Merge pull request #1 from PaddlePaddle/develop
merge PaddlePaddle/Paddle
Showing
.dockerignore
0 → 120000
RELEASE.md
0 → 100644
benchmark/.gitignore
0 → 100644
benchmark/README.md
0 → 100644
此差异已折叠。
benchmark/caffe/image/run.sh
0 → 100755
benchmark/figs/alexnet-4gpu.png
0 → 100644
{kind=link}
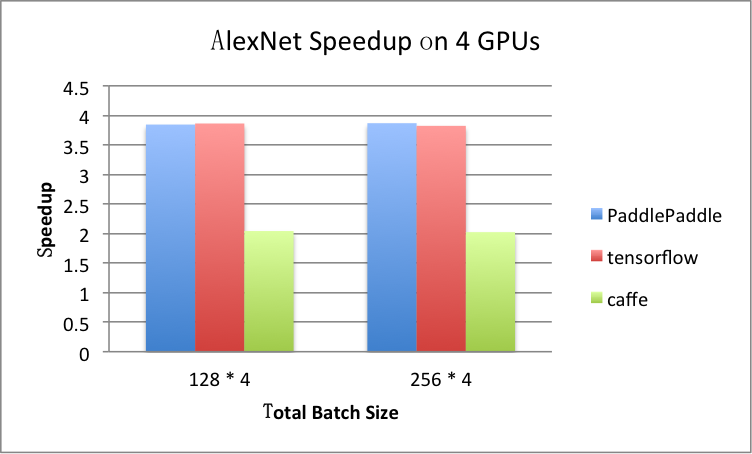
81.8 KB
benchmark/figs/googlenet-4gpu.png
0 → 100644
{kind=link}

81.8 KB
benchmark/figs/rnn_lstm_4gpus.png
0 → 100644
{kind=link}
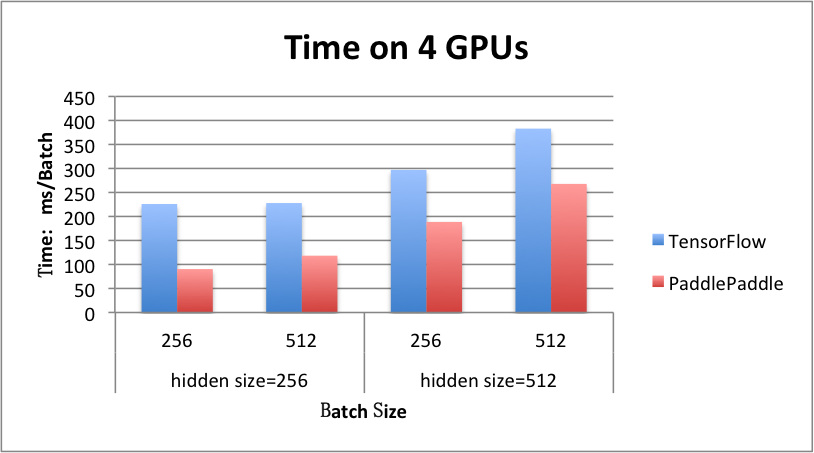
71.5 KB
benchmark/figs/rnn_lstm_cls.png
0 → 100644
{kind=link}
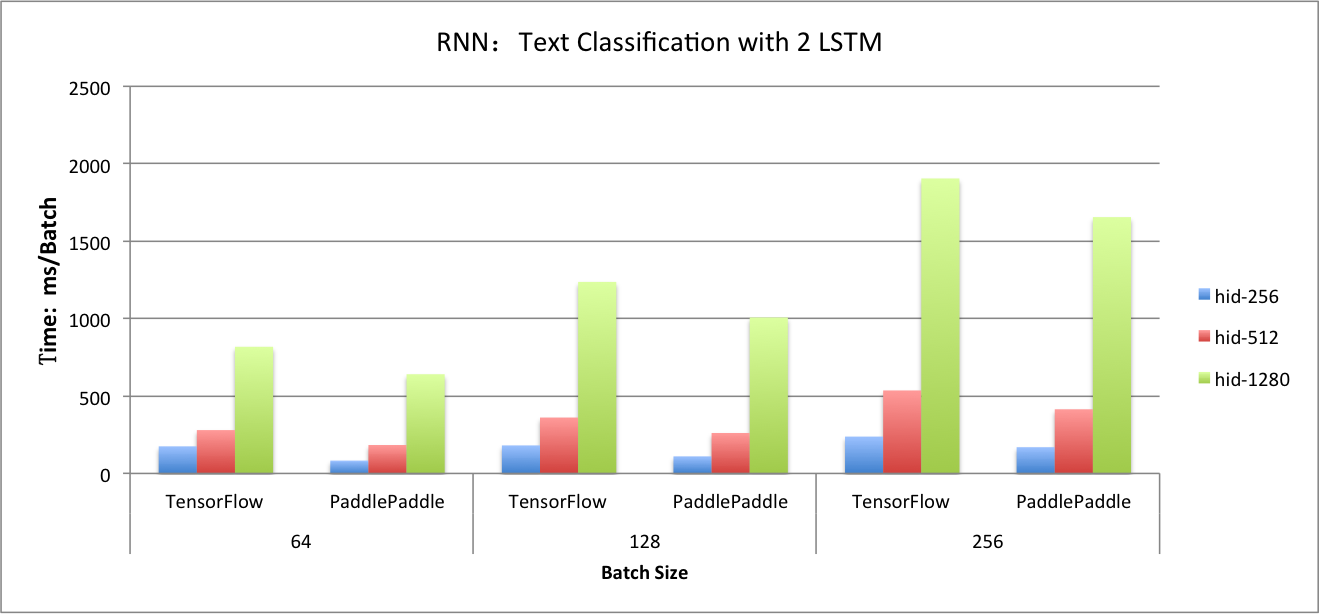
114.9 KB
benchmark/paddle/image/alexnet.py
0 → 100644
benchmark/paddle/image/run.sh
0 → 100755
benchmark/paddle/rnn/imdb.py
0 → 100755
benchmark/paddle/rnn/provider.py
0 → 100644
benchmark/paddle/rnn/rnn.py
0 → 100755
benchmark/paddle/rnn/run.sh
0 → 100755
此差异已折叠。
benchmark/tensorflow/image/run.sh
0 → 100755
此差异已折叠。
此差异已折叠。
benchmark/tensorflow/rnn/rnn.py
0 → 100755
此差异已折叠。
此差异已折叠。
benchmark/tensorflow/rnn/run.sh
0 → 100755
cmake/version.cmake
0 → 100644
此差异已折叠。
demo/gan/.gitignore
0 → 100644
demo/gan/README.md
0 → 100644
此差异已折叠。
demo/gan/data/download_cifar.sh
0 → 100755
此差异已折叠。
demo/gan/data/get_mnist_data.sh
0 → 100644
此差异已折叠。
demo/gan/gan_conf.py
0 → 100644
此差异已折叠。
demo/gan/gan_conf_image.py
0 → 100644
此差异已折叠。
demo/gan/gan_trainer.py
0 → 100644
此差异已折叠。
demo/quick_start/data/README.md
0 → 100644
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
doc/Doxyfile.in
已删除
100644 → 0
此差异已折叠。
doc/about/index.rst
0 → 100644
此差异已折叠。
doc/algorithm/rnn/bi_lstm.jpg
已删除
120000 → 0
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
此差异已折叠。
doc/api/index.rst
0 → 100644
此差异已折叠。
此差异已折叠。
文件已移动
此差异已折叠。
文件已移动
文件已移动
文件已移动
文件已移动
文件已移动
文件已移动
doc/build/docker_install.rst
已删除
100644 → 0
此差异已折叠。
doc/cluster/index.rst
已删除
100644 → 0
此差异已折叠。
此差异已折叠。
doc/dev/index.rst
已删除
100644 → 0
此差异已折叠。
doc/dev/layer.md
已删除
100644 → 0
此差异已折叠。
{kind=link}
此差异已折叠。
文件已移动
{kind=link}
此差异已折叠。
文件已移动
doc/getstarted/index.rst
0 → 100644
此差异已折叠。
此差异已折叠。
文件已移动
文件已移动
doc/howto/cmd_parameter/index.md
0 → 100644
此差异已折叠。
doc/howto/index.rst
0 → 100644
此差异已折叠。
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
文件已移动
文件已移动
文件已移动
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
文件已移动
{kind=link}
文件已移动
文件已移动
{kind=link}
文件已移动
文件已移动
{kind=link}
文件已移动
{kind=link}
文件已移动
{kind=link}
文件已移动
文件已移动
{kind=link}
文件已移动
{kind=link}
文件已移动
{kind=link}
{kind=link}
{kind=link}
文件已移动
{kind=link}
文件已移动
{kind=link}
文件已移动
{kind=link}
文件已移动
{kind=link}
文件已移动
{kind=link}
文件已移动
{kind=link}
文件已移动
文件已移动
{kind=link}
文件已移动
此差异已折叠。
{kind=link}
文件已移动
文件已移动
{kind=link}
文件已移动
文件已移动
{kind=link}
文件已移动
{kind=link}
文件已移动
文件已移动
此差异已折叠。
doc/ui/index.md
已删除
100644 → 0
此差异已折叠。
doc/user_guide.rst
已删除
100644 → 0
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
doc_cn/introduction/index.md
已删除
100644 → 0
此差异已折叠。
doc_cn/introduction/index.rst
0 → 100644
此差异已折叠。
doc_cn/ui/cmd/dump_config.rst
已删除
100644 → 0
doc_cn/ui/cmd/merge_model.rst
已删除
100644 → 0
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
paddle/math/tests/TensorCheck.h
0 → 100644
此差异已折叠。
paddle/math/tests/TestUtils.h
0 → 100644
此差异已折叠。
此差异已折叠。
paddle/math/tests/test_Matrix.cpp
0 → 100644
此差异已折叠。
paddle/scripts/docker/Dockerfile
0 → 100644
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
paddle/scripts/docker/build.sh
100644 → 100755
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。