataset format, model architecture and training procedure in detail, please refer to Text generation Tutorial.
Optional Function¶
Embedding Parameters Observation¶
For users who want to observe the embedding parameters, this function can convert a PaddlePaddle binary embedding model to a text model by running the command:
cd $PADDLE_ROOT/demo/model_zoo/embedding
python paraconvert.py --b2t -i INPUT -o OUTPUT -d DIM
-i INPUT: the name of input binary embedding model-o OUTPUT: the name of output text embedding model-d DIM: the dimension of parameter
You will see parameters like this in output text model:
0,4,32156096
-0.7845433,1.1937413,-0.1704215,0.4154715,0.9566584,-0.5558153,-0.2503305, ......
0.0000909,0.0009465,-0.0008813,-0.0008428,0.0007879,0.0000183,0.0001984, ......
......
- 1st line is PaddlePaddle format file head, it has 3 attributes:
- version of PaddlePaddle, here is 0
- sizeof(float), here is 4
- total number of parameter, here is 32156096
- Other lines print the paramters (assume
<dim>= 32)- each line print 32 paramters splitted by ‘,’
- there is 32156096/32 = 1004877 lines, meaning there is 1004877 embedding words
Embedding Parameters Revision¶
For users who want to revise the embedding parameters, this function can convert a revised text embedding model to a PaddlePaddle binary model by running the command:
cd $PADDLE_ROOT/demo/model_zoo/embedding
python paraconvert.py --t2b -i INPUT -o OUTPUT
-i INPUT: the name of input text embedding model.-o OUTPUT: the name of output binary embedding model
Note that the format of input text model is as follows:
-0.7845433,1.1937413,-0.1704215,0.4154715,0.9566584,-0.5558153,-0.2503305, ......
0.0000909,0.0009465,-0.0008813,-0.0008428,0.0007879,0.0000183,0.0001984, ......
......
- there is no file header in 1st line
- each line stores parameters for one word, the separator is commas ‘,’