Skip to content
体验新版
项目
组织
正在加载...
登录
切换导航
打开侧边栏
PaddlePaddle
Paddle
提交
450ac64c
P
Paddle
项目概览
PaddlePaddle
/
Paddle
大约 2 年 前同步成功
通知
2325
Star
20933
Fork
5424
代码
文件
提交
分支
Tags
贡献者
分支图
Diff
Issue
1423
列表
看板
标记
里程碑
合并请求
543
Wiki
0
Wiki
分析
仓库
DevOps
项目成员
Pages
P
Paddle
项目概览
项目概览
详情
发布
仓库
仓库
文件
提交
分支
标签
贡献者
分支图
比较
Issue
1,423
Issue
1,423
列表
看板
标记
里程碑
合并请求
543
合并请求
543
Pages
分析
分析
仓库分析
DevOps
Wiki
0
Wiki
成员
成员
收起侧边栏
关闭侧边栏
动态
分支图
创建新Issue
提交
Issue看板
提交
450ac64c
编写于
8月 04, 2017
作者:
T
tensor-tang
浏览文件
操作
浏览文件
下载
电子邮件补丁
差异文件
refine and add overview
上级
0fb0484e
变更
2
隐藏空白更改
内联
并排
Showing
2 changed file
with
21 addition
and
18 deletion
+21
-18
doc/design/mkldnn/README.MD
doc/design/mkldnn/README.MD
+21
-18
doc/design/mkldnn/image/overview.png
doc/design/mkldnn/image/overview.png
+0
-0
未找到文件。
doc/design/mkldnn/README.MD
浏览文件 @
450ac64c
...
...
@@ -11,7 +11,8 @@
## Contents
-
[
Overall
](
#overall
)
-
[
Cmake
](
#cmake
)
-
[
Details
](
#details
)
-
[
Cmake
](
#cmake
)
-
[
Layer
](
#layer
)
-
[
Activation
](
#activation
)
-
[
Unit Test
](
#unit-test
)
...
...
@@ -19,15 +20,19 @@
-
[
Python API
](
#python-api
)
-
[
Demo
](
#demo
)
-
[
Benchmark
](
#benchmark
)
-
[
Others
](
#others
)
-
[
Optimized Design
](
#optimized-design
)
-
[
New
](
#new
)
-
[
Add
](
#add
)
-
[
Others
](
#others
)
-
[
KeyPoints
](
#keypoints
)
## Overall
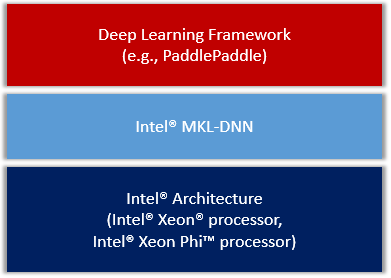
整体上,我们粗略的把集成方案分为了如下几个方面。
我们会把MKLDNN作为第三方库集成进PaddlePaddle,整体框架图
<div
align=
"center"
>
<img
src=
"image/overview.png"
width=
350
><br/>
Figure 1. PaddlePaddle on IA.
</div>
## Details
我们把集成方案大致分为了如下几个方面。
### Cmake
我们会在
`CMakeLists.txt`
中会添加
`WITH_MKLDNN`
的选项,当设置这个值为
`ON`
的时候会启用编译MKLDNN功能。同时会自动开启
`OpenMP`
用于提高MKLDNN的性能。
...
...
@@ -83,21 +88,19 @@ Activation的测试,计划在Paddle原有的测试文件上直接添加测试t
1.
如果在使用MKLDNN的情况下,会把CPU的Buffer对齐为64。
2.
深入PaddlePaddle,寻找有没有其他可以优化的可能,进一步优化。比如可能会用
`OpenMP`
改进SGD的更新性能。
##
Optimized Design
##
KeyPoints
为了更好的符合PaddlePaddle的代码风格,同时又尽可能少的牺牲MKLDNN的性能。
我们
决定尽可能少的在PaddlePaddle的父类Layer中添加变量或者函数,改用已有的
`deviceId_`
变量来区分layer的属性,定义
`-2`
为MkldnnLayer特有的设备ID。
我们
总结出一些特别需要注意的点:
### New
1.
创建
**MkldnnLayer**
,并override父类Layer的
`init`
函数,修改
`deviceId_`
为
`-2`
,代表这个layer是用于跑在MKLDNN的环境下。
2.
创建
**MkldnnMatrix**
,用于管理MKLDNN会用到的相关memory函数和接口。
3.
创建
**MkldnnBase**
,定义一些除了layer和memory相关的类和函数。包括MKLDNN会用到Stream和CpuEngine,和未来可能还会用到FPGAEngine等。
### Add
1.
在现有的
**Argument**
里面添加两个
**MkldnnMatrixPtr**
,取名为mkldnnValue和mkldnnGrad,用于存放MkldnnLayer会用到的memory buffer。 并且添加函数cvt(会修改为一个更加合适的函数名),用于处理"CPU device"和"MKLDNN device"之间memory的相互转化。
2.
在父类Layer中的
`getOutput`
函数中添加一段逻辑,用于判断
`deviceId`
,并针对device在MKLDNN和CPU之间不统一的情况,做一个前期转换。 也就是调用
`Argument`
的cvt函数把output统一到需要的device上。
3.
在原来的
`FLAGS`
中添加一个
`use_mkldnn`
的flag,用于选择是否使用MKLDNN的相关功能。
1.
使用
**deviceId_**
。为了尽可能少的在父类Layer中添加变量或者函数,我们决定使用已有的
`deviceId_`
变量来区分layer的属性,定义
`-2`
为
**MkldnnLayer**
特有的设备ID。
2.
重写父类Layer的
**init**
函数,修改
`deviceId_`
为
`-2`
,代表这个layer是用于跑在MKLDNN的环境下。
3.
创建
**MkldnnMatrix**
,用于管理MKLDNN会用到的相关memory函数和接口。
4.
创建
**MkldnnBase**
,定义一些除了layer和memory相关的类和函数。包括MKLDNN会用到Stream和CpuEngine,和未来可能还会用到FPGAEngine等。
5.
在
**Argument**
里添加两个MkldnnMatrixPtr,取名为mkldnnValue和mkldnnGrad,用于存放MkldnnLayer会用到的memory buffer。 并且添加函数cvt(会修改为一个更加合适的函数名),用于处理"CPU device"和"MKLDNN device"之间memory的相互转化。
6.
在父类Layer中的
**getOutput**
函数中添加一段逻辑,用于判断
`deviceId`
,并针对device在MKLDNN和CPU之间不统一的情况,做一个前期转换。 也就是调用
`Argument`
的cvt函数把output统一到需要的device上。
7.
在原来的
`FLAGS`
中添加一个
`use_mkldnn`
的flag,用于选择是否使用MKLDNN的相关功能。
## References
...
...
doc/design/mkldnn/image/overview.png
0 → 100644
浏览文件 @
450ac64c
9.7 KB
编辑
预览
Markdown
is supported
0%
请重试
或
添加新附件
.
添加附件
取消
You are about to add
0
people
to the discussion. Proceed with caution.
先完成此消息的编辑!
取消
想要评论请
注册
或
登录
{kind=link}