Merge branch 'develop' of https://github.com/PaddlePaddle/Paddle into adadelta
Showing
文件已删除
{kind=link}
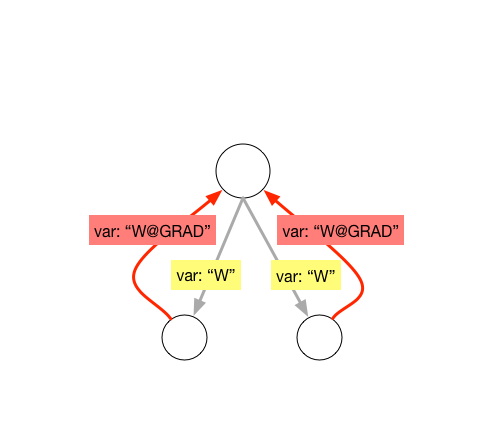
21.4 KB
文件已删除
{kind=link}
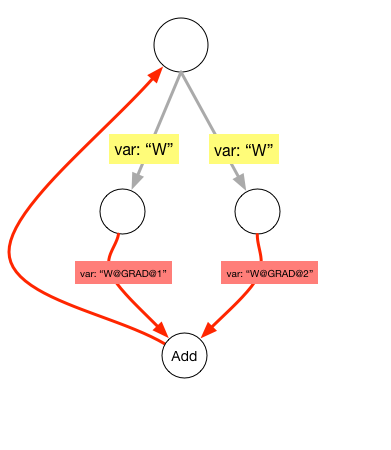
24.2 KB
doc/design/images/replica.png
已删除
100644 → 0
{kind=link}
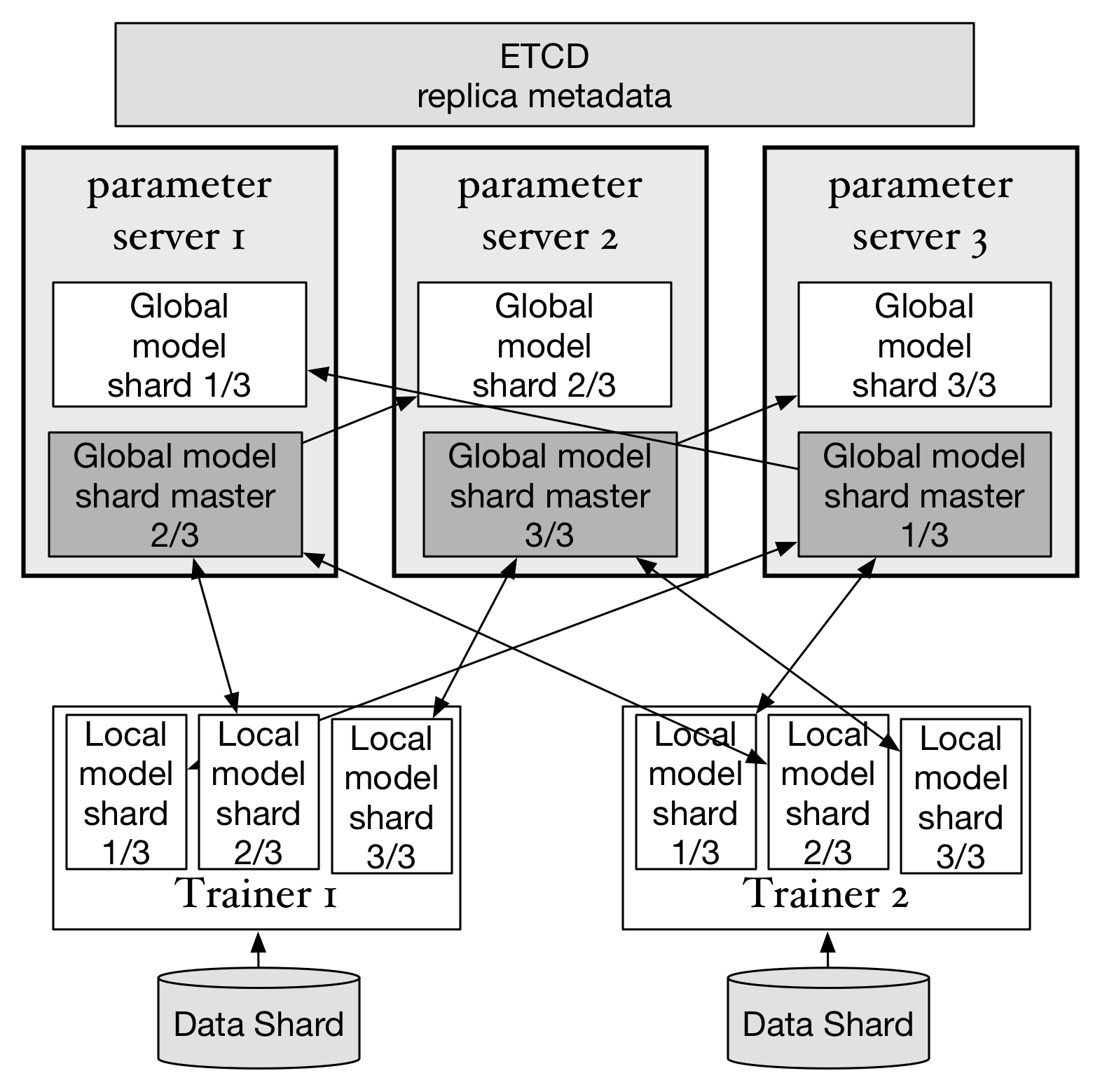
174.9 KB
{kind=link}
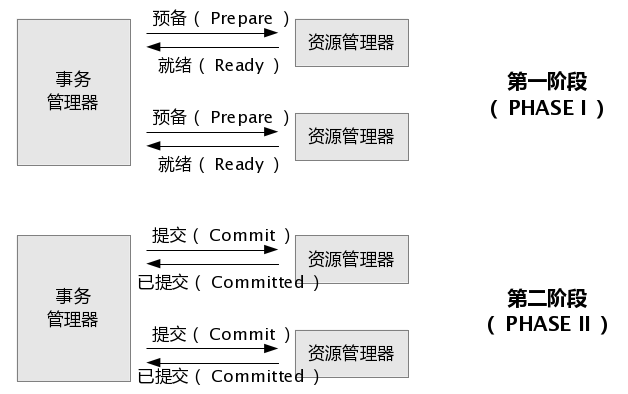
48.0 KB
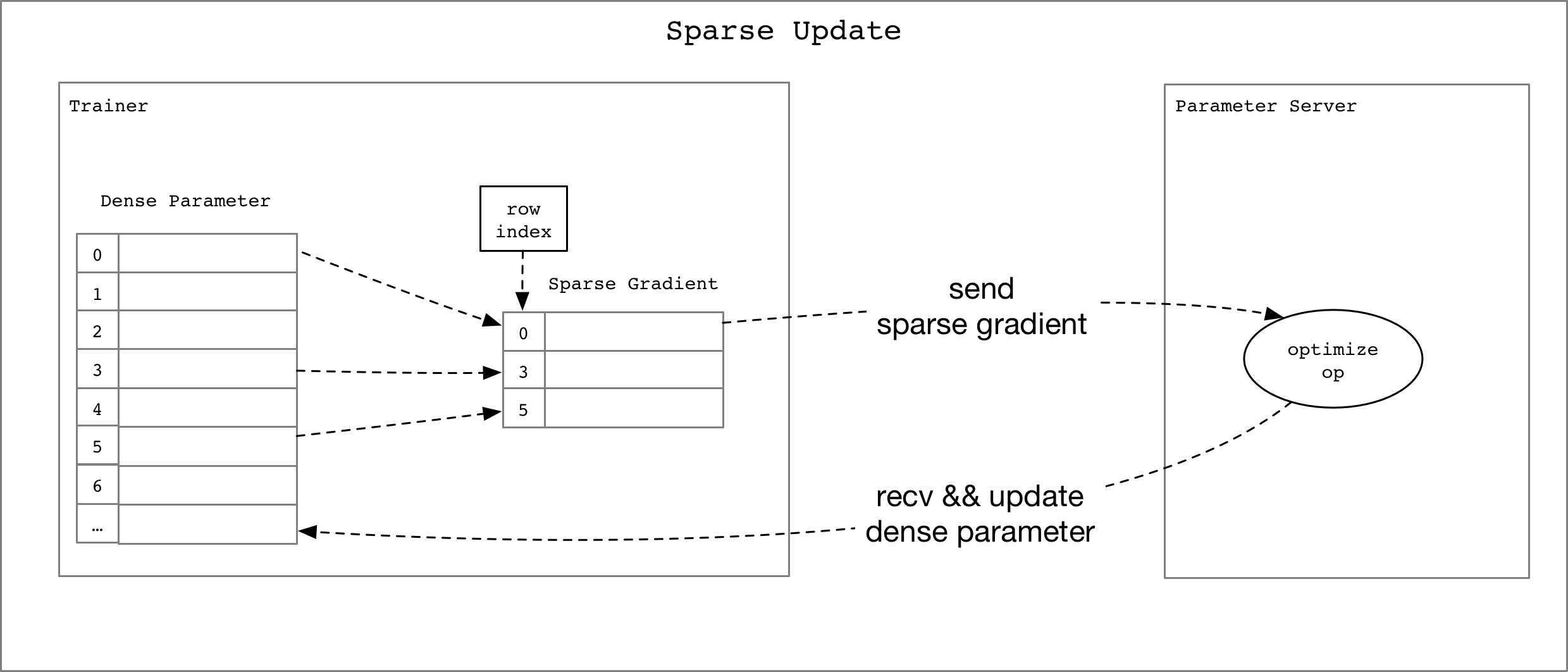
doc/design/lookup_table.png
0 → 100644
{kind=link}
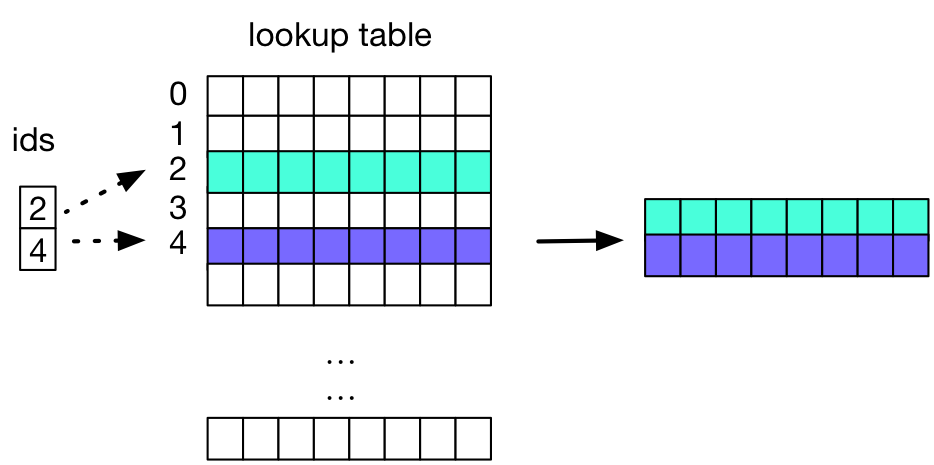
23.7 KB
{kind=link}
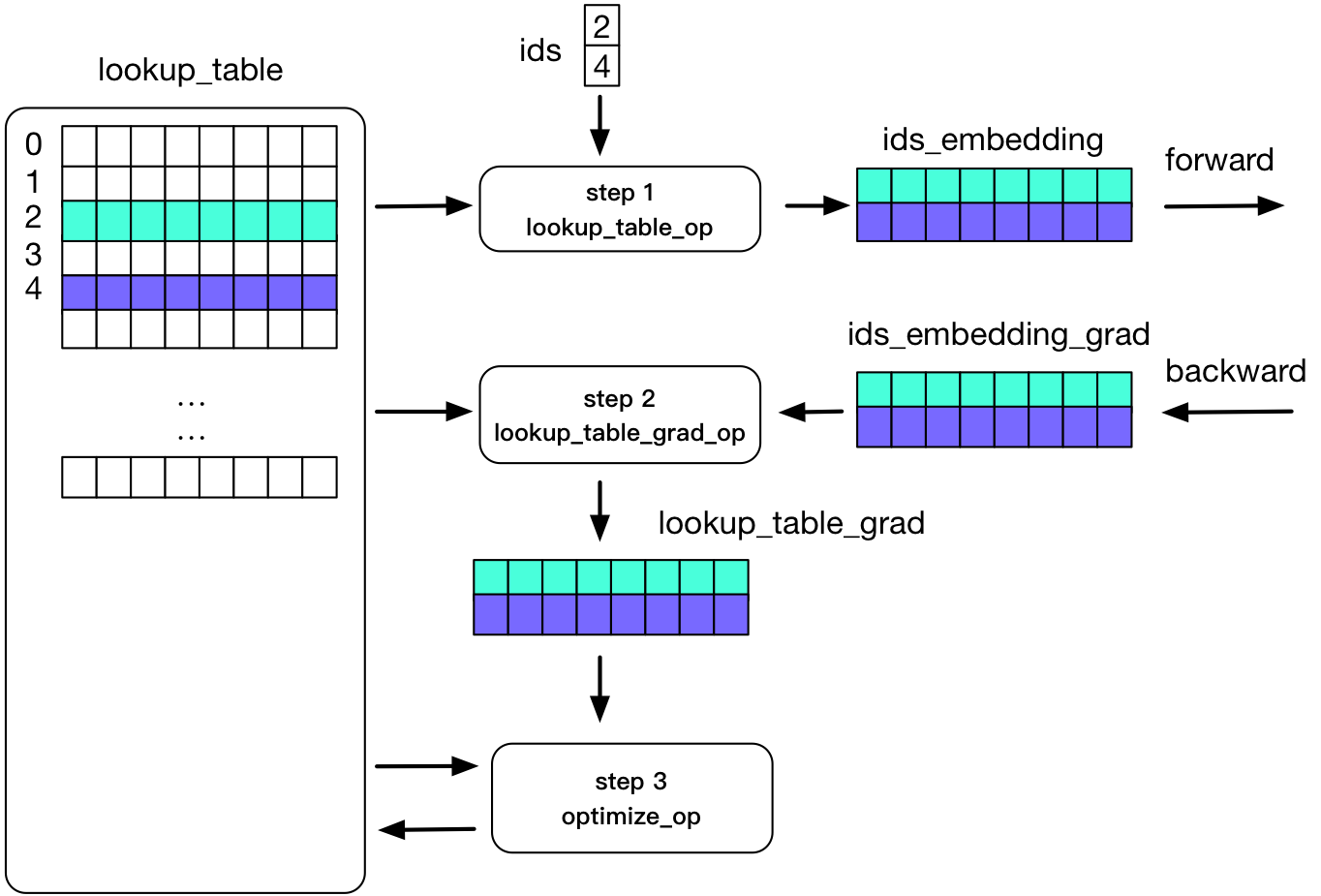
88.3 KB
{kind=link}
{kind=link}
文件已移动
文件已移动
文件已移动
{kind=link}
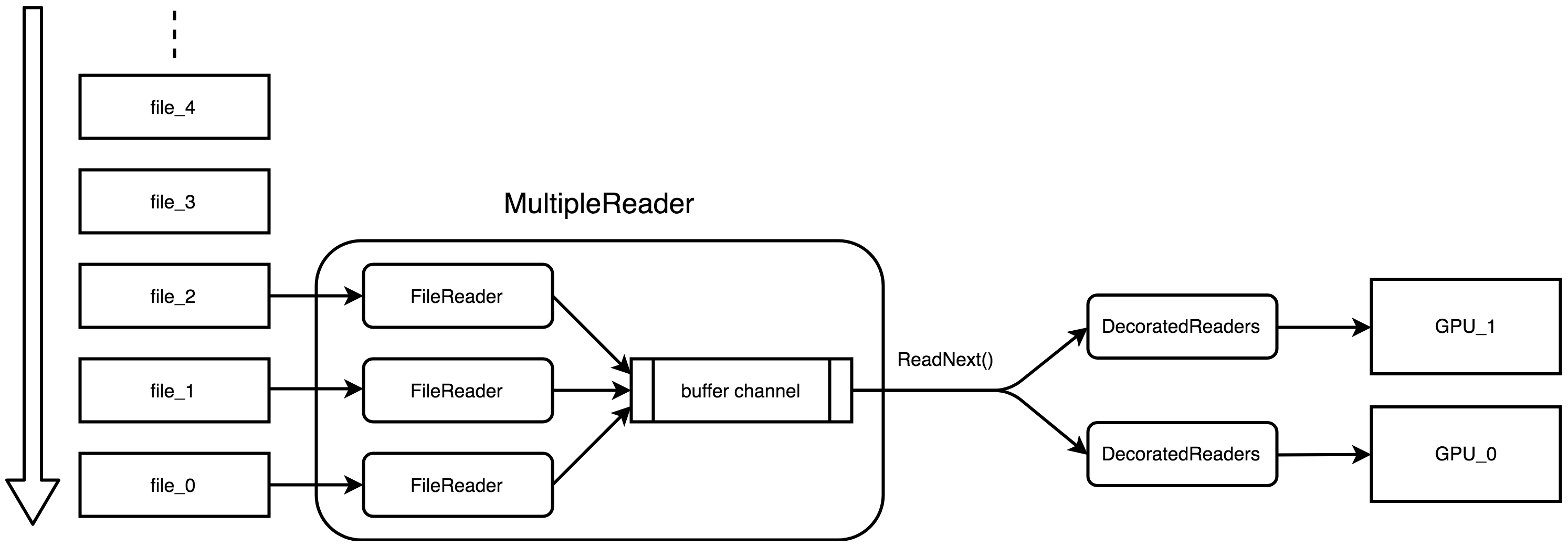
160.0 KB
{kind=link}
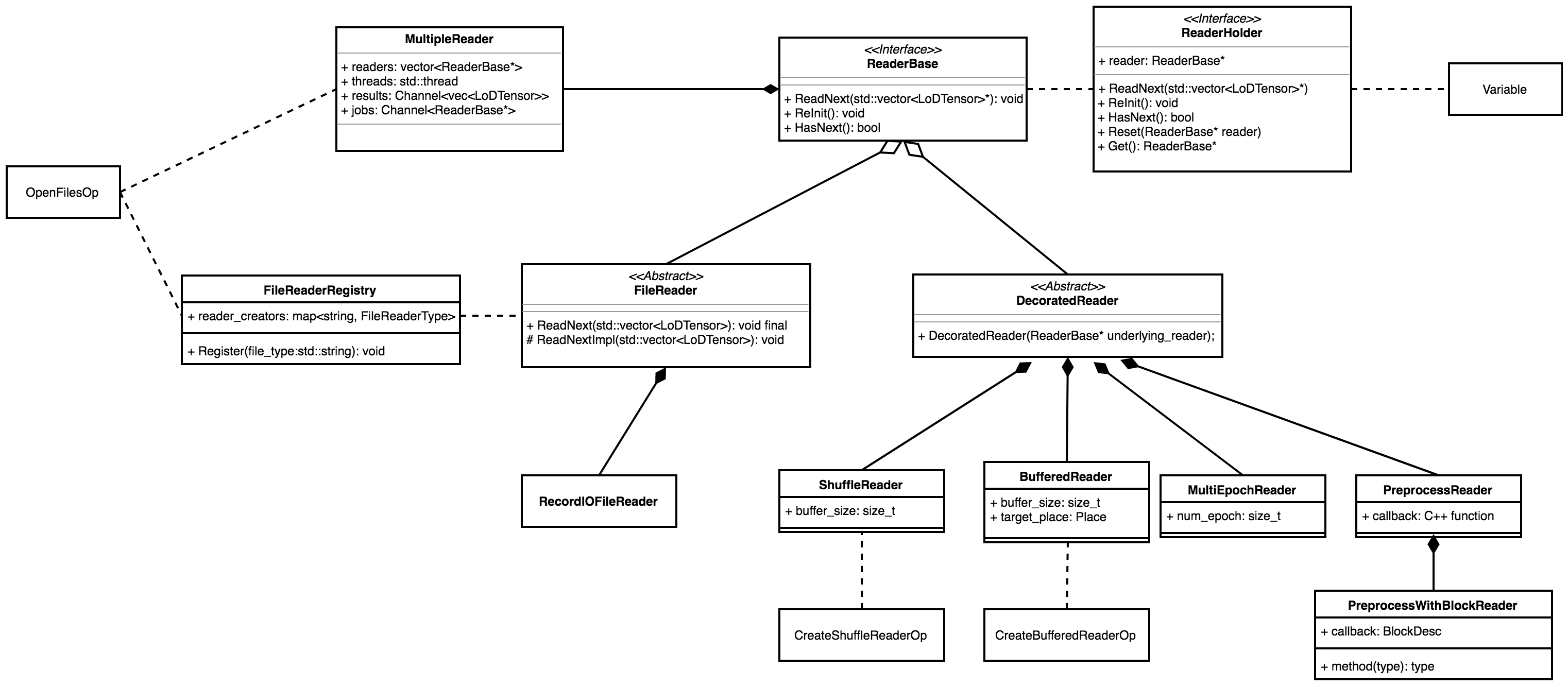
347.4 KB
文件已移动
文件已移动
文件已移动
文件已移动
{kind=link}
文件已移动
文件已移动
{kind=link}
文件已移动
文件已移动
{kind=link}
文件已移动
文件已移动
{kind=link}
文件已移动
文件已移动
{kind=link}
文件已移动
文件已移动
{kind=link}
文件已移动
{kind=link}
文件已移动
文件已移动
{kind=link}
文件已移动
文件已移动
{kind=link}
文件已移动
文件已添加
{kind=link}
119.7 KB
文件已移动
{kind=link}
文件已移动
{kind=link}
{kind=link}
文件已移动
{kind=link}
文件已移动
文件已移动
文件已移动
文件已移动
{kind=link}
文件已移动
{kind=link}
文件已移动
{kind=link}
文件已移动
文件已移动
文件已移动
文件已移动
{kind=link}
文件已移动
{kind=link}
文件已移动
{kind=link}
文件已移动
{kind=link}
文件已移动
{kind=link}
文件已移动
{kind=link}
文件已移动
{kind=link}
文件已移动
文件已移动
文件已移动
{kind=link}
文件已移动
文件已移动
文件已移动
文件已移动
文件已移动
此差异已折叠。
{kind=link}
文件已移动
{kind=link}
文件已移动
{kind=link}
文件已移动
文件已移动
文件已移动
{kind=link}
文件已移动
文件已移动
{kind=link}
文件已移动
{kind=link}
文件已移动
{kind=link}
文件已移动
文件已移动
{kind=link}
doc/fluid/dev/api_doc_std_cn.md
0 → 100644
此差异已折叠。
{kind=link}
文件已移动
文件已移动
doc/fluid/dev/src/fc.py
0 → 100644
此差异已折叠。
文件已移动
{kind=link}
文件已移动
{kind=link}
文件已移动
{kind=link}
此差异已折叠。
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
文件已移动
文件已移动
{kind=link}
文件已移动
文件已移动
{kind=link}
文件已移动
文件已移动
文件已移动
文件已移动
文件已移动
文件已移动
文件已移动
文件已移动
{kind=link}
文件已移动
{kind=link}
文件已移动
文件已移动
{kind=link}
文件已移动
文件已移动
{kind=link}
文件已移动
文件已移动
{kind=link}
文件已移动
{kind=link}
文件已移动
文件已移动
{kind=link}
文件已移动
文件已移动
{kind=link}
文件已移动
{kind=link}
文件已移动
{kind=link}
文件已移动
文件已移动
文件已移动
{kind=link}
文件已移动
文件已移动
{kind=link}
文件已移动
文件已移动
{kind=link}
文件已移动
文件已移动
{kind=link}
文件已移动
文件已移动
{kind=link}
文件已移动
文件已移动
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
doc/v2/dev/src/doc_en.png
0 → 100644
{kind=link}
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
paddle/fluid/pybind/recordio.cc
0 → 100644
此差异已折叠。
paddle/fluid/pybind/recordio.h
0 → 100644
此差异已折叠。
paddle/fluid/recordio/scanner.cc
0 → 100644
此差异已折叠。
paddle/fluid/recordio/scanner.h
0 → 100644
此差异已折叠。
paddle/fluid/recordio/writer.cc
0 → 100644
此差异已折叠。
paddle/fluid/recordio/writer.h
0 → 100644
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。